
- 1python 爬取视觉中国网站_视觉中国图片抓取网站
- 2SpringBoot微服务项目Maven打包瘦身,每个模块依赖的库打包到同一个lib目录_springboot多个项目公用一个lib包
- 3基于Python+Django框架在线考试系统设计与实现
- 4【AI】如何用AI生成XMind思维导图_自动生成xind
- 5【毕业设计】6-基于51单片机的电子称重装置/电子测温/压力测试控制系统设计(原理图+源码+仿真工程+论文+PPT)_mcu外设压力测试
- 6Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练_语义对齐 细粒度
- 7arcgis api 弹窗结合echarts可视化_arcgis 弹窗 echarts 折线图
- 8python - 动物识别产生式系统实验_动物识别系统python
- 9Graph Neural Network-Based Anomaly Detection in Multivariate Time Series 代码配置及解析_msl数据集
- 10京东商品评论数据爬虫,包含对数据的采集、清洗、可视化、分析等过程,作为数据库课程设计项目
【LLM】本地部署Gemma模型(图文)_gemma 代码生成
赞
踩
工具简介
我们需要使用到两个工具,一个是Ollama,另一个是open-webui。
Ollama
Ollama 是一个开源的大语言平台,基于 Transformers 和 PyTorch 架构,基于问答交互方式,提供大语言模型常用的功能,如代码生成、文本生成、数据分析等。
Ollama 的优势:
- 开源: 免费使用,无需付费。
- 易用: 简易的操作,无需复杂的代码或配置。
- 功能强大: 提供广泛的功能,以满足各种需求。
- 性能良好: 使用 PyTorch 和 Transformers 架构,可以实现快速和高效的模型训练。
Ollama 的局限性:
- 模型规模限制: 与其他大语言模型(Chat GPT3.5、Chat GPT4等)相比,模型规模可能相对较小。
- 数据集限制: 不支持所有数据集,特别是在特定领域的数据。
总体来说,Ollama 是一个强大的开源大语言平台,提供广泛的功能和良好的性能,适合各种任务。
open-webui
简单来讲,可以理解为Ollama的web ui。
机器配置
借助于**Ollama,开源大模型也可以通过CPU来运行,GPU会更快,且支持三大主流平台。**使用显卡要求显存6GB以上,对磁盘要求磁盘至少4GB,此外还要预留出模型存放的空间,如这里Gemma 7B模型约5.2GB。
⚠️如果使用显卡运行,安装之前需要检查显卡驱动是否存在。
配置步骤
⚠️本教程基于Ubuntu 22.04系统。
安装Ollama
这里介绍两种方式安装,及直接安装和在docker上安装,建议docker安装。
直接在机器上安装
-
去Ollama网址下载并安装Ollama。
 根据自己需要下载对应的操作系统版本,这里使用的ubuntu,直接复制如下命令到ubuntu上执行即可。
根据自己需要下载对应的操作系统版本,这里使用的ubuntu,直接复制如下命令到ubuntu上执行即可。curl -fsSL <https://ollama.com/install.sh> | sh
-
安装过程及其结果截图
-
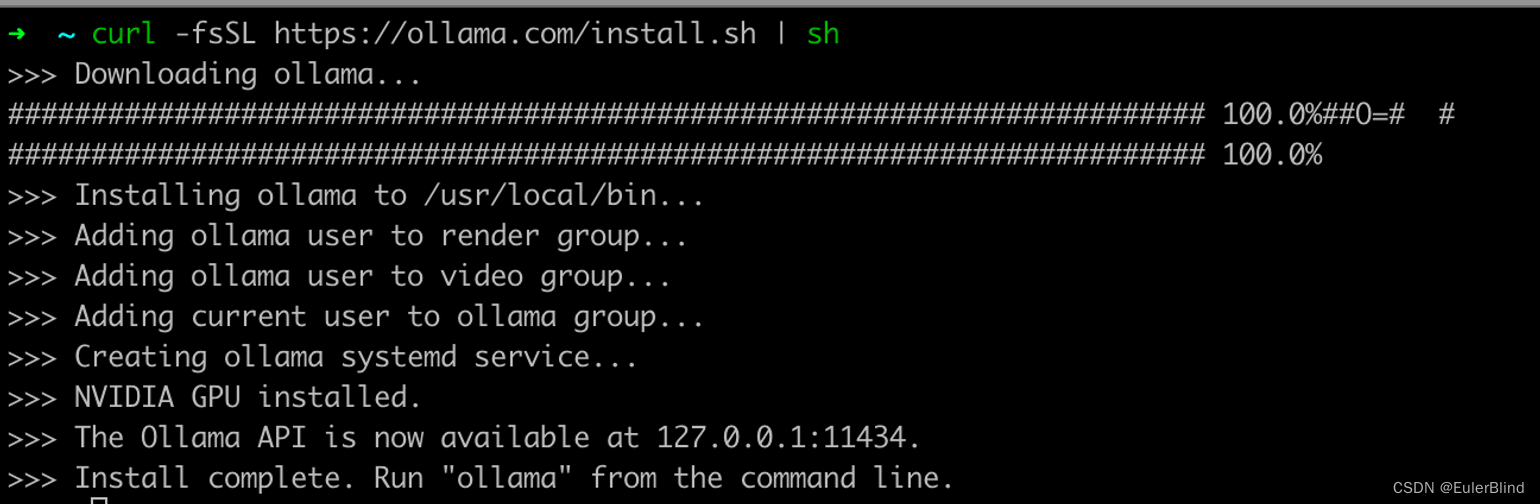 记住这里的访问链接
记住这里的访问链接127.0.0.1:11434
使用docker 安装
创建网络
docker network create ollama
由于要使用到显卡,所以这里直接用命令跑
docker run -d --gpus=all -v /opt/ollama:/root/.ollama --network ollama -p 11434:11434 --name ollama --restart always ollama/ollama
如果出现了如下提示
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
通过如下方式解决docker调用显卡问题,然后再使用上述命令启动ollama服务。
- curl -fsSL <https://nvidia.github.io/libnvidia-container/gpgkey> \\
- | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
- curl -s -L <https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list> \\
- | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \\
- | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- sudo apt-get update
-
- sudo apt-get install -y nvidia-container-toolkit
-
- sudo systemctl daemon-reload
- sudo systemctl restart docker
安装open-webui
安装open-webui很简单,这里会使用到docker,docker的安装教程这里就不给了。使用命令安装。
docker run -d --network host -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui
也可以使用如下docker-compose文件来安装,⚠️这里ollama使用容器安装的。如果使用宿主机直接安装,建议直接用host模式。
- version: '3.8'
-
- services:
- open-webui:
- image: ghcr.io/open-webui/open-webui
- container_name: open-webui
- ports:
- - "3000:8080"
- volumes:
- - /data/open-webui:/app/backend/data
- restart: always
- networks:
- - ollama
-
- networks:
- ollama:
- external: true

配置模型
访问 服务器地址:3000 (如果使用host模式,请访问8080端口),进入登陆界面。
open-webui 首次登陆,需要自行注册管理员账号
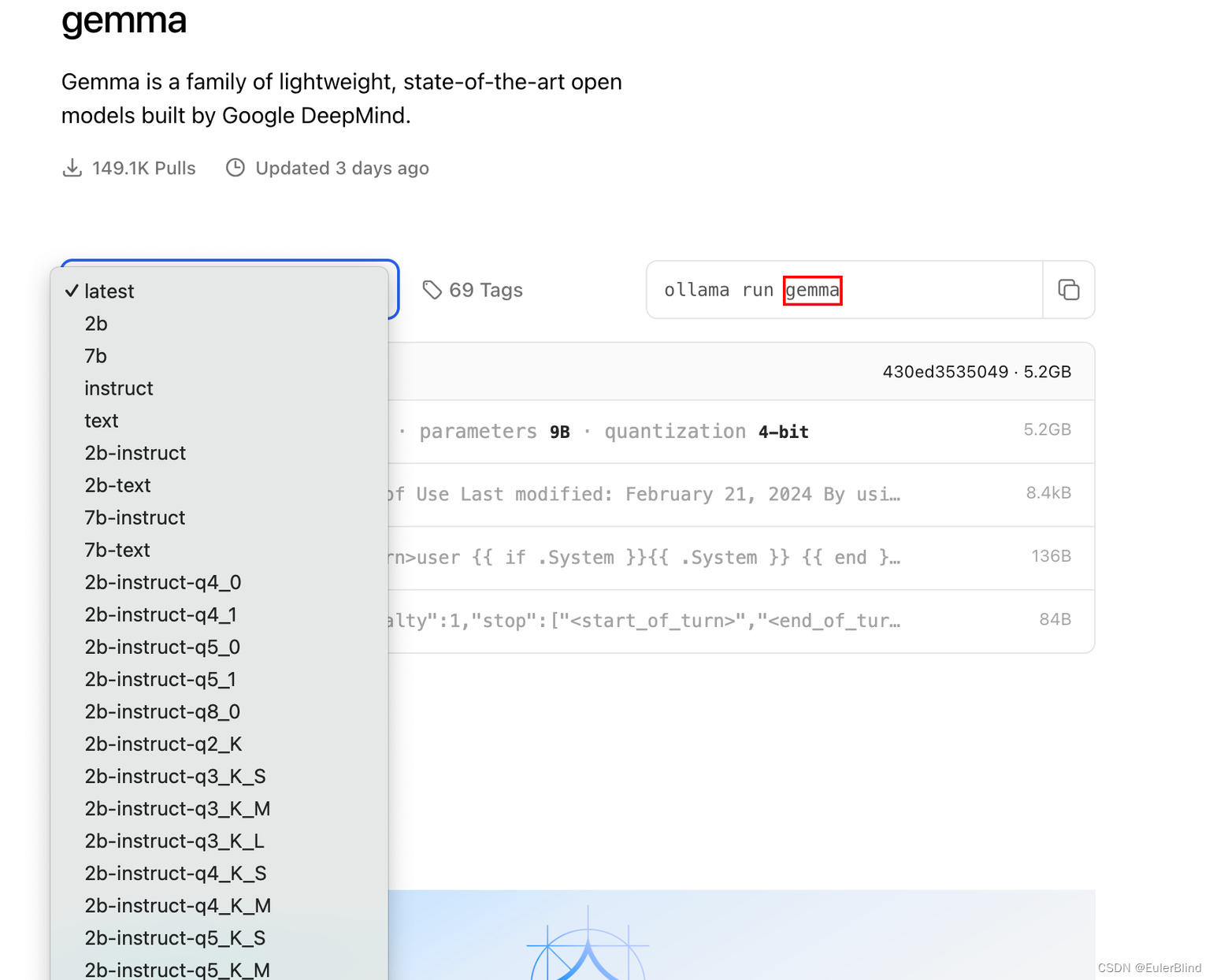
登陆后,我们就可以下载模型了,先去ollama确定需要下载的模型编码,这里以gemma模型为例。
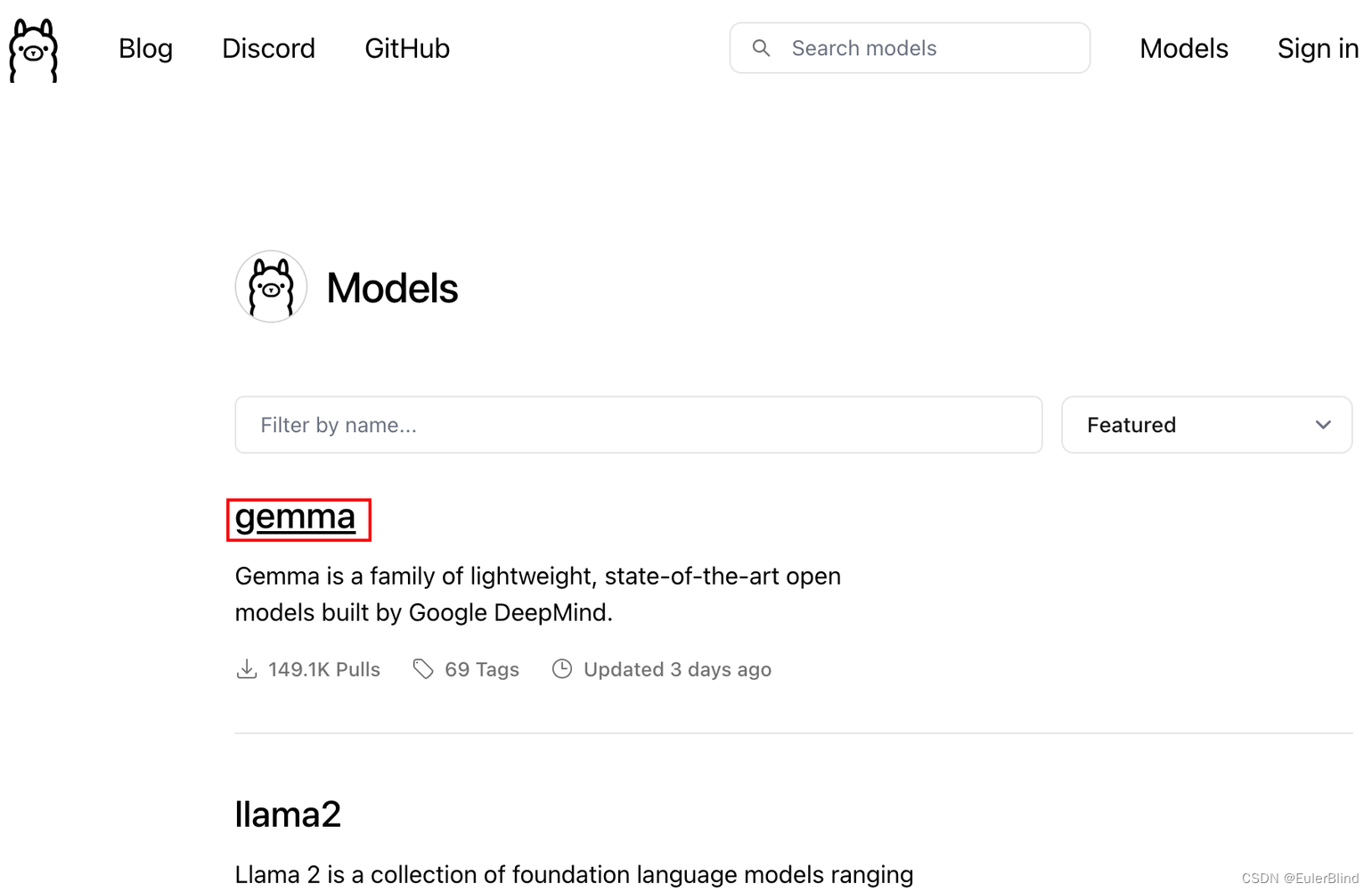 复制模型名称及其版本
复制模型名称及其版本
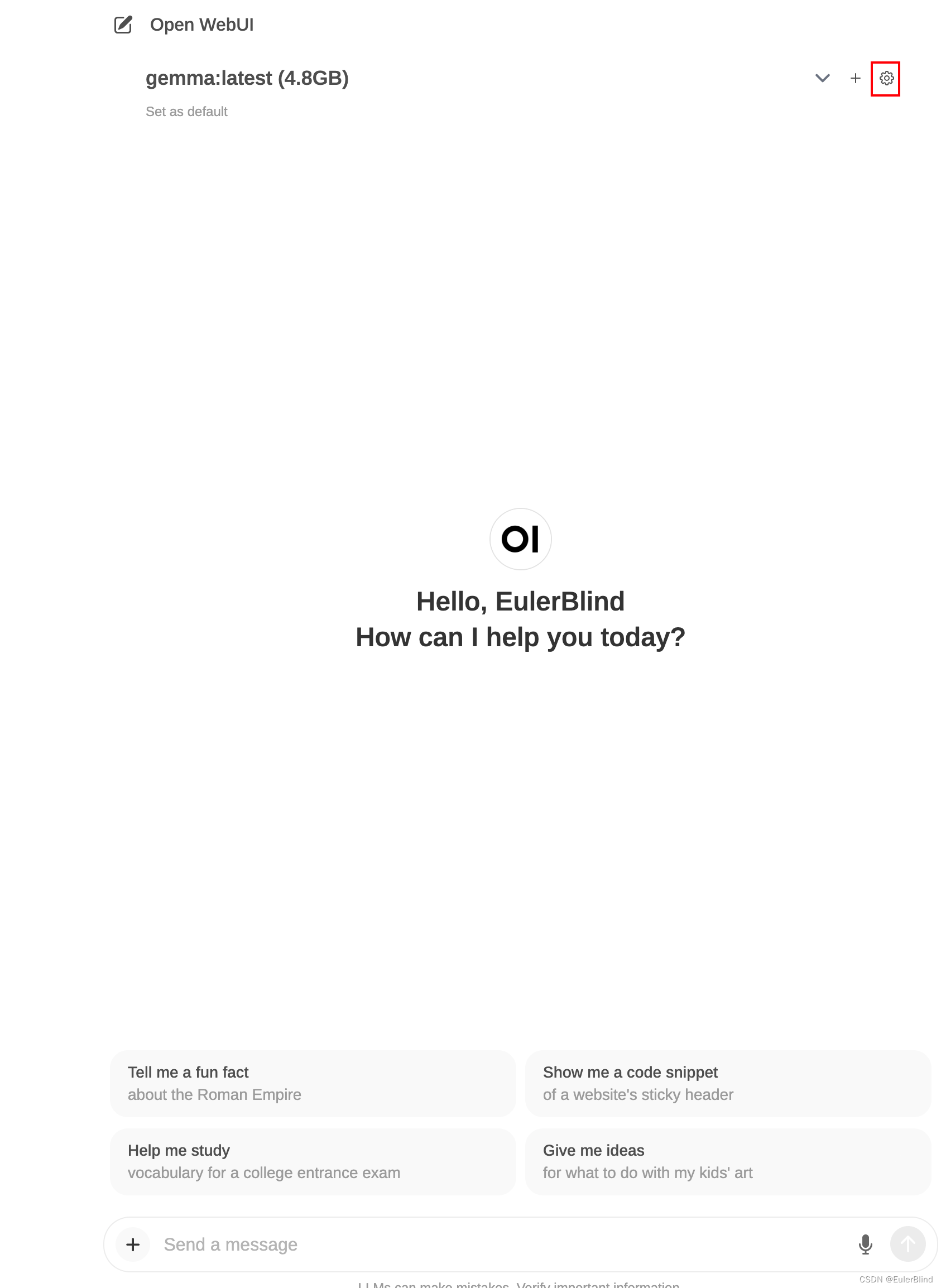
 点击如下按钮(忽略这里已经下载好的模型),进入设置界面
点击如下按钮(忽略这里已经下载好的模型),进入设置界面
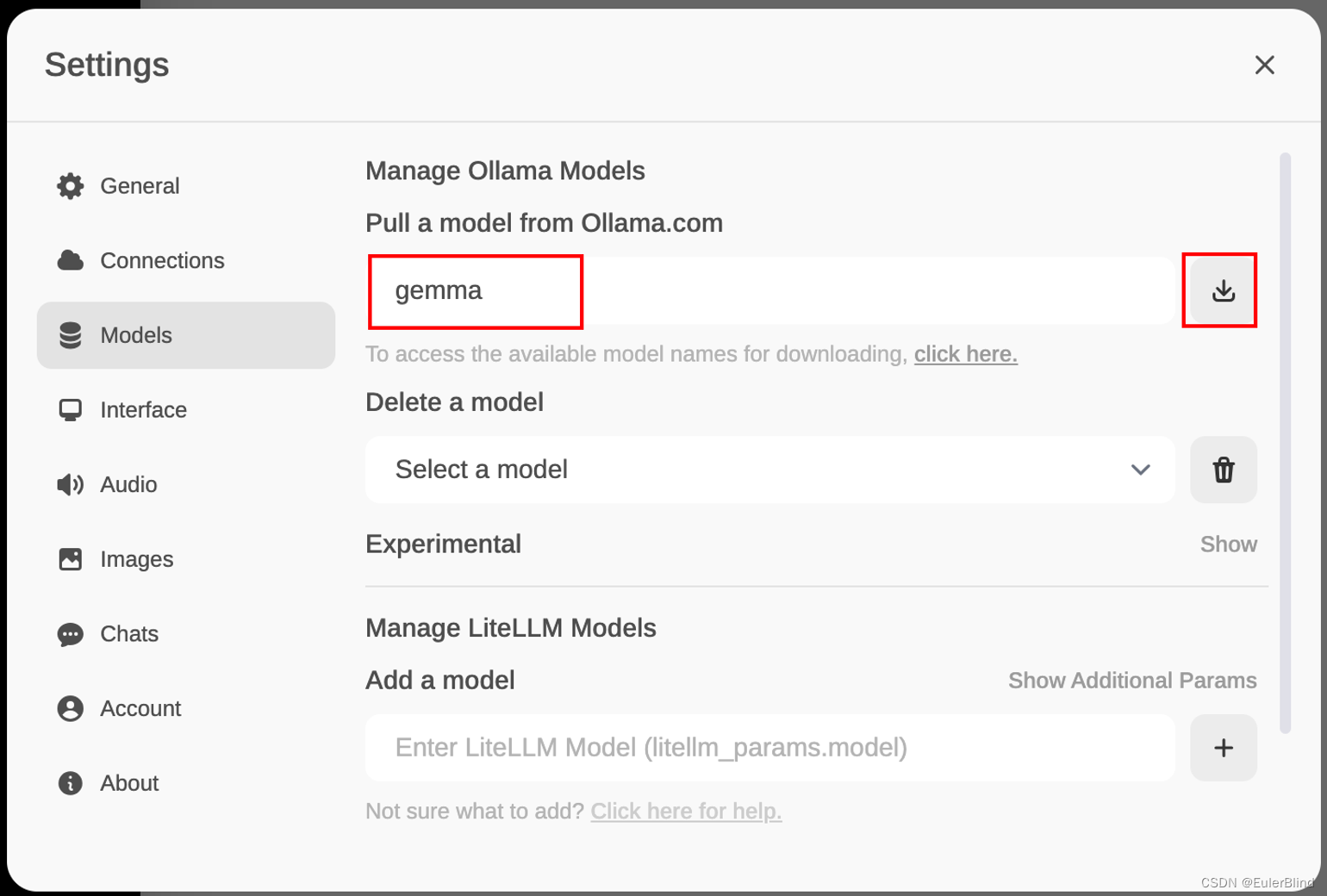
填入ollama后台然后点击下载,等待模型下载完毕(这里最好有科学环境,不然会很慢)
⚠️:ubuntu环境下直接安装情况下,默认模型路径为 /usr/share/ollama/.ollama
 下载完成后,即可选择相应的模型进行对话。
下载完成后,即可选择相应的模型进行对话。

