
- 1[网络安全学习篇60]:文件上传_phpstudy 禁止下载pdf
- 2Bert 模型学习_bert模型
- 3关于Gensim的word2vec要不要train的疑问_gensim train
- 4Jieba库基本用法_jieba库的使用
- 5GEE(Google earth engine)中的Landsat影像的选择和去云(附代码)_landsat/lc08/c02/t1去云
- 65、循环神经网络(RNN )
- 7Matlab求解规划问题之 fmincon函数_fmincon函数用法及例题
- 8tensorflow入门(一)波士顿房价数据集_load_boston数据集的替代·
- 9安卓移动开发基础知识大作业19145120_安卓移动开发大作业
- 10多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测_matlab多变量时序预测
GPT系列初探_gpt 自回归
赞
踩
GPT1
其实出现在BERT前,也算是现在大规模预训练模型的开始,奈何效果没有bert好,所有反而没有bert出名,它用的是一个decoder的架构去做的预训练,是一个自回归的模型。
gpt预训练的一个目标函数有两个,第一个是基础的下一个词预测任务,选择一个K窗口,将窗口中的K个词的embedding作为条件去预测下一个词
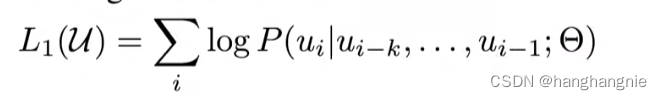
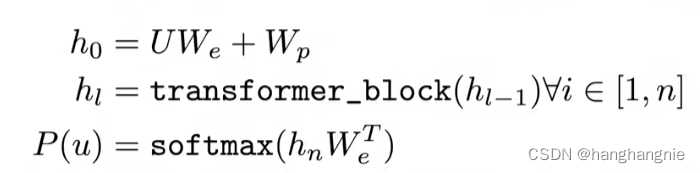
第二个是一个分类任务,一段话给一个标签,然后去预测这标签
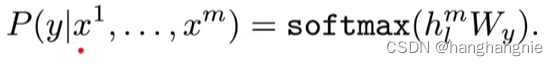
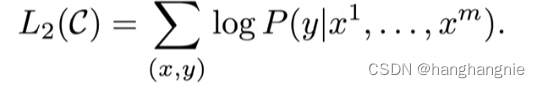
他作为预训练微调时的目标函数是这两个函数的和
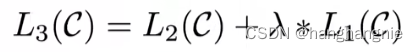
他在下接下游任务的时候,是将输入放入到transformer的decoder中,跟bert一样,使用预训练的参数,然后将特征加入到后续的一个FFN中,如下图所示:

他的层数是12层加768维,bert就是为了跟他做对比实验,才将自己的参数设置成这样的。
GPT2
GPT2是open ai为了回应bert,所做的一个反击,他首先是参数量大大增加了,bert large的参数总量也就是3.4亿,但是GPT2直接跳到了15亿,他的模型结构是基本没有变的,只是增加了层数参数,但是在模型架构训练目标函数上和1没有区别,他的卖点是 zero-shot也就是不需要微调,我的任何任务直接能拿来就用,正是因为zero-shot的设定,它没有在输入上加那些特殊符号,而是用一个text做前缀提示后续输入的形式,做法就是跟T5是一样的,可以看我上一篇文章。他的数据集是一个自己爬的超大的数据集。下面是它模型参数第一个设定,可以看出,非常大。

GPT3
3代模型就更大了,但是架构上他基本是就是按照12代做的,模型结构上区别也不大,模型训练和2也没太大区别,就是一个多任务的学习,GPT一共有1750亿个参数,模型大小是bert的上百倍,gpt3可以做zero-shot,也可以做one-shot,也可以做few-shot,顾名思义,一个是不需要微调,一个是用一个句子做微调,另一个是只用三两句句子做微调,其实他不做微调也不仅仅是因为特点,我觉得也有很大是因为,普通人办法去微调他,1750亿个参数太夸张了,你要跑一次这个模型,是不可以的,所有只能这样去使用它,
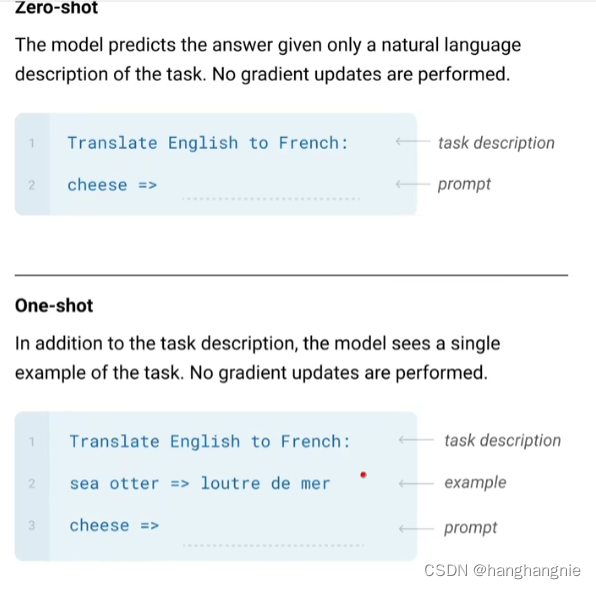
他的一个prompt是箭头,用来提示你可以进行一个任务预测了,任何前面再加上一个TEXT-TEXT形式的输入提示。

GPT的参数量是非常夸张的。
数据集它自己做了一个从redit上爬下来的自己清洗过的数据集,任何把gpt123bert的数据集全都用上了。
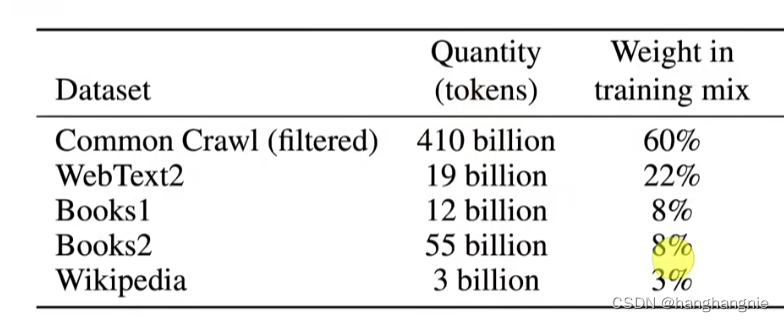
数据量也非常夸张。他基本是就是gpt2一个上百倍体量的版本,
不得不说,大力出奇迹。

