
热门标签
热门文章
- 1推荐使用AI开源平台:搭建GA领域案件分类的自动化处理
- 2CSDN付费专栏写作协议_csdn关闭付费专栏后文章还在吗
- 3实例7:将图片文件制作成Dataset数据集_sklearn将图片转成数据集
- 4【阅读论文】TimesNet短期预测的基本流程梳理_m4数据集
- 5Java:SpringBoot的使用_java 程序 使用springboot 库
- 6探索政府工作报告中计算机行业的发展方向
- 7【亲测有效】Claude3为什么不能注册?解决Claude3账号注册遇到被封号和无法发送手机验证码问题!_claude 注册 虚拟号 不行
- 8目标跟踪简介
- 92023华为OD面试手撕真题【行星碰撞】_华为面试行星碰撞
- 10【黑马程序员】SpringCloud——微服务_黑马程序员springcloud资料
当前位置: article > 正文
pytorch自定义loss损失函数
作者:菜鸟追梦旅行 | 2024-03-27 03:34:40
赞
踩
pytorch自定义loss
自定义loss的方法有很多,但是在博主查资料的时候发现有挺多写法会有问题,靠谱一点的方法是把loss作为一个pytorch的模块,比如:
class CustomLoss(nn.Module): # 注意继承 nn.Module
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, x, y):
# .....这里写x与y的处理逻辑,即loss的计算方法
return loss # 注意最后只能返回Tensor值,且带梯度,即 loss.requires_grad == True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例代码
以一个pytorch求解线性回归的代码为例(参考:https://blog.csdn.net/weixin_35757704/article/details/117395205):
import torch import torch.nn as nn import numpy as np import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" def get_x_y(): np.random.seed(0) x = np.random.randint(0, 50, 300) y_values = 2 * x + 21 x = np.array(x, dtype=np.float32) y = np.array(y_values, dtype=np.float32) x = x.reshape(-1, 1) y = y.reshape(-1, 1) return x, y class LinearRegressionModel(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegressionModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) # 输入的个数,输出的个数 def forward(self, x): out = self.linear(x) return out if __name__ == '__main__': input_dim = 1 output_dim = 1 x_train, y_train = get_x_y() model = LinearRegressionModel(input_dim, output_dim) epochs = 1000 # 迭代次数 optimizer = torch.optim.SGD(model.parameters(), lr=0.001) model_loss = nn.MSELoss() # 使用MSE作为loss # 开始训练模型 for epoch in range(epochs): epoch += 1 # 注意转行成tensor inputs = torch.from_numpy(x_train) labels = torch.from_numpy(y_train) # 梯度要清零每一次迭代 optimizer.zero_grad() # 前向传播 outputs: torch.Tensor = model(inputs) # 计算损失 loss = model_loss(outputs, labels) # 返向传播 loss.backward() # 更新权重参数 optimizer.step() if epoch % 50 == 0: print('epoch {}, loss {}'.format(epoch, loss.item()))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
步骤1:添加自定义的类
我们就用自定义的写法来写与MSE相同的效果,MSE计算公式如下:
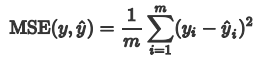
添加一个类
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, x, y):
mse_loss = torch.mean(torch.pow((x - y), 2)) # x与y相减后平方,求均值即为MSE
return mse_loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
步骤2:修改使用的loss函数
只需要把原始代码中的:
model_loss = nn.MSELoss() # 使用MSE作为loss
- 1
改为:
model_loss = CustomLoss() # 自定义loss
- 1
即可
完整代码
import torch import torch.nn as nn import numpy as np import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" def get_x_y(): np.random.seed(0) x = np.random.randint(0, 50, 300) y_values = 2 * x + 21 x = np.array(x, dtype=np.float32) y = np.array(y_values, dtype=np.float32) x = x.reshape(-1, 1) y = y.reshape(-1, 1) return x, y class LinearRegressionModel(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegressionModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) # 输入的个数,输出的个数 def forward(self, x): out = self.linear(x) return out class CustomLoss(nn.Module): def __init__(self): super(CustomLoss, self).__init__() def forward(self, x, y): mse_loss = torch.mean(torch.pow((x - y), 2)) return mse_loss if __name__ == '__main__': input_dim = 1 output_dim = 1 x_train, y_train = get_x_y() model = LinearRegressionModel(input_dim, output_dim) epochs = 1000 # 迭代次数 optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # model_loss = nn.MSELoss() # 使用MSE作为loss model_loss = CustomLoss() # 自定义loss # 开始训练模型 for epoch in range(epochs): epoch += 1 # 注意转行成tensor inputs = torch.from_numpy(x_train) labels = torch.from_numpy(y_train) # 梯度要清零每一次迭代 optimizer.zero_grad() # 前向传播 outputs: torch.Tensor = model(inputs) # 计算损失 loss = model_loss(outputs, labels) # 返向传播 loss.backward() # 更新权重参数 optimizer.step() if epoch % 50 == 0: print('epoch {}, loss {}'.format(epoch, loss.item()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

