
- 1运算放大器的理解与应用_电压控制电路的运放作用csdn
- 2基于先验驱动深度神经网络的图像复原去噪_神经网络恢复图像算法
- 3Android 中的广播机制_android 广播
- 4Docker入门学习教程_c# docker
- 5深度学习图解 - 具备高中数学知识就能从入门到精通的神书 Andrew W· Trask
- 6使用move_base规划路径后,小车接近目的地后原地打转的原因分析_movebase导航原地打转
- 7pytorch自定义loss损失函数
- 8JavaScript面试题看这一篇就够了,简单全面一发入魂(持续更新 step2)_javascript 面试题
- 9ArkTS基础学习笔记_arkts文档
- 10手把手教你DouZero项目的环境配置及运行,使用注意事项(否则会退出)
【Attention(3)】【QKV的注意力机制】 主要思路(笔记)_交叉注意力机制 qkv怎么设计
赞
踩
通俗理解讲解一
与自注意力机制不一样,QKV 中 Q query是输入的问题,KV key value是源码、原始文本等数据。
以翻译英文论文为例,RNN 基于QKV注意力,训练英文翻译中文。
source:我 是 中国人--> K V
target: I am Chinese ---> Q query
- 1
- 2
比如翻译目标单词为 I 的时候,Q为I
而source中的 “我” “是” “中国人”都是K,
那么Q就要与每一个source中的K进行对齐(相似度计算);
1、"I"与"我"的相似度,
2、"I"与"是"的相似度;
3、"I"与"中国人"的相似度;
处理步骤:
1、先进行相似度的值进行归一化后会生成对齐概率值(“I"与source中每个单词的相似度(和为1)),也可以注意力值;
2、而V代表每个source中输出的context vector;如果为RNN模型的话就是对应的状态向量;即key与value相同;
3、然后相应的V与相应的P进行加权求和,就得到了context vetor;
从网上找到了一张图更能证明我的理解的正确性;
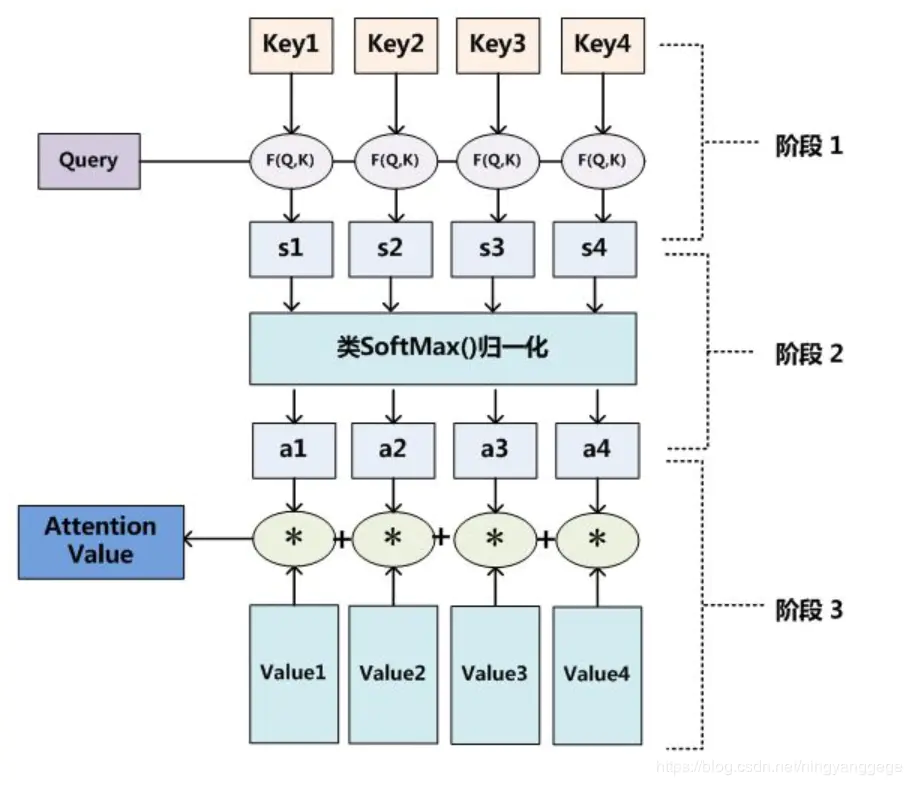
如果为RNN模型的话就是对应的状态向量;即key与value相同;
阶段1中的F函数是一个计算得分的函数;比如可以用前馈神经网络结构进行计算得分:
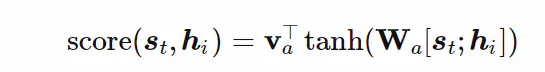
这里的v与上面的V是不一样的,这属于一个单隐藏层的前馈神经网络;v属于隐藏层激活后的一个计算得分的权重系数矩阵;
w属于激活前的权重系数矩阵;
这里应该是输出神经元为一个得分值;所以需要多个前馈神经网络同时计算每个hi的得分;与我预想的不同,以为一个前馈神经网络就可以输出所有对应的得分,即输出层的维度是与input序列长度一样;(目前的理解);为什么不与预想的一致呢?
然后对所有得分进行归一化,一般选择softmax方法;让权重系数为1
第二阶段:将hi与对应的权重系数相乘得到一个context vector;即注意力值.
通俗理解讲解二
Q、K、V是什么
[PS:本文谈论的Q、K、V只限于seq2seq结构]
Q:指的是query,相当于decoder的内容
K:指的是key,相当于encoder的内容
V:指的是value,相当于encoder的内容
- 1
- 2
- 3
参考
https://www.jianshu.com/p/7a61533fd73b

