
- 1【机器学习-周志华】学习笔记-第十章_周志华第十章答案
- 2STM32开发之模拟I2C与MPU6050通信_模拟i2c delay.h
- 3ElasticSearch~ES索引操作~对索引的增删改查_es 修改索引配置
- 4基于eNSP的千人中型校园/企业网络设计与规划(可以自己按步骤实现)_ensp智能小区的网络规划与设计
- 5操作系统课程设计之处理机调度_编写并实现对n个进程使用动态优先权算法的进程调度c语言
- 6vue循环发起请求,等一个请求结束后,进行下一次请求
- 7VMware Horizon view 7 云桌面终端安全解决方案_view云桌面 内存计算容量
- 8通过docker在容器中通过Gunicorn运行flask
- 9mac 远程ftp服务器文件共享,mac远程连接ftp服务器配置
- 10Git之HEAD和origin_git head origin
神经网络理解:前向传播与反向传播_神经网络前向传播和反向传播
赞
踩
参考资料
主要基于参考资料的学习整理。
神经网络
神经网络通俗地可以理解成一个函数近似器,它需要近似一个输入x到输出y的映射函数。我们所要训练的网络参数其实就是在拟合这个映射函数的未知量。神经网络的训练可以分为两个步骤:一个是前向传播,另一个是反向传播。
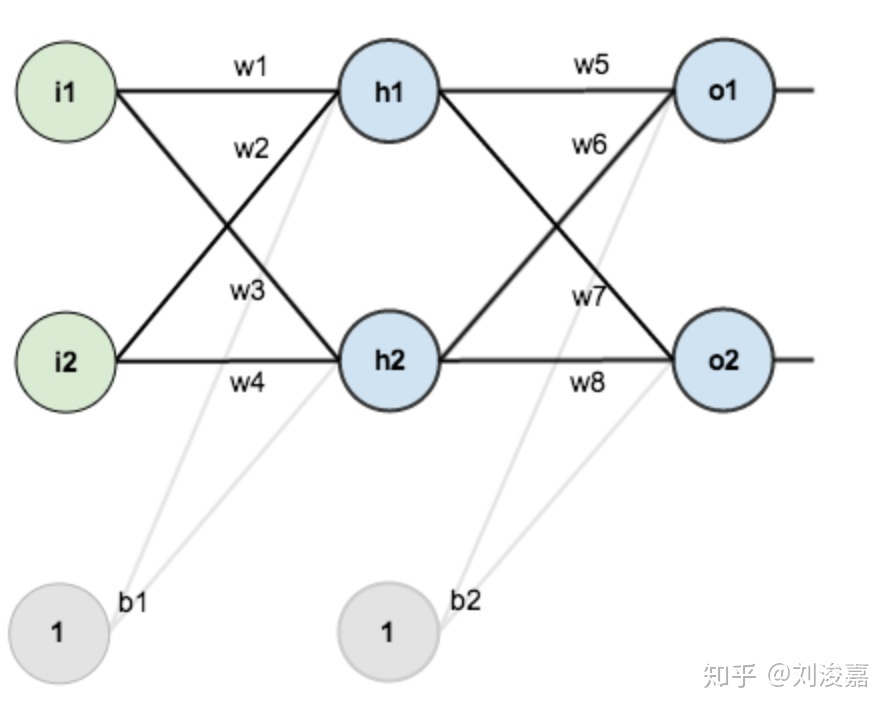
前向传播
神经网络前向传播从输入层到输出层:前向传播就是从输入层开始,经过一层层的Layer,不断计算每一层的神经网络得到的结果及通过激活函数的本层输出结果,最后得到输出的过程。
1. 输入层->隐含层
计算神经元 h 1 h1 h1 的输入加权和:
n e t h 1 = w 1 ∗ i 1 + w 2 ∗ i 2 + b 1 ∗ 1 net_{h1}=w_1*i_1+w_2*i_2+b_1*1 neth1=w1∗i1+w2∗i2+b1∗1
激活后的输出 :
o u t h 1 = 1 1 + e − n e t h 1 out_{h1}=\frac{1}{1+e^{-net_{h1}}} outh1=1+e−neth11
其余隐层节点同理。
2. 隐含层->输出层
计算输出神经元
o
1
o1
o1的值:
n
e
t
o
1
=
w
5
∗
o
u
t
h
1
+
w
6
∗
o
u
t
h
2
+
b
2
∗
1
net_{o1}=w_5*out_{h1}+w_6*out_{h2}+b_2*1
neto1=w5∗outh1+w6∗outh2+b2∗1
o
u
t
o
1
=
1
1
+
e
−
n
e
t
o
1
out_{o1}=\frac{1}{1+e^{-net_{o1}}}
outo1=1+e−neto11
其余输出节点同理。
反向传播
-
前向传播计算出了输出值(也即预测值),就可以根据输出值与目标值的差别来计算损失loss。
-
反向传播就是根据损失函数loss来反方向地计算每一层的偏导数,从最后一层逐层向前去改变每一层的权重,也就是更新参数,核心就是损失函数对每一网络层的每一个参数求偏导的链式求导法则。
1. 计算总误差
首先,我们需要通过前向传播的输出 o u t p u t output output和真实样本 t a r g e t target target计算此时神经网络的损失
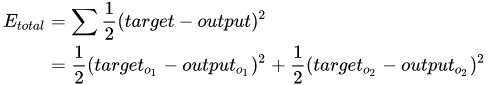
2. 隐藏层与输出层之间的权重更新
以权重
w
5
w_5
w5为例,对参数
w
5
w_5
w5求偏导可以看出
w
5
w_5
w5对整体误差产生的影响,总体误差对
w
5
w_5
w5求偏导的链式规则如下所示:
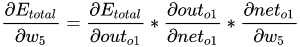
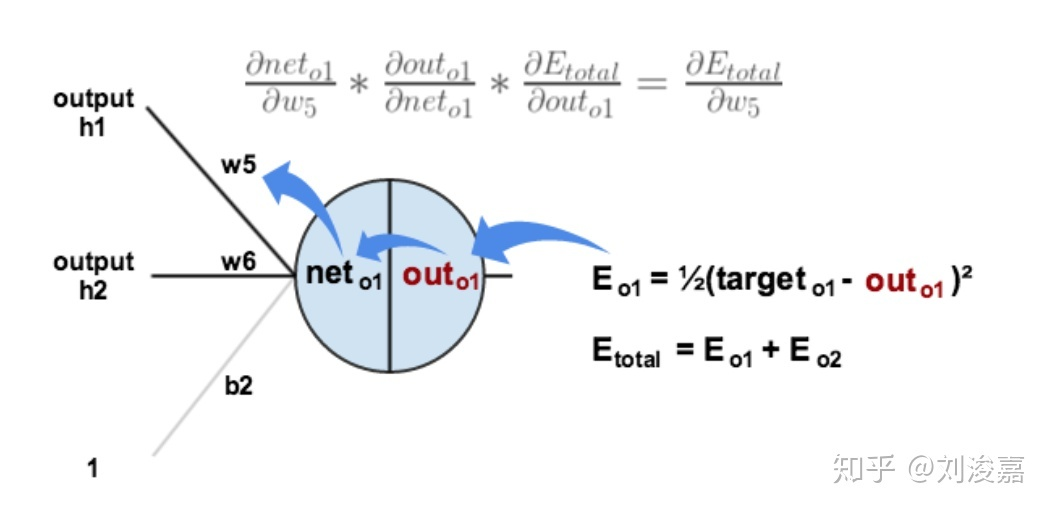
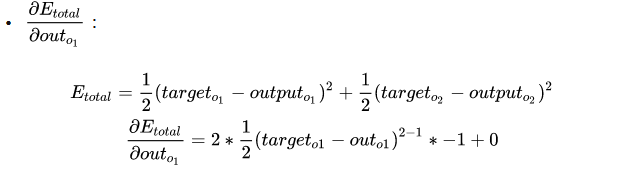
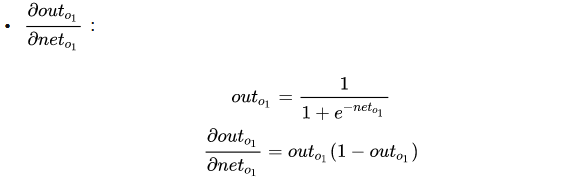
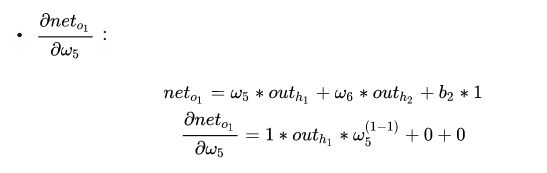
最后三者相乘,下面的任务就是进行梯度下降从而更新参数:

η \eta η 为 learning rate,其余权重同理。
3. 输入层与隐藏层之间的权重更新
以权重 w 1 w1 w1为例
∂ E total ∂ w 1 = ∂ E total ∂ o u t h 1 ∗ ∂ o u t h 1 ∂ n e t h 1 ∗ ∂ net h 1 ∂ w 1 \frac{\partial E_{\text {total }}}{\partial w_{1}}=\frac{\partial E_{\text {total }}}{\partial out_{h_1}} * \frac{\partial out_{h_1}}{\partial net_{h_1}} * \frac{\partial \text {net}_{h_1}}{\partial w_{1}} ∂w1∂Etotal =∂outh1∂Etotal ∗∂neth1∂outh1∗∂w1∂neth1
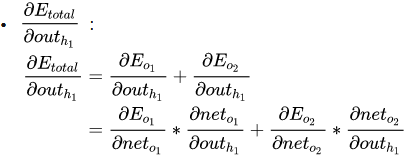
计算方法与上述步骤一致
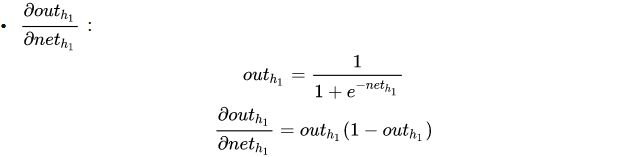
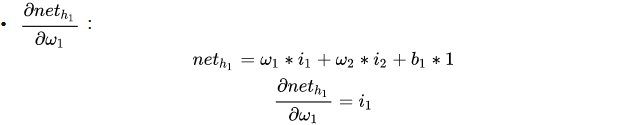
最后三者相乘,进行梯度下降从而更新参数:
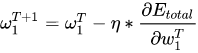
4. 梯度下降
神经网络就是通过不断的前向传播和反向传播不断调整神经网络的权重,最终到达预设的迭代次数或者对样本的学习已经到了比较好的程度后,就停止迭代,那么一个神经网络就训练好了。这就是神经网络的本质:通过计算误差、不断修正权重以拟合输入输出的映射函数曲线。

