
- 1多模态是什么意思,在生活工业中有哪些应用?_多模态是什么意思?
- 2python-pytorch基础之加载bert模型获取字向量_pytorch加载本地bert模型
- 3Android自定义View基础--Paint设置PorterDuffXfermode图形混合模式实现遮罩效果,例如头像展示_android view遮罩 mpaint.setxfermode
- 4gcc流程及鲜有人知的参数_-fvolatile
- 5使用vim编写golang_vim中编译go语言文件的命令
- 6Ubuntu16.04+python3+Spyder+qt5(python3)的安装
- 7R语言使用caret包的confusionMatrix函数计算混淆矩阵、基于混淆矩阵的信息手动编写函数计算f1指标_r语言 f1 score
- 8有道词典笔3新增功能扫读和点读是怎么集成的?_词典笔是什么原理
- 9【8个Python数据清洗代码,拿来即用】_python进行文本清洗时的去除噪声的代码
- 10任意文件上传下载漏洞_nginx防止php文件被下载
业界分享 | 美团到店综合知识图谱的构建与应用
赞
踩

美团到店综合业务涵盖了本地生活中的休闲玩乐、丽人、亲子、结婚、宠物等多个行业。为了不断提升到店综合业务场景下的供需匹配效率,美团深入挖掘用户在本地生活中的多样化需求,构建了以用户需求节点为中心并链接商户、商品和内容的到店综合知识图谱 ( GENE,GEneral NEeds net )。
本文将围绕美团到店综合知识图谱展开,介绍图谱构建与应用过程中的技术实践,并分享具体的落地应用和最新探索。
主要包括以下几个部分:
美团到店综合业务介绍
到店综合知识图谱的构建方案
到店综合知识图谱的应用实践
未来展望
01
美团到店综合业务介绍
美团到店综合业务涵盖了本地生活中的休闲玩乐、丽人、亲子、结婚等众多行业,聚焦用户的到店消费场景,为用户提供丰富便捷的本地生活服务。
在到店综合业务场景下,我们希望能够深耕本地生活的细分行业,不断提升供需匹配效率,改善用户体验,而这其中的关键是如何理解用户需求。
用户的决策路径可以分为五个阶段,依次是起心动念、考虑、评估选择、交易购买和履约服务。用户的需求往往集中在前两个阶段产生,首先起心动念形成场景化的诉求,例如“周末陪宝宝去哪玩”,我们称之为场景需求,继而考虑具体的方案,例如“户外烧烤”,我们称之为具象需求。
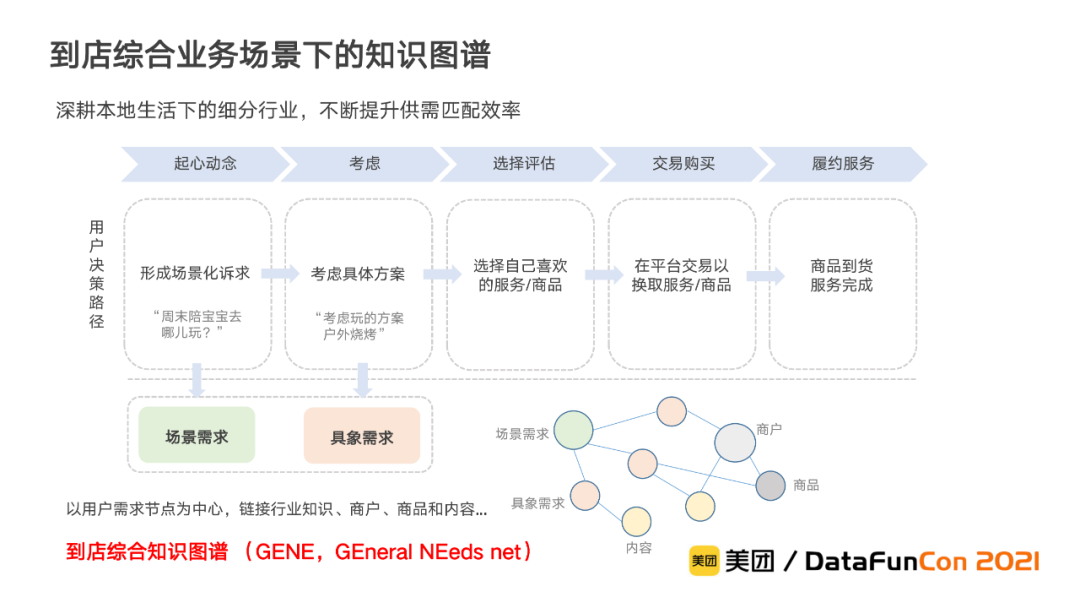
无论是用户的场景需求还是具象需求,都需要进一步和商户和商品等实体建立联系,从而为用户提供能满足其对应需求的不同类型的供给。知识图谱作为一种揭示实体及实体间关系的语义网络,用以解决上述问题显得尤为合适。为此,我们以用户需求节点为中心,链接到店综合业务涉及的行业知识、商户、商品和内容,构建了到店综合知识图谱(GENE,GEneral NEeds net)。
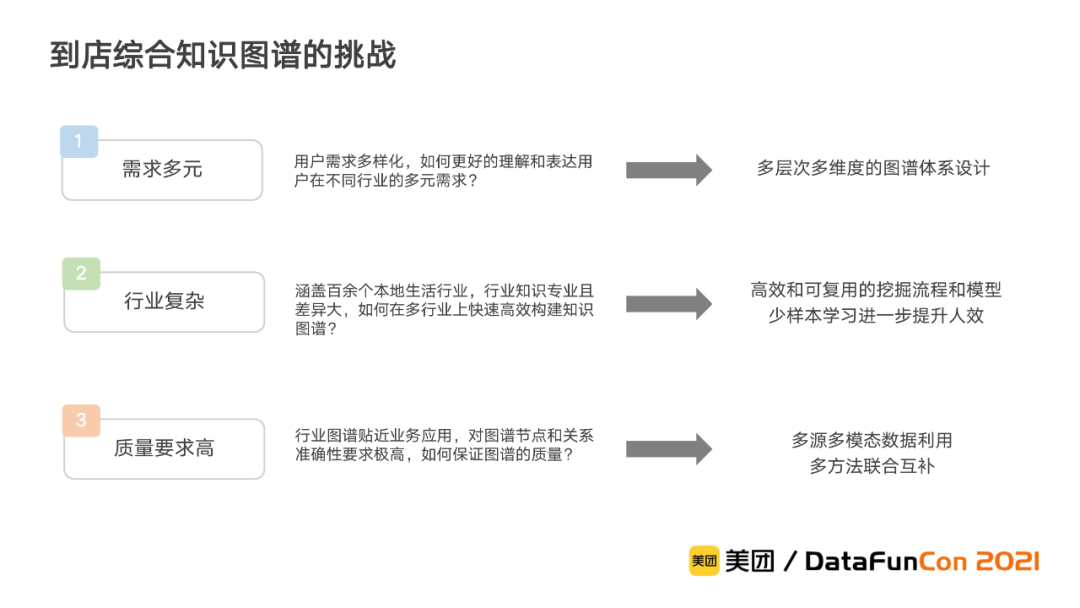
在到店综合知识图谱的构建过程中,主要面临三个方面的挑战:
用户需求多样化:在本地生活场景中,用户的需求多样。为了理解和表达用户在不同行业的多元需求,我们设计了多层次多维度的图谱体系,对用户需求进行层次化和结构化的挖掘。
本地生活行业复杂:到店综合业务涵盖了百余个本地生活的行业,行业知识专业且差异很大。为了在多行业上快速构建知识图谱,我们设计和开发高效可复用的挖掘流程和模型,并结合少样本学习来不断提升图谱构建的效率。
知识图谱质量要求高:由于面向实际的业务应用,对图谱节点和关系准确性的要求高。为此,我们基于多源多模态数据,通过多种挖掘方法联合使用来进行优势互补,以确保最终知识图谱的质量。
02
到店综合知识图谱的构建方案
1. 到店综合知识图谱体系设计
到店综合知识图谱的体系设计由六部分组成,包含场景需求层、场景要素层、具象需求层、需求对象层、行业体系层和供给层。
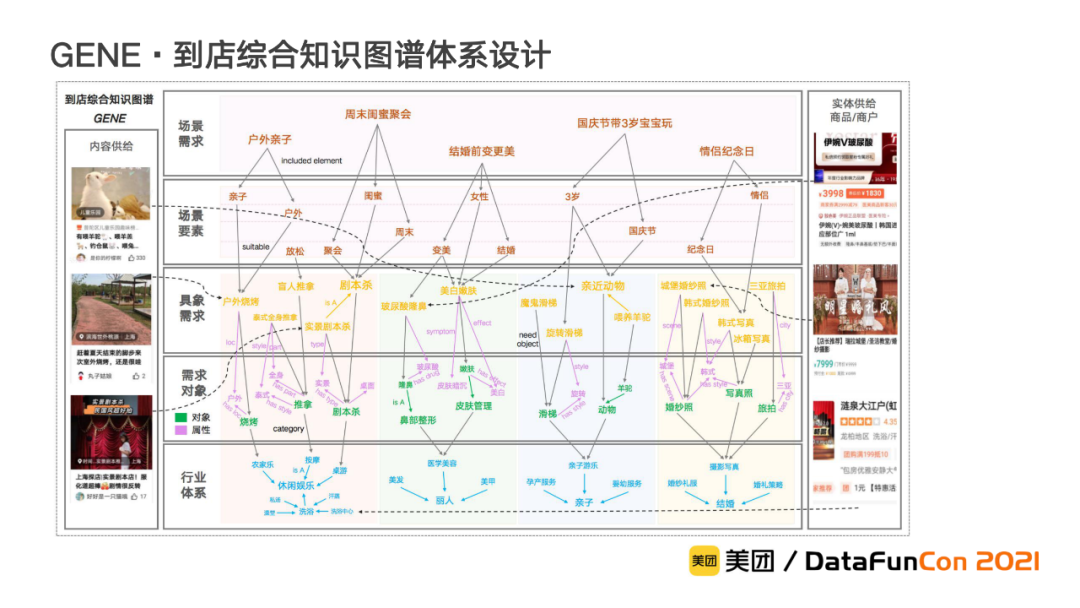
场景需求层:该层包含了用户的场景需求节点,例如“户外亲子”、“周末闺蜜聚会”,这些节点直接反应了用户场景化的诉求。
场景要素层:在该层中,为了更好地表达场景需求,我们对其进行拆解,细化成多个不同类型的细粒度的词汇,我们将其称为场景要素。
具象需求层:该层包含了用户的具象需求节点,例如“户外烧烤”、“实景剧本杀”,这些节点直接反应了用户在场景化诉求下具体的服务需求。
需求对象层:在该层中,为了进一步理解具象需求,我们将其分为具体的服务需求所对应的对象,并叠加各种维度的属性描述,包括服务交互、风格、功效、部位等。
行业体系层:在该层中,我们构建了各行业涉及的类目体系,作为上述各层构建的业务基础。
供给层:该层包含了内容供给和商户商品这类实物供给,这些供给将会和需求节点进行关联,从而为用户需求提供相对应的供给支撑。
总体来说,在到店综合知识图谱中,用户场景化的需求和具体的服务需求分别在场景需求层和具象需求层进行展现。这两种需求又分别通过场景要素和需求对象进行表达。最后,不同类型的供给都会与场景需求和具象需求相关联,从而以用户需求为纽带,提升供给和用户的匹配效率。
2. 图谱各层构建涉及的主要任务
在图谱各层的构建中主要涉及三个方面的任务:
① 节点挖掘:包括需求、对象、属性等不同类型节点的挖掘;
② 节点关系构建:包括同义、上下位、属性关系等多种节点关系的构建;
③ 节点和供给关联:包括节点与商户、商品和内容等不同类型供给的关联。
下面我们将按照自底向上的顺序介绍各层的具体构建方案。
行业体系层:
① 类目树构建和属性挖掘
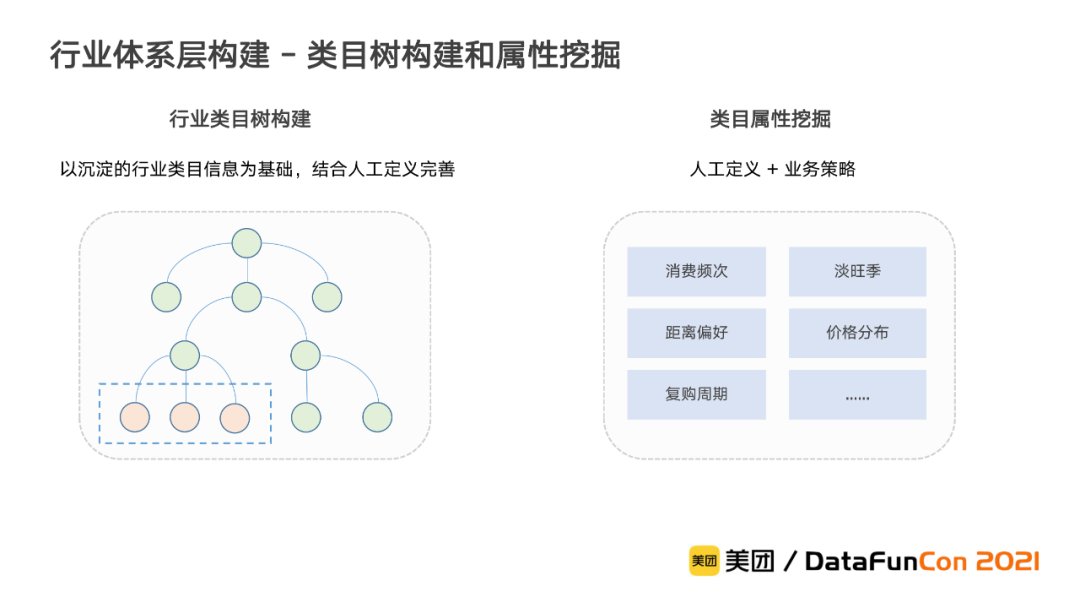
由于行业体系的构建对专家知识的要求较高,我们直接沿用了已有的行业类目树,再通过人工定义来完善。为了对不同行业有更深的理解,我们还定义了包含复购周期、距离偏好在内的多个维度的类目属性,并基于业务策略对各个行业进行多维度的描述。
② 类目节点和供给的关联
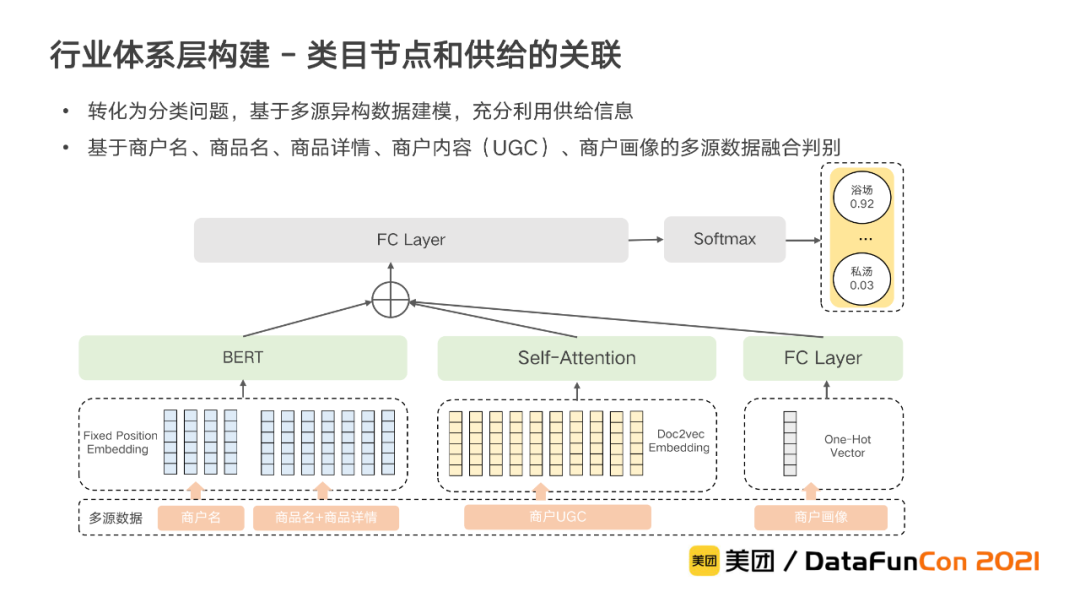
在行业体系层中,我们需要进一步建立类目和供给之间的关联关系。我们将其转化为分类问题,基于供给的各种信息,构建多源异构数据融合判别模型来进行类目分类。
以商户供给为例,我们将商户名、商品名、商品详情、商户内容(UGC)、商户画像等多源数据进行融合判别。其中:
商户名、商品名及商品详情:均为文本数据,直接通过BERT提取文本语义特征后输出;
商户UGC:由于数量非常多,为了对其信息进行有效利用,我们首先通过Doc2Vec的方式进行Encode得到UGC的特征后,再通过一个Self-Attention模块进行特征处理后输出;
商户画像则直接转成One-Hot特征后,通过全连接层进行非线性映射后输出。
上述三种特征相连接后进行融合,实现最终的类目判别。基于多源数据的融合建模,商户信息得到了充分利用,分类准确率也得到了明显提升。
需求对象层:
在需求对象层,我们希望能够挖掘出需求的对象和各种维度的属性作为该层的节点,这是用于组成具象需求的基础。在挖掘过程中,我们分为了粗粒度和细粒度两个环节。
在粗粒度挖掘中,我们希望获取对象和属性维度。由于专业知识差异很大、行业知识壁垒较高,为了高效挖掘,我们设计了关键词抽取->相关词聚类->维度提炼的pipeline,通过算法和人工相结合的方式来确定该层最终的结构。
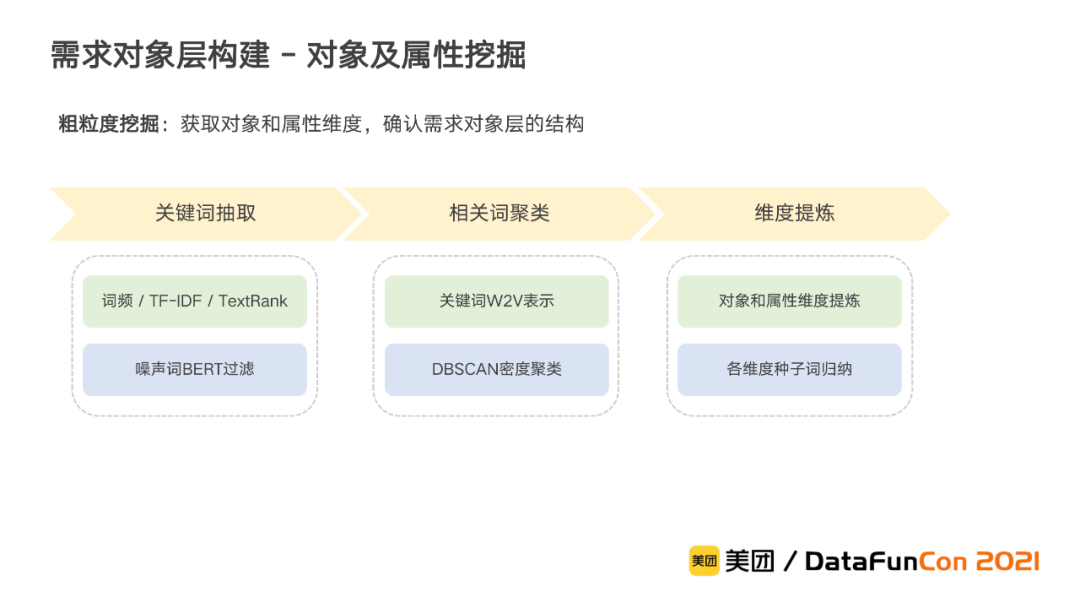
接下来是针对各维度进行细粒度的节点挖掘。为了确保对象和属性挖掘的全面性,我们采用多源多方法的方式。在数据上,我们采用用户搜索、UGC等多种文本作为挖掘语料。在方法上,我们采用无监督扩充和有监督标注相结合来挖掘。
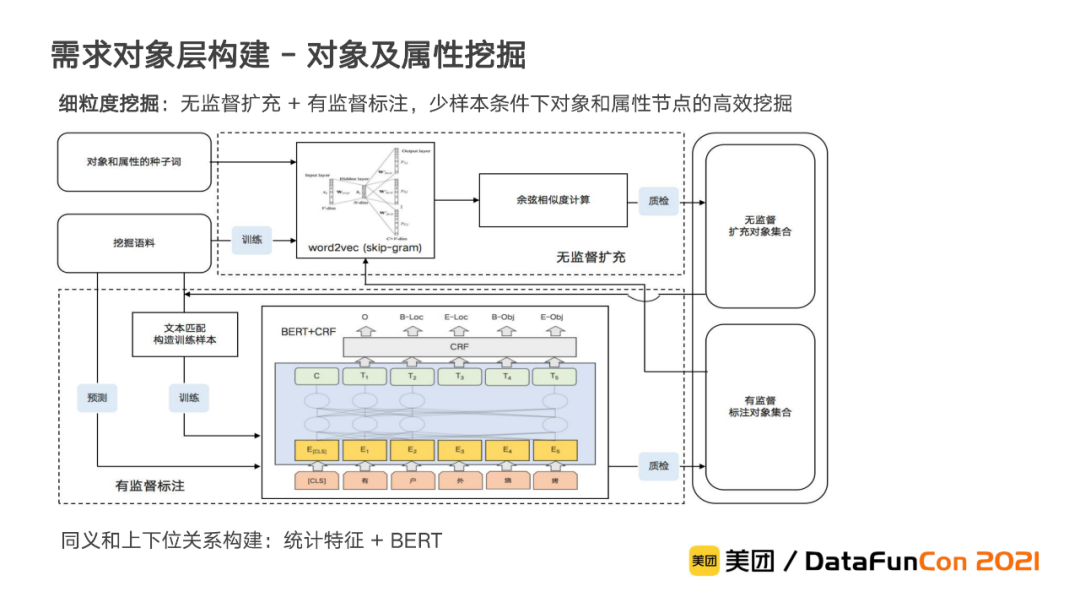
在无监督扩充中,我们利用词向量模型,对各维度的种子词提取词向量,并结合余弦相似度,快速扩充相关的对象和属性。在有监督标注中,我们则采用基于BERT+CRF的序列标注模型,在语料中自动识别出新的对象和属性。
由于人工标注样本数量往往十分缺乏,面对少样本的情况,我们进一步利用无监督扩充的结果有针对性地构造有监督标注环节的训练样本。完成对象和属性节点的挖掘后,我们会进一步基于统计特征结合BERT来实现节点的上下位和同义关系的构建。
具象需求层:
① 具象需求挖掘
在具象需求层中,除了部分需求对象可以直接成为具象需求节点外,我们还需要在对象和属性的基础上进一步挖掘具象需求。
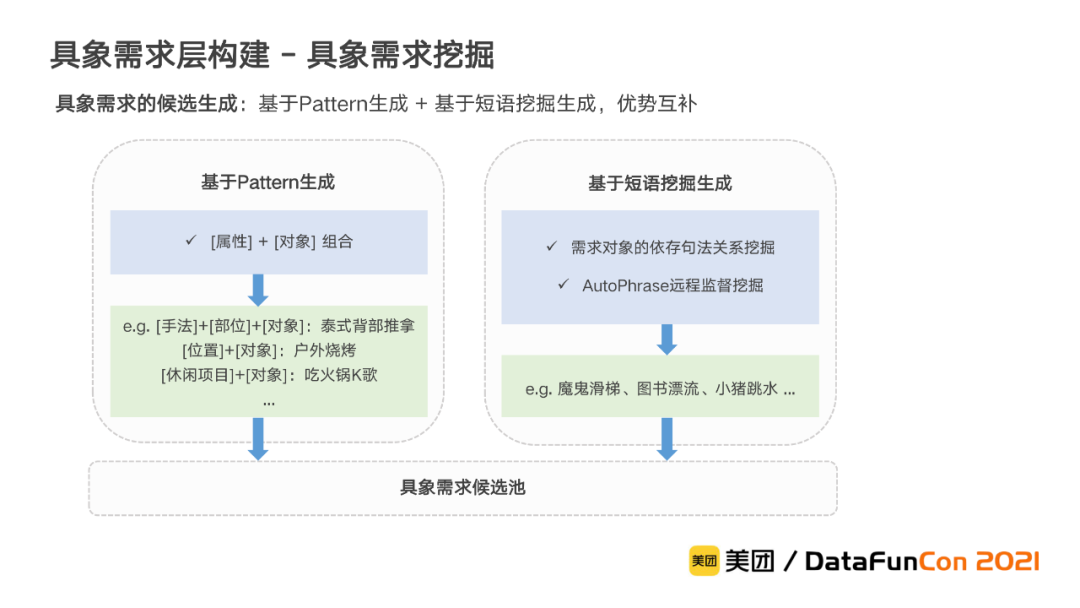
首先我们进行具象需求的候选生成。为了生成的全面性,我们通过基于Pattern和基于短语挖掘两种方式互补来实现。一方面,通过属性和对象的Pattern组合直接生成,比如“户外烧烤”、“吃火锅K歌”,另一方面通过依存句法树的句法关系模板挖掘和基于远程监督的AutoPhrase方法进行短语挖掘,以对组合结果进行补充。最后所有挖掘的结果通过词频过滤后进入候选池。
以上获取的候选节点虽然符合我们预设的规则或句法关系,但语义上仍然存在大量与用户实际需求或者行业知识不相符的情况。为了更全面地衡量候选节点的质量,我们基于节点的统计和语义特征联合建模,构建了一个基于Wide&Deep结构的质量判别模型,对候选池中每个节点的质量进行判别。
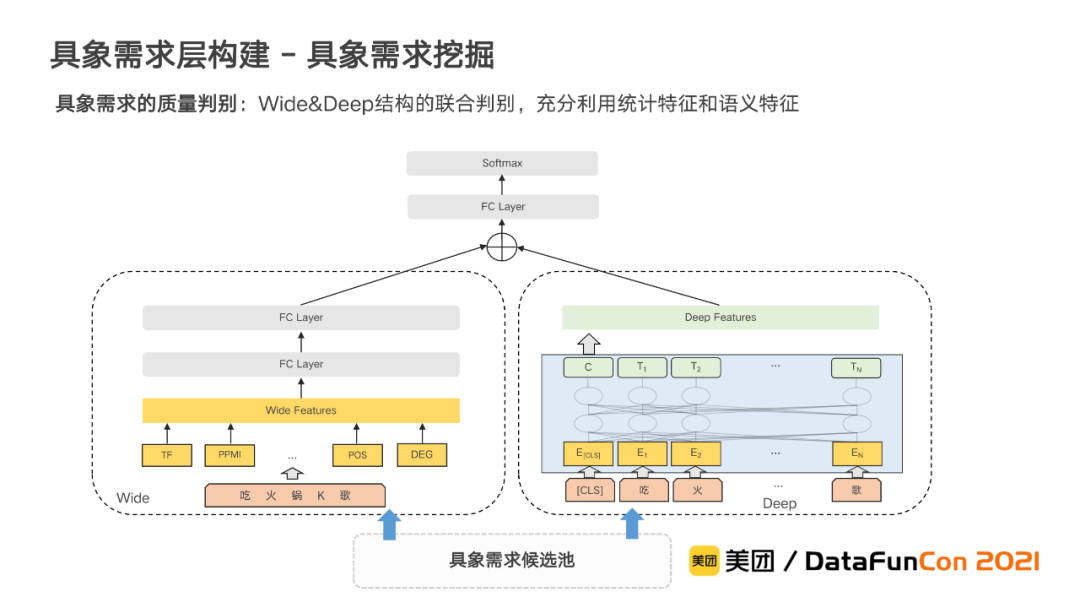
Wide部分提取候选节点的全局和上下文的统计特征,Deep部分通过BERT提取候选节点的深度语义特征。两部分的特征相连接后进行融合,经过全连接层来实现最终的短语质量判别。在训练过程中,除了直接使用已经积累的常识性短语作为正样本外,我们还通过预设一些常识性的组合来构造样本,并结合主动学习来进行训练。通过质量判别后保留的节点则会交由运营人工审核后入库。
② 节点关系的构建
对于同义和上下位的关系,可以复用需求对象层积累的关系结果和相应的模型。此外,还需要进一步建立具象需求和属性之间的关系,以对具象需求进行更详细的刻画。对于基于Pattern生成的具象需求,关系已经天然存在,而直接通过需求对象得到以及基于短语挖掘生成的具象需求,则需要构建其和属性的关系。
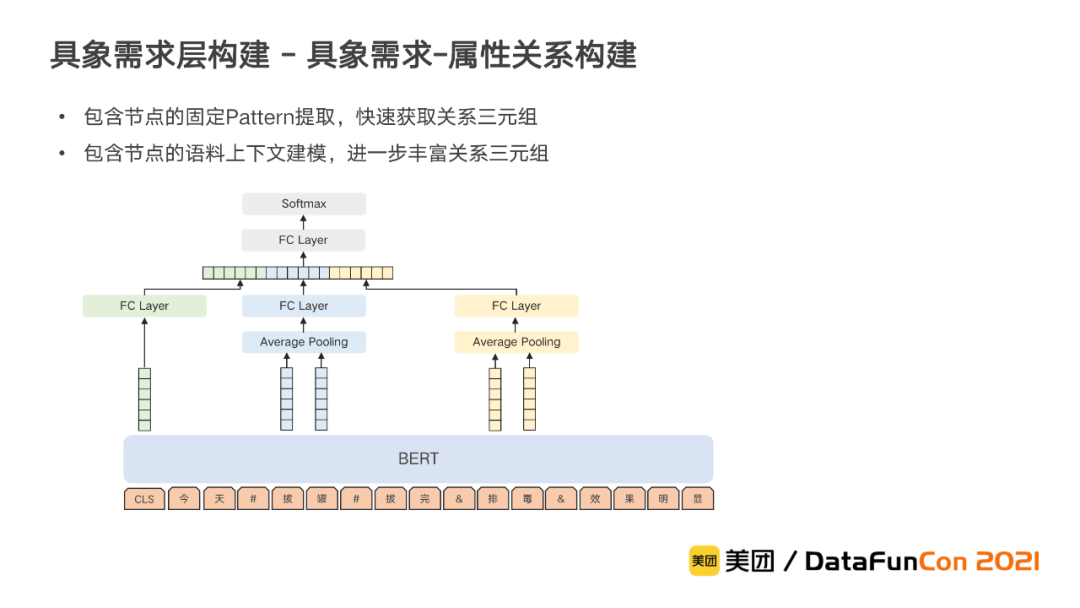
我们采用两阶段的方式来构建关系。首先通过在语料文本中提取包含具象需求和属性的固定Pattern,快速获取关系三元组。在此基础上,构建基于BERT的句中实体关系抽取模型,对包含具象需求和属性的语料上下文建模,将具象需求和属性的特征与上下文特征融合后联合分类获取,从而进一步丰富关系三元组。
③ 具象需求节点和供给的关联
在具象需求层中,我们还需要将具象需求与实体供给(商户和商品)和内容供给进行关联。我们将这个问题抽象为一个实体链接的问题,通过语义匹配来解决。由于具象需求数量众多,同时供给的文本信息通常包含多个子句,出于效率和效果的平衡考虑,我们将整个匹配过程分为了召回、排序和聚合三个阶段。
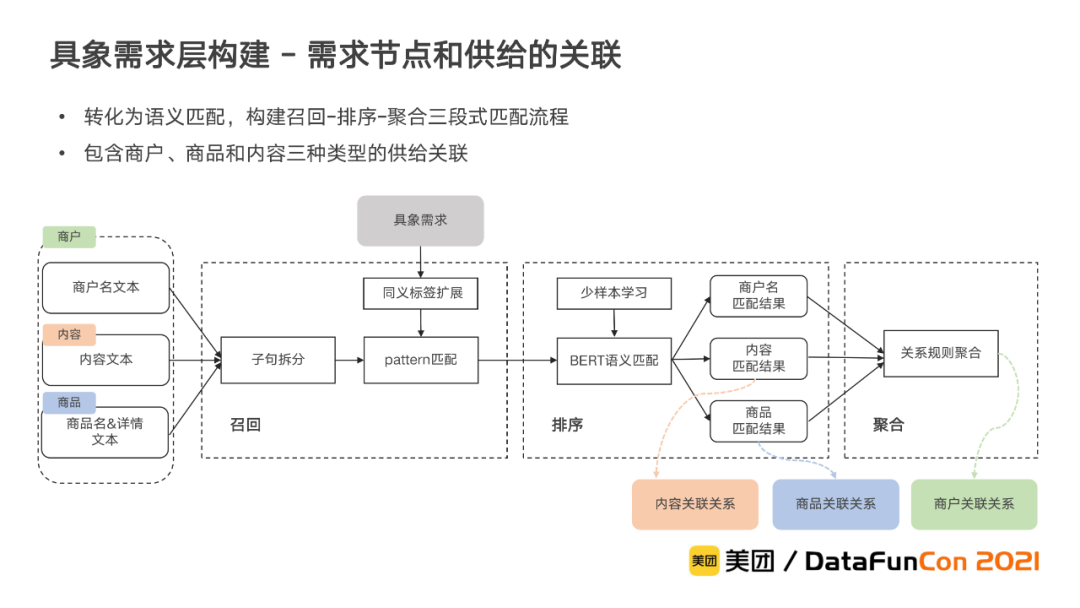
在召回阶段,基于构建的同义关系扩展具象需求的同义标签,并将其与子句文本进行粗粒度匹配,粗筛出可能与具象需求节点有潜在关联的子句,并进入到排序阶段进行精细化的关联关系计算。
在排序阶段,我们采用基于BERT句间关系分类的语义匹配模型,同时通过一些对比学习方法来弥补样本的不足,并结合主动学习提升标注效率。模型通过对召回阶段得到的粗筛样本进行预测,识别两者在语义上的匹配关系。最后对于商户,我们将结合商品和内容的匹配结果,通过规则聚合来完成关联。具象需求和供给的关联,保证了用户的具体服务需求有相应的供给进行承接。
场景要素层:
场景要素层包含了组成用户场景需求的场景要素。在该层中,我们复用在之前已经积累的流程进行高效挖掘。
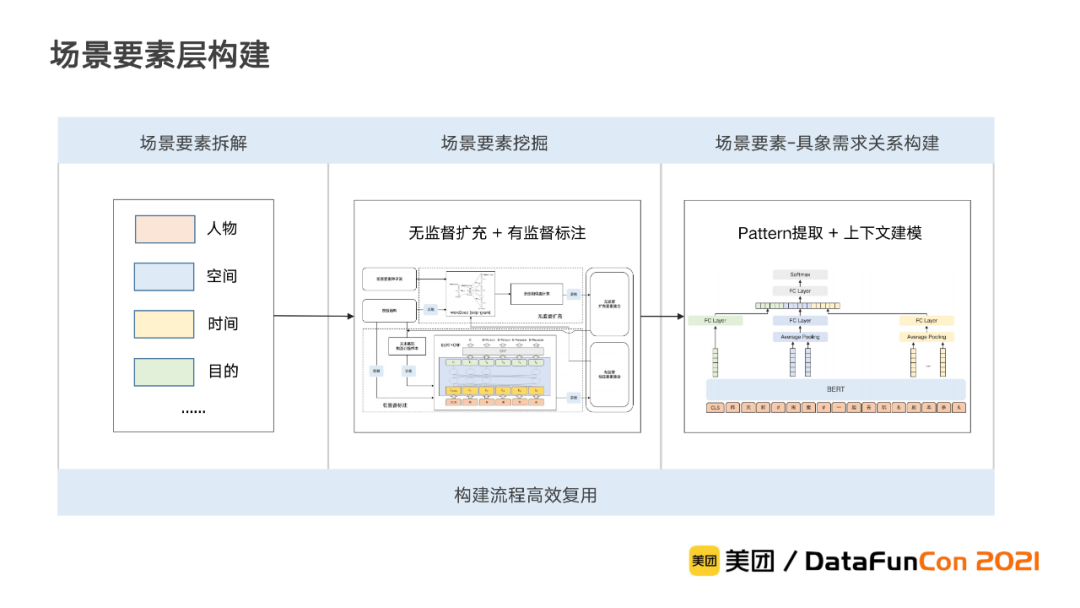
① 场景要素的挖掘
我们首先对场景要素进行类型拆解,要描述一个场景,需要交代特定的人物、时间、空间、目的等要素。在此基础上,考虑到场景要素作为具象需求的场景化的信息,往往来自于用户的直观感受,所以我们选择与具象需求关联的UGC的上下文作为挖掘语料。与需求对象挖掘的方法类似,我们基于无监督扩充和有监督标注相结合的方式,完成各个类型的要素挖掘。
② 场景要素和具象需求关系的构建
场景要素与具象需求之间还需要进一步构建关系,即对于每个场景要素,我们还需要找出其适合的具象需求,例如和“闺蜜”可以玩“剧本杀”,带“孩子”可以去“亲近动物”。具体的方法和具象需求-属性关系构建类似,我们通过关系模板提取和句中实体关系建模,在UGC中提取场景要素和具象需求的关系。
场景需求层:
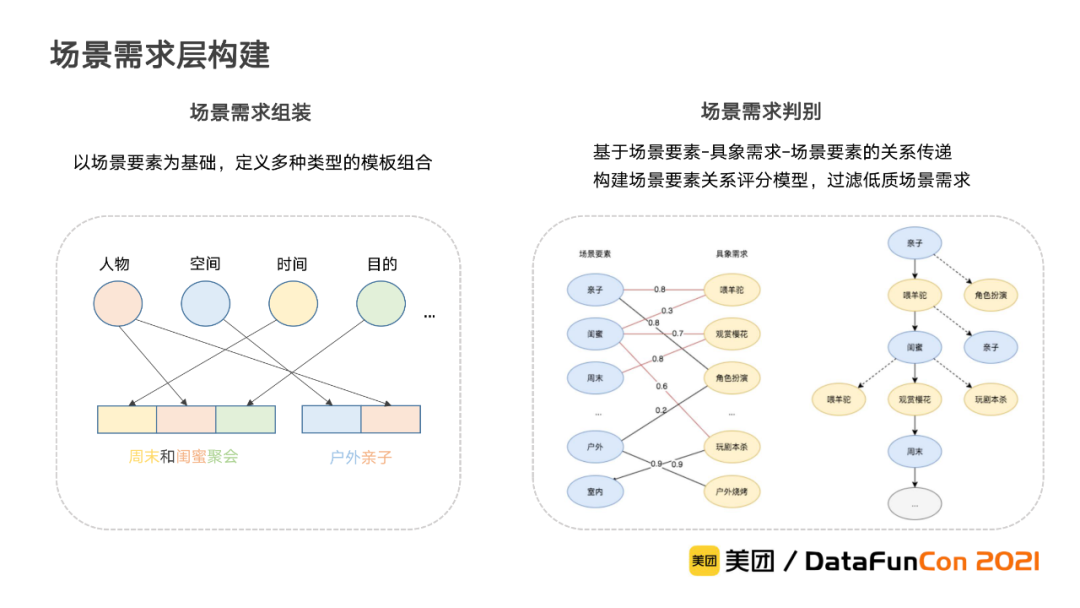
在场景需求层,我们将场景要素层的信息进行组装,从而生成大量的场景需求。组装出的场景需求,既可以包含单个场景要素,也可以包含多个不同类型的场景要素。例如周末和闺蜜聚会、户外亲子等等。
对于组装得到的场景需求,最重要的是保证其合理性,例如“户外”和“亲子”就是合理的场景,而“闺蜜”和“亲子”则是矛盾的场景。为此,我们首先需要计算场景要素之间的关系评分,从而指导场景需求的组装。我们以场景要素和具象需求的关系得分作为依据,通过关系传递评估两个场景要素之间的相关性,以过滤低质场景需求。
最终场景需求通过其包含的场景要素,可以链接到相应的具象需求,进而关联相关的供给,从而给用户提供场景化的解决方案。
3. 数据沉淀

经过一年多的发展,到店综合知识图谱已完成整体的结构设计和核心数据的建设,覆盖了到店综合业务的60多个行业,包含了40多万的需求节点、上亿的关系数以及上百种的关系类型,整体关系的准召率均在90%以上。
03
到店综合知识图谱的应用实践
到店综合知识图谱当前已在到店综合业务的诸多场景中进行了应用,取得了不错的效果,提升了用户体验,下面我们介绍具体应用实践。
1. 到店综合知识图谱的应用
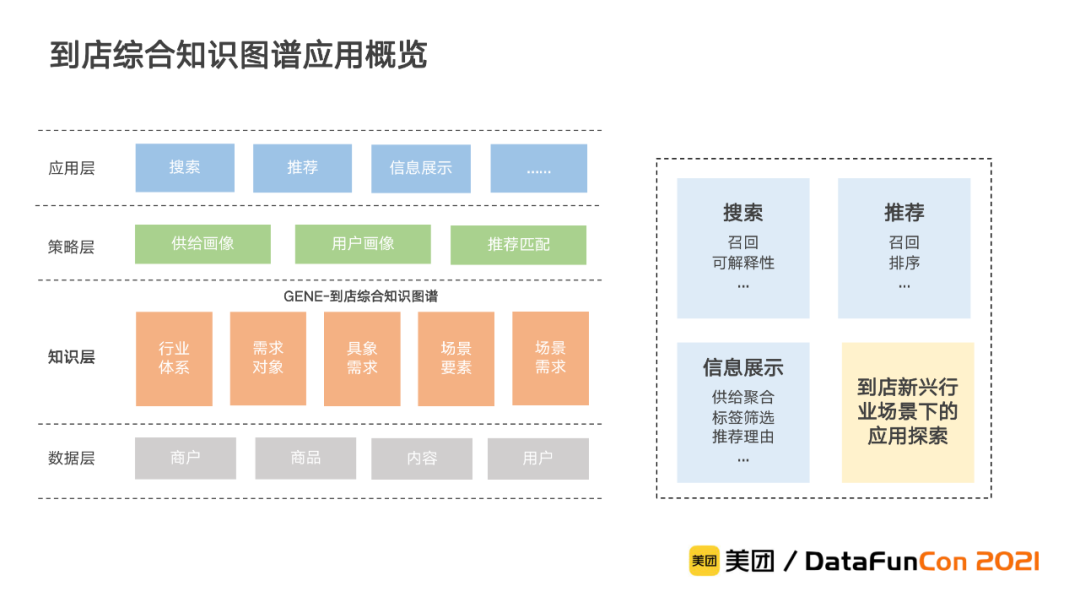
当前到店综合知识图谱的应用主要有三个方面,分别是搜索、推荐和信息智能展示。除了这三个主要应用之外,由于在本地生活中新行业不断出现,我们还会进一步基于知识图谱在新兴行业上进行一系列应用探索。
搜索:
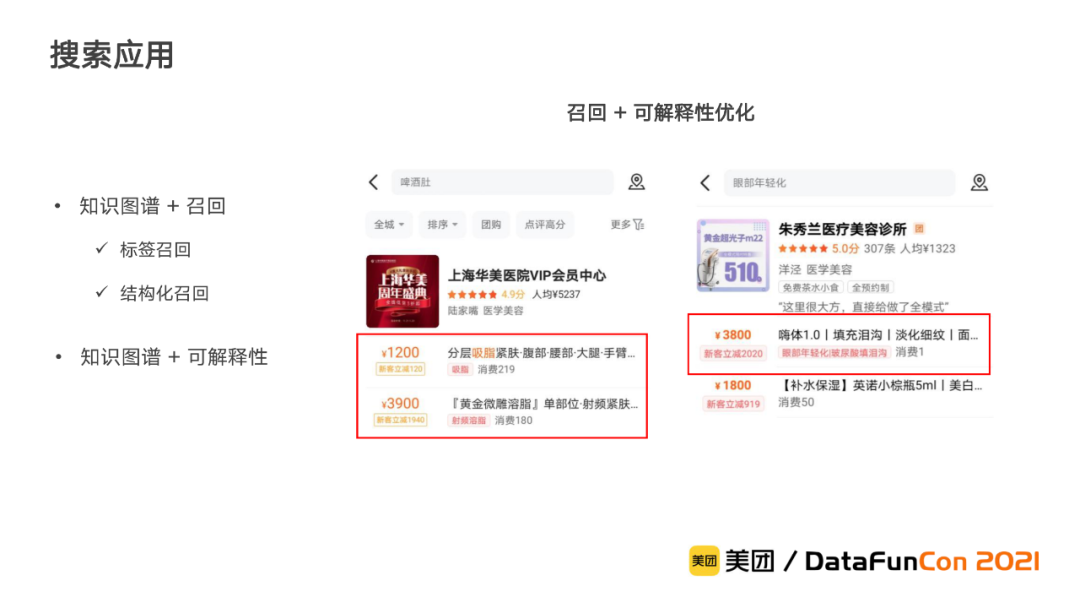
现阶段主要应用于搜索的召回和可解释性优化。这里以医美行业为例,由于医美行业的专业性高,用户在搜索时输入的query和供给之间往往存在较多的语义隔阂。我们的图谱数据,可以为医美搜索的召回和可解释性提供大量的知识输入。例如,用户希望眼部年轻化,我们可以直接返回提供相关项目的供给,从而提升用户搜索的效率。
推荐:
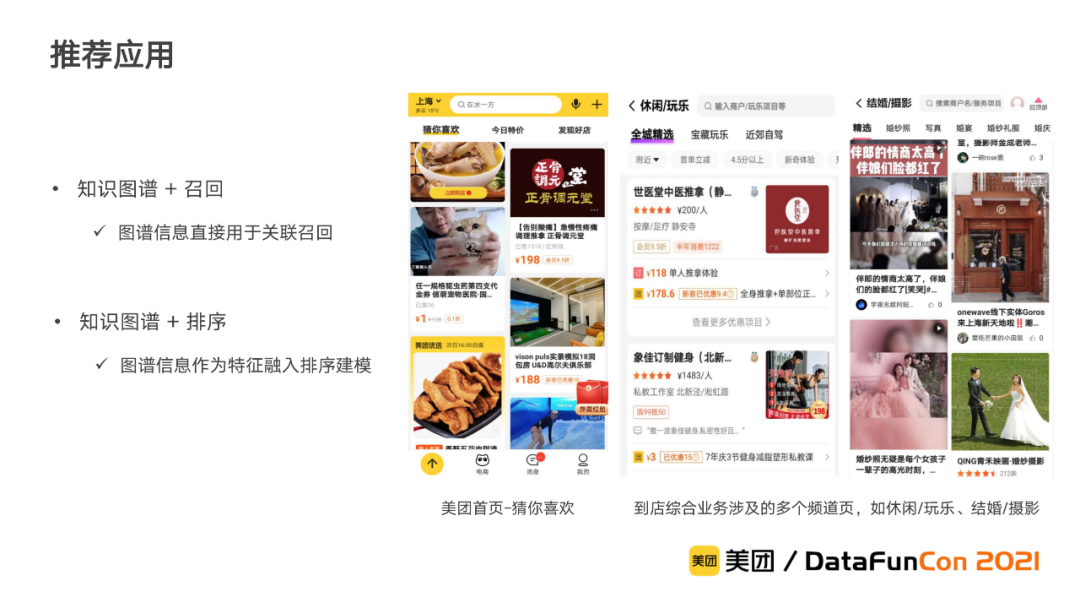
现阶段主要应用于推荐的召回和排序。对于召回,图谱信息可以直接应用于供给的关联召回。对于排序,图谱信息则可以作为特征融入排序建模。当前到店综合知识图谱已在美团首页的猜你喜欢和到店综合业务涉及的各个频道页内的多个推荐流量位进行了应用,推荐的效果得到了明显改善。
信息智能展示:
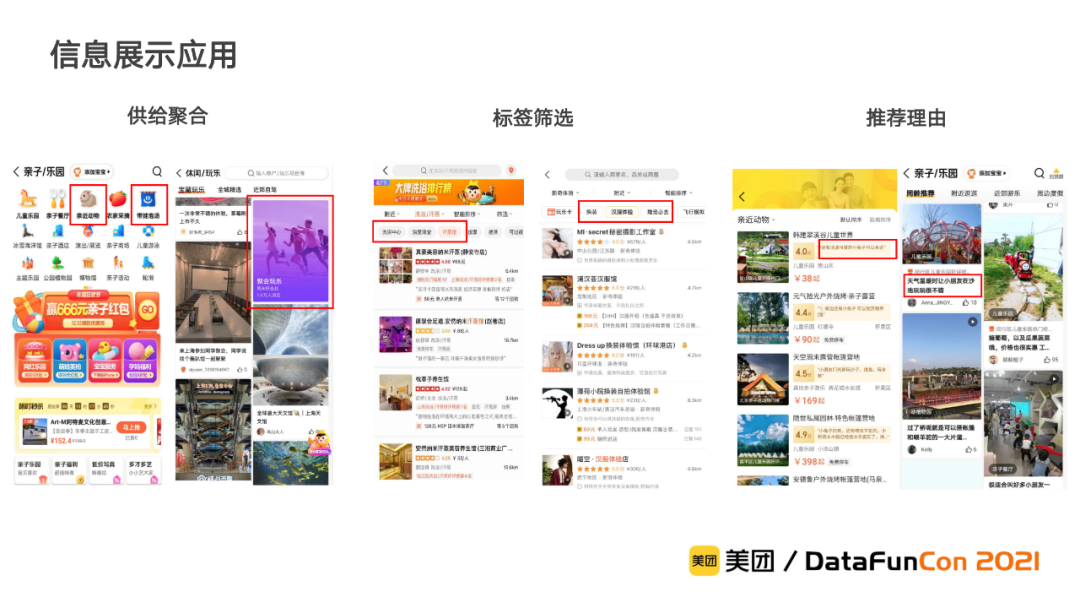
① 供给聚合
为了满足用户丰富多样的需求,我们跨类目生成需求ICON,如“亲近动物”、“带娃泡汤”,对符合用户需求的相似供给进行聚合。同时,我们也为用户生成主题式的供给聚合卡片,更人性化地满足用户需求,提升了用户决策效率。
② 标签筛选
图谱的部分需求节点可以直接用于列表页的标签筛选,这些筛选项提升了用户选择供给的效率。
③ 推荐理由
基于需求节点和供给的关联关系为每个供给选择包含相应需求的文本信息,通过抽取式或受控生成的方式,作为推荐理由外露,这些句子从用户实际需求的角度展示供给信息,显著提升了用户体验。
2. 到店新兴行业场景下的应用探索
这里我们以最近很火的剧本杀行业为例进行介绍。
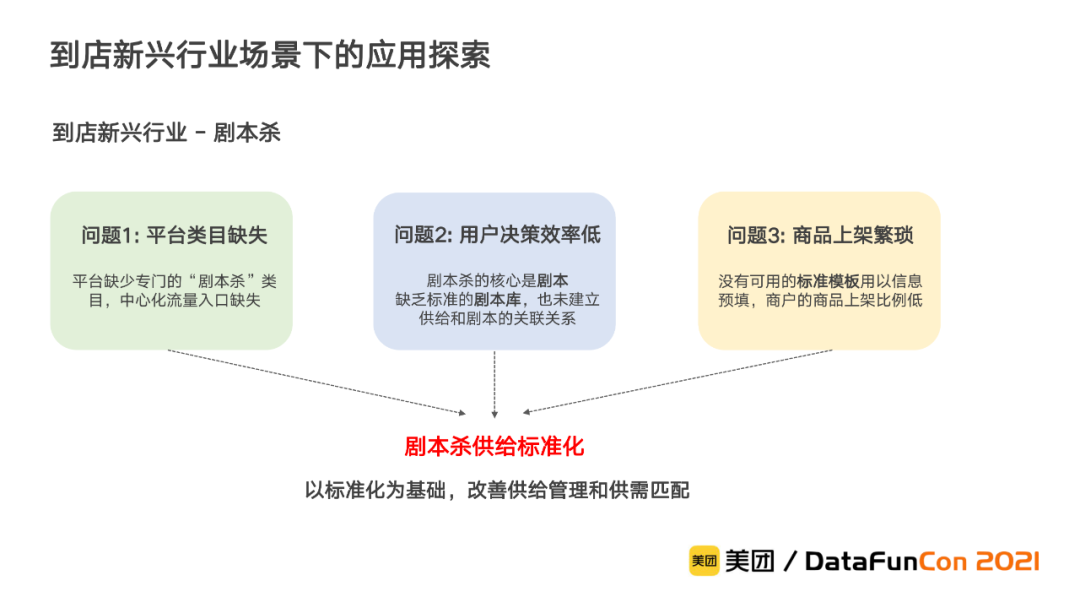
剧本杀行业近年来呈爆发式增长态势,然而由于剧本杀是新兴行业,平台已有的类目体系和产品形态,越来越难以满足飞速增长的用户和商户需求,主要表现为平台类目缺失、用户决策效率低、商户上架繁琐三个方面的问题。为了解决这些问题,我们需要进行剧本杀的供给标准化建设,实现以标准化为基础,改善供给管理和供需匹配。
在标准化建设过程中,涉及了剧本名称、剧本属性、类目、商户、商品、内容等多种类型的实体,以及它们之间的多元化关系构建,这很适合用知识图谱来解决。因此我们以到店综合知识图谱的体系设计为基础,以标准剧本为核心构建剧本杀行业知识图谱,来实现剧本杀的供给标准化。整个剧本杀供给标准化包括了剧本杀供给挖掘、标准剧本库构建和供给与标准剧本的关联三个步骤。
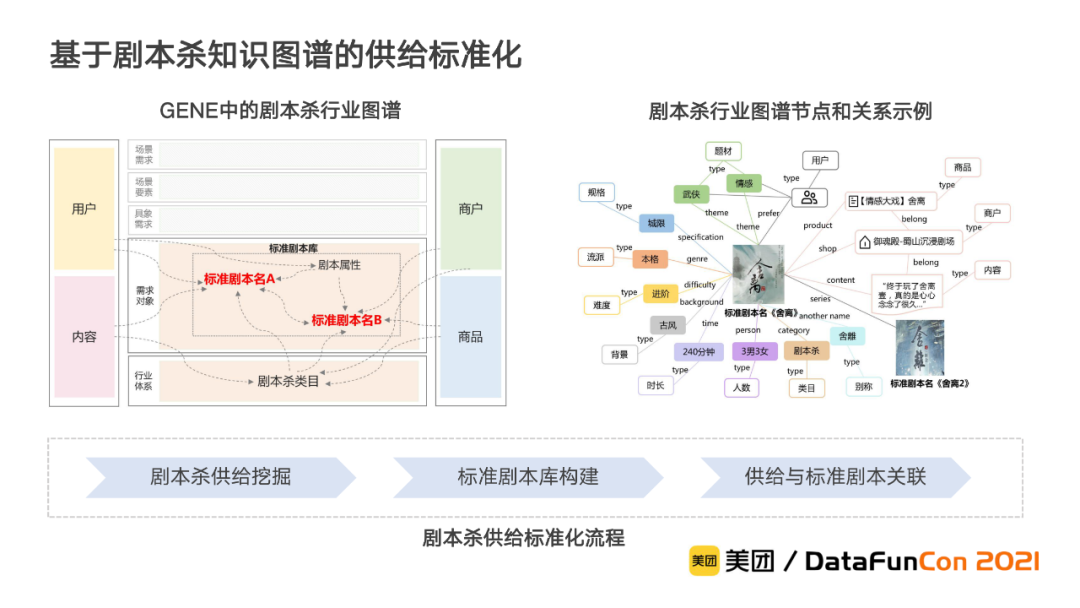
剧本杀供给挖掘:
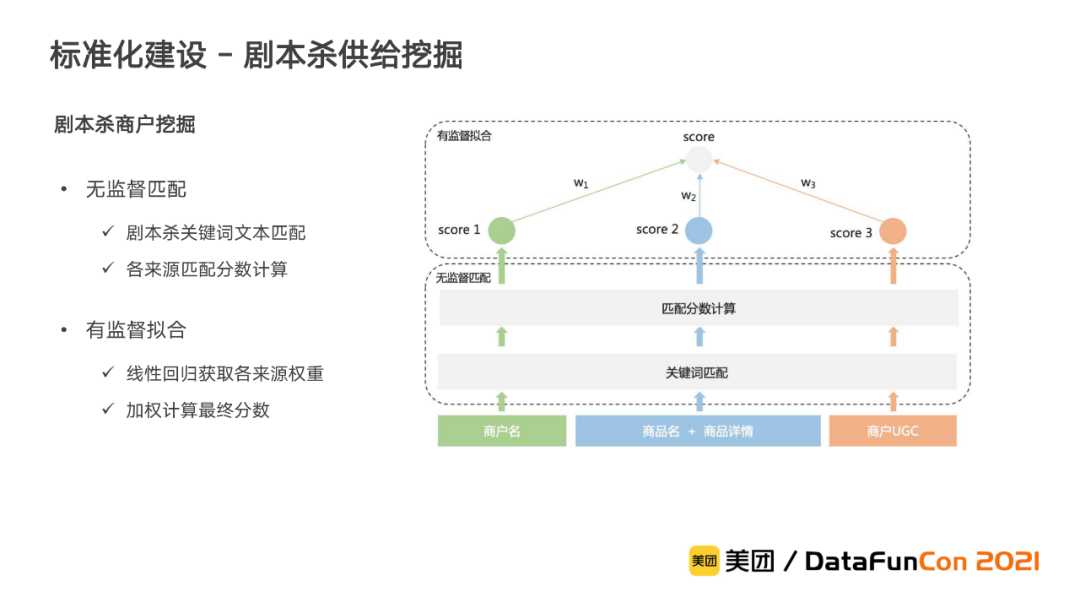
在剧本杀供给挖掘中,需要判断商户是否提供剧本杀服务,判别依据包括了商户名、商品名及商品详情、商户UGC三个来源的文本语料。这个本质上是一个多源数据的分类问题,然而由于缺乏标注的训练样本,我们没有直接采用前文提到的端到端的多源数据融合判别模型,而是依托业务输入,采用无监督匹配和有监督拟合相结合的方式高效实现。首先基于剧本杀关键词文本匹配计算各来源的分数,再基于线性回归拟合标注的商户分数,获取各来源的权重,从而实现对剧本杀商户的精准挖掘。
标准剧本库构建:
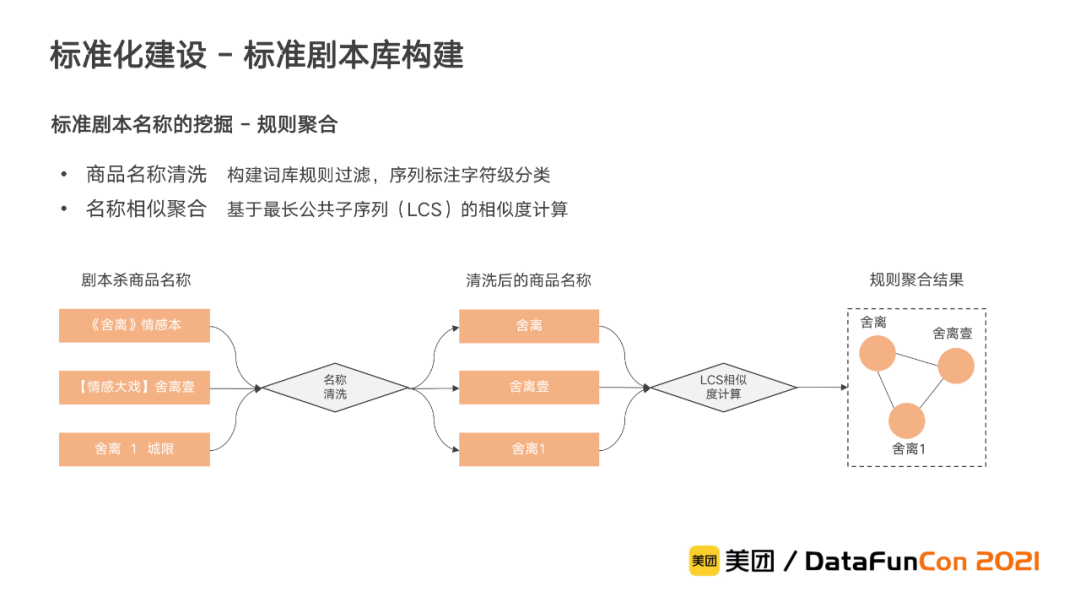
在标准剧本库构建中,关键是剧本名称的挖掘,我们根据剧本杀商品的特点,先后采用了规则聚合、语义聚合和多模态聚合三种方法进行迭代,从数十万剧本杀商品的名称中聚合得到数千标准剧本名称。下面分别对三种聚合方法分别进行介绍。
我们首先考虑剧本杀商品的命名特点,设计相应的清洗策略对剧本杀商品名称进行清洗后再聚合。除了梳理常见的非剧本词,构建词库进行规则过滤外,也进一步将其转换为命名实体识别问题,采用序列标注对字符进行分类。对于清洗后的剧本杀商品名称,则通过基于最长公共子序列(LCS)的相似度计算规则,结合阈值筛选对其进行聚合。通过规则聚合的方式能够在建设初期帮助业务快速对剧本杀商品名称进行聚合。
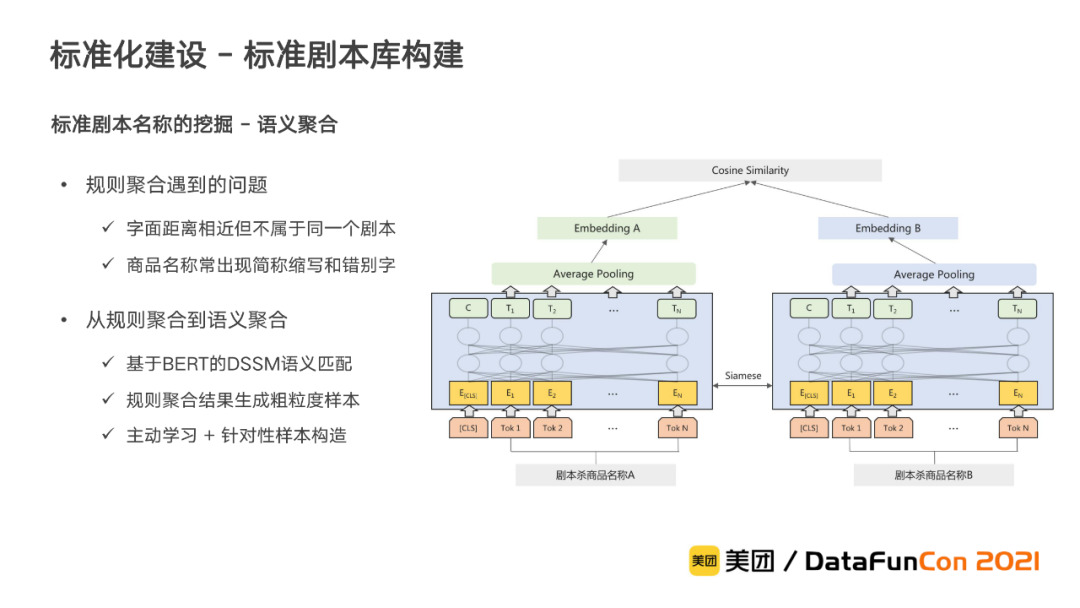
规则聚合的方式虽然简单好用,但由于剧本名称的多样性和复杂性,我们发现聚合结果中仍然存在一些问题:1)字面距离相近但不属于同一个剧本。2)商品名称常出现简称缩写和错别字。
针对这上述这两种问题,我们进一步考虑使用商品名称语义匹配的方式,从文本语义相同的角度来进行聚合。具体地,我们采用双塔式的方法来实现,以Sentence-BERT的模型结构为基础,将两个商品名称文本分别通过BERT提取向量后,再使用余弦距离来衡量两者的相似度。在训练过程中,首先基于规则聚合结果,构造粗粒度的训练样本,完成初版模型的训练。在此基础上,进一步结合主动学习,对样本数据进行完善。此外,我们还根据规则聚合出现的两种问题,针对性的批量生成样本。
通过语义聚合的方式实现了从商品名称文本语义层面的同义聚合,然而我们通过对聚合结果分析后发现,剧本还存在一些语义完全不一样的别称,导致语义不同的商品但仍属于同一个剧本。为此,我们考虑引入商品的图像信息来进一步辅助聚合,尝试构建剧本杀商品的多模态匹配模型,充分利用商品名称和图像信息来进行匹配。
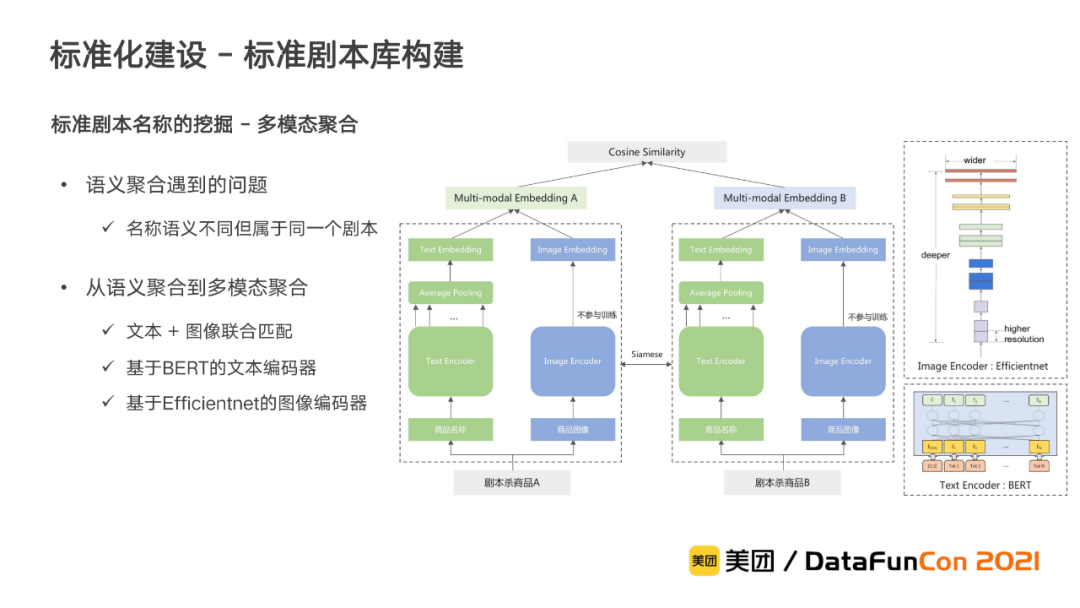
在多模态匹配模型中,模型沿用语义聚合中使用的双塔式结构。剧本杀商品的名称和图像分别通过基于BERT的文本编码器和基于Efficientnet的图像编码器得到对应的向量表示后,再进行拼接作为最终的商品向量计算相似度。通过多模态聚合,弥补了仅使用文本匹配的不足,进一步改善了标准剧本的挖掘效果。
供给与标准剧本关联:
在完成标准剧本库构建后,还需要建立剧本杀的商品、商户和内容三种供给与标准剧本的关联关系,从而使剧本杀的供给实现标准化。由于商品和内容从属于商户,所以我们只对商品和内容进行标准剧本关联。
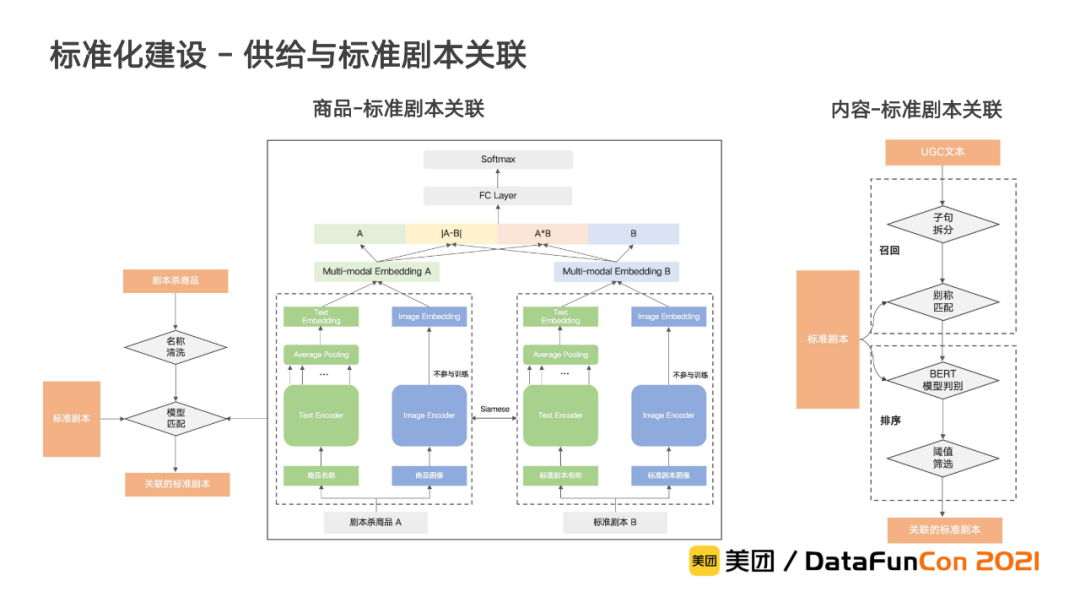
在商品关联中,我们首先对商品名称进行清洗再进行匹配关联。在匹配环节,我们基于商品和标准剧本的名称及图像的多模态信息,对两者进行匹配判别。而对于内容关联,则沿用前文介绍的在具象需求层中使用的内容和需求节点关联的方法,通过召回和排序两个环节,采用基于BERT句间关系分类的语义匹配模型来实现。
效果呈现:
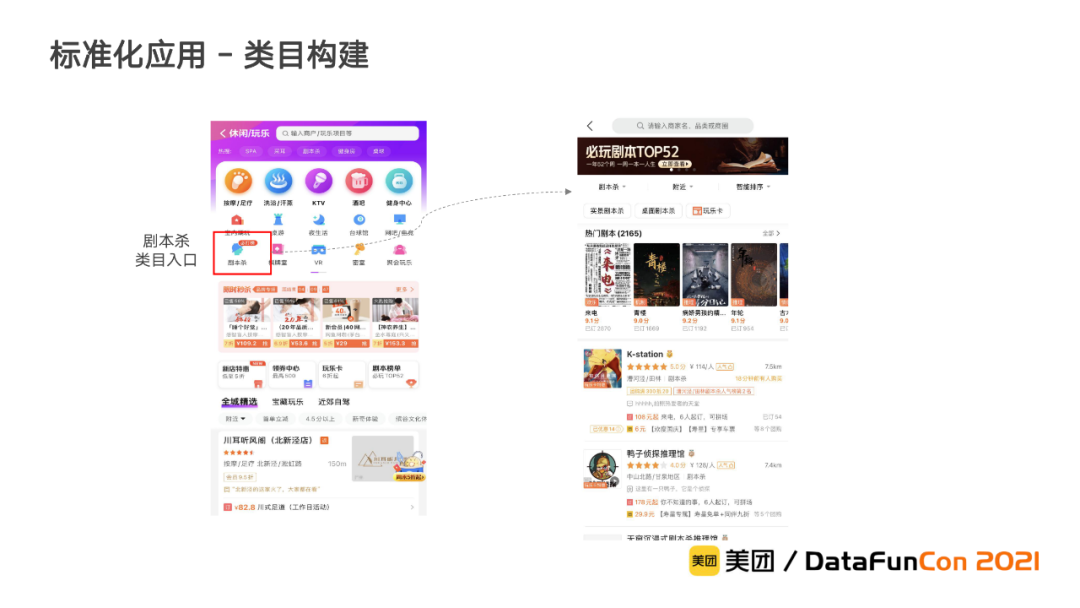
① 剧本杀类目上线
通过剧本杀供给挖掘,识别出剧本杀商户,助力剧本杀新类目和相应剧本杀列表页的构建,为用户提供了中心化流量入口,提升了用户的选择效率。
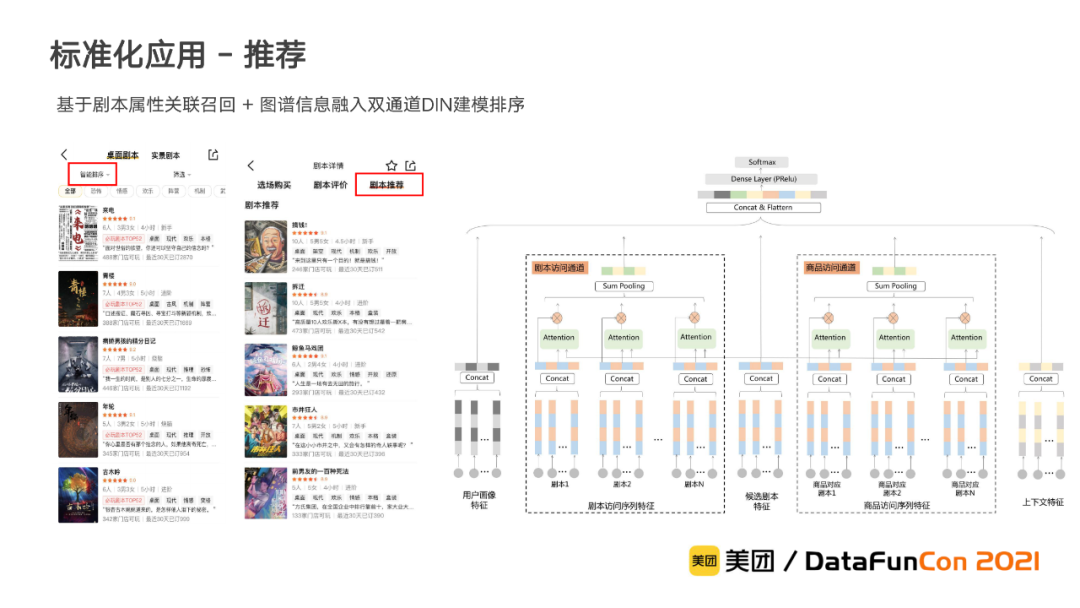
② 推荐优化
基于剧本属性关联召回和图谱信息融入双通道DIN建模排序,为推荐带来了显著的效果提升,优化了用户认知和选购体验,提高了用户和供给的匹配效率。
③ 信息展示
基于剧本杀知识图谱的剧本标签筛选项和相关信息外露,为用户提供了规范的信息展示,降低了用户决策成本,更加方便了用户选店和选剧本。同时,内容和标准剧本的关联关系参与到剧本的评分计算。在此基础上,基于剧本维度,形成剧本榜单,从而为用户的剧本选择决策提供了更多的帮助。

04
未来展望
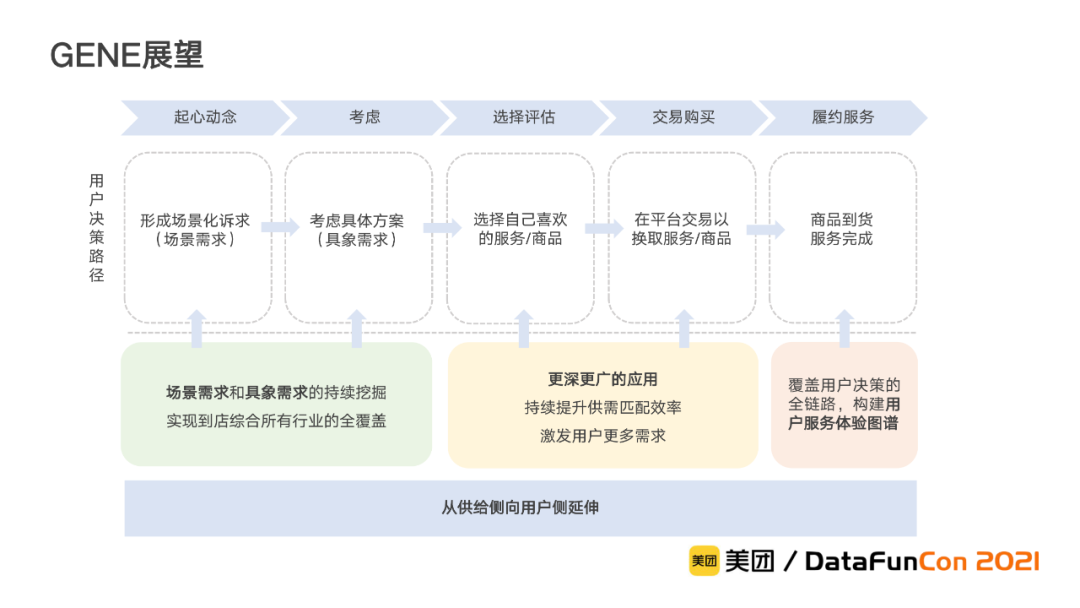
由于美团到店综合业务的复杂性,到店综合知识图谱还有很长的迭代之路要走,在此我们提出一些后续的思考和展望。
首先,我们将从当前的供给侧向用户侧延伸,实现图谱从货到人的迭代,纳入用户节点。同时,加强对已覆盖的行业的建设,挖掘更多的节点和关系,更好的理解用户需求,并基于高效的挖掘流程,快速横向覆盖到店综合涉及的所有行业。此外,我们也会将图谱进一步扩展到用户决策的全链路,覆盖履约服务环节,分析其中的用户需求和反馈,更好地赋能商家提升用户体验。最后,我们还会基于在知识表示和计算等环节上的不断迭代,更充分地利用图谱信息进行更深更广的应用。
希望我们的到店综合知识图谱能够在供需匹配上发挥出更大的作用,为用户在本地生活到店场景下提供更好的服务,帮大家吃得更好,生活更好。
05
问答环节
Q:模板抽取的部分,人工定义的三元组模板抽取怎么跟算法提取结果相结合?整体的效果怎么样?
A:这一部分说的应该是需求节点和属性之间关系的构建。通过人工定义的模板抽取的三元组本身质量较高,可以直接入库。这部分关系也可以作为后续算法建模的样本输入,整体结果准确率在95%以上。
Q:现在的体系和流程,扩展一个新的行业大概需要多久?
A:美团到店综合业务涵盖的行业非常多,每个行业差异又比较大,所以很难给出准确的时间预估,要看行业本身的复杂性。对于新行业,我们会先按照之前业务上积累下来的高效构建流程,先整体构建一遍,再来判断够到底需要多少时间。
Q:标签召回是离线标签吗?知识图谱的召回是利用了图中哪些信息,效果怎么样?
A:我们对接下游应用有两种方式。一种是通过离线数据的形式直接向下游传输;第二种是通过图数据库以服务来对接下游,满足多跳查询等复杂的应用需求。标签召回当前采用的是第一种方式,利用需求节点及其和供给的关系信息,将需求节点以离线标签的形式进行应用。在召回效果上,我们以医美这个行业为例进行了介绍,除了医美之外,我们在结婚、亲子、教育等多个行业上都有一些实践,整体上用户的CTR都有不错的提升。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)


