
- 1【学术精选】NLP可投的顶会信息(近期截稿)_acl会议2023年收稿多少
- 2BERTopic安装最全教程及报错处理_装bertopic报错
- 3华为手机百度云息屏后停止下载_华为智选车载智慧屏评测:像手机一般好用,行车体验更便捷...
- 4python决策树分类鸢尾花_【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类...
- 50.96寸 4针OLED屏模块功能实现(STM32)_0.96寸oled显示屏4针
- 6怎么让ai写代码?三款软件帮你轻松解决
- 7Google谷歌浏览器阻止不安全内容下载_google 老是阻止不安全
- 8VLAN与三层交换机和VRRP实操_思科三层交换机vrrp配置实例
- 9学习JavaScript笔记9_"javascript 无序列表对象调用insertbefore(\"test\")方法会在无序列表
- 10《人工智能》之读书笔记_人工智能读书笔记
BERT学习与实践:为紧追潮流ChatGPT做好技术准备_转换bert embedding 为 chatgpt embedding
赞
踩
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
BERT学习与实践:为紧追潮流ChatGPT做好技术准备!
本项目的主角是:ChatGPT的技术底座,NLP自然语言机器学习的开山之作,ERNIE相爱相杀的好基友–BERT模型!当然ChatGPT更直接的技术底座是GPT3.0。
如果有人问NLP自然语言机器学习有啥用?恐怕半年前还需要用800字才能讲明白,但现在有了ChatGPT,事实胜于雄辩,千千万万的公司和个人不再迷茫于NLP有啥用,而是发现了商机并投入到ChatGPT研发和应用的热潮中。ChatGPT的表现让人震惊,它可能正在捅破强人工智能和弱人工智能之间的那层窗户纸!
文心大模型,它是基于ERNIE模型的。而ERNIE模型跟BERT模型,就像它们俩在《芝麻街》中的故事一样,是亦敌亦友的关系。
总而言之,BERT开启了NLP新时代,ChatGPT引爆了NLP应用的市场!三种核心技术BERT、GPT和ERNIE互相借鉴,共同提高。现在的问题是:ERNIE大模型没有开源,GPT3.0没有开源,ChatGPT没有开源,而且这三个大模型即使开源了普通人也没有那么多算力去训练,甚至连放模型和数据集的存储空间都不够。聪明的你,肯定能够明白:如果想紧跟时代潮流,对于大多数人,扎扎实实把BERT弄熟弄透才是正解!
本项目参考自李沐老师《动手学深度学习》中文飞桨版,https://zh.d2l.ai 。 可以观看李沐老师B站讲解视频
也可以在AIStudio学习课程:https://aistudio.baidu.com/aistudio/education/group/info/25851
一、BERT原理:来自Transformers的双向编码器表示
什么是BERT?我们首先来思考下面的问题
什么是NLP里的迁移学习
在BERT之前
- 是Word2Vec或者语言模型
- 一般不更新预训练好的模型
- 换新任务需要构建新的网络来抓取新任务需要的信息
BERT的动机
- 基于微调的NLP模型,像CV一样用通用大数据进行预训练,然后针对特定任务微调
- 这样预训练模型抽取了足够多的信息,权重可以重复使用,
- 新任务只需要增加一个简单的输出层
BERT的架构
BERT是只有编码器的Transformer模型。也就是把解码器砍了的Transformer模型。
也就是只有下图的编码部分。
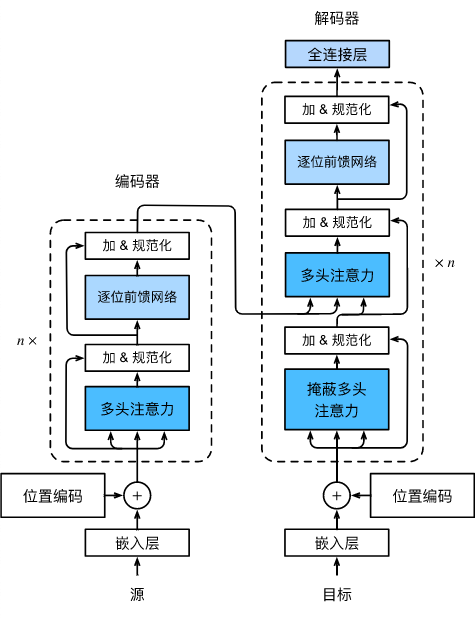
但是如果只是砍了解码器,并不会使BERT成为划时代的模型,因为BERT还有一样大创新,那就是:
对输入的修改
- 每个样本是一个句子对
- 加入额外的片段嵌入,给前一个句子Ea向量,后一个句子Eb向量
- 位置编码可学习
单单这三个技术修改,每个都平平无奇,但是它们结合起来,使BERT获得了自监督学习的能力,再配合后面的预训练任务,使BERT的语言处理发挥出惊人的能力,引领了其后的整个NLP发展的方向!
BERT代码实践
实践是最好的学习方法!让我们开始从头到尾用飞桨来实现BERT模型吧!
import warnings
from d2l import paddle as d2l
warnings.filterwarnings("ignore")
import paddle
from paddle import nn
- 1
- 2
- 3
- 4
- 5
- 6
输入表示
在自然语言处理中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。BERT输入序列明确地表示单个文本和文本对。当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“<sep>”的连结。我们将始终如一地将术语“BERT输入序列”与其他类型的“序列”区分开来。例如,一个BERT输入序列可以包括一个文本序列或两个文本序列。
为了区分文本对,根据输入序列学到的片段嵌入 e A \mathbf{e}_A eA和 e B \mathbf{e}_B eB分别被添加到第一序列和第二序列的词元嵌入中。对于单文本输入,仅使用 e A \mathbf{e}_A eA。
下面的get_tokens_and_segments将一个句子或两个句子作为输入,然后返回BERT输入序列的标记及其相应的片段索引。
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
BERT选择Transformer编码器作为其双向架构。在Transformer编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的Transformer编码器不同,BERT使用可学习的位置嵌入。总之,
BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
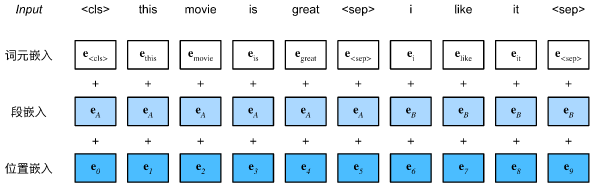
编码器
下面的BERTEncoder类类似于 TransformerEncoder类,但是使用了片段嵌入和可学习的位置嵌入。
class BERTEncoder(nn.Layer): """BERT编码器""" def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000, key_size=768, query_size=768, value_size=768, **kwargs): super(BERTEncoder, self).__init__(**kwargs) self.token_embedding = nn.Embedding(vocab_size, num_hiddens) self.segment_embedding = nn.Embedding(2, num_hiddens) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_sublayer(f"{i}", d2l.EncoderBlock( key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, True)) # 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数 # self.pos_embedding = nn.Parameters(paddle.randn(1, max_len, # num_hiddens)) x = paddle.randn([1, max_len, num_hiddens]) self.pos_embedding = paddle.create_parameter(shape=x.shape, dtype=str(x.numpy().dtype), default_initializer=paddle.nn.initializer.Assign(x)) print(self.pos_embedding, self.pos_embedding.shape, type(self.pos_embedding)) # param = paddle.create_parameter(shape=x.shape, # dtype=str(x.numpy().dtype), # default_initializer=paddle.nn.initializer.Assign(x)) def forward(self, tokens, segments, valid_lens): # 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens) X = self.token_embedding(tokens) + self.segment_embedding(segments) # X = X + self.pos_embedding.data[:, :X.shape[1], :] # nn.Parameter X = X + self.pos_embedding[:, :X.shape[1], :] for blk in self.blks: X = blk(X, valid_lens) return X

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
假设词表大小为10000,为了演示BERTEncoder的前向推断,让我们创建一个实例并初始化它的参数。
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
- 1
- 2
- 3
- 4
我们将tokens定义为长度为8的2个输入序列,其中每个词元是词表的索引。使用输入tokens的BERTEncoder的前向推断返回编码结果,其中每个词元由向量表示,其长度由超参数num_hiddens定义。此超参数通常称为Transformer编码器的隐藏大小(隐藏单元数)。
tokens = paddle.randint(0, vocab_size, (2, 8))
segments = paddle.to_tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
- 1
- 2
- 3
- 4
二、BERT预训练
预训练任务1:带掩码的语言模型
Transformer编码是双向的,而标准语言模型要求是单向的,BERT为了解决这个问题,提出了带掩码的语言模型这个概念,训练的时候,随机(15%概率)将一些词元换成看不见的<mask>,具体来说,在这15%的词元里:
80%几率将选中的词元变成<mask>
10%几率换成一个随机词元
10%几率保持原有的词元
下面的MaskLM类来预测BERT预训练的掩蔽语言模型任务中的掩蔽标记。预测使用单隐藏层的多层感知机(self.mlp)。在前向推断中,它需要两个输入:BERTEncoder的编码结果和用于预测的词元位置。输出是这些位置的预测结果。
import warnings
from d2l import paddle as d2l
warnings.filterwarnings("ignore")
import paddle
from paddle import nn
- 1
- 2
- 3
- 4
- 5
- 6
class MaskLM(nn.Layer): """BERT的掩蔽语言模型任务""" def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs): super(MaskLM, self).__init__(**kwargs) self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.LayerNorm(num_hiddens), nn.Linear(num_hiddens, vocab_size)) def forward(self, X, pred_positions): num_pred_positions = pred_positions.shape[1] pred_positions = pred_positions.reshape([-1]) batch_size = X.shape[0] batch_idx = paddle.arange(0, batch_size) # torch.arange() # 假设batch_size=2,num_pred_positions=3 # 那么batch_idx是np.array([0,0,0,1,1]) # print(f'batch_idx:{batch_idx} num_pred_positions:{num_pred_positions}') batch_idx = paddletile(batch_idx, [num_pred_positions]) # print(f"'batch_idx:{batch_idx}") masked_X = X[batch_idx, pred_positions] # print("masked_X{masked_X} pred_positions{pred_positions} masked_X{masked_X}") masked_X = masked_X.reshape((batch_size, num_pred_positions, -1)) mlm_Y_hat = self.mlp(masked_X) return mlm_Y_hat def paddletile(x, n) : # 写一个飞桨的代码,满足torch.repeat_interleave命令。飞桨自带的tile不满足要求。 out = paddle.to_tensor([]) for i in x: tmp = paddle.tile(i, n) out = paddle.concat([out, tmp]) return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
为了演示MaskLM的前向推断,我们创建了其实例mlm并对其进行了初始化。回想一下,来自BERTEncoder的正向推断encoded_X表示2个BERT输入序列。我们将mlm_positions定义为在encoded_X的任一输入序列中预测的3个指示。mlm的前向推断返回encoded_X的所有掩蔽位置mlm_positions处的预测结果mlm_Y_hat。对于每个预测,结果的大小等于词表的大小
(
x
−
1
)
(
x
+
3
)
a
2
+
b
2
x
=
a
0
+
1
a
1
+
1
a
2
+
1
a
3
+
a
4
\left(x-1\right)\left(x+3\right)\sqrt{a^2+b^2}x = a_0 + \frac{1}{a_1 + \frac{1}{a_2 + \frac{1}{a_3 + a_4}}}
(x−1)(x+3)a2+b2
x=a0+a1+a2+a3+a4111。
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = paddle.to_tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shape
- 1
- 2
- 3
- 4
# 通过掩码下的预测词元`mlm_Y`的真实标签`mlm_Y_hat`,我们可以计算在BERT预训练中的遮蔽语言模型任务的交叉熵损失。
mlm_Y = paddle.to_tensor([[7, 8, 9], [10, 20, 30]])
# loss = nn.CrossEntropyLoss(reduction='none')
loss = nn.CrossEntropyLoss()
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape([-1]))
mlm_l.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
预训练任务2:下一句子预测
预测句子对中两句是否相邻
训练样本中,50%选相邻句子对,50%选随机句子对(也就是不相邻句子对)
将<cls>对应的输出放到一个全连接层来预测
下面的NextSentencePred类使用单隐藏层的多层感知机来预测第二个句子是否是BERT输入序列中第一个句子的下一个句子。由于Transformer编码器中的自注意力,特殊词元“<cls>”的BERT表示已经对输入的两个句子进行了编码。因此,多层感知机分类器的输出层(self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而MLP隐藏层的输入是编码后的“<cls>”词元。
class NextSentencePred(nn.Layer):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
开始预训练BERT
在WikiText-2数据集上对BERT进行预训练。
加载数据集
加载WikiText-2数据集作为小批量的预训练样本,用于遮蔽语言模型和下一句预测。批量大小是512,BERT输入序列的最大长度是64。注意,在原始BERT模型中,最大长度是512。
数据集下载可能较慢,这里放在work目录,并在使用前拷贝到data目录,以提高运行速度。
!cp ~/work/wikitext-2-v1.zip ~/data
def load_data_wiki(batch_size, max_len):
"""加载WikiText-2数据集
Defined in :numref:`subsec_prepare_mlm_data`"""
data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')
paragraphs = d2l._read_wiki(data_dir)
train_set = d2l._WikiTextDataset(paragraphs, max_len)
train_iter = paddle.io.DataLoader(dataset=train_set, batch_size=batch_size, return_list=True,
shuffle=True, num_workers=0)
return train_iter, train_set.vocab
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
预训练BERT
原始BERT有两个不同模型尺寸的版本。基本模型( BERT BASE \text{BERT}_{\text{BASE}} BERTBASE)使用12层(Transformer编码器块),768个隐藏单元(隐藏大小)和12个自注意头。大模型( BERT LARGE \text{BERT}_{\text{LARGE}} BERTLARGE)使用24层,1024个隐藏单元和16个自注意头。值得注意的是,前者有1.1亿个参数,后者有3.4亿个参数。为了便于演示,我们定义了一个小的BERT,使用了2层、128个隐藏单元和2个自注意头。
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在定义训练代码实现之前,我们定义了一个辅助函数_get_batch_loss_bert。给定训练样本,该函数计算遮蔽语言模型和下一句子预测任务的损失。请注意,BERT预训练的最终损失是遮蔽语言模型损失和下一句预测损失的和。
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y): # 前向传播 _, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X, valid_lens_x.reshape([-1]), pred_positions_X) # 计算遮蔽语言模型损失 mlm_l = loss(mlm_Y_hat.reshape([-1, vocab_size]), mlm_Y.reshape([-1])) *\ mlm_weights_X.reshape([-1, 1]) mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8) # 计算下一句子预测任务的损失 nsp_l = loss(nsp_Y_hat, nsp_y) l = mlm_l + nsp_l return mlm_l, nsp_l, l
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
通过调用上述两个辅助函数,下面的train_bert函数定义了在WikiText-2(train_iter)数据集上预训练BERT(net)的过程。训练BERT可能需要很长时间。以下函数的输入num_steps指定了训练的迭代步数,而不是像CV训练里那样指定训练的轮数。
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps): trainer = paddle.optimizer.Adam(parameters=net.parameters(), learning_rate=0.01) step, timer = 0, d2l.Timer() animator = d2l.Animator(xlabel='step', ylabel='loss', xlim=[1, num_steps], legend=['mlm', 'nsp']) # 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数 metric = d2l.Accumulator(4) num_steps_reached = False while step < num_steps and not num_steps_reached: for tokens_X, segments_X, valid_lens_x, pred_positions_X,\ mlm_weights_X, mlm_Y, nsp_y in train_iter: trainer.clear_grad() timer.start() mlm_l, nsp_l, l = _get_batch_loss_bert( net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y) l.backward() trainer.step() metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1) timer.stop() animator.add(step + 1, (metric[0] / metric[3], metric[1] / metric[3])) step += 1 if step == num_steps: num_steps_reached = True break print(f'MLM loss {metric[0] / metric[3]:.3f}, ' f'NSP loss {metric[1] / metric[3]:.3f}') print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on ' f'{str(devices)}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
# 测试50step 14秒。预计50000步需要3.8小时。
train_bert(train_iter, net, loss, len(vocab), devices[:1], 50)
- 1
- 2
用BERT表示文本
在预训练BERT之后,我们可以用它来表示单个文本、文本对或其中的任何词元。下面的函数返回tokens_a和tokens_b中所有词元的BERT(net)表示。
def get_bert_encoding(net, tokens_a, tokens_b=None):
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
token_ids = paddle.to_tensor(vocab[tokens]).unsqueeze(0)
segments = paddle.to_tensor(segments).unsqueeze(0)
valid_len = paddle.to_tensor(len(tokens))
encoded_X, _, _ = net(token_ids, segments, valid_len)
return encoded_X
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
插入特殊标记“”(用于分类)和“”(用于分隔)后,BERT输入序列的长度为6。因为零是“”词元,encoded_text[:, 0, :]是整个输入语句的BERT表示。为了评估一词多义词元“crane”,我们还打印出了该词元的BERT表示的前三个元素。
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]
- 1
- 2
- 3
- 4
- 5
- 6
现在考虑一个句子“a crane driver came”和“he just left”。类似地,encoded_pair[:, 0, :]是来自预训练BERT的整个句子对的编码结果。注意,多义词元“crane”的前三个元素与上下文不同时的元素不同。证明BERT表示是上下文敏感的。
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
预训练总结
BERT针对预训练和微调设计,基于Transformer的编码器做了如下修改:
- 模型更大,训练数据更多
- 输入句子对,片段嵌入
- 可学习位置编码
- 训练时使用两个任务:
- 带掩码的语言模型
- 下一个句子预测
一句话就是:BERT使用了上面的技术,实现了自监督训练(预训练),并为后面的微调应用打好了基础。
三、BERT微调应用
有了BERT预训练模型之后,我们只需要再一个额外的多层感知机(一层或几层线性层),即可实现NLP自然语言的很多下游任务,比如情感分析,文本分类、问答系统等。
本节将下载一个预训练好的小版本的BERT,然后对其进行微调,以便在SNLI数据集上进行自然语言推断。
import warnings
from d2l import paddle as d2l
warnings.filterwarnings("ignore")
import json
import multiprocessing
import os
import paddle
from paddle import nn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
加载预训练的BERT
前面已经在WikiText-2数据集上预训练BERT(请注意,原始的BERT模型是在更大的语料库上预训练的)。原始的BERT模型有数以亿计的参数。在下面,提供了两个版本的预训练的BERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。
d2l.DATA_HUB['bert_small'] = ('https://paddlenlp.bj.bcebos.com/models/bert.small.paddle.zip', '9fcde07509c7e87ec61c640c1b277509c7e87ec6153d9041758e4')
d2l.DATA_HUB['bert_base'] = ('https://paddlenlp.bj.bcebos.com/models/bert.base.paddle.zip', '9fcde07509c7e87ec61c640c1b27509c7e87ec61753d9041758e4')
- 1
- 2
- 3
两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。我们实现了以下load_pretrained_model函数来加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens, num_heads, num_layers, dropout, max_len, devices): data_dir = d2l.download_extract(pretrained_model) # 定义空词表以加载预定义词表 vocab = d2l.Vocab() vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json'))) vocab.token_to_idx = {token: idx for idx, token in enumerate( vocab.idx_to_token)} bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256], ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens, num_heads=4, num_layers=2, dropout=0.2, max_len=max_len, key_size=256, query_size=256, value_size=256, hid_in_features=256, mlm_in_features=256, nsp_in_features=256) # 加载预训练BERT参数 bert.set_state_dict(paddle.load(os.path.join(data_dir, 'pretrained.pdparams'))) return bert, vocab
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
devices = d2l.try_all_gpus() # 这句devices赋值并没有使用,属于历史遗留问题
# 下载时间约14秒
bert, vocab = load_pretrained_model(
'bert_small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
- 1
- 2
- 3
- 4
- 5
微调BERT的数据集:SNLI数据集
对于SNLI数据集的下游任务自然语言推断,我们定义了一个定制的数据集类SNLIBERTDataset。在每个样本中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列,如下图:
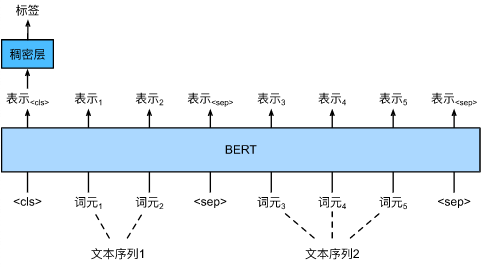
(其中的稠密层,就是我们常说的线性层)
片段索引用于区分BERT输入序列中的前提和假设。利用预定义的BERT输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足max_len。原作中为了加速生成用于微调BERT的SNLI数据集,使用4个工作进程并行生成训练或测试样本,但在AIStudio中,我们还是用单线程。
class SNLIBERTDataset(paddle.io.Dataset): def __init__(self, dataset, max_len, vocab=None): all_premise_hypothesis_tokens = [[ p_tokens, h_tokens] for p_tokens, h_tokens in zip( *[d2l.tokenize([s.lower() for s in sentences]) for sentences in dataset[:2]])] self.labels = paddle.to_tensor(dataset[2]) self.vocab = vocab self.max_len = max_len (self.all_token_ids, self.all_segments, self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens) print('read ' + str(len(self.all_token_ids)) + ' examples') def _preprocess(self, all_premise_hypothesis_tokens): # pool = multiprocessing.Pool(1) # 使用4个进程 # out = pool.map(self._mp_worker, all_premise_hypothesis_tokens) out = [] for i in all_premise_hypothesis_tokens: tempOut = self._mp_worker(i) out.append(tempOut) all_token_ids = [ token_ids for token_ids, segments, valid_len in out] all_segments = [segments for token_ids, segments, valid_len in out] valid_lens = [valid_len for token_ids, segments, valid_len in out] return (paddle.to_tensor(all_token_ids, dtype='int64'), paddle.to_tensor(all_segments, dtype='int64'), paddle.to_tensor(valid_lens)) def _mp_worker(self, premise_hypothesis_tokens): p_tokens, h_tokens = premise_hypothesis_tokens self._truncate_pair_of_tokens(p_tokens, h_tokens) tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens) token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \ * (self.max_len - len(tokens)) segments = segments + [0] * (self.max_len - len(segments)) valid_len = len(tokens) return token_ids, segments, valid_len def _truncate_pair_of_tokens(self, p_tokens, h_tokens): # 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置 while len(p_tokens) + len(h_tokens) > self.max_len - 3: if len(p_tokens) > len(h_tokens): p_tokens.pop() else: h_tokens.pop() def __getitem__(self, idx): return (self.all_token_ids[idx], self.all_segments[idx], self.valid_lens[idx]), self.labels[idx] def __len__(self): return len(self.all_token_ids)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
下载完SNLI数据集后,我们通过实例化SNLIBERTDataset类来生成训练和测试样本。这些样本将在自然语言推断的训练和测试期间进行小批量读取。
同样为了提高运行速度,我们将数据集放在work目录,并在使用前拷贝到data目录
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
# 运行耗时84秒
!cp ~/work/snli_1.0.zip ~/data
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = paddle.io.DataLoader(train_set, batch_size=batch_size, shuffle=True, return_list=True)
test_iter = paddle.io.DataLoader(test_set, batch_size=batch_size, return_list=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
微调BERT
如前面所述,用于自然语言推断的微调BERT只需要一个额外的多层感知机,该多层感知机由两个全连接层组成(请参见下面BERTClassifier类中的self.hidden和self.output)。这个多层感知机将特殊的“<cls>”词元的BERT表示进行了转换,该词元同时编码前提和假设的信息为自然语言推断的三个输出:蕴涵、矛盾和中性。
class BERTClassifier(nn.Layer):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x.squeeze(1))
return self.output(self.hidden(encoded_X[:, 0, :]))
net = BERTClassifier(bert)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
预训练的BERT模型bert被送到用于下游应用的BERTClassifier实例net中。在BERT微调的常见实现中,只有额外的多层感知机(net.output)的输出层的参数将从零开始学习。预训练BERT编码器(net.encoder)和额外的多层感知机的隐藏层(net.hidden)的所有参数都将进行微调。
我们通过该函数使用SNLI的训练集(train_iter)和测试集(test_iter)对net模型进行训练和评估。若计算资源比较充裕,训练和测试精度可以进一步提高:比如换用更大的BERT模型、使用更大的数据集以及训练更长的步数!
# 总共耗时852秒
lr, num_epochs = 1e-4, 5
trainer = paddle.optimizer.Adam(learning_rate=lr, parameters=net.parameters())
loss = nn.CrossEntropyLoss(reduction='none')
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
- 1
- 2
- 3
- 4
- 5
- 6
四、思考题:用中文数据集进行BERT预训练和微调
数据集可以参考用这个【NLP】对联数据集:https://aistudio.baidu.com/aistudio/datasetdetail/110057
也可以自行寻找其它中文语料。
基本思路:
对中文语料数据集进行处理,写成句子对的形式。相较英文语料,需要增加一个中文分词的步骤
预训练和微调跟英文语料基本一致
另外需注意对数据集进行清洗,去掉含有错别字和丢字的部分。
如果能从头开始预训练中文语料,并微调解决自己的NLP实际问题,那么大家可以自豪的说:没有人比我更懂BERT! --特朗普名言 与诸君共勉
结束语
让我们荡起双桨,在AI的海洋乘风破浪!
飞桨官网:https://www.paddlepaddle.org.cn
因为水平有限,难免有不足之处,还请大家多多帮助。
作者:段春华, 网名skywalk 或 天马行空,济宁市极快软件科技有限公司的AI架构师,百度飞桨PPDE。
我在AI Studio上获得至尊等级,点亮10个徽章,来关注我呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/141218

