
- 1如何面对“00后整顿职场”
- 2大数据分析与内存计算——Spark安装以及Hadoop操作——注意事项
- 310款生成PPT的AI工具实测_pptai生成
- 4Springboot + vue 实现文件上传_springboot vue文件上传
- 5Android架构探究之MVC设计模式_android mvc
- 6深度学习pytorch好用网站分享
- 7NTFS磁盘格式读写工具Tuxera NTFS for Mac 2023中文版新功能介绍_microsoft ntfs for mac by tuxera
- 8msf添加路由及socks代理进行内网穿透_msf内网代理
- 9『Nginx安全访问控制』利用Nginx实现账号密码认证登录的最佳实践_何通过前端传递传递nginx验证的账号和密码
- 10【面试HOT200】滑动窗口篇
NLP界新SOTA!吸纳5000万级知识图谱,一举刷爆54个中文任务!
赞
踩
点击下面卡片,关注我呀,每天给你送来AI技术干货!
来自:夕小瑶的卖萌屋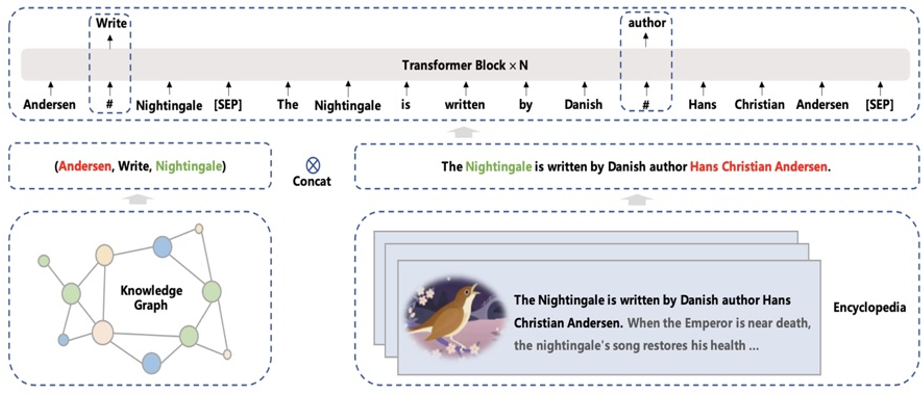
大家还记得2019年底首次将GLUE榜单分数刷过90大关的百度ERNIE模型吗?
在随后一年多的时间里,又陆续出现了GPT-3、Switch Transformer等一众靠模型体量取胜的千亿乃至万亿参数规模的超大预训练模型,似乎新训一个预训练模型没有个千亿参数都不好意思拿出来吹。
但是,万事都是有天花板的。参数规模的提升,不仅使得模型训练变得极其困难,而且应用部署也变的更加棘手,更为让人忍不住思考的问题是:难道预训练就没有一条更加光明的道路了吗?

近期,笔者从百度新发布的ERNIE 3.0模型上看到了新的希望——ERNIE 3.0没有选择一味的比拼模型规模,而是巧妙地将包含5000万+实体知识的大规模知识图谱融合到百亿级参数规模的超大规模模型中,并通过数据规模、多样性、质量的提升,以及模型结构与训练方式的框架级改进,使得模型全面屠榜了各大中文NLP任务!还顺便登顶了GLUE、SuperGLUE两大NLP权威榜单...

论文链接:
https://arxiv.org/pdf/2107.02137.pdf
权威榜单双榜首,刷爆50+中文任务
提到预训练模型的效果测评,就不得不提到 SuperGLUE Benchmark 。
SuperGLUE是由谷歌DeepMind、Facebook 研究院、纽约大学、华盛顿大学等多个权威机构联合发布的复杂语言理解任务评测,旨在解决常识推理、因果判断、上下文消歧、指代消解等对于人工智能系统更为复杂任务,相对于GLUE等权威经典评测挑战更大。
在这份业界公认的“地狱级GLUE榜单”上,百度ERNIE3.0以 90.6 的分数击败Google T5、微软DeBERTa、OpenAI的GPT-3等强队,以超越人类水平0.8个百分点的成绩成功实现登顶!
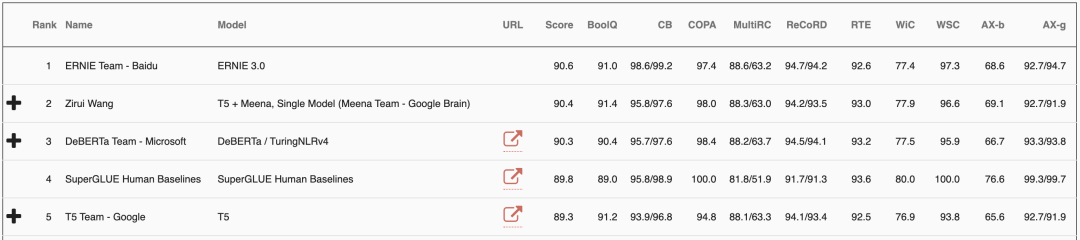
除了SuperGLUE榜单外,笔者还注意到在NLP经典权威榜单GLUE上,百度ERNIE同样稳居第一:

可以说一举实现了权威自然语言理解评测的双榜首。
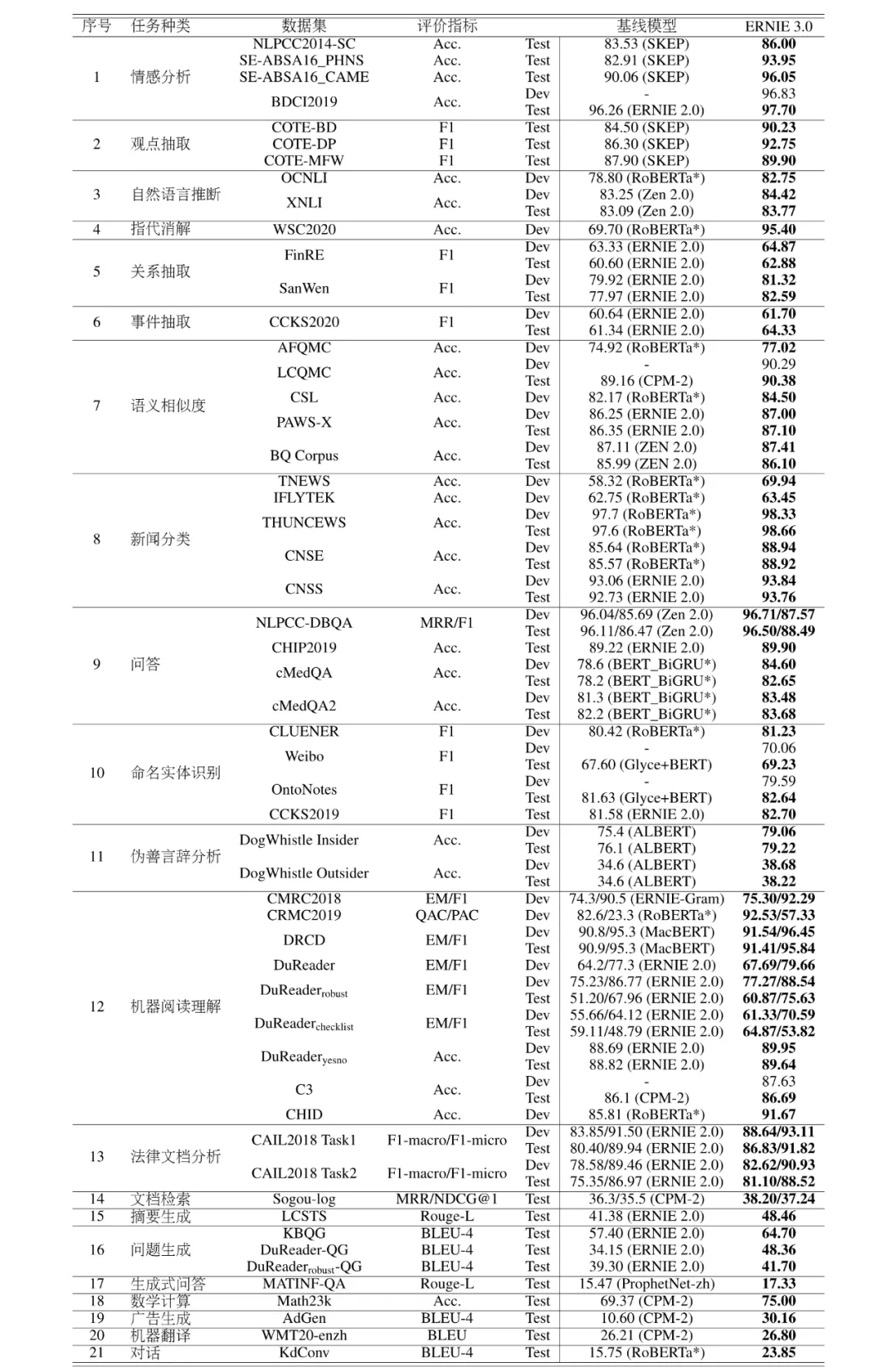
不仅如此,为了证明模型的通用性,ERNIE 3.0竟然一口气刷新了50多个中文NLP任务。。。其中涵盖了情感分析、观点抽取、阅读理解、文本摘要、对话生成等NLP经典任务,笔者也是被震惊到了。
例如,基于ERNIE 3.0进行下游任务finetune后,有20几个NLP任务取得了3%以上的显著提升:
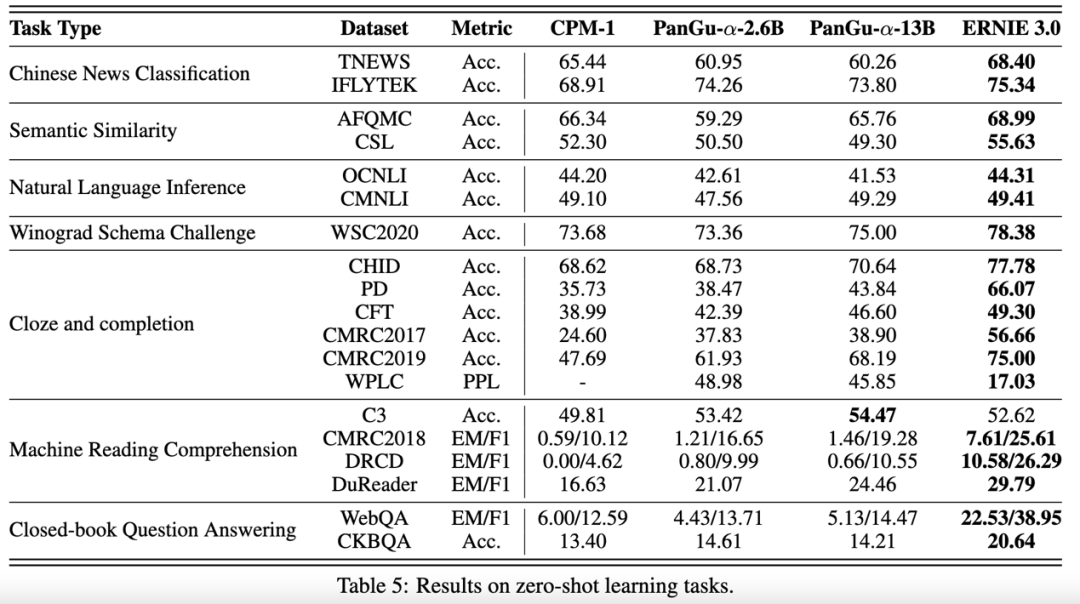
甚至在zero-shot的设定下,ERNIE 3.0 在大多数任务上相对已有的中文超大模型也取得了显著的效果提升。
中文创作能力出众
如果说SuperGLUE证明了ERNIE 3.0的自然语言理解能力,50+中文NLP任务证明了ERNIE 3.0的鲁棒性和通用性,那ERNIE 3.0的中文创作能力的冲击就更加直观了,下面直接上case!
古文创作
歌词创作
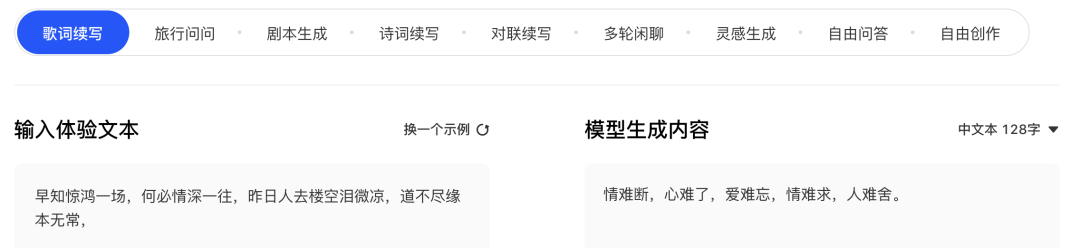
笔者特意搜了一下,发现模型确实不是暴力记忆了互联网上的歌词,而是有改编和创作成分在里面
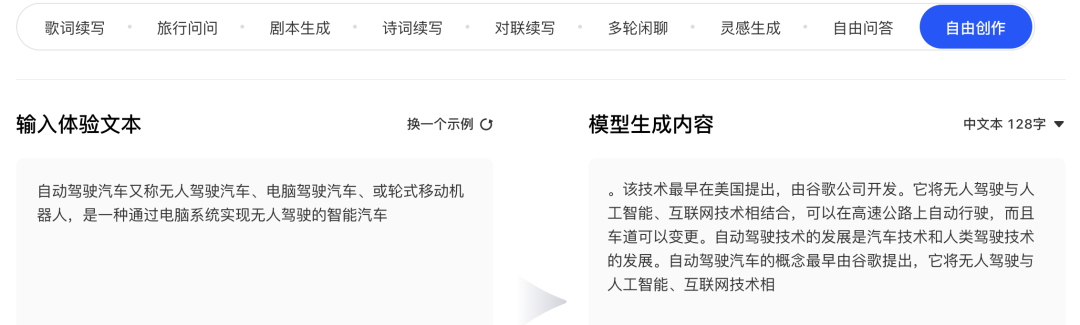
科技文稿创作
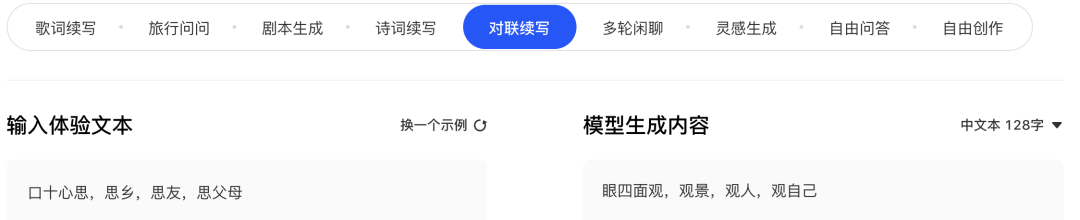
对对联
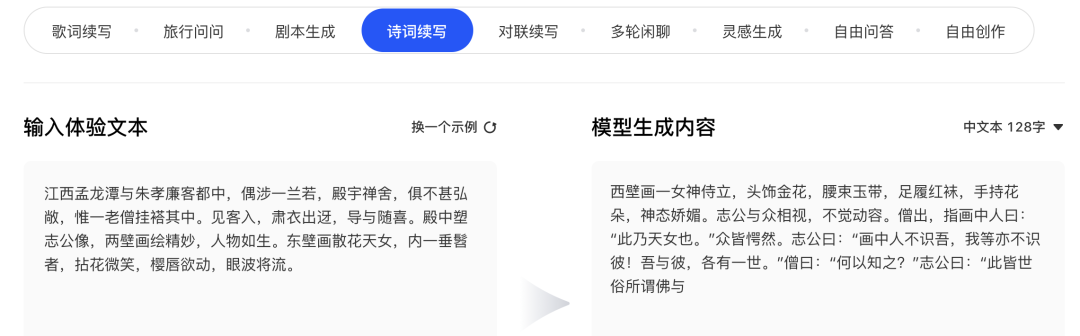
作诗
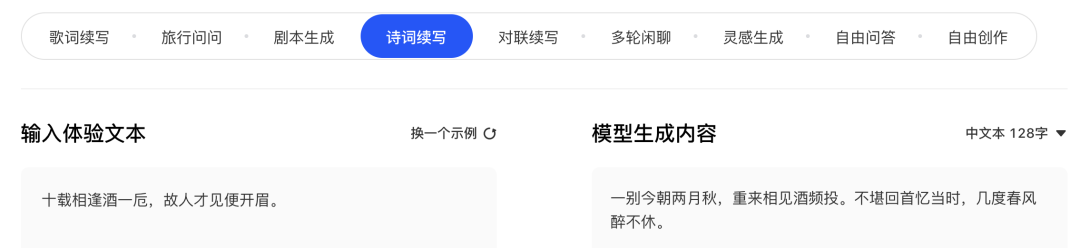
续写小说

这段小说的文字水平显然已经超越了笔者的高考作文
此外,由于ERNIE 3.0在预训练阶段引入了大规模知识图谱,因此在需要依赖知识的文本生成任务上同样表现出众,比如生成式问答:
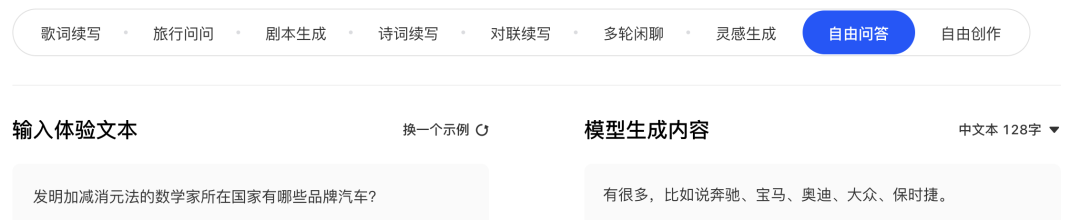


更多脑(tiao)洞(xi),欢迎通过demo传送门进行试用:
https://wenxin.baidu.com/wenxin/ernie
如何做到的?
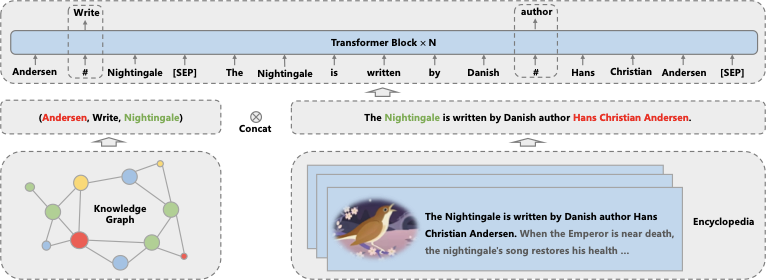
首先,是基于海量文本和大规模知识图谱的平行预训练技术!
文本与知识的平行预训练
数据方面,ERNIE 3.0使用了多达 4TB 的中文数据,而且在文本的多样性和质量方面也做了大量优化,如下表所示,数据来源包含11个大类:
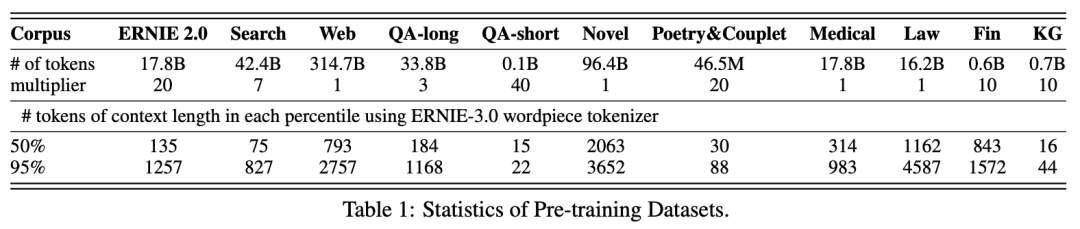
此外,4TB数据中还包含了 5千万知识图谱三元组 同时输入到预训练模型之中进行联合掩码训练。大规模知识图谱的融入有效促进了结构化知识和无结构文本之间的信息共享,大幅提升了模型对于知识的记忆和推理能力。
文本与知识的平行预训练方法如下图所示:
那么模型吃掉了这么多的知识,有什么用呢?
在论文的ablation study章节,可以看到引入大规模知识图谱后,最直观的就是对信息抽取这类知识驱动任务的性能提升:
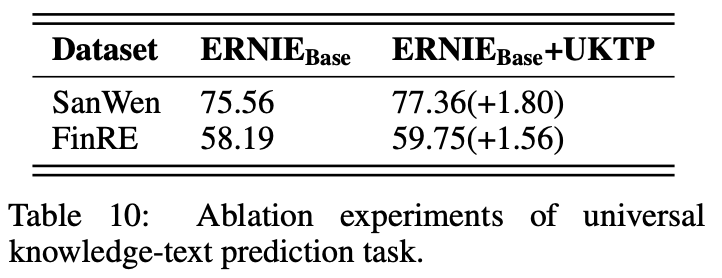
此外,如前述case所示,在KBQA任务以及zero shot的生成式问答方面,ERNIE 3.0具备显著优势。
模型结构改进
在结构方面,ERNIE 3.0基于Transformer-XL作为模型backbone,使得模型天然具备长文本处理能力。
此外,为了减小预训练与微调阶段的gap,提升模型的zero-shot能力,ERNIE 3.0还增加了task-specific的表示模块,如图所示:
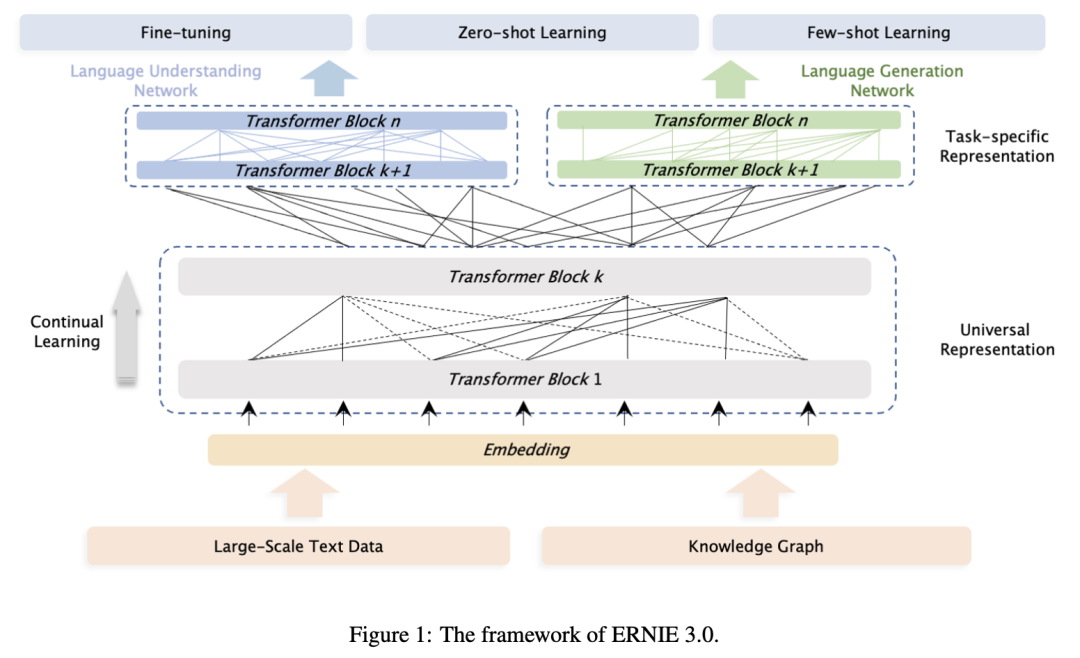
底层参数共享的shared backbone网络和上层参数不共享的任务网络均采用Transformer模型结构。backbone网络对所有任务均为可学习,而每个任务网络只对某一种任务进行学习。
此外,而为了更好的融合知识,让模型同时具备语言理解和语言生成的能力,ERNIE 3.0还融合了自编码和自回归两种范式进行统一预训练,使得模型兼具语言理解、生成与知识记忆能力。ERNIE 3.0也延续了ERNIE 2.0使用的持续学习范式,整个框架可通过引入新的预训练任务和新的任务模型网络,实现模型持续学习,进而解决新的任务。

由此可见,ERNIE 3.0框架的提出证明了预训练问题在模型规模之外依然存在很大的探索空间,包括但不限于大规模知识图谱的融合学习、数据多样性与质量优化、结构与训练方式改进等,提升参数规模绝对不是当下预训练问题的唯一解!
但从另一个角度来说,未来的ERNIE模型进化到千亿、万亿乃至十万亿参数规模后,又会带给业界怎样的惊喜呢?让我们拭目以待吧!
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!

