
- 1人工智能基础知识:计算机视觉、自然语言处理、机器学习、强化学习等技术简介_计算机视觉、自然语言处理、其他
- 2MTCNN RetinaFace YoloFace_loss_kps
- 32022 年 前40道 ReactJS 面试问题和答案_jsx的面试题
- 4基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
- 5读锁和写锁(共享锁和排他锁)介绍 以及相关类 ReentrantReadWriteLock 学习总结,使用场景
- 6uniapp安卓手机无线真机调试教程_uniapp无线真机调试
- 7【AI大模型应用开发】【LangChain系列】7. LangServe:轻松将你的LangChain程序部署成服务
- 8大数据毕业设计hadoop+spark+hive+nlp知识图谱课程推荐系统 慕课在线教育课程数据分析可视化大屏 课程爬虫 文本分类 LSTM情感分析 计算机毕业设计 机器学习 深度学习 人工智能_spark、hadoop课程
- 9基于ISO13209(OTX)实现EOL下线序列_dts odx
- 10BP神经网络算法学习_bp神经网络神经元层数影响
Transformer 理解Tokenizer_transformer tokenizer
赞
踩
1.tokenizer
1.介绍
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
- 1
- 2
- 3
- 4
transformer 中tokenizer负责预处理文本, 首先会将文本分词(或比词更细的粒度subwords,标点符号…),将分词后的每个个体叫做tokens。然后会转化成一个一个id通过一个查询表(look-up table)
transformer中有三种主要的tokenizers :Byte-Pair Encoding (BPE), WordPiece, and SentencePiece
比如BertTokenizer就是用的WordPiece
对英文文本分词比想象的难,举例,对下面这句话分词

如果按照空格分词,会得到

可以看到标点符号黏在词的后面 “Transformers?” 还有“do.”
所以要将标点符号考虑进来,进行分词。

但是对于“Don’t” 这个词又没切好,最好将其切成["Do","n't"]
可以看到切词并不简单,要清楚的是每个模型都有其专属的tokenizer,分词规则。
与训练模型只有在使用相同分词规则的tokenizer时才会表现的好。
spaCy和Moses是两个主流的基于规则的分词器,使用这两个分词器进行分词的结果如下

可以看出,这里使用了空间和标点分词以及基于规则的分词。 空间和标点分词和基于规则的分词都是单词分词的示例,它们被宽松地定义为将句子拆分为单词。 虽然这是将文本分成较小块的最直观的方法,但是这种分词方法可能会导致应用在大量文本语料库时出现问题。 在这种情况下,空格和标点符号化通常会产生很大的词汇量。 例如,Transformer XL使用空间和标点符号化,因此词汇量为267,735!
如此大的词汇量迫使模型要有巨大的嵌入矩阵embedding matrix作为输入和输出层,这会增加内存和时间复杂度。 通常,转换器模型的词汇量很少会超过50,000,特别是如果仅使用一种语言进行预训练的话。
因此,如果简单的空格和标点符号的分词不能令人满意,为什么不简单地对英文字母进行分词? 尽管字母分词非常简单,并且将大大减少内存和时间的复杂性,但是它使模型学习有意义的输入表示变得更加困难。 例如。 学习字母“ t”的基于上下文的表示要比学习单词“ today”的基于上下文的表示要困难得多。 因此,字母分词通常会伴随性能下降。 因此,为了获得两全其美的效果,转换器模型在单词级和字母级分词之间使用了一种混合方式,称为subword tokenization
1.1 Subword tokenization
Subword tokenization算法基于以下原则:不应将常用词分解为较小的子词,而应将稀有词分解为有意义的子词。
例如“annoyingly”被认为是罕见词,应该将其分解为“annoying” 和“ly”,分开后的两个词,会比“annoyingly”更常见
Subword tokenization可以使模型有一个合理的词汇大小(reasonable vocabulary size )同时可以学到有意义的基于上下文的对词汇的表达(meaningful context-independent representations.)
另外,Subword tokenization 可以使得模型处理它之前没见过的词,通过将陌生词切分成已知的Subword
例如
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer.tokenize("I have a new GPU!")
- 1
- 2
- 3
注意:会将GPU这个词切分成
["i", "have", "a", "new", "gp", "##u", "!"]
因为使用的是uncased model,uncased model的意思是,单词首字母都小写的模型,可以看到,前面的词都正常分词出来

但gpu 这个词并没有正常分词出来,而是分成了

##的意思是后一个词应该跟前一个词黏在一起,且没有空格(用于解码和分词的逆转)
举另一个例子,用到XLNetTokenizer
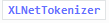
from transformers import XLNetTokenizer
tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
tokenizer.tokenize("Don't you love 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/347503Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

