
- 12023中大厂Android面试八股文合集,GitHub,牛客,leetcode已爆火!
- 2Unity鼠标移动到物体上显示信息
- 3数据仓库内容分享(六):数据仓库层次化设计_数据仓库app层
- 4cuda pytorch torchvision torchaudio版本对应_cuda11.8对应的torchvision和torchaudio
- 5git clone时账号密码弹窗不出现(认证失败)的解决方法_remote: 认证失败,请确认您输入了正确的凭证。
- 6全网最细-华为Atlas开发板联网升级、Mind Studio配置和部署深度学习vgg16样例_huawei atlas rgbtorgbp
- 7Git push长时间无反应或处于等待状态_git push -u origin master没反应
- 8双链表——双链表的定义及其基本操作(初始化、头插法尾插法建表、插入、查找、删除、判空等)_双链表尾插法
- 9你见过这样的爹娘和老婆吗(看的我都哭了)
- 10Git下载和安装步骤
MySQL MVCC的详解之Read View_mysql mvcc readview
赞
踩
概要
在上文中,我们提到了MVCC(Multi-Version Concurrency Control)多版本并发控制,是通过undo log来实现的。那具体是如何实现的呢?将在本文一一道来。
MVCC是为了实现非阻塞读,即提高数据库并发读能力的一种机制。
通常来说,A事务正在修改数据行X,在修改未结束前,B事务要读数据行X,为了避免读到脏数据,B就会被阻塞,直到A事务修改完数据行X,MVCC很好的避免了这种情况的发生。
MVCC是通过保存数据在某个时间点的快照来实现的,即保存一个数据行的多个变更版本(空间换时间)。这些版本就是undo log了,每一行的变更记录就存在undo log中,通过链表联系在一起,构成了一个完整的版本链,供MVCC实现非阻塞读。
例如在可重复读隔离级别下,A事务正在修改数据行X,在修改数据行X前会把其当前记录插入到版本链中,B事务要读数据行X就到版本链中找符合的,这样B就不会被阻塞了。
ps:MySQL的MVCC只作用于在REPEATABLE READ和READ COMMITED两个隔离级别下执行普通的SELECT操作。
在高性能MySQL第三版一书中对MVCC的操作描述如下:
 下面来一起探索下具体实现吧。
下面来一起探索下具体实现吧。
本文背景:MySQL InnoDB存储引擎。
一、基于UNDO LOG的版本链
在了解版本链之前,首先看一下InnoDB存储引擎的行记录。
1.1、行记录结构
提到MySQL的行记录,肯定会想到行ID、用户数据列等内容,除了这些信息外,还有一些隐藏信息,比如事务ID、回滚指针等其他额外信息,那我们可以得出下图:

其中事务ID(trx_id)、回滚指针(rollback_ptr)是本文要讲的核心。
ps:InnoDB的行记录是存储在聚族索引中的
1.2、了解UNDO LOG
MySQL undo log结构示意图
- 1

MySQL的undo log分为两大类:
- insert undo:insert 操作产生的,记录了table_id、trx_id、主键各列数据等信息。
- update undo:update和delete操作产生的,
虽说update和delete操作产生的undo log都会记录到update undo这个大类,但其记录内容是有很大差距的。
delete操作产生的undo log会记录table_id、trx_id、rollback_ptr、主键各列数据等信息,而update操作产生的undo log会记录更新table_id、trx_id、rollback_ptr、被更新列旧值、主键各列数据等信息。
ps:可以看到undo log中并没有记录用户列数据
1.3、版本链
我们现在在test库下有一个test表:
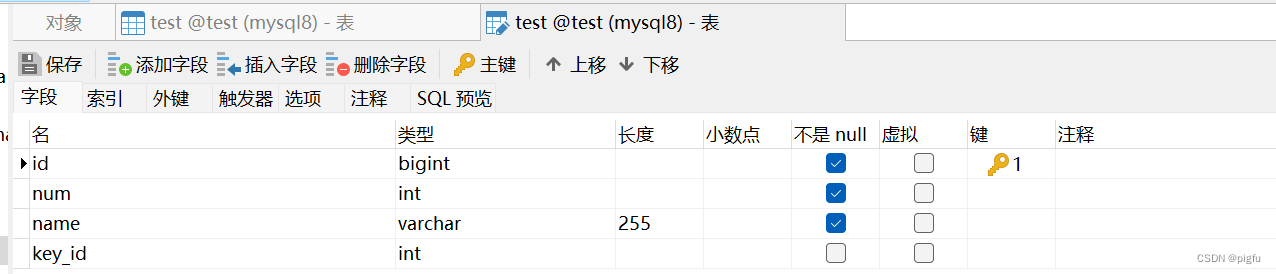 下面我们经过一系列插入,删除,更新来演示版本链的变迁:
下面我们经过一系列插入,删除,更新来演示版本链的变迁:
假设当前全局trx_id = 101。
- 插入一条数据
insert into test (id,num,name,key_id) values (1,1,"bob",11);
- 1
此时有:
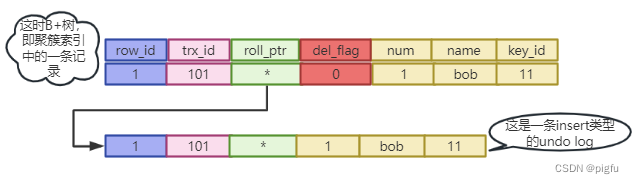
- 更新数据
1)令id=1的数据name=tom
update test set name = "tom" where id = 1;
- 1
此时有:
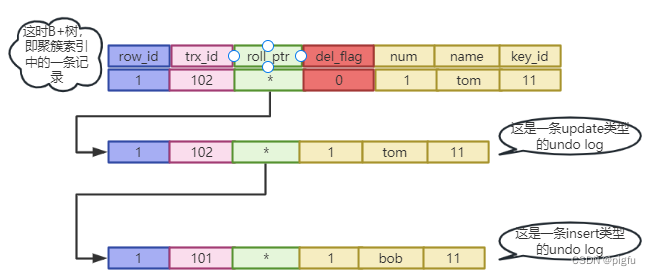
2)令id=1的数据name=join
update test set name = "join" where id = 1;
- 1
此时有:
- 删除数据,删除id=1的数据
delete from test where id = 1;
- 1
此时有:
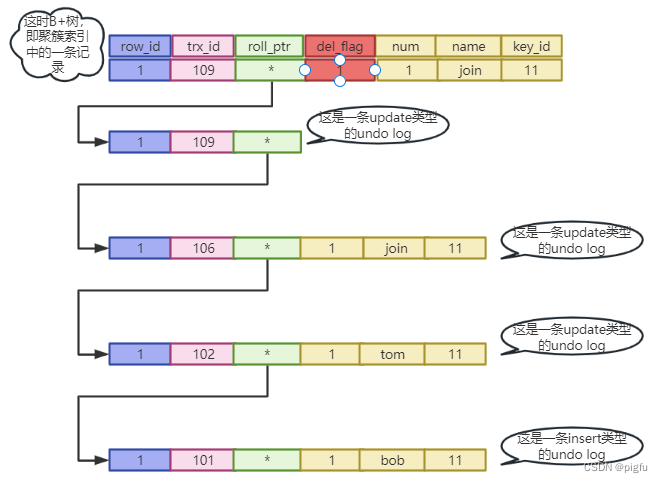
如上图,在对id=1这一条记录的插入,更新,删除的过程中构建了一个版本链。其中删除操作,只是在聚簇索引上的记录中打了删除标记,并不会立即删除,而是当没有Read View持有该事务ID时才会有purge线程去真的去删除,之后这块空间才能被使用,为什么不能立即删除呢,主要是因为undo log中并不保存所有的用户列数据,甚至不保存,都是基于聚簇索引中的记录行,在结合undo log内容,在回滚过程中构造某个版本的数据。
另外,我们在1.2小节中强调了 undo log中并不记录用户列数据,这里只是为了表示方便才画了出来,其实MySQL是基于聚簇索引上的记录内容,通过从聚簇索引上的记录roll_ptr开始,依次回滚,直到遇到符合要求的事务ID,构造出最终数据。
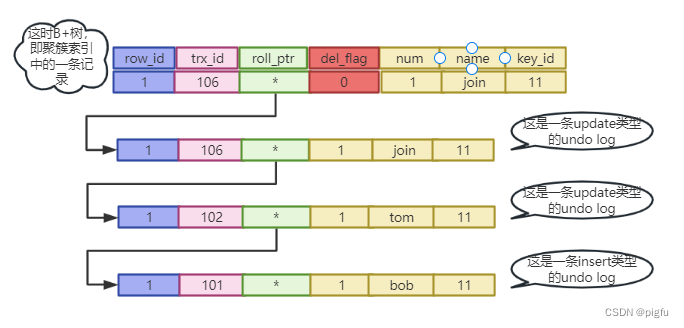
假设第二次更新操作开始但未提交时,有个trx_id=107的事务要读id=1的数据,此时发现ID=1的数据trx_id=106且处于活跃状态,则需要沿着版本链回滚,当遇到trx_id=102的记录,结合聚簇索引上的记录和trx_id=102的undo记录,构造出trx_id=102的完整数据,对于trx_id=107的事务来说,该事务是已提交的事务,则读取即可。其实这就是Read View了,详情请看下一章节。
二、Read View
对于READ COMMITED隔离级别,需要读已经提交的数据,那当A事务修改完聚簇索引上的记录X后尚未提交,此时B事务读取记录X,按照定义,此时聚簇索引上的记录是不允许读取的,如何判定呢?就依赖Read View机制了
对于REPEATABLE READ隔离级别,需要重复读数据,那当A事务读取记录X后,B事务修改完聚簇索引上的记录X并提交,此时A事务需要在此读取记录X,按照定义,此时聚簇索引上的记录是不允许读取的,如何判定呢?也就依赖Read View机制了
Read View也称作一致性视图,其主要包含4个主要的内容:
- m_ids:在生成Read View时,当前系统中活跃的读写事务的事务ID列表;
- min_trx_id:在生成Read View时,当前系统中活跃的读写事务中最小的事务ID,即m_ids中的最小值;
- max_trx_id:在生成Read View时,当前系统中活跃的读写事务中最大的事务ID,即系统应该分配给下一个事务的事务ID(全局事务ID的值);
- creator_trx_id:在生成Read View时,当前事务的事务ID。
其中max_trx_id要注意下,并不一定是m_ids中的最大值,而是生成Read View时的全局事务ID值。因为事务ID时递增(循环)分配的,在RR隔离级别下,假设当前活跃的事务ID有1,2,3,事务ID=3的事务提交后,再开启一个事务A,发起读操作,此时Read View时m_ids=[1,2,4],min_trx_id=1,max_trx_id=4,如果有另一个写事务B提交了,消耗了一个事务ID=4,那么此时事务A进行写操作,就会出现creator_trx_id=5的情况。
为什么会这样呢?我们要明白事务ID的生成并不是开启事务(执行begin操作)时就确定的,而是第一次执行写操作时确定的。
而Read View生成时机是在读操作前确定的,但RC与RR还不同,RC是每次读操作前都生成一个Read View(保证可以读已提交数据),而RR是在第一次读操作前生成一个Read View,就不会变动了(保证可重复读)。
2.1、判定机制
MySQL根据Read View读要访问的记录依次进行以下判定,来决定是否可访问:
- 如果被访问记录的trx_id等于creator_trx_id相等,这意味当前事务在访问它自己修改的记录,允许被访问;
- 如果被访问记录的trx_id小于min_trx_id,这意味被访问记录在当前事务生成Read View时已经提交了,允许被访问;
- 如果被访问记录的trx_id大于等于max_trx_id,这意味被访问记录在当前事务生成Read View之后产生的,不允许被访问;
- 如果被访问记录的trx_id在m_ids中,说明在当前事务生成Read View时被访问记录所属的事务还是活跃的,不允许被访问;
- 如果被访问记录的trx_id不在m_ids中,说明在当前事务生成Read View时被访问记录所属的事务已经提交了,允许被访问;
以上的判定机制,是实现RC和RR的基础。
select trx_id,trx_state,trx_started,trx_rows_locked from INFORMATION_SCHEMA.INNODB_TRX; #可以查看当前活跃的事务id等信息
针对1.3小节的版本链案例:
我们依次执行下面四个语句,看看效果如何(RR隔离级别):
1:
insert into test (id,num,name,key_id) values (1,1,"bob",11);#事务id = 101
- 1
2:
begin;
update test set name = "tom" where id = 1; #事务id = 102
- 1
- 2
3:
insert into test (id,num,name,key_id) values (2,2,"2ob",22);#事务id = 103
insert into test (id,num,name,key_id) values (3,3,"3ob",33);#事务id = 104
- 1
- 2
4:
begin;
update test set name = "uuu" where id = 2; #事务id = 105
- 1
- 2
5:
begin;
select * from test where id = 1;
update test set name = "uuu" where id = 3; #事务id = 106
- 1
- 2
- 3
那么第五句select * from test where id = 1;的Read View如下:
m_ids=[102,105],min_trx_id=102,max_trx_id=106, creator_trx_id = 0
针对id=1这条记录,此时test表聚簇索引中的记录是 (1,1,"tom",11),隐藏字段trx_id=102。但是102在m_ids中,所以不可见,根据其undo log得到最终结果 (1,1,"bob",11)
2.2、源码
MySQL V8.0.32
- 生成Read View
/*调用链如下 trx_assign_read_view trx_sys->mvcc->view_open(MVCC::view_open) view->prepare(ReadView::prepare) */ //下面来看看核心的prepare函数干了什么 /* Opens a read view where exactly the transactions serialized before this point in time are seen in the view. @param id Creator transaction id */ void ReadView::prepare(trx_id_t id) { ut_ad(trx_sys_mutex_own()); m_creator_trx_id = id; //赋值creator_trx_id m_low_limit_no = trx_get_serialisation_min_trx_no(); m_low_limit_id = trx_sys_get_next_trx_id_or_no();//系统应该分配给下一个事务的事务ID,即max_trx_id ut_a(m_low_limit_no <= m_low_limit_id); if (!trx_sys->rw_trx_ids.empty()) { copy_trx_ids(trx_sys->rw_trx_ids); //将此刻全局活跃跃事务列表ids 赋值给当前READ VIEW的m_ids属性 } else { m_ids.clear(); } /* The first active transaction has the smallest id. */ m_up_limit_id = !m_ids.empty() ? m_ids.front() : m_low_limit_id;//获取当前活跃事务列表中的最小事务id,即min_trx_id ut_a(m_up_limit_id <= m_low_limit_id); ut_d(m_view_low_limit_no = m_low_limit_no); m_closed = false; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
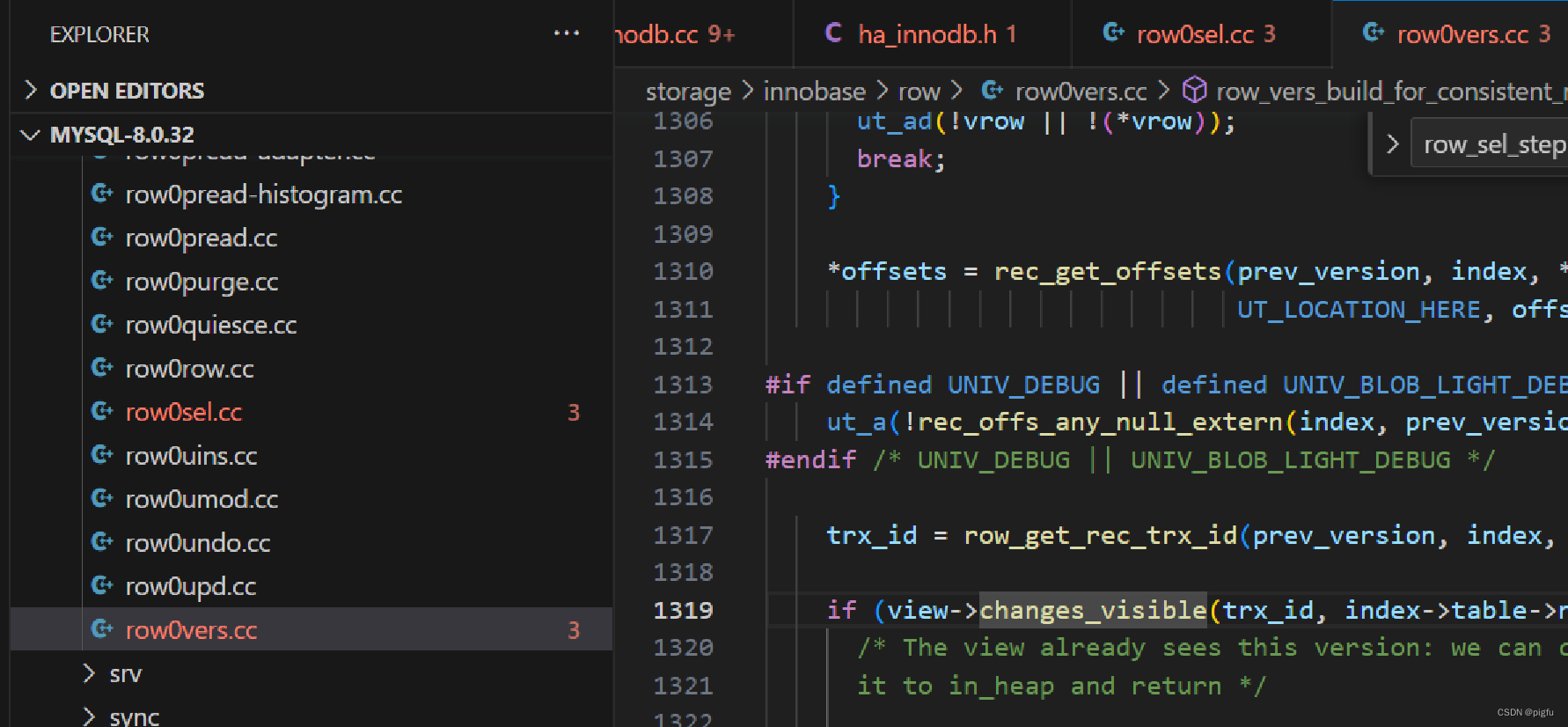
- Read View判定
/** Check whether the changes by id are visible. @param[in] id transaction id to check against the view @param[in] name table name @return whether the view sees the modifications of id. */ [[nodiscard]] bool changes_visible(trx_id_t id, const table_name_t &name) const { ut_ad(id > 0); if (id < m_up_limit_id || id == m_creator_trx_id) {//小于min_trx_id 或等于 creator_trx_id 则允许访问 return (true); } check_trx_id_sanity(id, name); if (id >= m_low_limit_id) { //大于max_trx_id 则不允许访问 return (false); } else if (m_ids.empty()) {//m_ids为空则允许访问 return (true); } const ids_t::value_type *p = m_ids.data(); return (!std::binary_search(p, p + m_ids.size(), id));//二分查找,在m_ids不允许访问,不在则允许访问 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

