
热门标签
热门文章
- 1GO开发环境配置_go环境配置
- 2多元时间序列 | BP神经网络多变量时间序列预测(Matlab完整程序)_bp神经网络时间序列预测
- 3鸿蒙os后台运行,Day10 鸿蒙,Ability全家桶(二)如何后台运行任务
- 4【资料分享】Xilinx Zynq-7010/7020工业评估板规格书(双核ARM Cortex-A9 + FPGA,主频766MHz)_zynq7010和7020的区别
- 5AI 3.0》王飞跃教授推荐序——未来智能:人有人用,机有机用
- 6JavaAgent技术解析:深入理解和使用_java agent技术
- 7Python之Sklearn使用教程_python sklearn
- 8Task05基于鸢尾花数据集的贝叶斯分类算法实践_iris鸢尾花数据集贝叶斯分类
- 9CLRNet: Cross Layer Refinement Network for Lane Detection_clrnet复现 windows
- 10python tokenizer是什么_Python tokenizer包_程序模块 - PyPI - Python中文网
当前位置: article > 正文
transformer bert seq2seq 深度学习 编码和解码的逻辑-重点_bert中的tokneize编码和解码代码
作者:从前慢现在也慢 | 2024-03-31 19:20:29
赞
踩
bert中的tokneize编码和解码代码







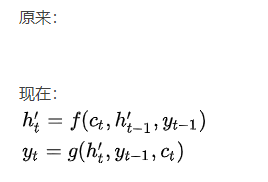














参考文献:
详解从 Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention模型
【NLP】Attention Model(注意力模型)学习总结(https://www.cnblogs.com/guoyaohua/p/9429924.html)
深度学习对话系统理论篇–seq2seq+Attention机制模型详解
论文笔记:Attention is all you need
Attention机制详解(二)——Self-Attention与Transformer
Attention 机制学习小结
20210118
seq2seq
https://blog.csdn.net/weixin_44388679/article/details/102575223
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/345856?site=
推荐阅读
相关标签

