
- 1无损APE,FLAC,盗版CD与原CD的差别(转载)
- 2强化学习能挑战众多世界冠军,人类亦能利用强化学习成为冠军
- 3spring boot框架_探索微框架:Spring Boot
- 4从 TikTok 危机看去中心化应用未来曙光 | ArcBlock 博客
- 51.Git下载及其安装
- 6【SQL Server】利用函数(Function)判断输入的数是不是质数_sql server 判断给定的数是否是素数
- 7【多传感融合】优达学城多传感融合学习笔记(三)——将激光雷达3D点云映射到相机图像(上)_激光雷达投影到图像
- 8Git详解之四 服务器上的Git_revent abuse, only git is allowed
- 9信创操作系统--统信UOS桌面版(使用终端:bash、tty、基本shell操作)_统信uos系统终端命令
- 102022年终总结_dream life csdn
【强烈建议收藏:MySQL面试必问系列之事务专题【事务ACID四大特性以及实现原理】、【数据库事务的隔离级别】、【事务并发带来的问题、脏读、不可重复读、幻读】、【MySQL事务并发以及锁机制】】_面试题mysql acid
赞
踩
一.面试开始
面试官拿出你的简历一看,这小伙子会MySQL,那我必须要好好问问他了,看看他掌握的怎么样?

二.什么是事务的四大特性ACID?
原子性: 原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个sql语句执行失败,则已执行的语句也必须回滚,数据库退回到事务前的状态。
一致性: 事务执行前后,数据保持一致,多个事务对同一个数据读取的结果是相同的
隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的
持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
你以为这要结束了吗,其实才这个问题才刚刚开始?
三.那ACID是怎么实现的呢?
拓展:首先介绍一下MySQL的事务日志。MySQL的日志有很多种,如二进制日志、错误日志、查询日志、慢查询日志等,此外InnoDB存储引擎还提供了两种事务日志:redo log(重做日志)和undo log(回滚日志)。其中redo log用于保证事务持久性;undo log则是事务原子性和隔离性实现的基础。
3.1 原子性实现原理
实现原理:undo log
- undo log是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句。
- InnoDB实现回滚,靠的是undo log,当事务对数据库进行修改时,InnoDB会生成对应的undo log。
- 如果事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
- undo log属于逻辑日志,它记录的是sql执行相关的信息。
- 当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:对于每个insert,回滚时会执行delete;对于每个delete,回滚时会执行insert;对于每个update,回滚时会执行一个相反的update,把数据改回去。
3.2 隔离性实现原理
实现原理:undo log+锁机制+MVCC
- 隔离性与原子性、持久性侧重于研究事务本身不同,隔离性研究的是不同事务之间的相互影响。
- 隔离性是指,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。严格的隔离性,对应了事务隔离级别中的Serializable (可串行化),但实际应用中出于性能方面的考虑很少会使用可串行化。
- 隔离性追求的是并发情形下事务之间互不干扰。
我们主要考虑最简单的读操作和写操作(加锁读等特殊读操作会特殊说明),那么隔离性的探讨,主要可以分为两个方面:
事务T1执行写操作对事务T2执行写操作的影响:锁机制保证隔离性
事务T1执行写操作对事务T2执行读操作的影响:MVCC保证隔离性
关于锁机制的相关内容我们下篇文章讲,否则内容过多,读者也会感觉接收不了。
3.3 持久性实现原理
实现原理:redo log
- InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为了提高效率,InnoDB提供了缓存(Buffer Pool)。
- Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。
- Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
- redo log被引入来解决这个问题:当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
拓展1:既然redo log也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:
1 刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。
2 刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
拓展2:redo log日志和与binlog日志的区别?
在MySQL中还存在binlog(二进制日志)也可以记录写操作并用于数据的恢复,但二者是有着根本的不同的:
1.作用不同:redo log是用于crash recovery的,保证MySQL宕机也不会影响持久性;binlog是用于point-in-time recovery的,保证服务器可以基于时间点恢复数据,此外binlog还用于主从复制。
2.层次不同:redo log是InnoDB存储引擎实现的,而binlog是MySQL的服务器层实现的,同时支持InnoDB和其他存储引擎。
3.内容不同:redo log是物理日志,内容基于磁盘的Page;binlog的内容是二进制的,根据binlog_format参数的不同,可能基于sql语句、基于数据本身或者二者的混合。
4.写入时机不同:binlog在事务提交时写入;redo log的写入时机相对多元:当事务提交时会调用fsync对redo log进行刷盘;这是默认情况下的策略,修改innodb_flush_log_at_trx_commit参数可以改变该策略,但事务的持久性将无法保证。除了事务提交时,还有其他刷盘时机:如master thread每秒刷盘一次redo log等,这样的好处是不一定要等到commit时刷盘,commit速度大大加快。
3.4 一致性实现原理
实现原理:原子性+隔离性+持久性
- 一致性是事务追求的最终目标:前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,除了数据库层面的保障,一致性的实现也需要应用层面进行保障。
- 实现一致性的措施包括:
-
保证原子性、持久性和隔离性,如果这些特性无法保证,事务的一致性也无法保证- 1
-
数据库本身提供保障,例如不允许向整形列插入字符串值、字符串长度不能超过列的限制等- 1
-
应用层面进行保障,例如如果转账操作只扣除转账者的余额,而没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致- 1
面试官:嗯,基础功还算扎实,那你知道事务的隔离级别吗?
四.事务的隔离级别你知道有哪些吗?
废话不多说,先上图,总览全局,然后再了解每个具体的隔离级别。如下图所示:
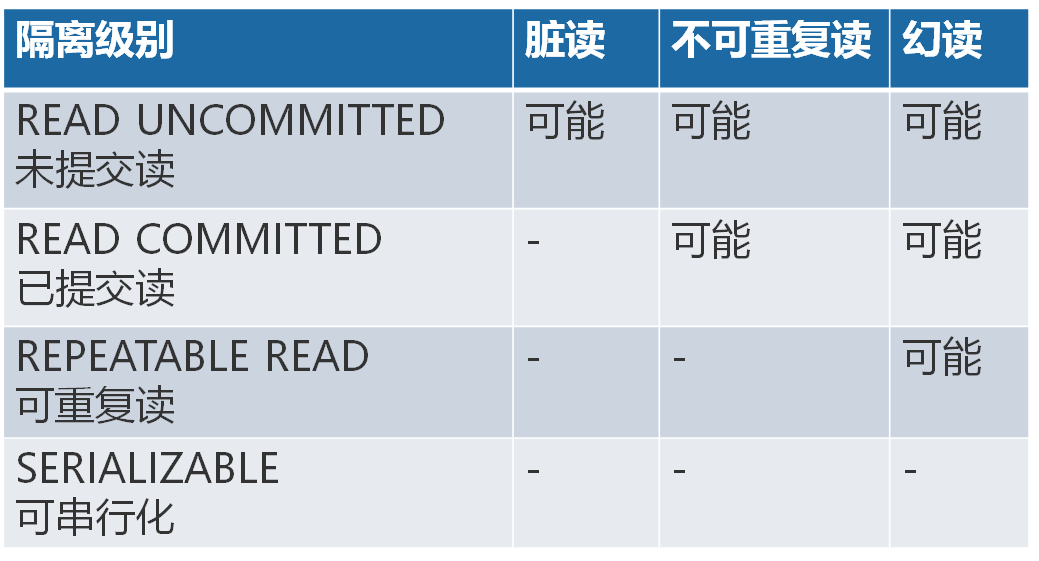
SQL标准中规定,针对不同的隔离级别,并发事务可以发生不同严重程度的问题,具体情况如下:
-
Read Uncommitted:在该隔离级别,可能发生脏读、不可重复读和幻读问题。所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
-
Read Committed:在该隔离级别,可能发生不可重复读和幻读问题,但是不可以发生脏读问题。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
-
Repeatable Read:隔离级别下,可能发生幻读问题,但是不可以发生脏读和不可重复读的问题。这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
-
Serializable:隔离级别下,各种问题都不可以发生。这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争,效率会比较低。
卑微的你: 回答了好长时间呀,心想是不是快要结束了呢
面试官:那你知道事务并发会带来什么问题吗?
五.面试官:你刚才也提到了事务并发带来的一些问题,具体分析一下吧?
事务并发会带来我们MySQL中俗称的脏读、不可重复读、幻读的问题。
上边介绍了几种并发事务执行过程中可能遇到的一些问题,按照问题严重性来简单排一下序:
脏读 > 不可重复读 > 幻读
5.1 事务并发带来的问题
-
脏读
脏读是指无效数据的读出,是指在数据库访问中, 事务 T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销rollback对该值的修改,这就导致了T2所读取到的数据是无效的,值得注意的是,脏读一般是针对于update操作的。 -
不可重复读
每次读取的数据都是不同的,比如说我们事务T1修改了数据,并且提交了事务,此时事务T2读取该值。然后事务T1又修改了值,此时再次提交,此时事务T2再次读取,发现此时和自己第一次读取的值是不一样的,就会出现不可重复读的影响。 -
幻读
当某个事务T1进行范围查询数据时,另一个事务T2在该范围内插入了数据,当事务T1再次范围查询时,数据变多了,和我们之前的结果也不一样,而且变多了,这个呢就是幻行(即多了事务b插入的那行数据)。
5.2 如何解决事务并发带来的问题呢?
这个问题呢主要还是想考察你是否了解MySQL底层的锁机制。这个问题呢需要回答的点也比较多,为了 让知识成体系,并且每一篇文章尽可能的不要过于长,接下来我们会专门开一篇文章来讲MySQL底层加锁的机制原理。
等不及的同学也可以看看这篇文章,我马上就会更新的。
六.总结
先感谢这篇文章的博主对于我总结ACID实现的原理有很大的帮助:
深入学习MySQL事务:ACID特性的实现原理
然后我们再一起来回顾一下这篇文章的主要内容
- 事务的四大特性ACID
- 四大特性底层实现的原理
- MySQL中日志的作用以及区别
- MySQL数据库事务隔离级别
- 事务并发存在的问题
- 提到了数据库锁机制+MVCC机制等等,这个我们后面会专门写一篇文章来讲关于这方面的内容。
然后想对屏幕前的你们说一句话,苦尽甘来,我们只管确定目标+为之努力,剩下的交给时间。
好啦,不说啦,我说硕风和炜,我们下篇文章见哦。

