
- 1深度学习-数据归一化与Batch Normalization
- 2深度学习和强化学习的关系
- 3【MapGIS精品教程】004:矢量数据格式转换(shp、dxf、GDB、txt)_shpfile 转gdb
- 4浅聊一下最接近英伟达B200的AI芯片_mi300x 和b200
- 5可能你已经刷了很多01背包的题,但是真的对01背包领悟透彻了吗?,看我这一篇,使君对01背包的理解更进一步【代码+图解+文字描述】
- 6【ArcGIS模型构建器】02:shp批量转kml/kmz_acrgisshp转kml
- 7Linux驱动开发 IO模型:阻塞IO_linux 读取 io文件阻塞
- 8【HarmonyOS NEXT】ffmpeg动态库如何在Mac上编译_mac编译支持harmonyos next的ffmpeg
- 9HDD杭州站·HarmonyOS技术专家分享HUAWEI DevEco Studio特色功能_鸿蒙 dev-eco studio 可视化开发
- 10SpringBoot全局处理系列--全局请求处理_springboot处理所有请求
AI声音克隆模型常见问题汇总笔记(附解决方法,可评论区留言问题技术交流_final_annotation_train.txt
赞
踩
AI声音克隆模型常见问题汇总-学习笔记(附解决方法
声明:
源码非原创,转载自小破站UP主Jack-Cui,文章部分内容来源网路,本文只用于技术分享,模型训练与语音输出已测试成功。
硬件配置工具及运行环境
CPU: i5-12490F
显卡:七彩虹战斧 RTX 4060 显存8G # 网传:A卡不行
内存:16G
运行系统:Windows 10
Python版本:3.10.9
Python旧版本下载链接:https://www.python.org/downloads/windows/
- 1
- 2
- 3
- 4
- 5
- 6
名词解释:
batch_size:计算效率和内存容量之间的平衡参数。若为高性能GPU,可以设置更大的batch_size值
epochs:所有样本训练一遍。一个epoch是所有训练样本的一轮正向传递和一轮反向传递。
举例:假设训练数据集总共有1000个数据集,batch_size=10,样本集需要100次迭代,完成1次epoch。
*问题汇总(附解决方法
Part 1: 训练几小时报错。
解决方法:比如设置了epoch为50,结果训练很久后报错,可以看cmd的日志,是不是最后一条训练Epoch为50或者51.这种报错是模型训练已经完成。直接关闭,启动 预测一键启动.bat 即可
Part 2:CUDA相关报错
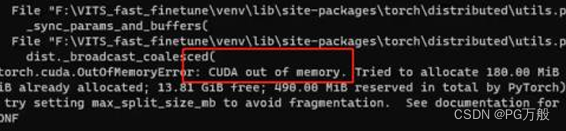
解决方法:这种一般是爆显存,建议是音频做下切片,每个wav不超过2分钟,batch_size调小一下。
Part 3: Error Connection errored out.

解决方法:打开报错:Error Connection errored out. 建议检查下代理服务器有没有关掉,以及墙/VN/魔法上网,有没有关闭。
Part 4: 找不到系统指定路径问题
解决方法:一般这个是权限不够,直接双击,或者用管理员身份打开。如果是预测一键启动.bat打不开,也有可能是模型没有训练成功。
Part 5:开始运行后提示:音频文件识别失败
解决方法:这个是训练填写的路径错误,路径不要包含中文,建议是直接在工程文件里面找到VITS_fast_finetune\raw_audio直接复制粘贴过去
Part 6:页面文件太小,无法完成操作
解决方法:这个需要修改下虚拟内存。建议改大一点。具体教程可以百度搜索
大概步骤:高级系统设置–点上边高级–性能里面点设置–再点性能选项中高级–出来有个虚拟内存更改按钮–点击进去设置(根据自己硬件条件设置,比如D盘256G 我设置100G虚拟内存
Part 7:bat 文件乱码
解决方法:不要使用win11默认的解压软件,解压压缩包,请使用WinRAR解压。
解压工具分享链接:https://pan.baidu.com/s/10QEYoeNoUem9hCkWzzQpaw
提取码:9996
Part 8: ProcessExitedException 报错 code 3221225477
process 0 terminated with exit code 3221225477
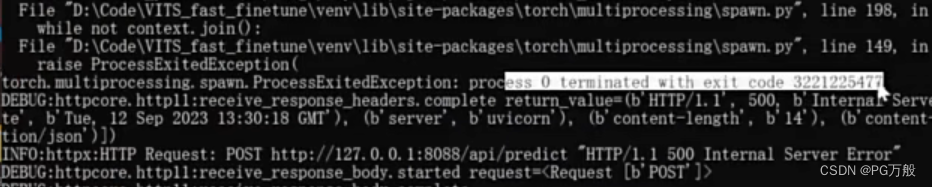
解决方法:报错原因是音频通过脚本生成对应的text文本中,句子太长。简而言之还是爆显存
个人解决方法:将wav文件做下前期处理,通过剪映将长句子的片段裁剪掉
Up主解决方法:https://www.bilibili.com/video/BV13z4y1L74i/ 视频4分钟后就有讲解该问题。
Part 9:训练没有进度条,空跑项目
解决方法:检查音频raw_audio文件夹有没有放到VITS_fast_finetune 工程目录下
Part 10:运行后网页打不开

解决方法:打开 finetune_webui.py 文件,修改最后两行代码,8088 改为 8089 或者其他端口。
Part 11:multiprocessing.spawn.ProcessExitedException: process 0 terminated with exit code 1

解决方法:这种异常报错,直接打开 finetune_webui.py 文件,找到587行,将gr.Slider中第二个参数改成 10000,重新运行代码,在网页端选择epochs时,调高点。
max_epochs = gr.Slider(2, 10000, value = 200, label = "训练epochs次数", info = "迭代训练的轮次,默认200")
- 1
Part 12:路径没错,点开始训练完全没反应,也没打印流程
解决方法:检查,检查,检查路径中的音频文件后缀是不是小写wav,文件后缀必须为小写!小写!小写的wav
Part 13: UnicodeEncodeError: ‘gbk‘ codec can‘t encode character(编码问题
解决方法:更新一下 pip,
更新指令:pip install --upgrade pip
然后win+R 输入cmd,输入
set PYTHONUTF8=1
Part 14:关于预测一键启动.bat 运行失败问题
解决方法:检查路径中是否含有中文,需要先运行训练一键启动.bat,训练好模型之后,关掉训练一键启动.bat,只运行预测一键启动.bat,模型是不能分享,必须自己训练。
Part 15:关于重新训练模型
解决方法:分别删除以下 目录 里面的文件
denoised_audio
custom_character_voice
separated
segmented_character_voice
OUTPUT_MODEL
然后删除工程目录下的 txt 文件
final_annotation_train.txt
final_annotation_val.txt
另外:如果想继续之前训练一般的模型,OUTPUT_MODEL目录的文件不用删除,仅删除上面所述的其他文件。重新运行代码即可
Part 16:(待更新,可以在评论区留言…
有待更新…
个人使用总结:
1.音频文件尽量是5分钟内
2.效果与预期可能有点差距,只能到百分之80-90的效果
3.训练的时间需要很长。建议先设置epochs=50试一下,是不是自己想要的效果,不满意建议就换音源节省时间,个人测试后epochs=900与epochs=50 只是音质完善一下。
4.训练模型中,最好使用干声作为数据源
5.使用工具链接分享
哔哩哔哩视频解析下载:https://bilibili.iiilab.com/
在线视频提取音频:https://airmore.cn/extract-audio-online
在线转换音频文件:https://www.aconvert.com/cn/audio/

