
- 1华为od机试C卷-最长表达式求值
- 2Python旅游景点数据大屏 爬虫+实时监控系统 旅游数据可视化 大数据 毕业设计_基于python的旅游景点数据分析系统
- 3pythonrdkit教程_RDKit入门与进阶教程(30篇)
- 4vue3 + vite 项目搭建 - 配置eslint_vue3+vite devdependencies
- 5基于java的宠物管理系统设计与实现_java连接数据库宠物管理系统
- 6大模型周报丨代码语言模型和模型即服务两篇综述,涵盖50+模型、30+评估任务和500+篇相关论文_模型即服务相关书籍
- 7【计算机毕业设计】在线商城系统_java在线商城系统
- 8简单的京东爬虫
- 9RAG学习总结
- 10【FPGA - 基础知识(二)】锁存器、触发器_寄存器用单稳态锁存器还是双稳定器
【自然语言处理与文本分析】中文分词的基本原理,如何进行词性标注 使用HMM算法提高准确率_中文分词要求词长度大于1,且只保留名词
赞
踩
-
- 分词(中文)
本次内容
分词:
N-Gram vs.中文分词
分词的难点
法则式分词
统计式分词
词性标注:
词性标注简介
词性标注的难点
词性的种类及意义
保留某些词性的词
分词:
N-Gram vs.中文分词
分词的难点
法则式分词
统计式分词
词性标注:
词性标注简介
词性标注的难点
词性的种类及意义
保留某些词性的词
-
-
- N-Gram分词法:
-
比如“南京市长江大桥”按N-Gram分可以有如下结果
UniGram:南 京 市 长 江 大 桥(都分为一个词)
Bi-Gram:南京 京市 市长 长江 江大 大桥
Tri-Gram:南京市 京市长 市长江 长江大 江大桥
4-Gram:南京市长 京市长江 市长江大 长江大桥
N-Gram的优点不用进行中文分词,就是当N够大的时候,一定会包含所有正确的分词
N-Gram的缺点是大多数采集的数据没有语法意义噪声过多,无法与许多资源(关联分析)结合,会影响后续分析,有意义的词就2个
-
-
- 中文分词:
-
中文的自动分词,是中文自然语言处理的特有问题,因为单独的汉字不是语意的最小单位。词才是中文中单独出现的最小单位。句法和语意都必须以词为基础去发展
中文分词的目的就是要简化步骤和复杂度,避免考虑太多不可能的分词情形。一般将句子的字符串顺序转化为词语顺序的过程就是分词。
分词就是利用计算机识别出中文中词汇的过程。
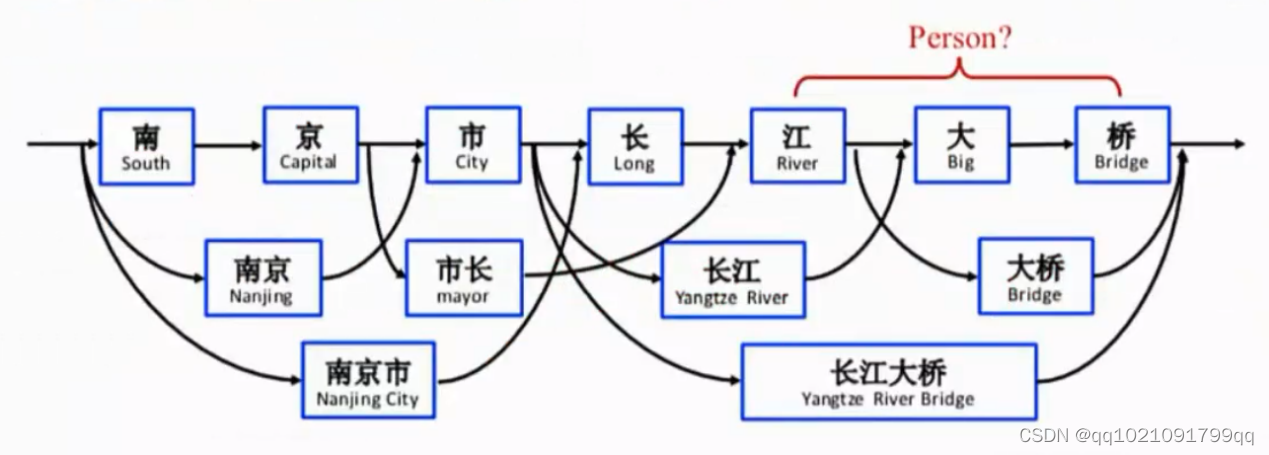
江大桥可能是人名。
-
-
- 分词难点:
-
歧义无处不在
交叉歧义(多种切分交织在一起):
内塔内亚胡\说\的\确实\在理
胡说,的确
组合歧义
这个人\手上有痣
我公司\人手\不足
真歧义
乒乓球拍\卖\完了
乒乓球\拍卖\完了
切分都对
新词层出不穷,
我们分词依赖词典,如果经常出现新词很难及时更新。
—人名、地名、机构名:刘德华,长坂坡,耀华路
—网名:你是我的谁,旺仔小馒头
—公司名、产品名:摩托罗拉,,爱国者,尼康D700
以上是命名实体(用深度学习可以试一试)可以定义的一定要先定义到分词系统,目前准确率不高。
—定量词:这三本书,这五本书(可以用规则方式定义)
—重迭词:高高兴兴。跳跳舞(可以用规则方式)
普通词和新词互用
高明(演员)表演真好\它的表演很高明
汪洋(人名)到深圳检查工作\洞庭湖一片汪洋
普通词与新词交织在一起
克小顿对内塔尼亚胡说
-
-
- 分词技术发展:
-
以构词规则为出发点的分词法
1.全切分
2.FMM(forward Maximum Matching
)
3.BMM(backward Maximum Matching
)
4.Bi-direction Maximum Matching
研究二利用语聊库来归类统计数据,作为凭证判断标准的统计式分词法
1.N-Gram概率模型
2.HMM概率模型
上述的方法,错了HMM,都需要词典的帮助。
-
-
- 研究1:法则式分词法
-
全切分:
获得文本所有可能的切分结果。一个一个逐步进行切割。它不会判断是否正确。

FMM(左到右)/BMM(右到左):
把句子扫描一遍,遇到字典里有的最长的词就标识出来,遇见不认识的字符串就分割为单字词
如果词典里最长的是3个,就会先扫描3个字,有对应的就标识。
案例如下:

下面的分词情况出现了一个成都,就是因为BMM规则,从右向左扫描。
不一定都是FMM比BMM效果好

都有可能出错。
双向法(Bi-direction Maximum Matching)
如果FMM和BMM词数不同,那么取词较少的取用
如果FMM和BMM词数相同,且结果相同,则返回任一个结果
如果FMM和BMM的词数相同,且结果不同,则返回单字较少的结果

比如这种情况,因为词数相同,返回单字最少的,所以就取用BMM。
法则法优点:
简单易行,开发周期短。
没有任何复杂的计算分词速度快。
法则法缺点:,歧义处理过于简单,
不能识别新词(只能傻傻的根据词典进行。)
分词精度不能满足实际需求(该分词结果文本分词率高于百分之80,互联网文本为百分之70)
-
-
- 研究2:统计式分词法
-
首先利用已切分好词的学习样本建立模型(语料),再利用模型对预测结果进行间接推理。
马可夫假设
当前状态出现的概率,只和过去有限的历史状态有关,而与其他状态无关
具体到分词认为,就是文本中第i个词出现的概率,仅仅依赖于它前面的i-1个词,而与其他词无关。
N-Gram
概率模型步骤如下:
学习语料(正确分好词的文章)——》学习算法——》分词知识库(词与词间的相连概率。通过语料库求出。)——》切分算法。
句子—词典—》切分算法——》切分结果

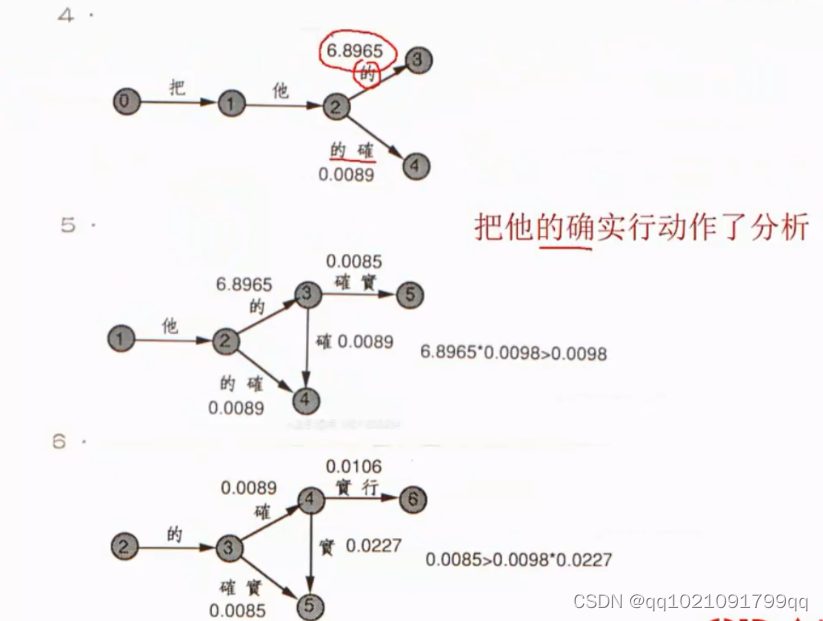
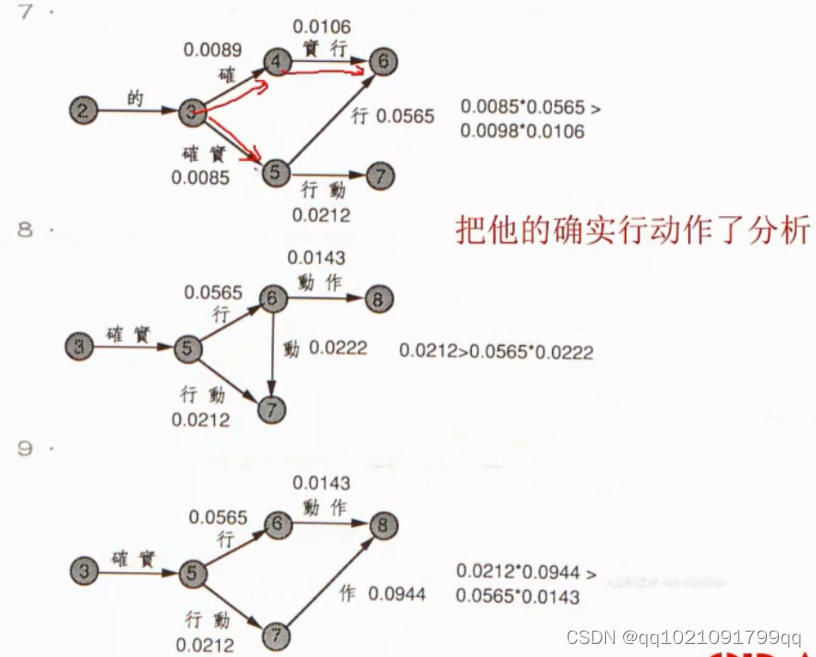
案例:
第一步全切分

第二步:Viterbi动态规划,找到所有分割的句子的路径,计算每条路径的概率。利用二阶马可夫模型计算概率
一阶马可夫模型就只和自己有关,也就是自己的概率相乘
二阶马可夫模型代表每个词只和之前的的词出现的概率相关
三阶马可夫模型,代表的就是每个词和前两个词出现的概率有关。

第三步,选择概率最大的路径为分割结果。
Viterbi动态规划:

这是一阶马可夫用Viterber的概率模式
HMM概率模型
唯一一个不依赖词典的概率模型,判断准确率很高。
HMM规定名字只能是4个构词成分
要么是词首B
要么是词中M
要么是词尾E
要么是单字词S
HMM的语料库要按照这个规定进行划分,
案例:
原文句子是中文分词是文本处理不可或缺的一步
分词结果:中文/分词/是/文本处理/不可或缺/的/一步
HMM结果:中/B 文/E 分/B 词/E 是/S 文/B 本/M 处/M 理/E 不/B可/M或/M缺/E的/S一/B步/E
模型的训练要以HMM结果的格式进行,也就是(词料库是它)
C=c1c2….cn代表输入的句子,例如中文分词
O=o1o2…on代表输出的结果,例如BEBE
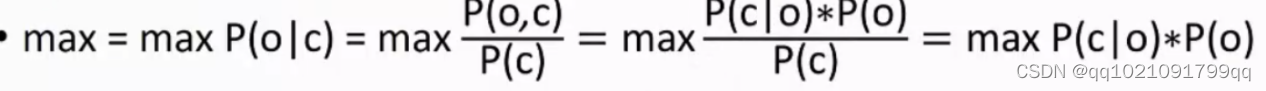
我们要找到的就是在c这个字的前提下最大可能o的概率,是bme还是s
因为每个数值都会除以Pc,所以推导出来的结果就是上图所示
我们把上图结果的两个概率进行推导。

第一个是o已知的情况c的概率,就是各个概率相乘,只和自己有关。叫做发射概率
Po的概率就是3阶马可夫模型,与前两个词有关。叫做移转概率
二者对应相乘。
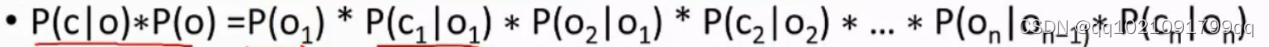

为了排除BBB,EM这些不合理的组合,要设置某些

然后我们再次利用Viterbi的动态规划,找到贯穿句子的路径,并计算每条路径的概率,得到最大概率的路径
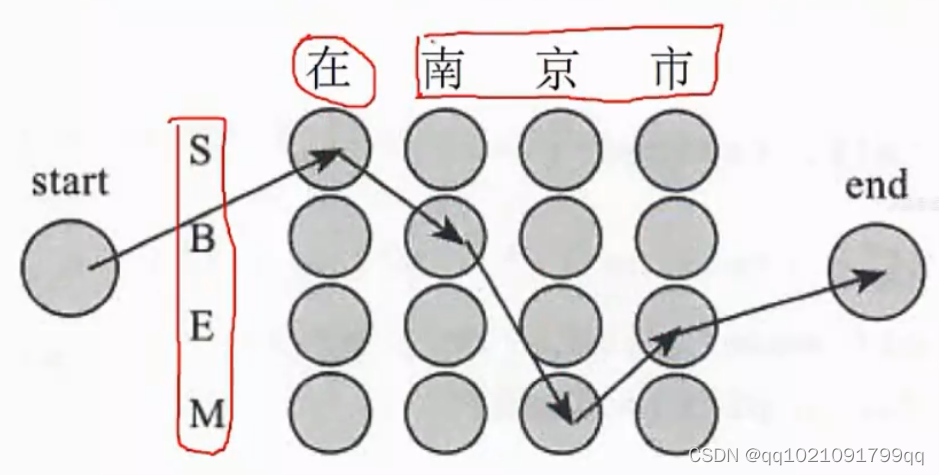
HMM模型优点:解决大多数常用词的歧义问题。
训练语料的规模够大,覆盖领域够多的前提下,可以获得较高的切分准确率(>=95%)
HMM模型缺点:不能处理新词以及新词带来的歧义问题
需要很大的训练语料
分词速度比规则型的慢些。
如何判断分词效能。
利用查准率:分词结果词数,除以正确分词词数。
查全率:正确词数除以总词数
求F1(0~1)
案例:

词性标注(part-of-speech Tagging)
词性大致可以分为名词、动词、形容词、数词、量词、代词、介词、副词、连词、感叹词、助词和拟声词
句法分析、信息抽取(关键词采集)等任务有非常重要的作用

只保留名词路
难点。具有两个或两个以上的词性的词,兼类词的问题。
针对兼类词的歧义排除算法有:
基于规则的算法
局域概率统计模型的算法
规则与统计结合的算法
HMM概率模型如何同时完成分词和词性标注。
因为分词有错误的概率,再进行词性标注,就容易错的更惨。
一方面可以提高分词的准确率,也可以提高词性标注的准确性
做法:
每个字只能是4个构词位置中的一种
B:词首M:词中E:词尾S:单字词
HMM结果:

同一个词的词性会控制到一致。
模型训练也是以HMM结果的格式进行。也就是中用b_nz代替文用E_nz代替。
然后做概率模型就好
Python可以含结巴套件进行分词,40种词性如下:
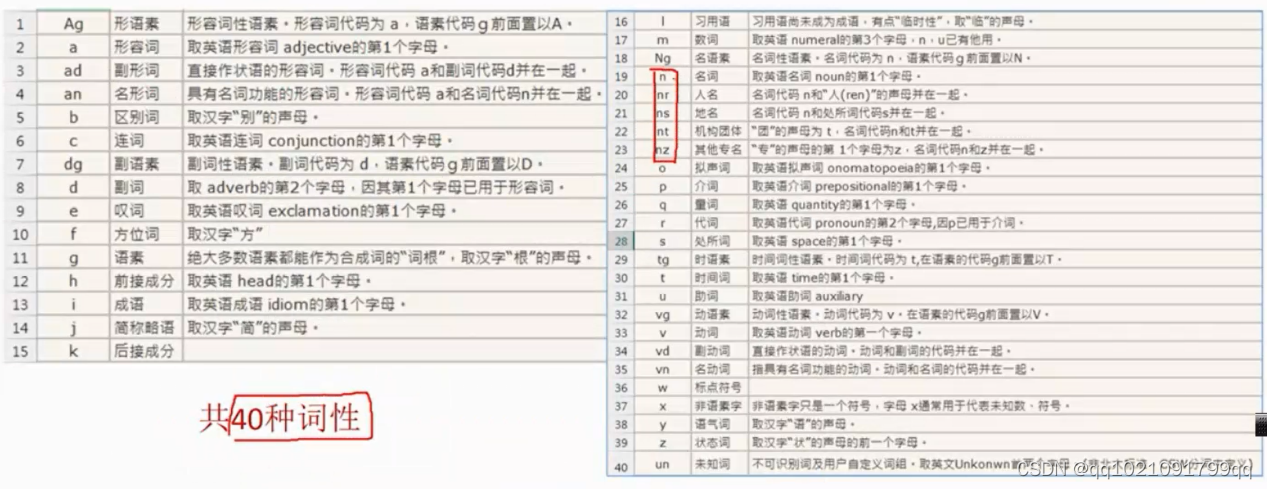
后面我们会在算法部分用python代码进行编程教学。调用之前要稍微理解一下才行。

这是之前的4篇文章,这是我们保留的名词。
关键词提取:出现次数必须大于等于两(可更改)次。算的是所有文章大于等于2次。就可以抽取比较漂亮的关键词出来。


把许多不必要的词可以筛除掉,就可以很清楚的看出重要性,进行词云图等操作都会简单许多。

