
- 1OpenAI 为 GPT-3.5 Turbo 推出微调功能 (fine-tuning)_fine-tuning openai's gpt 3.5 for langchain agents
- 2华为鸿蒙系统支持什么手机_什么样的手机可以刷鸿蒙系统?看看你的手机支持吗?...
- 3安卓连接java_从零学习安卓自动化(java+appium方向):手机连接Appium(二)
- 4基于FPGA的UDP协议栈设计第四章_UDP层设计
- 5yolov5训练高精度非机动车驾驶检测_非机动车数据集
- 6modelsim仿真验证后,修改代码,不用重新关闭打开的调试技巧_modelsim仿真改原文件后
- 7【证明】对极几何:本质矩阵内在性质_本质矩阵的内在性质
- 8Unity开发(六) Prefab加载自动化管理引用计数管理器_unity assetbundle 和 gameobject的 引用计数
- 9怎么样去处理样本不平衡问题 | (文后分享大量检测+分割框架)
- 10【无人机综合题】+题解
通义千文大模型API调用示例(python)_通义千问api上下文 python
赞
踩
API详情
通义千问是阿里云自主研发的大语言模型,能够在用户自然语言输入的基础上,通过自然语言理解和语义分析,理解用户意图,在不同领域、任务内为用户提供服务和帮助。您可以通过提供尽可能清晰详细的指令,来获取更符合您预期的结果。
模型具备的能力包括但不限于:
- 创作文字,如写故事、写公文、写邮件、写剧本、写诗歌等
- 编写代码
- 提供各类语言的翻译服务,如英语、日语、法语、西班牙语等
- 进行文本润色和文本摘要等工作
- 扮演角色进行对话
- 制作图表
通义千问以用户以文本形式输入的指令(prompt)以及不定轮次的对话历史(history)作为输入,返回模型生成的回复作为输出。在这一过程中,文本将被转换为语言模型可以处理的token序列。Token是模型用来表示自然语言文本的基本单位,可以直观的理解为“字”或“词”。对于中文文本来说,1个token通常对应一个汉字;对于英文文本来说,1个token通常对应3至4个字母或1个单词。例如,中文文本“你好,我是通义千问”会被转换成序列[‘你’, ‘好’, ‘,’, ‘我’, ‘是’, ‘通’, ‘义’, ‘千’, ‘问’],而英文文本"Nice to meet you."则会被转换成[‘Nice’, ’ to’, ’ meet’, ’ you’, ‘.’]。
目前(2023-12-15)API调用免费,具体截止时间还没有通知,大家赶快尝试一下!!!
官网文档:点击查看
模型概览
| 模型名 | 模型简介 | 模型输入输出限制 |
|---|---|---|
| qwen-turbo | 通义千问超大规模语言模型,支持中文英文等不同语言输入。 | 模型支持 8k tokens上下文,为了保障正常的使用和输出,API限定用户输入为6k tokens。 |
| qwen-plus | 通义千问超大规模语言模型增强版,支持中文英文等不同语言输入。 | 模型支持 32k tokens上下文,为了保障正常的使用和输出,API限定用户输入为 30k tokens。 |
| qwen-max (限时免费开放中) | 通义千问千亿级别超大规模语言模型,支持中文英文等不同语言输入。随着模型的升级,qwen-max将滚动更新升级,如果希望使用稳定版本,请使用qwen-max-1201。 | 模型支持 8k tokens上下文,为了保障正常的使用和输出,API限定用户输入为6k tokens。 |
| qwen-max-1201 (限时免费开放中) | 通义千问千亿级别超大规模语言模型,支持中文英文等不同语言输入。该模型为qwen-max的快照稳定版本,预期维护到下个快照版本发布时间(待定)后一个月。 | 模型支持 8k tokens上下文,为了保障正常的使用和输出,API限定用户输入为6k tokens。 |
| qwen-max-longcontext (限时免费开放中) | 通义千问千亿级别超大规模语言模型,支持中文英文等不同语言输入。 | 模型支持 30k tokens上下文,为了保障正常的使用和输出,API限定用户输入为 28k tokens。 |
| qwen-vl-plus | 通义千问VL plus支持灵活的交互方式,包括多图、多轮问答、创作等能力的模型,大幅提升了图片文字处理能力,增加可处理分辨率范围,增强视觉推理和决策能力 | - |
开通DashScope并创建API-KEY
API-KEY创建说明
说明:需要通过阿里云主账号或者得到主账号AliyunDashScopeFullAccess授权的子账号进行DashScope模型服务的开通及API-KEY的创建。
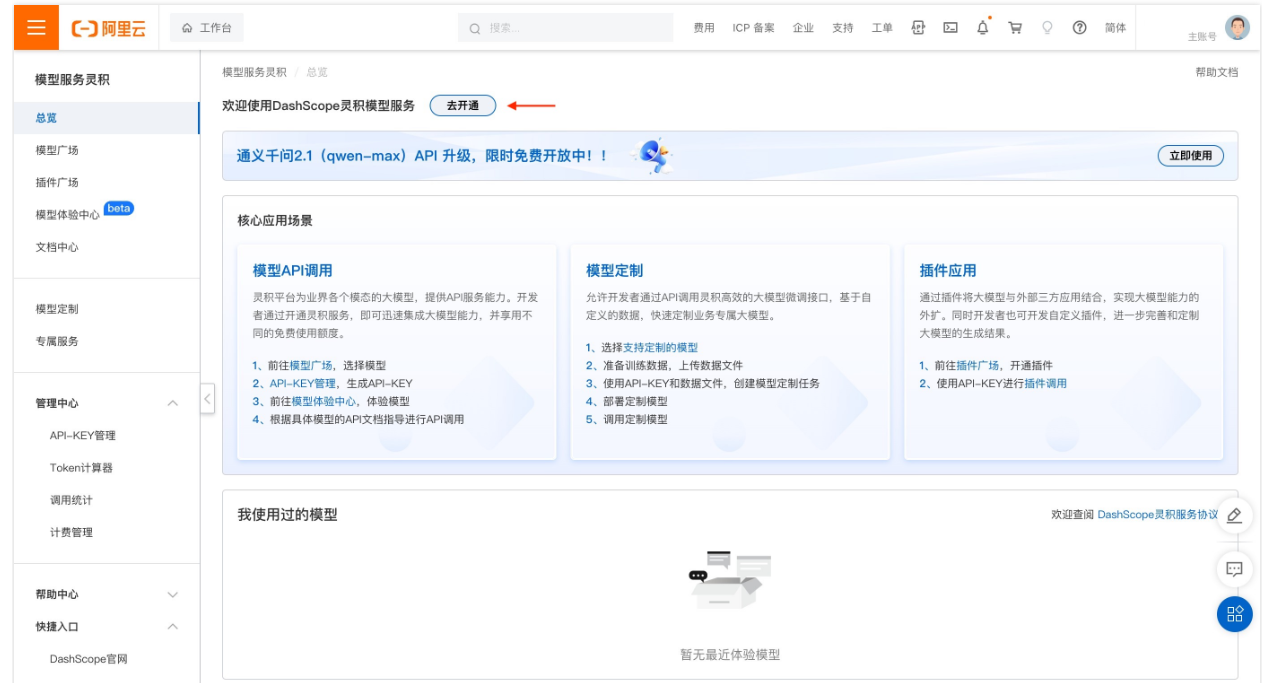
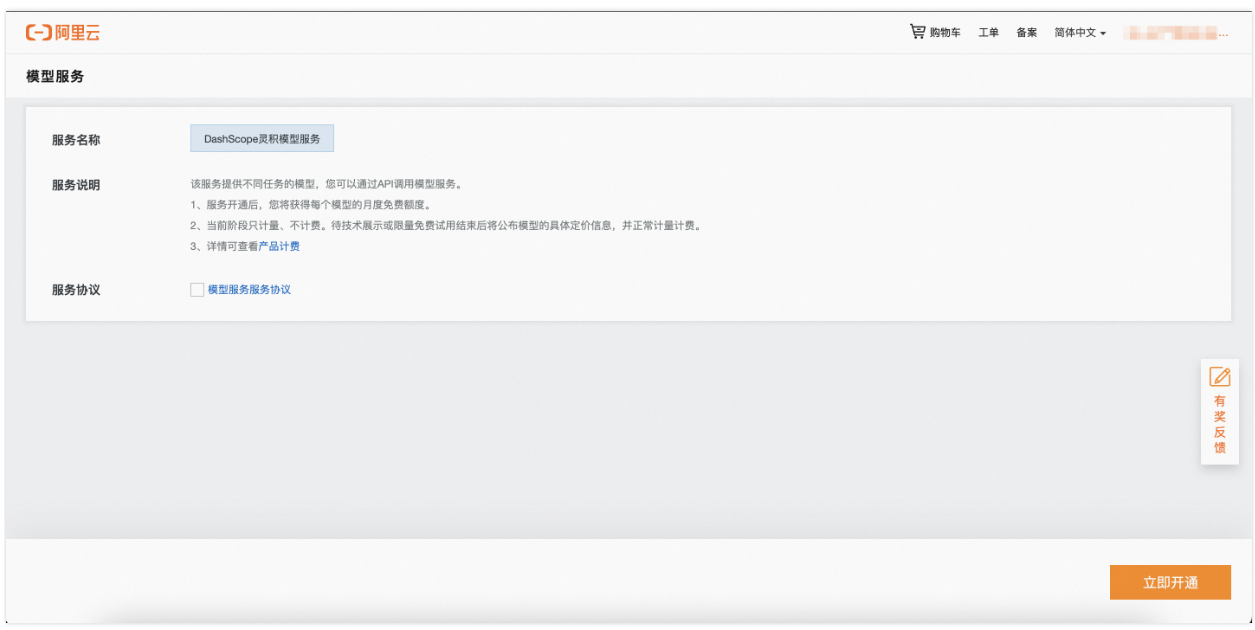
开通DashScope灵积模型服务
访问DashScope管理控制台:前往控制台。
创建API-KEY
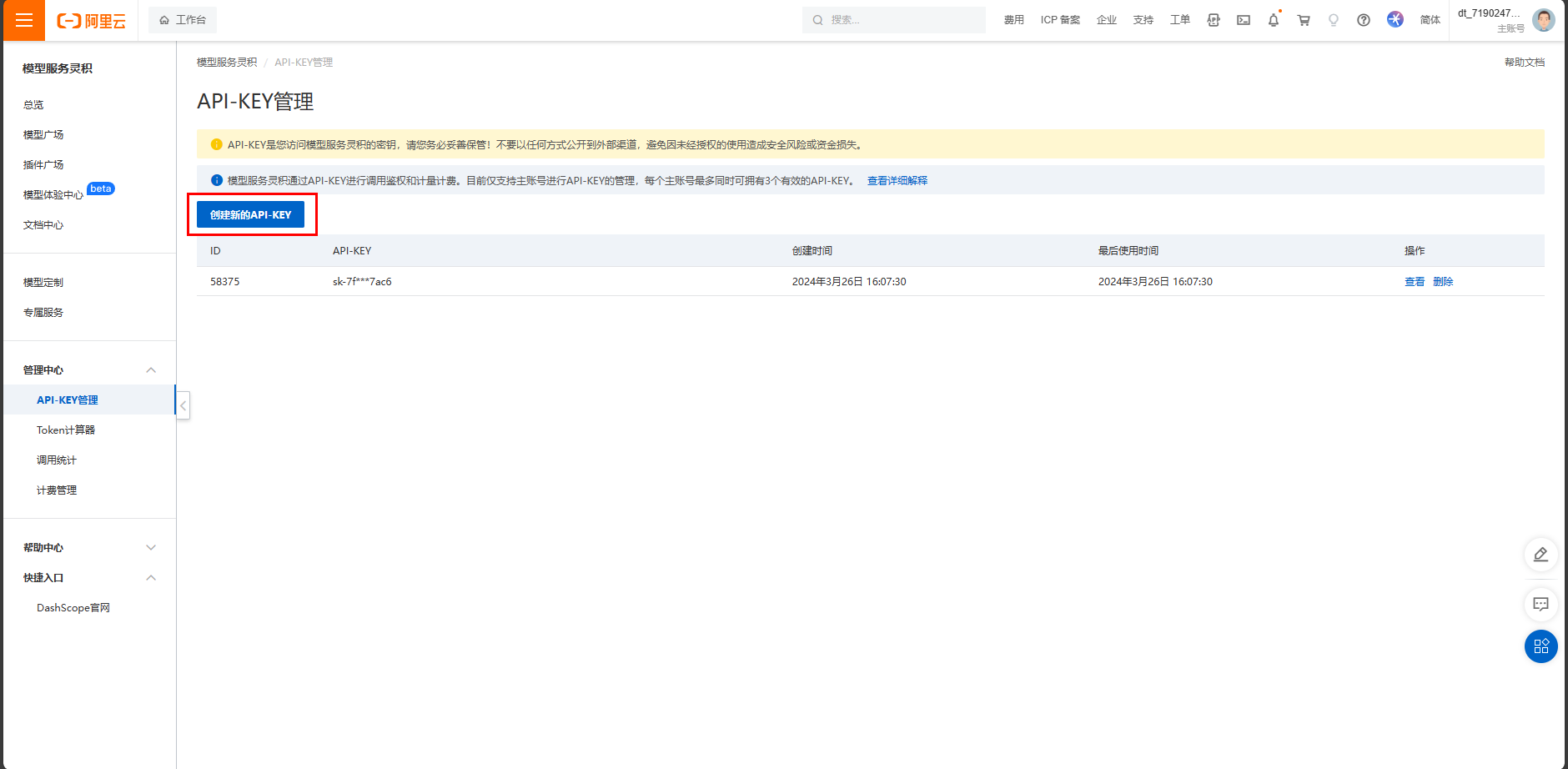
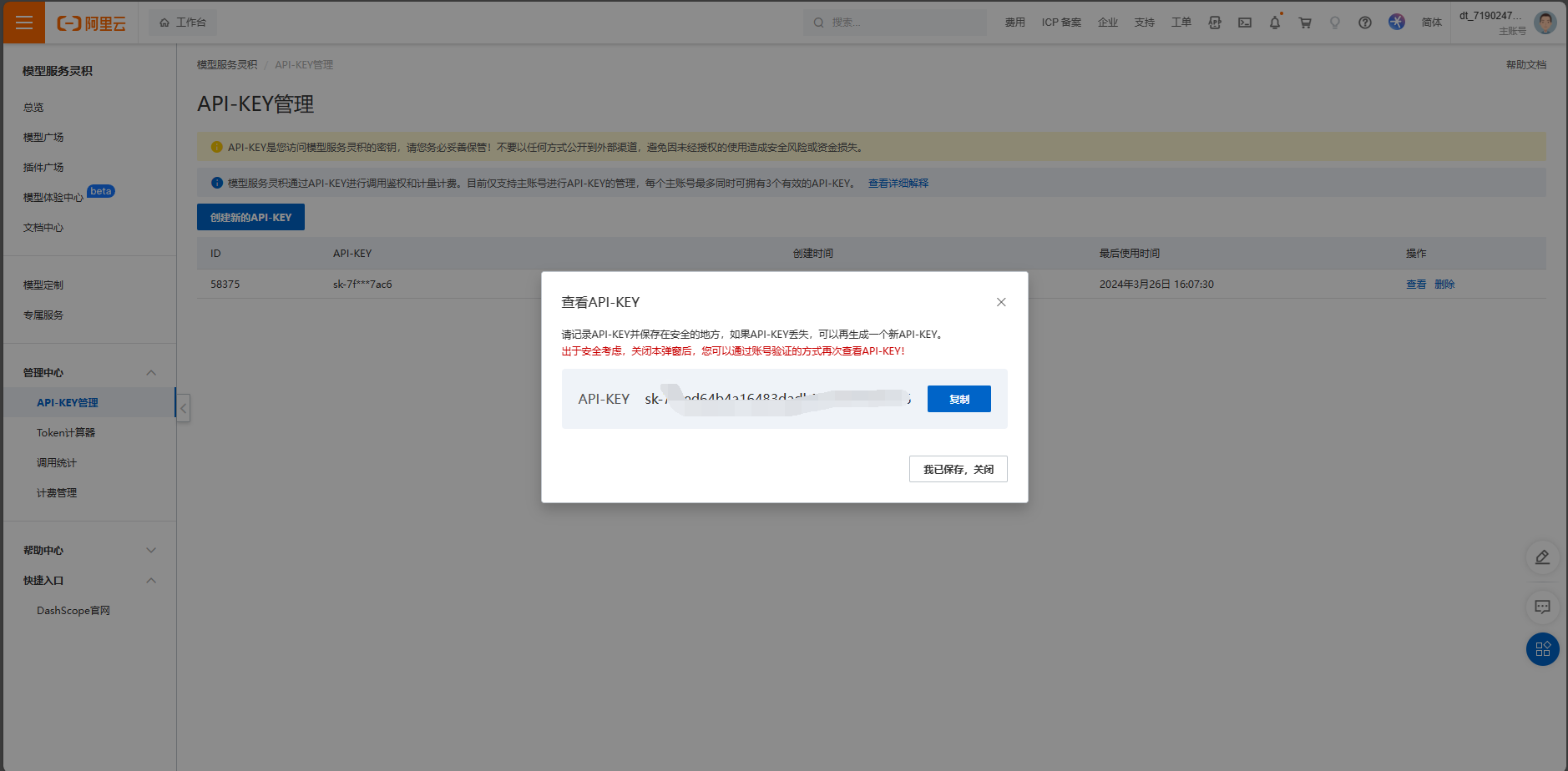
访问DashScope管理控制台API-KEY管理页面:前往API-KEY管理,然后点击“创建新的API-KEY”。
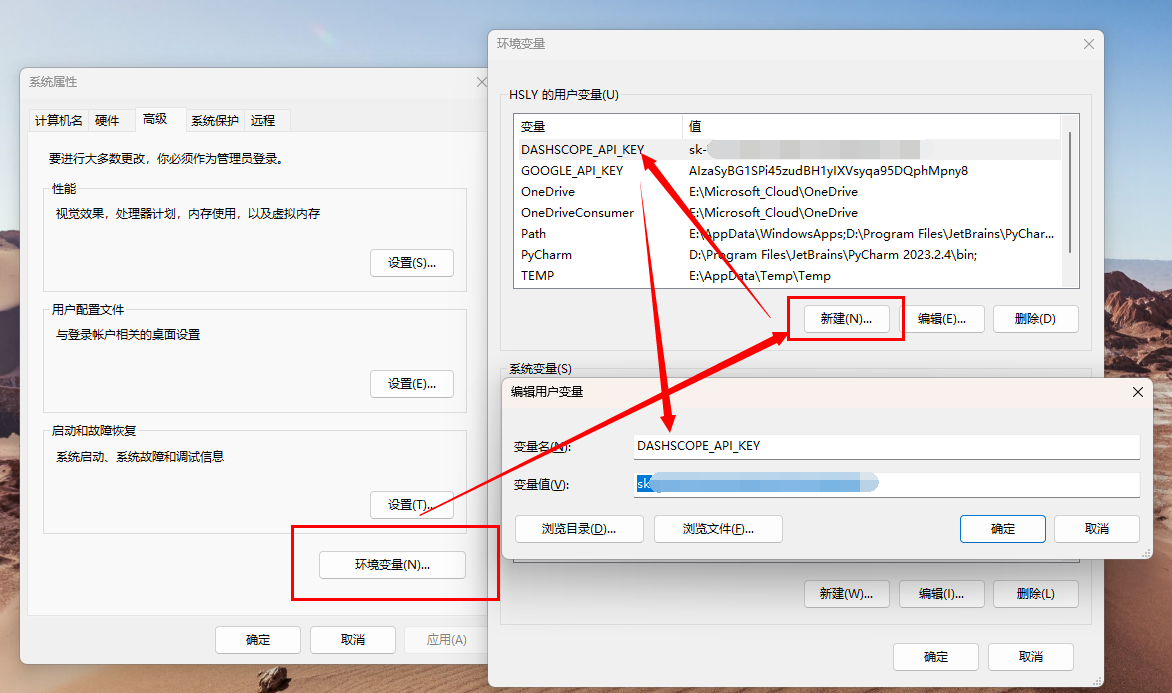
API-KEY添加至系统变量
- 新建用户变量
- 输入变量名(可以自定义):DASHSCOPE_API_KEY
- 输入变量值(API-KEY):直接复制
Python调用示例
import os
import time
import json
import random
from http import HTTPStatus
import dashscope
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
# 两种方式调用api-key
key = os.getenv("DASHSCOPE_API_KEY") # 调用时需要手动添加key
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY") # 不需要手动添加key
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
流式输出
def call_with_stream(question): messages = [ {'role': 'user', 'content': f'{question}'}] responses = Generation.call( model='qwen-max-1201', max_tokens=1500, messages=messages, result_format='message', stream=True, incremental_output=True ) full_content = '' for response in responses: if response.status_code == HTTPStatus.OK: full_content += response.output.choices[0]['message']['content'] api_reports(response, question) else: print('Request id: %s, Status code: %s, error code: %s, error message: %s' % ( response.request_id, response.status_code, response.code, response.message )) print(f'{question}:\n\n' + full_content) def api_reports(output_response, text): time_now = time.strftime('%Y年%m月%d日%H点%M分%S秒', time.localtime()) f = open(f'大模型调用记录/通义千文/{text}_{time_now}.json', 'w') output_json = json.dumps(output_response) f.write(output_json) f.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
text = '为什么我保存response的json文件,content为空'
call_with_stream(text)
- 1
- 2

简单多模态

def simple_multimodal_conversation_call(img,question): messages = [ { "role": "user", "content": [ {"image": f"{img}"}, {"text": f"{question}"} ] } ] response = dashscope.MultiModalConversation.call(model='qwen-vl-plus', messages=messages) if response.status_code == HTTPStatus.OK: print(response.output.choices[0]['message']['content'][0]['text']) else: print(response.code) print(response.message)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
img = 'https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg'
text = '这是什么?'
simple_multimodal_conversation_call(img, text)
- 1
- 2
- 3

参考
官网文档:https://help.aliyun.com/zh/dashscope/developer-reference/api-details#8d583410d7so6

