
- 1(转)SSE,MSE,RMSE,R-square指标讲解_sse mse
- 2数字IC设计工程师笔试面试经典100题_什么是时序优化时序优化的目的
- 3UART使用_uart串口文件描述符
- 4LLM大模型推理加速实战:vllm、fastllm与llama.cpp使用指南_fastllm vllm
- 5大数据,头歌,Hbase的配置_hbase数据库的安装头歌
- 6MySQL 中常见的几种高可用架构部署方案_mysql 高可用部署
- 7【阿里云生活物联网架构师专题 ②】esp8266 sdk 直连接入阿里云物联网平台,实现天猫精灵找队友零配网功能和语音控制;_gitee nvs
- 8【程序人生】如何申请CSDN创作新星?—— 来自【嵌入式领域创作新星】的一点点总结和感悟_csdn优质创作者怎么申请
- 9mavros笔记(一):mavros概述与offboard例程解析
- 10Tokenize Anything via Prompting
mysql用 fifo 记录日志_2016-08-29 上午 京东酒店机票部-3轮面试
赞
踩
今天上午去京东面试,经过了三轮面试最终还是被(HR)告知 回家等消息吧.
先说一下 各个 面试官都问了啥吧:
记性不好 我就不一一罗列了,就直接整理一下所有的问题吧.
1.先来个 排序算法 热热身
分析:
2.聊一下 并发库相关,
2.1 说一下 线程安全地队列
分析:ConcurrentLinkedQueue、ArrayBlockingQueue、LinkedBlockingQueue
2.2 说一下 线程安全的数据结构 自己知道的
分析:按照 不同的数据结构分类说
数据结构
线程安全的实现类
map
ConcurrentHashMap
ConcurrentSkipListMap
set
ConcurrentSkipListSet
CopyOnWriteArraySet
list
CopyOnWriteArrayList
queue
ConcurrentLinkedQueue
ArrayBlockingQueue
LinkedBlockingQueue
LinkedTransferQueue
PriorityBlockingQueue
SynchronousQueue
deue
ConcurrentLinkedDeque
LinkedBlockingDeque
2.3 说一下 AtomicInteger 的 实现(具体说一下 自增是怎么实现的线程安全的)
分析:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
2.4 还问了一下SynchronousQueue,这个我没回答好
分析:
3.map的实现
分析:
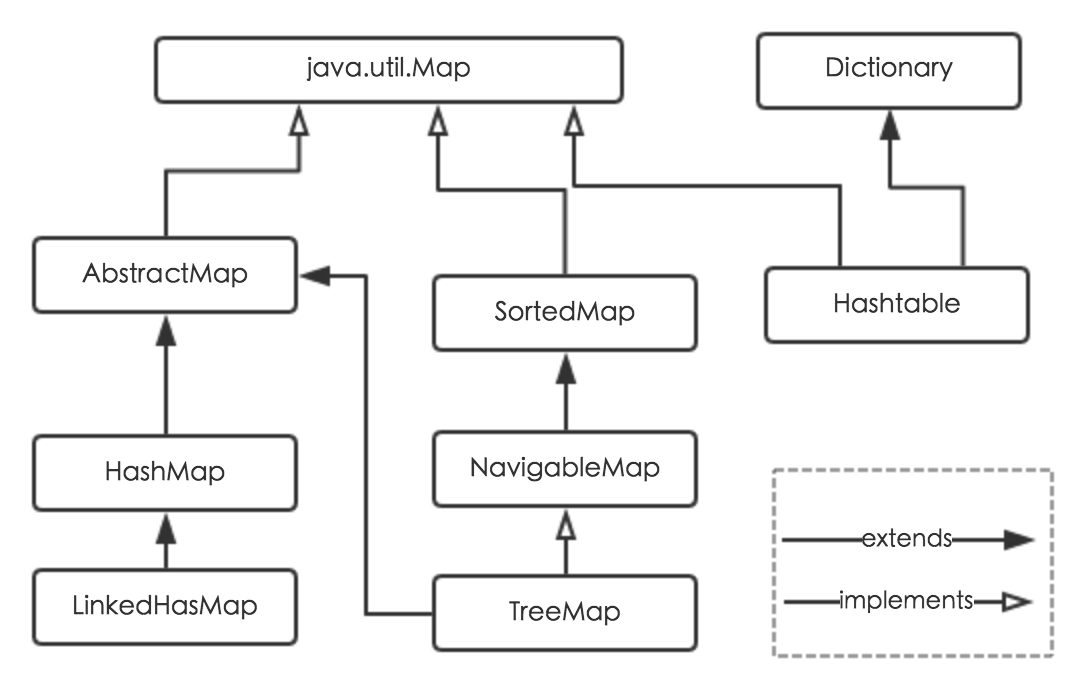
3.1hashmap的新节点是添加到什么地方(链头还是链尾)
分析:这个题巨坑啊,还要分版本1.8之前都是添加到链表的头部,1.8之后是添加到尾部
JDK7U79的版本table[bucketIndex] =newEntry<>(hash, key, value, e);
JDK8U60的版本p.next = newNode(hash, key, value,null);
4.2个FIFO队列实现栈的效果,简单来说就是abc逆序打印
分析:2个FIFO队列分别是F1,F2
先把abc依次放到F1,再把ab依次取出并放回到F1,那么F1的顺序现在是bac,
将c放到F2,再将a取出放回F1,那么F1现在的顺序是ab,
再将ab依次从F1中取出放到F2,这时从F2取出的顺序就是 c,b,a
5.sqlserver和mysql的区别
分析:
6.mysql中myisam和InnoDB在索引上的区别
分析:
MyISAM
InnoDB
使用前缀压缩技术是的索引更小
按照原数据格式进行存储
通过数据的物理位置引用被索引的行
通过主键引用被索引的行
myisam记录的直接是文件的offset
InnoDB寻址要映射到块,再到行
自适应哈希索引,是系统对热点索引
自动创建的内部行为,
用户无法控制或者配置
6.1MySQL存储引擎MyISAM与InnoDB的优劣(自己引申出来的题)
MyISAM
InnoDB
存储结构
每张表被存放在三个文件:frm-表格定义
MYD(MYData)-数据文件
MYI(MYIndex)-索引文件
所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB
存储空间
MyISAM可被压缩,存储空间较小
InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引
可移植性、备份及恢复
由于MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作
免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了
事务安全
不支持 每次查询具有原子性
支持 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表
AUTO_INCREMENT
MyISAM表可以和其他字段一起建立联合索引
InnoDB中必须包含只有该字段的索引
SELECT
MyISAM更优
INSERT
InnoDB更优
UPDATE
InnoDB更优
DELETE
InnoDB更优 它不会重新建立表,而是一行一行的删除
COUNT without WHERE
MyISAM更优。因为MyISAM保存了表的具体行数
InnoDB没有保存表的具体行数,需要逐行扫描统计,就很慢了
COUNT with WHERE
一样
一样,InnoDB也会锁表
锁
只支持表锁
支持表锁、行锁 行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的
外键
不支持
支持
FULLTEXT全文索引
支持
不支持 可以通过使用Sphinx从InnoDB中获得全文索引,会慢一点
7.treemap实现原理,如何实现的有序
分析:以二叉树实现treemap,内部组合compare来实现比较和排序,
8.mysql优化
分析:从几个方面来谈
数据库引擎
InnoDB支持事务
数据库字段选择
索引优化
查询性能优化
分表分库
mysql服务器优化
操作系统和硬件优化
主从设置
9.一个十亿行记录的文本,如何从中查询是否含有某个字符串
分析:从网上搜到 有人说用
lucene
compass(我没见过这个东西)
用搜索引擎进行搜索 。如:elasticsearch, solar。
10.查询某个压缩包中压缩的文本文件中是否含有某个字符串
分析:
11.如何通过linux命令将一个文件传输到另外一台服务
分析:scp
12.问到了mq,不过我确实是没做过也没看过,所以就没往下问
13.判断链表有环
分析:
方案1:
遍历链表中每一个 节点,然后放到一个 hashmap(我面试当时说的是数组)中,然后key重复了就说明有环.
方案2:
参考下面代码,利用temp2 步子大,跑得快,可以 套temp1的圈,总会有碰到 的时候(这个时候不一定就是 交叉的那个环点).
public static boolean hasLoop(Node n) {
// 定义两个指针tmp1,tmp2
Node tmp1 = n;
Node tmp2 = n.next;
while (tmp2 != null) {
tmp1 = tmp1.next; // 每次迭代时,指针1走一步,指针2走两步
tmp2 = tmp2.next.next;
if (tmp2 == null)
return false;// 不存在环时,退出
int d1 = tmp1.val;
int d2 = tmp2.val;
if (d1 == d2)
return true;// 当两个指针重逢时,说明存在环,否则不存在。
}
return true; // 如果tmp2为null,说明元素只有一个,也可以说明是存在环
}
14.写一段sql,实现类似于if else的功能,比如判断是否含有某条记录,有则更新,无则追加.
分析:这个需要用到存储过程:
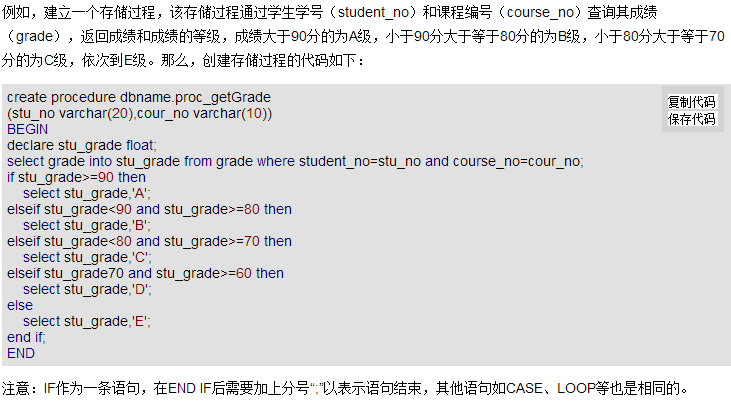
15.代码审查,代码走查等,工具
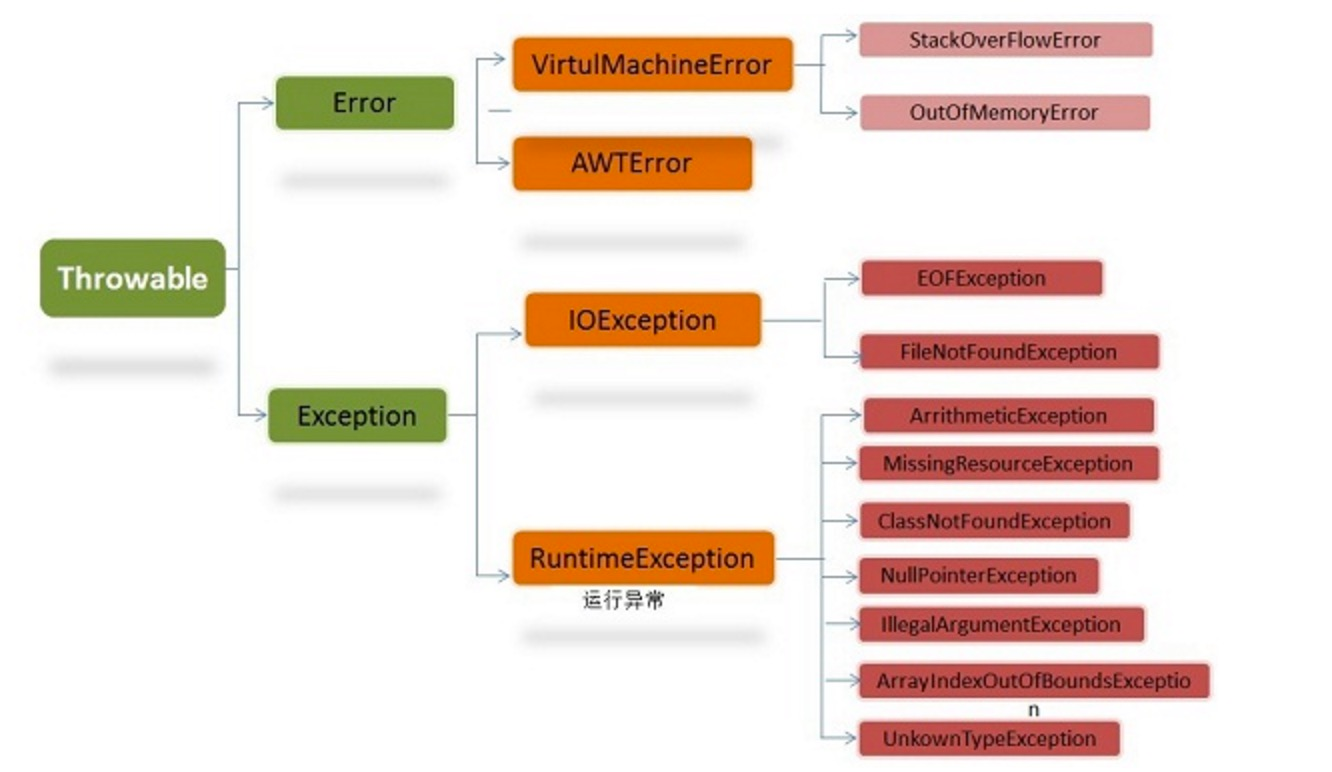
16.单元测试,Junit,mock
17.异常和错误的继承关系,并说几种运行时异常
分析:
18.dubbo服务提供者中的异常设置,消费者捕获后如何处理
分析:
18.1根据不同情况抛出不同的异常信息,包含自定义异常
18.2比如根据不同的自定义异常来判断是否需要回滚或者重试等


