
- 1零基础学习Alfred(二)——常用功能和设置_aflred 设置迁移
- 2Flink 是如何保证 Exactly-once语义的?_flink 的 exactlyonce 语义怎么保证
- 3TimesNet处理UEA数据集,用在InceptionTime上
- 4第01课:中文自然语言处理的完整机器处理流程
- 5Android MediaPlayer整体架构源码分析 -【MediaCodec编解码器插件模块化注册和创建处理流程】【Part 2-B】_blocks-per-second
- 6Twin-Builder — 系统级多物理域数字孪生平台_twim builder 模块拼接
- 7python用于人工智能的例子,python人工智能有趣例子_python人工智能案例
- 8爬虫-基于python的旅游数据可视化-计算机毕业设计源码81319_python旅游数据可视化
- 9生产制造园区数字孪生3D大屏展示提升运营效益_可视化大屏实现3d效果的技术有哪些?
- 10启信宝商业大数据助力全国经济普查
大语言模型的代码生成能力前沿追踪(2023年7月)_grounded copilot: how programmers interact with co
赞
踩
1 背景
为了解基于大语言模型的代码生成的能力和原理,对关键的原始论文进行阅读和总结。
论文阅读原则:
-
在大模型生成代码领域,具有代表性的奠定论文
-
能说清楚最新前沿情况的最新论文
1.1 国外研究现状
“AI 助手”与程序员并肩工作的想法存在于我们的想象几十年了,它催生了来自编程语言[Ferdowsifard et al. 2020; Miltner et al. 2019; Ni et al. 2021; Raychev et al. 2014]和机器学习[Guo et al. 2021; Kalyan et al. 2018; Xu et al. 2020]社区的大量工作。由于大型语言模型(LLMs) [Li et al. 2022; Vaswani et al. 2017]的最新突破,这个梦想变得接近了。OpenAI的Codex模型[Chen et al. 2021]包含120亿个模型参数,训练了GitHub上5400万个软件库,能够正确解决30-70%的常规的Python问题,而DeepMind的AlphaCode [Li et al. 2022]在竞争性编程平台Codeforces上排名前54.3%,超过了5000名人类程序员。凭借这种令人印象深刻的表现,大型代码生成模型正在迅速逃离研究实验室,为工业编程助手工具提供动力,例如Github Copilot [Friedman 2021]。
2 代表性的论文工作
2.1 OpenAI 的 Codex(2021)
2.1.1 概述
论文地址:Evaluating Large Language Models Trained on Code
论文摘要:
Codex是一种GPT语言模型,它是在GitHub上公开可用的代码上进行了微调,研究了它的Python代码编写能力。Codex的生产版本驱动GitHub Copilot。在我们发布的新评估集HumanEval中,我们用于从docstrings合成程序的模型解决了28.8%的问题,而GPT-3解决了0%,GPT-J解决了11.4%。此外,我们发现从模型中重复采样是一种出人意料的有效策略,可用于生成解决难题的工作方案。使用这种方法,我们每个问题使用100个样本解决了70.2%的问题。对我们模型的仔细调查揭示了其局限性,包括难以描述长操作链的docstrings以及将操作绑定到变量上。最后,我们讨论了部署强大的代码生成技术可能带来的潜在广泛影响,涵盖安全、安全和经济方面。
这篇论文是关于评估在代码上训练的大型语言模型的。论文介绍了Codex,这是一个在GitHub上公开可用的代码上进行微调的GPT3语言模型,并研究了它的Python代码编写能力。Codex的生产版本为GitHub Copilot提供支持能力。
论文研究的动机:
由于考虑到大语言模型通常很难在没有经过学习的数据集中表现良好,而 GPT3 的训练数据中比较少包含代码数据,因此,论文作者决定基于 GPT3 上做代码的微调。另外一方面,作者们认为代码生成有广阔的应用前景,该问题值得被研究。
| 项目 | OpenAI Codex | 备注 |
| 大语言模型 | GTP3 | |
| 验证数据集 | HumanEval dataset | OpenAI 研究人员自行构造的 164 个比较常规的编程任务。 164 original programming problems with unit tests. https://www.github.com/openai/human-eval |
| 训练数据来源 | 54 million public software repositories hosted on GitHub 经过清洗后,159 GB 的程序文件。 | |
| 输入和输出格式 | 输入:程序函数的注释 输出:程序代码 | |
| 训练方式 | 针对 GPT3 进行微调 | |
| 应用场景 | Github Copilot | |
| 局限性 | 注释输入不能太长 |
2.1.2 论文验证结论
PASS @ K 是指给定编程任务,生成 K 程序结果后通过的概率,常规情况下,我们认为一次生成一次做对的能力更有说服力,论文中提到生成 10 和 100 个带有一定随机的程序结果,并且其中至少有一个能通过的概率。
| 模型版本 | 描述 | 参数规模 | 数据集的验证结果 PASS@1 | 备注 |
| Codex | 基于编程数据集微调(Fine-tuning)后的 Codex | 120 亿 | 28% | 基于GPT3 |
| 原始GTP3 | 未经过微调的原始 GPT3 | 1750 亿 | 0% | GPT3 并未刻意学习过程序代码 |
| GPT-Neo | 2021 年另外一个研究 | 27 亿 | 6.4% | |
| GPT-J | 2021 年另外一个研究 | 60亿 | 11.62% |

2.1.3 随着大语言模型规模的扩大,模型生成代码的准确率持续上升
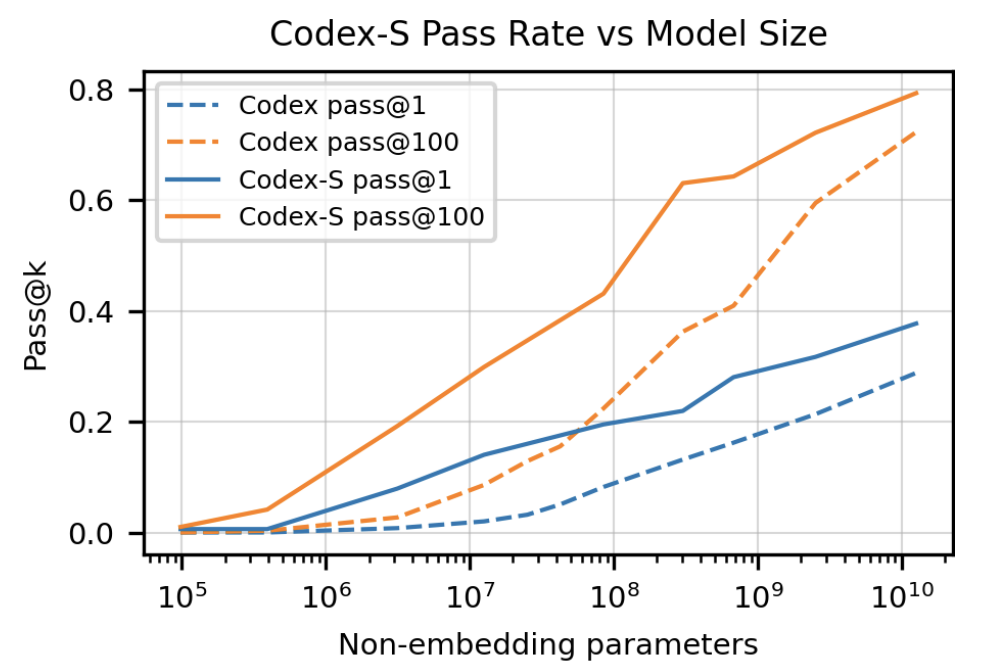
虽然code generation 的效果随着模型规模的上升而上升,但是,它们之间并非线性相关,参数规模上升一个数量级,正确率只会上升一点点。
2.1.4 论文小结
-
HumanEval 的任务比较简单,即使在这样简单的任务中,一次生成正确程序的概率只有 28.8%。对于程序员来说,帮助很有限。
-
原始的大语言模型并未学习过 code generation 任务,其效果会比较差,必须进行微调。
-
虽然code generation 的效果随着模型规模的上升而上升,但是,它们之间并非线性相关,参数规模上升一个数量级,正确率只会上升一点点。
2.2 DeepMind(Google) 的 AlphaCode(2022)
2.2.1 概述
论文地址:Competition-level code generation with alphacode
摘要:
编程是一种强大而普遍的问题解决工具。开发能够协助程序员甚至独立生成程序的系统可以使编程更具生产力和可访问性,但迄今为止,将AI创新纳入其中已经证明是具有挑战性的。最近的大规模语言模型展示了生成代码的令人印象深刻的能力,现在能够完成简单的编程任务。然而,这些模型在评估需要超出简单将指令转换为代码的问题解决技能的更复杂、未知问题时仍表现不佳。例如,需要理解算法和复杂自然语言的竞争性编程问题仍然极具挑战性。为了解决这一差距,我们引入了AlphaCode,一个用于代码生成的系统,可以创建这些需要更深入推理的问题的新颖解决方案。在Codeforces平台上最近的编程比赛的模拟评估中,AlphaCode在超过5,000名参赛者的比赛中平均排名前54.3%。我们发现,要实现良好且可靠的性能,有三个关键组成部分:(1)用于培训和评估的广泛而干净的竞争性编程数据集,(2)大型且高效采样 Transformer 架构,以及(3)大规模模型采样以探索搜索空间,然后根据程序行为过滤到一小部分提交。
AlphaCode是 DeepMind 发布的一个代码生成系统,也是基于 Transformer 架构,它在Codeforces平台上的编程竞赛中获得了平均排名为Top 54.3%的成绩。
相比于 Codex,它支持更长的文档输入,生成更复杂的代码(竞赛级的代码)。这篇论文在媒体传播上有一个标题“打败一半的程序员”(就是一个标题党!)。
| 项目 | OpenAI Codex |
| 模型 | 基于 Transformer 架构的模型 |
| 验证数据集 | 竞赛题目 |
| 训练数据来源 | 54 million public software repositories hosted on GitHub 包含的语言:C++, C#, Go, Java, JavaScript, Lua, PHP, Python, Ruby, Rust, Scala, and TypeScript 来自开源的 Github 代码,经过清洗后,159 GB 的程序文件。 除此之外,模型还专门针对竞赛题目进行了额外的fine-turning 训练(CodeContests 数据集) |
| 输入和输出格式 | 输入:程序函数的注释 输出:程序代码 |
| 训练方式 | - |
| 应用场景 | - |
2.2.2 推理模型的输入和输出
竞赛题目的输入:

输出为编程程序:

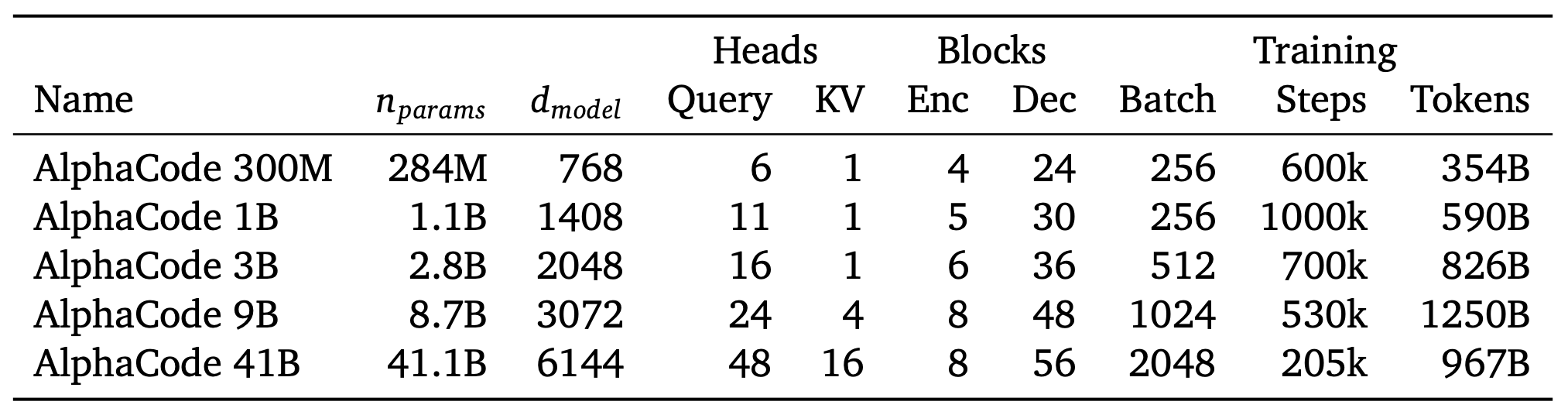
2.2.3 模型架构

超参数设置:
n(Params):模型的参数规模,最高达到 410 亿
d(dimension):token 的向量维度数,d指 dimension
Query、KV(Key、Value)、Enc(Encode,编码)、Dec(Decode,解码):Transformer 架构内的超参数
Batch:训练的 Batch 大小
Steps:训练步数
Tonkens:自然语言的拆解最小单位
2.2.4 模型验证结果

2.2.5 论文小结
该论文虽然号称在编程竞赛中击败了 50% 的人类,实际上,该表述存在一定的水分:
-
模型生成 1000 个程序,选取得分最高的 10 个程序结果提交到验证程序,通过率最高只有 16.4%。
-
在实际的编程竞赛中,频繁提交是会被罚分的。
-
程序员在实际的开发过程中,不太可能让模型提供 1000 个程序的排序结果,然后让程序员选择,程序员阅读这些程序就要耗费不少时间,这种模式的实际研发效率比较低。这也解释了为什么给 GitHub Copilot 写一个代码注释,它会提供好几个代码版本让程序员选择。
2.3 北京大学的 TIP(2023.5)
2.3.1 概述
论文原文:Enabling Programming Thinking in Large Language Models Toward Code Generation
摘要:
大型语言模型(LLMs)(例如ChatGPT)在代码生成方面表现出了令人印象深刻的性能。一项大规模研究表明,编写程序需要编程思维,即分析和实现编程逻辑中的要求(例如,顺序、分支、循环)。现有研究使用LLMs直接从要求生成程序,而不明确介绍编程思维。本文探讨如何在代码生成中解锁LLMs的编程思维,并提出了一种名为TIP的方法。我们的想法是将代码生成分解为两个步骤,并逐步引导LLMs分析和实现编程逻辑中的要求。具体而言,TIP首先生成一个代码草图,该草图使用编程逻辑提供高级解决方案,但省略了实现细节(例如API)。然后,TIP使用特定的编程语言将草图实现为程序。
我们在三个公共基准测试(即HumanEval、MBPP和MBCPP)上进行了广泛的实验。(1) TIP在Pass@1、Pass@3和Pass@5方面的表现优于最先进的基线-ChatGPT,分别提高了17.5%、11.02%和9.84%。(2) 人类评估显示,TIP在三个方面(即正确性、代码质量和可维护性)方面优于ChatGPT。(3) TIP对不同的LLMs有效。(4) 我们探讨了多种选择(例如思路链)的代码草图,并验证了我们设计的优越性。(5) 我们讨论了TIP与后处理方法(例如CodeT)之间的互补性。
选取阅读的原因:
论文发表于 2023 年 5 月,比较新,它包含了过往三年的 code generation 的方法的总结和对比,并且提出了一个比较特别的代码生成思路。
模型关键信息
| 项目 | OpenAI Codex | 备注 |
| 模型 | 基于 Transformer 架构的模型 | |
| 验证数据集 |
| 验证集比较简单。 |
| 训练数据来源 | ||
| 输入和输出格式 | 见下文 | |
| 训练方式 | - | |
| 应用场景 | - |
|
2.3.2 模型架构
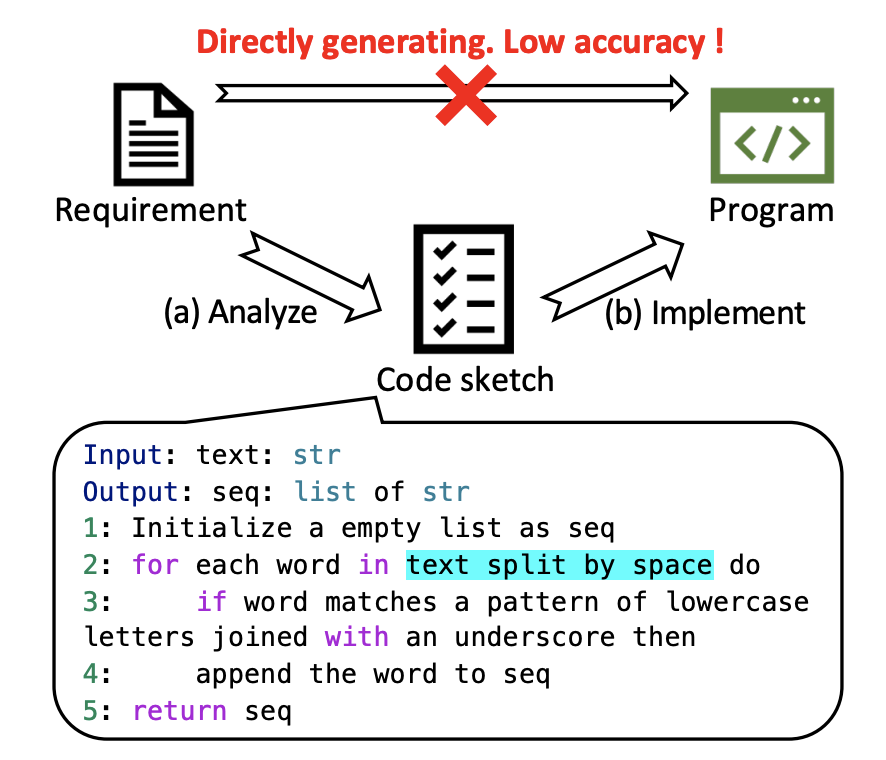
将代码生成拆解成两段:
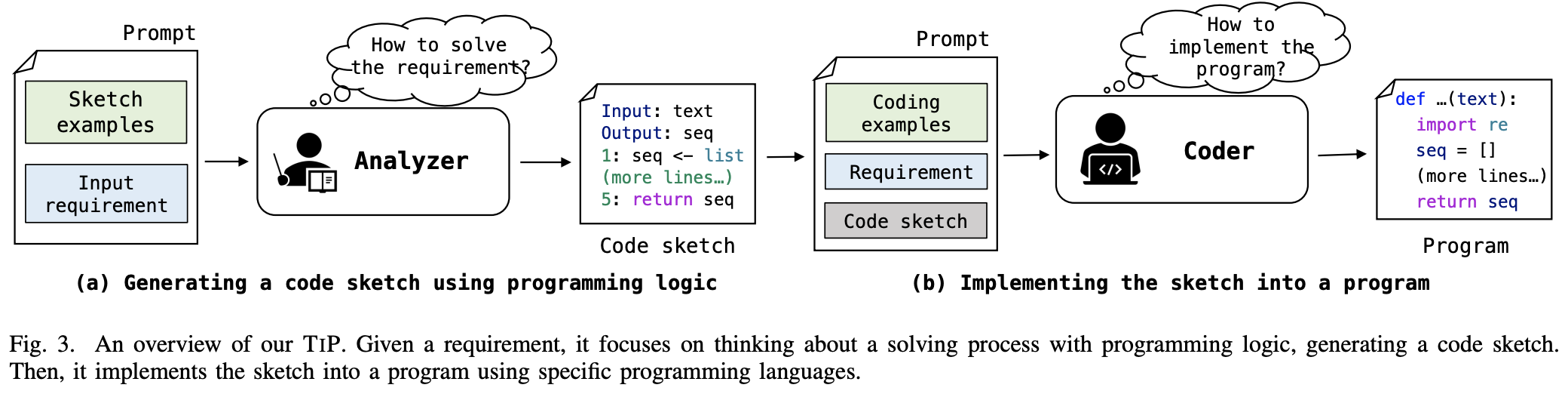
输入和输出:

2.3.3 论文验证结论
该论文发表于 2023 年 5 月,几乎是最新的关于 code generation 论文,它包含了最近三年各个 code generation 模型的效果对比,我们采用最基准的 HumanEval 作为基准验证集,可看见,即使在拆解步骤的情况下,一次生成的代码正确率也仅有 60%,ChatGPT(3.5)非步骤拆解的方式,一次生成正确代码的正确率也仅有 52%,但是,其参数规模已经高达 1750 亿。

根据前文可知,虽然模型的参数规模扩大,代码的正确率会持续上升,但是,它们之间并非线性相关,通常是模型的参数提高一个数量级,代码生成的准确率只能提高 5-10% 。而且,该验证集仍然只是比较简单的编程任务。
3 总结
-
常规大语言模型并未专门针对编程语言进行学习,它并不擅长代码生成,因此,针对代码通常需要进行专门的微调(fine-turning),甚至专门训练面向代码的大模型。
-
从模型的原理、现状看,大模型在短时间内取代程序员并不现实,任重道远。即使面对比较简单的编程任务(HumanEval),ChatGPT 一次生成正确的概率也只有 52%,2023 年 5 月最 SOTA 的方法能达到 60%。在可预见的未来,AI 仍然只能扮演辅助编程的角色。
-
模型参数规模越大,越有利于提高程序生成的准确率,但是,这种大力出奇迹的方法,需要耗费的计算成本也较高。通常是模型的参数提高一个数量级,代码生成的准确率只能提高 5-10% 。以此进行粗略推算,模型参数规模达到 10 万亿级别(相比 ChatGPT3.5 提高 100 倍),利用最前沿的方法,又或者算法本身获得极大的突破,才有机会在简单任务中达到 90% 的一次生成正确率。
(篇幅所限,没有展开具体原理,对具体原理、数学公式感兴趣的同学,可点击原始论文哈)
4 参考文献
Code generation 系列论文:
Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.
Li Y, Choi D, Chung J, et al. Competition-level code generation with alphacode[J]. Science, 2022, 378(6624): 1092-1097.
Wang Y, Wang W, Joty S, et al. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation[J]. arXiv preprint arXiv:2109.00859, 2021.
Barke S, James M B, Polikarpova N. Grounded copilot: How programmers interact with code-generating models[J]. Proceedings of the ACM on Programming Languages, 2023, 7(OOPSLA1): 85-111.
Li J, Li G, Li Y, et al. Enabling Programming Thinking in Large Language Models Toward Code Generation[J]. arXiv preprint arXiv:2305.06599, 2023.
GPT 系列的论文(分别为 ChatGPT 1、2、3、3.5、4):
Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
OpenAI R. GPT-4 technical report[J]. arXiv, 2023: 2303.08774.

