
- 1【自然语言处理】PyTorch-Transformers预训练模型库的简单了解_pytorch_transformers
- 2深度学习之基于yolov3学生课堂行为及专注力检测预警监督系统_基于深度学习的课堂行为检测
- 3UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大内核ConvNet
- 4双非计算机学子保研(推免)985高校历程_蓝桥杯国二可以保本吗
- 5鸿蒙os后台运行,Day10 鸿蒙,Ability全家桶(二)如何后台运行任务
- 6transformer、bert总结_bert和transformer的关系
- 7vscode前后台分离Nodejs+vue校园影院售票系统_490gq
- 8云服务器Windows无损扩容_无损扩容服务器硬盘大小
- 9pytorch - contiguous函数_view libtorch contiguous
- 10基于时空注意力融合网络的城市轨道交通假期短时客流预测
什么?是Transformer位置编码
赞
踩
作者:陈安东,中央民族大学,Datawhale成员
过去的几年里,Transformer大放异彩,在各个领域疯狂上分。它究竟是做什么,面试常考的Transformer位置编码暗藏什么玄机?本文一次性讲解清楚。
Transformer的结构如下:

可能是NLP界出镜率最高的图
Transformer结构中,左边叫做编码端(Encoder),右边叫做解码端(Decoder)。大家不要小看这两个部分,其中左边的编码端最后演化成了最后鼎鼎大名的Bert,右边的解码端在最近变成了无人不知的GPT模型。从刚才的描述中,我们就可以知道Transformer这个模型对于NLP领域的影响有多大,并且这个影响力还在往其他领域扩展。
所以问题就来了,Transformer到底是干嘛的?
答:重点在Transformer的突破之一—Self-attention,可以让NLP模型做到像CV模型一样,并行输入。
在自然语言处理(NLP)领域中,模型的输入是一串文本,也就是Sequence。
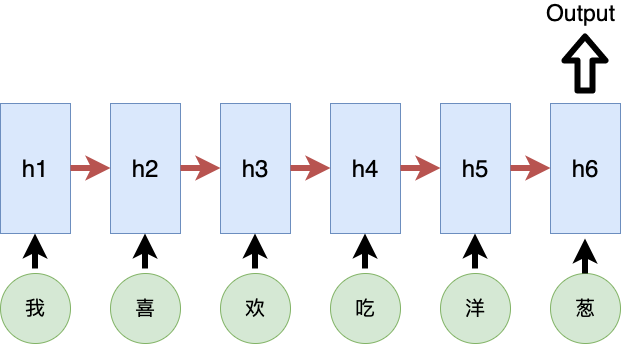
在以前的模型中,NLP的每个Sequence都是一个token一个token的输入到模型当中。比如有一句话是“我喜欢吃洋葱”,那么输入模型的顺序就是“我”,“喜”,“欢“,”吃“,”洋“,”葱”,一个字一个字的。
上面的输入方式其实就引入了一个问题。一个模型每次只吃了一个字,那么模型只能学习到前后两个字的信息,无法知道整句话讲了什么。为了解决这个问题,Transformer模型引用了Self-attention来解决这个问题。Self-attention的输入方式如下:
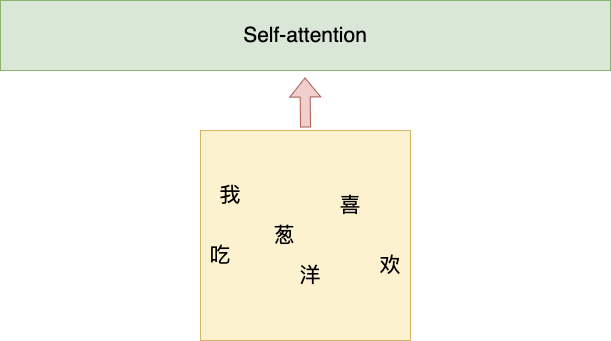
我们可以看到,对于Self-attention结果而言,它可以一次性的将所有的字都当做输入。但是NLP的输入是有特点的,其特点是输入的文本要按照一定的顺序才可以。因为,文本的顺序是带有一部分语义关系的。比如下面两句话,不同的语序就有不同的语义。
句子1:我喜欢吃洋葱
句子2:洋葱喜欢吃我
所以,对于Transformer结构而言,为了更好的发挥并行输入的特点,首先要解决的问题就是要让输入的内容具有一定的位置信息。在原论文中,为了引入位置信息,加入了Position机制。
对于Transformer而言,Position机制看似简单,其实不容易理解。这篇文章通过梳理位置信息的引入方式,然后详细讲解在Transformer中是如何做的。最后将通过数学来证明为什么这种编码方式可以引入相对的位置信息。
位置编码分类
总的来说,位置编码分为两个类型:函数型和表格型
函数型:通过输入token位置信息,得到相应的位置编码
表格型:建立一个长度为L的词表,按词表的长度来分配位置id
以前的方法-表格型
方法一:使用[0,1]范围分配
这个方法的分配方式是,将0-1这个范围的,将第一个token分配0,最后一个token分配去1,其余的token按照文章的长度平均分配。具体形式如下:
我喜欢吃洋葱 【0 0.16 0.32.....1】
我真的不喜欢吃洋葱【0 0.125 0.25.....1】
问题:我们可以看到,如果句子长度不同,那么位置编码是不一样,所以无法表示句子之间有什么相似性。
方法二:1-n正整数范围分配
这个方法比较直观,就是按照输入的顺序,一次分配给token所在的索引位置。具体形式如下:
我喜欢吃洋葱 【1,2,3,4,5,6】
我真的不喜欢吃洋葱【1,2,3,4,5,6,7】
问题:往往句子越长,后面的值越大,数字越大说明这个位置占的权重也越大,这样的方式无法凸显每个位置的真实的权重。
总结
过去的方法总有这样或者那样的不好,所以Transformer对于位置信息的编码做了改进。
相对位置的关系-函数型
相对位置编码的特点,关注一个token与另一个token距离的相对位置(距离差几个token)。位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2与位置3和位置4都只相差1。
还是按照上面"我喜欢吃洋葱"中的“我”为例,看看相对位置关系是什么样子的:

我们可以看到,使用相对位置的方法,我们可以清晰的知道单词之间的距离远近的关系。
Transformer的Position
类型
首先给一个定义:Transformer的位置信息是函数型的。在GPT-3论文中给出的公式如下:

细节:
首先需要注意的是,上个公式给出的每一个Token的位置信息编码不是一个数字,而是一个不同频率分割出来,和文本一样维度的向量。向量如下:
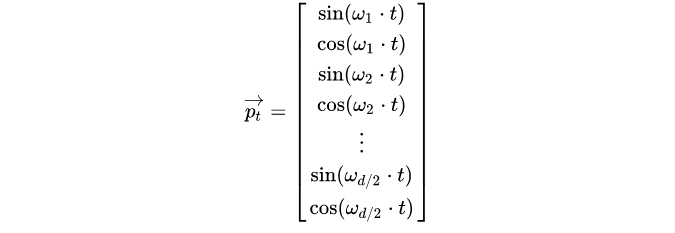
不同频率是通过
来表示的。
得到位置向量P之后,将和模型的embedding向量相加,得到进入Transformer模型的最终表示。
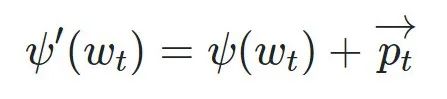
关于每个元素的说明:
① 关于 :
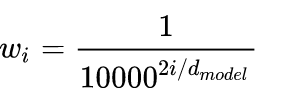
是频率
② 关于
这里的 就是每个token的位置,比如说是位置1,位置2,以及位置n
为什么可以表示相对距离?
上文说过,这样的位置信息表示方法可以表示不同距离token的相对关系。这里我们通过数学来证明。
简单复习
回顾下中学的三角函数正余弦公式:

开始证明
我们知道某一个token的位置是 ,如果某一个token表示为 ,那就表明这个位置距上一个token为 。
如果这时我们需要看看一个位置 和 这两个字符的关系。按照位置编码的的公式,我们可以计算 的位置编码,其结果如下:
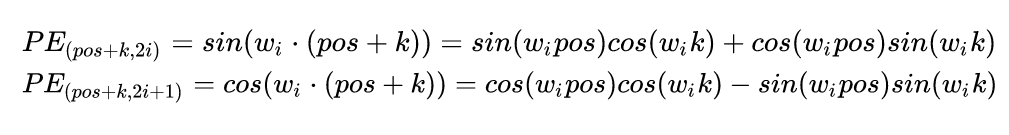
我们可以看看上面公式中,有一部分是似曾相识的:
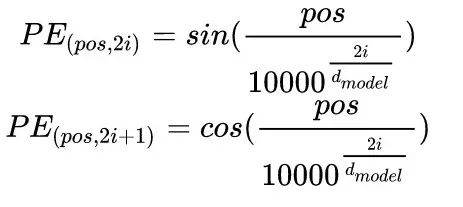
根据上面的公式我们可以看出,似曾相识的部分带入 的公式中,带入之后的结果如下:

我们可以知道,距离K是一个常数,所有上面公式中
和
的计算值也是常数,可以表示为:
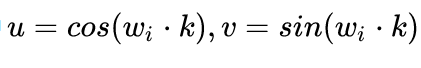
这样,就可以将
写成一个矩阵的乘法。
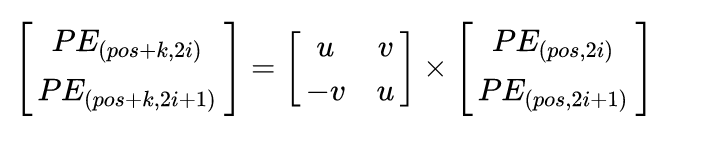
可以从上面的矩阵乘法角度看到,位置
的编码与位置
的编码是线性关系。
 那么问题来了,上面的操作也只可以看到线性关系,怎么可以更直白地知道每个token的距离关系?
那么问题来了,上面的操作也只可以看到线性关系,怎么可以更直白地知道每个token的距离关系?
为了解答上面的问题,我们将 和 相乘 (两个向量相乘),可以得到如下结果:

我们发现相乘后的结果为一个余弦的加和。这里影响值的因素就是
。如果两个token的距离越大,也就是K越大,根据余弦函数的性质可以知道,两个位置的
相乘结果越小。这样的关系可以得到,如果两个token距离越远则乘积的结果越小。
其他
这样的方式虽说可以表示出相对的距离关系,但是也是有局限的。其中一个比较大的问题是:只能的到相对关系,无法得到方向关系。所谓的方向关系就是,对于两个token谁在谁的前面,或者谁在谁的后面是无法判断的。数学表示如下:
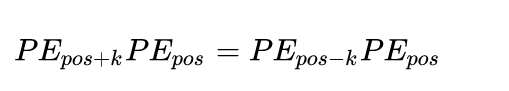
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

Reference
1.https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
2.https://zhuanlan.zhihu.com/p/121126531
3.https://timodenk.com/blog/linear-relationships-in-the-transformers-positional-encoding/
- END -








