
DAOS低时延与高性能RDMA网络_rdma能提升网络带宽吗
赞
踩
什么是RDMA
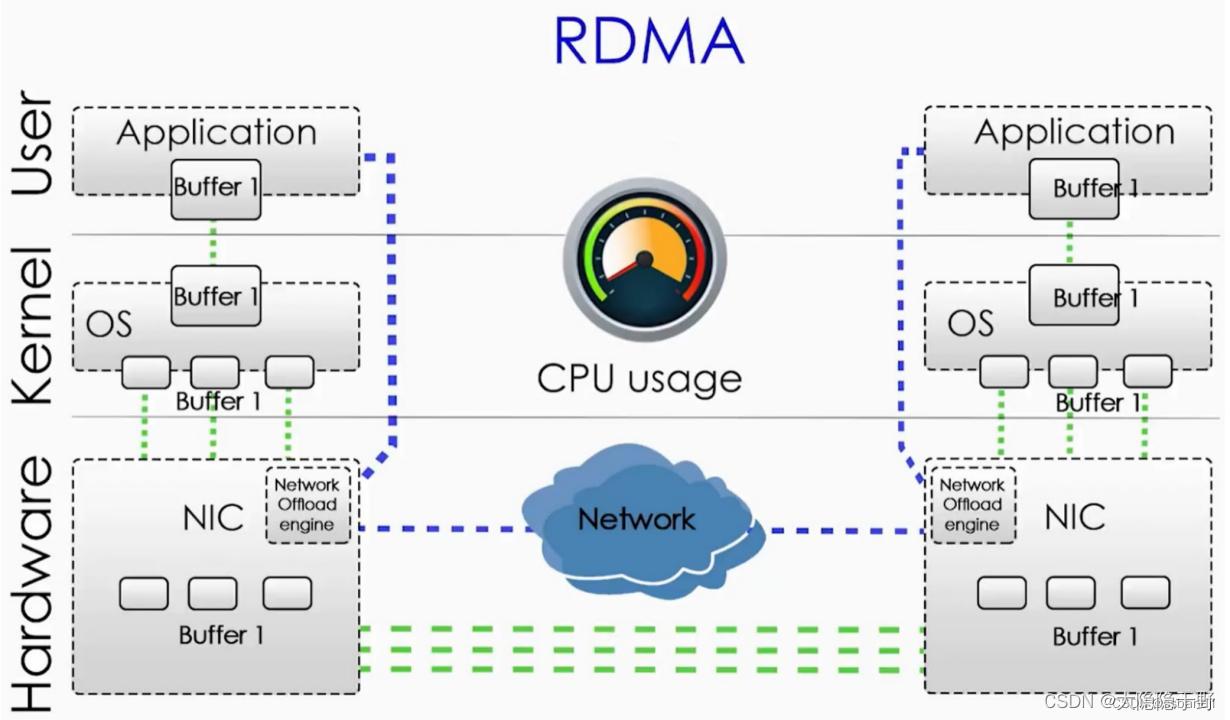
RDMA(Remote Direct Memory Access)远程直接内存访问是一种技术,它使两台联网的计算机能够在主内存中交换数据,而无需依赖任何一台计算机的处理器、缓存或操作系统。与基于本地的直接内存访问 ( DMA ) 一样,RDMA 提高了吞吐量和性能,因为它可以释放资源(如cpu),从而加快数据传输速率并降低延迟。在大规模并行计算机集群中特别有用,比如分布式存储,超算中心。
RDMA 通过网络适配器能够将数据从线路直接传输到应用程序内存或从应用程序内存直接传输到线路,支持零拷贝,无需在应用程序内存和操作系统中的数据缓冲区之间复制数据。 不需要 CPU、缓存或上下文切换完,并且数据传输与其他系统操作并行,减少了消息传输的延迟。
Remote Direct Memory Access远程直接内存访问是一种技术,它使两台联网的计算机能够在主内存中交换数据,而无需依赖任何一台计算机的处理器、缓存或操作系统。与基于本地的直接内存访问 ( DMA ) 一样,RDMA 提高了吞吐量和性能,因为它可以释放资源(如cpu),从而加快数据传输速率并降低延迟。RDMA 可以使网络和存储应用程序都受益
概念
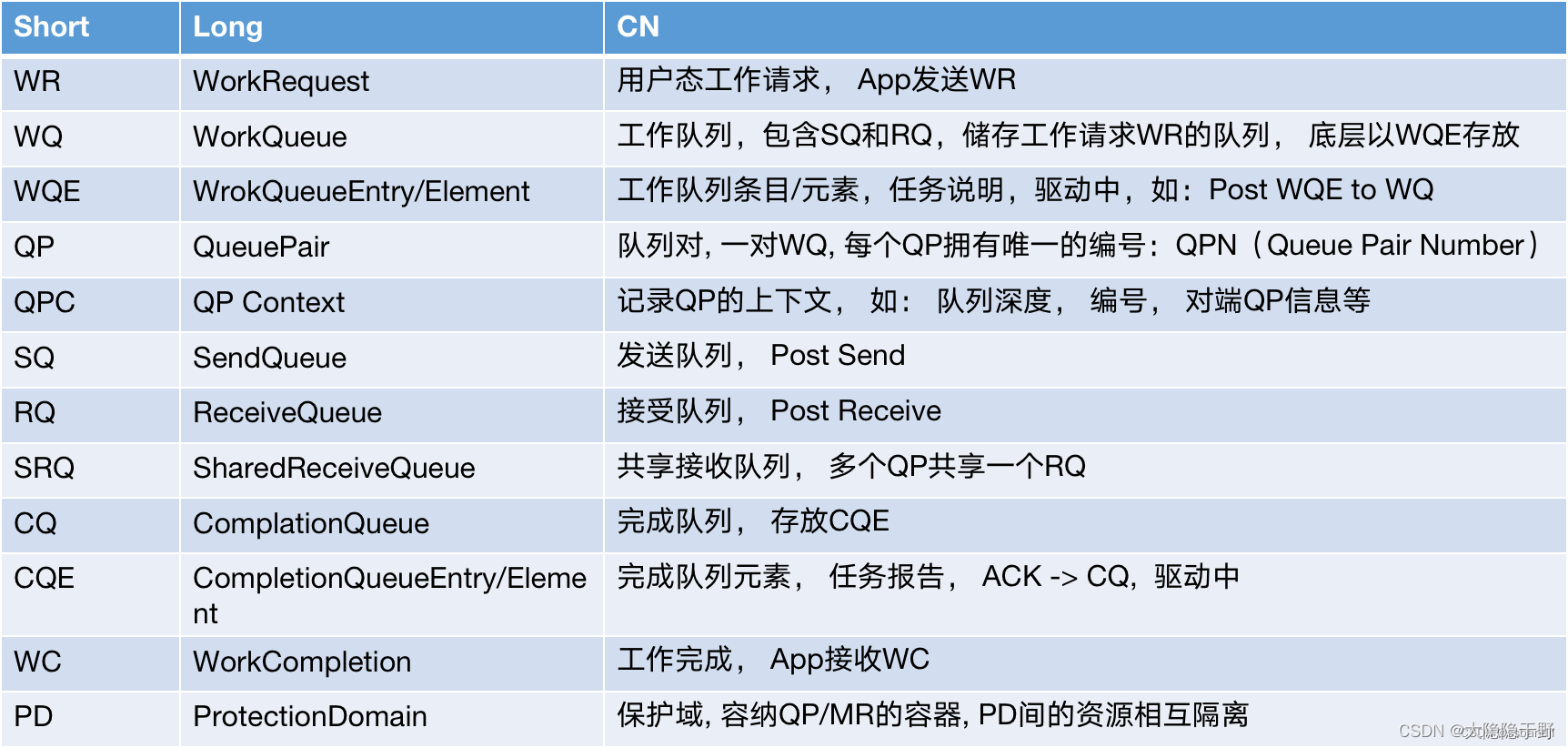
Fabric: 支持RDMA的局域网(LAN)
CA(Channel Adapter): 通道适配器, 将系统连接到Fabric的硬件组件, 本质是生产和消费包(packet)
HCA: Host Channel Adapter 主机通道适配器, 支持verbs接口的CA, 作用同上, ib协议对其定义为处理器和I/O单元中能够产生和消耗数据包的IB设备
Verbs: 访问RDMA硬件的“一组标准动作”。 每一个Verb可以理解为一个Function
RoCE: RDMA over Converged Ethernet (RoCE) protocol: rdma融合以太网协议
zero-copy networking: 零拷贝网络
bypass the kernel networking stack: 内核旁路(绕过内核)
high-performance computing (HPC): 高性能计算
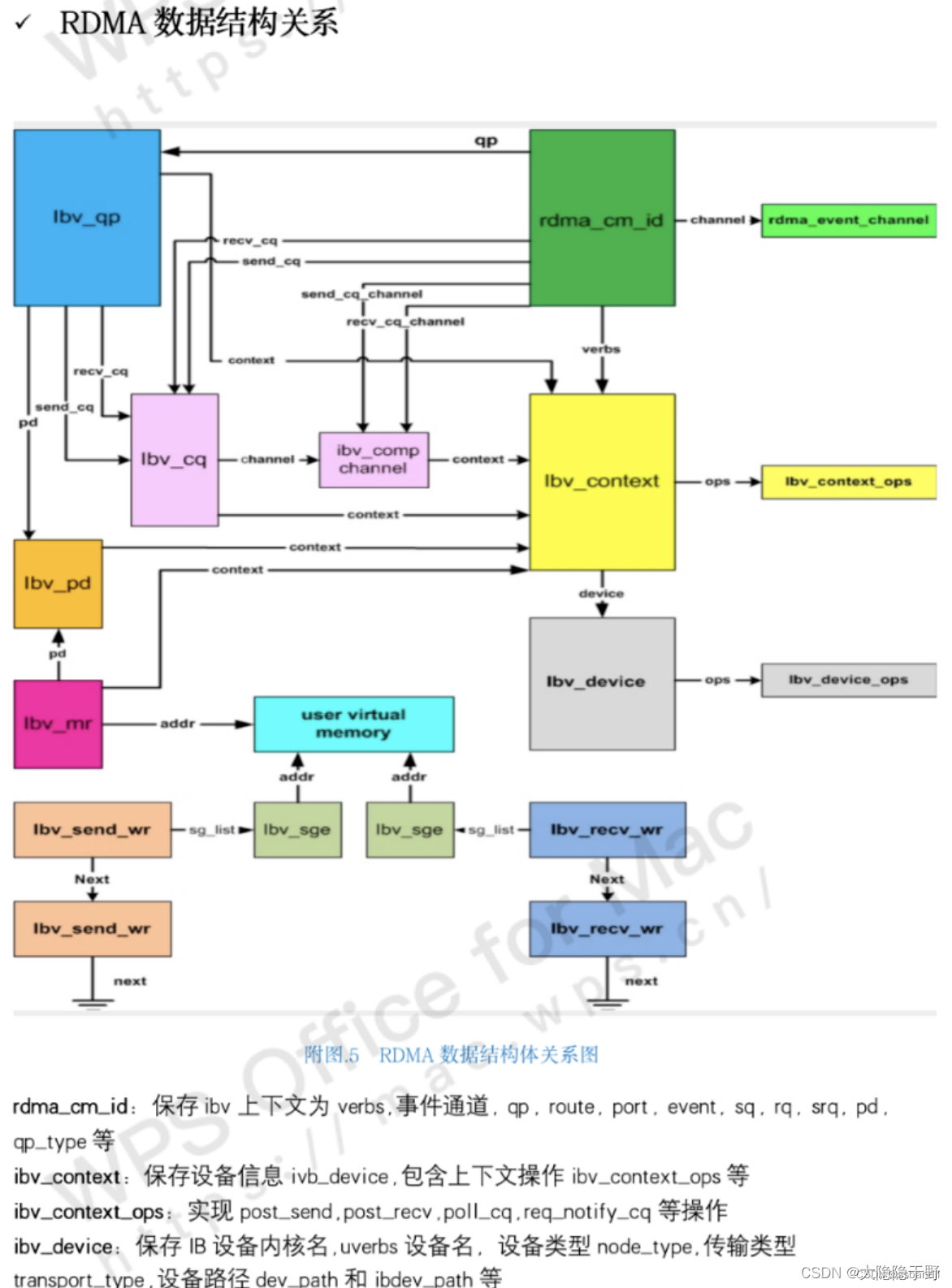
Memory Registration(MR) : 内存注册后, 操作系统不能对数据所在的内存进行页置换(page out)操作 – 物理地址和虚拟地址的映射必须是固定不变的, 底层调用内核提供的函数pin住内存(防止换页)
va -> pa
protect
pin: lock page(va<=>pa)
服务类型(队列对qp类型):连接(可靠RC/不可靠UC), 数据报(可靠RD/不可靠UD)
RDMA术语

优点
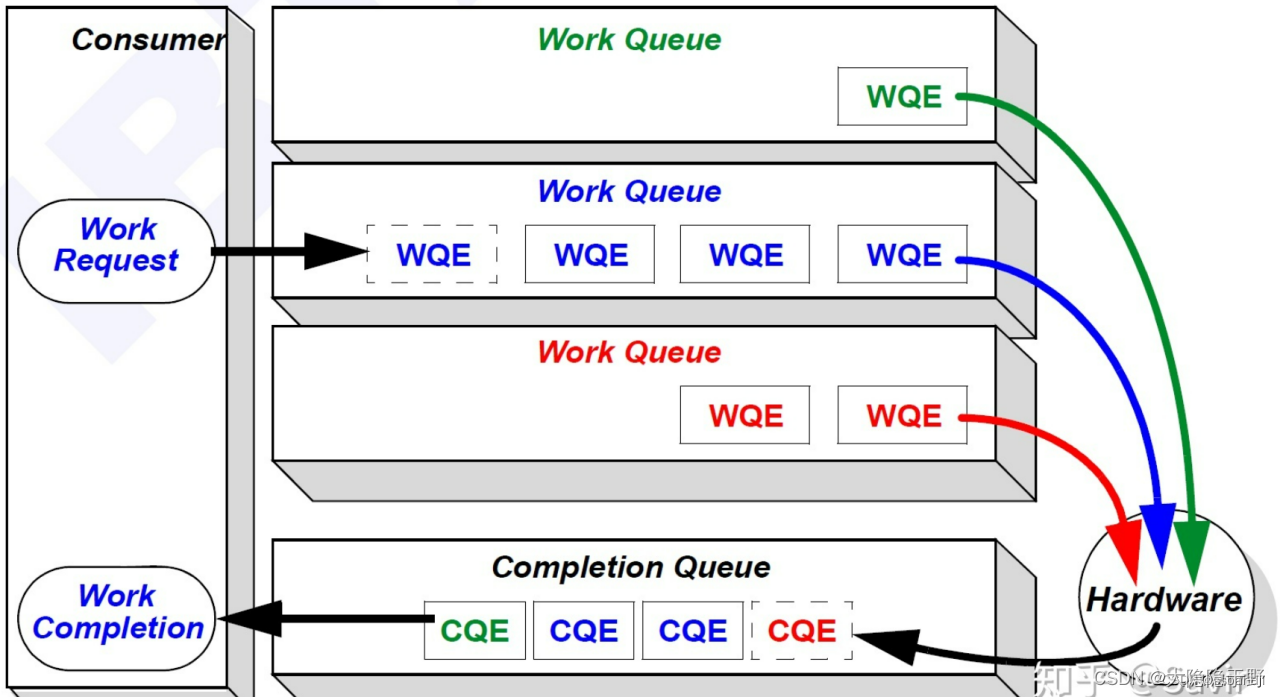
Zero-copy零拷贝-应用程序可以在不涉及网络软件堆栈的情况下执行数据传输,并且数据被直接发送到缓冲区,而无需在网络层之间复制。
Kernel bypass绕过内核 - 应用程序可以直接从用户空间执行数据传输,而无需执行上下文切换。
CPU Offload 卸载 - 应用程序可以访问远程内存而不消耗远程机器中的任何 CPU。无需远程进程(或处理器)的任何干预。远程 CPU 中的缓存也不会被传输过程中的内存内容填充。
Message based transactions 基于事务的消息 - 数据作为离散消息而不是作为流处理,这消除了应用程序将流分离为不同消息/事务的需要。
Scatter/gather entries 分散/聚集条目支持 - RDMA 支持本地处理多个分散/聚集条目,即读取多个内存缓冲区并将它们作为一个流发送或获取一个流并将其写入多个内存缓冲区
应用场景
低延迟 - 例如:HPC、金融服务、Web 2.0
高带宽 - 例如:HPC、医疗设备、存储和备份系统、云计算
CPU 占用空间小 - 例如:HPC、云计算
当今是云计算、大数据的时代,企业业务持续增长需要存储系统的 IO 性能也持续增长。传统的 TCP/IP 技术在数据包处理过程中,要经过操作系统及其他软件层,数据在系统内存、处理器缓存和网络控制器缓存之间来回进行复制,给服务器的 CPU 和内存造成了沉重负担。尤其是网络带宽、处理器速度与内存带宽三者的严重"不匹配性",更加剧了网络延迟效应。为了降低数据中心内部网络延迟,提高带宽,RDMA 技术应运而生。RDMA 允许用户态的应用程序直接读取和写入远程内存,避免了数据拷贝和上下文切换;并将网络协议栈从软件实现 offload 到网卡硬件,实现了高吞吐量、超低时延和低 CPU 开销的效果。
当前 RDMA 在以太网上的传输协议是 RoCEv2,RoCEv2 是基于无连接协议的 UDP 协议,相比面向连接的 TCP 协议,UDP 协议更加快速、占用 CPU 资源更少,但其传输是不可靠的,一旦出现丢包会导致 RDMA 的传输效率降低,这是由 RDMA 的 Go-back-N 重传机制决定的。RDMA 接收方网卡发现丢包时,会丢弃后续接收到的数据包,发送方需要重发之后的所有数据包,这导致性能大幅下降。所以要想 RDMA 发挥出其性能,需要为其搭建一套不丢包的无损网络环境。
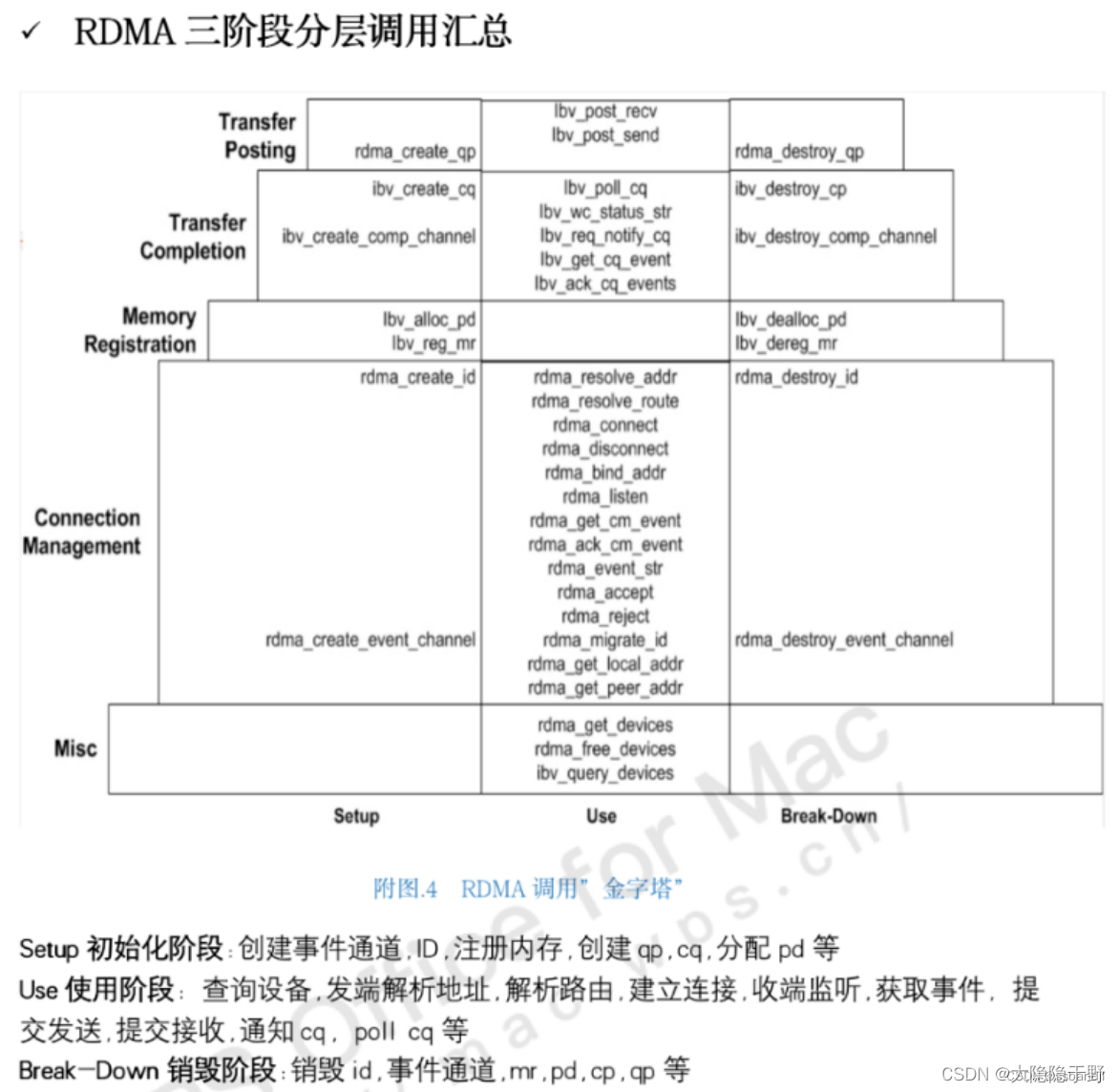
编程
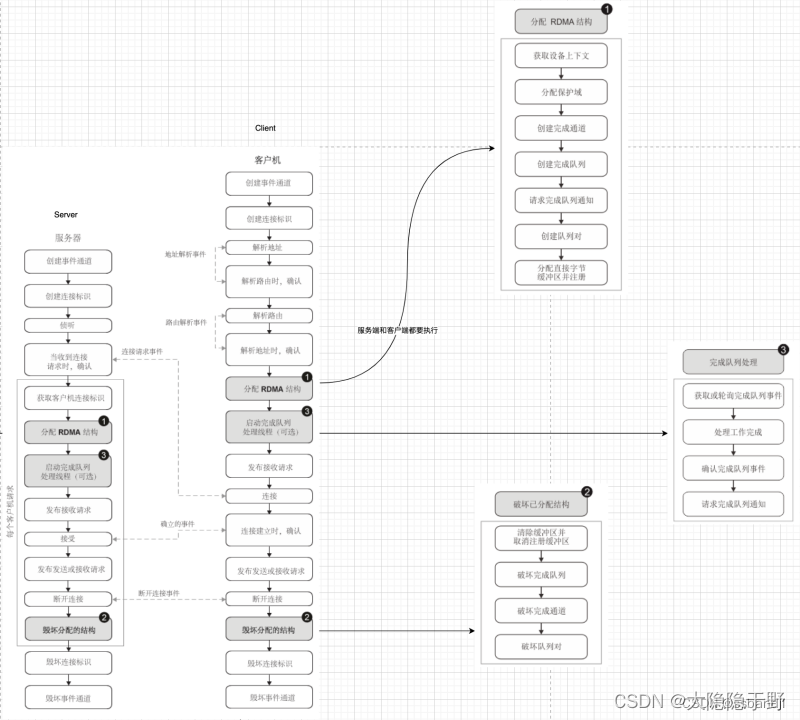
服务器流程
在 RDMA 连接的服务器端建立了以下事件:
创建事件通道。server_cm_ec = rdma_create_event_channel();
创建连接标识并将其与事件通道关联。可以将任何数量的连接标识与事件通道关联。
struct rdma_cm_id* listener; rc = rdma_create_id(server_cm_ec, &listener, NULL, RDMA_PS_TCP);
绑定地址后, 服务器侦听来自客户机的连接请求。 rc = rdma_bind_addr(listener, (struct sockaddr *)&srv_addr); rc = rdma_listen(listener, BACKLOG); 启动rdma服务器运行线程: rc = pthread_create(&tid, NULL, rserver_run, this);
当接收到客户机连接请求时,将对请求进行应答。请求的事件类型为 RDMA_CM_EVENT_CONNECT_REQUEST。
对于从客户机接收到的每个请求,将会执行以下步骤:
5.1 服务器获取客户机连接标识。
5.2 在建立服务器和客户机之间的连接之前分配必要的 RDMA 结构。需要以下步骤来创建 RDMA 结构:
获取设备的上下文,该上下文可用于查询设备、端口或全局唯一标识 (GUID)。
分配保护域PD。
为发布完成事件创建完成通道。
创建完成队列。
针对完成队列通知发出工作请求。
创建队列对。
为数据传输分配并注册直接字节缓冲区。
5.3 (可选)可以启动完成队列处理线程。有关发生的事件的更多信息,请参阅完成队列处理。
5.4 当 RDMA 结构就绪时,服务器会发布接收工作请求。
5.5 接受(accept)工作请求后,会向客户机发送事件以确认连接已建立并准备就绪以接收 RDMA 发送或接收请求。事件类型为 RDMA_CM_EVENT_ESTABLISHED。
5.6 发布发送或接收请求,该请求会在服务器和客户机系统之间启动数据传输。
5.7 当工作请求完成时,断开连接。服务器会生成事件类型 RDMA_CM_EVENT_DISCONNECTED。
按照以下顺序移除为数据传输创建的 RDMA 结构:
清除并注销缓冲区。
移除完成队列。
移除完成通道。
移除队列对。
要断开服务器与客户机系统的连接以阻止进一步的 RDMA 操作,请移除连接标识。
移除事件通道。在接收到所有应答之前,无法移除事件通道。
客户机流程
在 RDMA 连接的客户端发生了以下事件:
8. 创建事件通道。struct rdma_event_channel* cm_ec; client_cm_context.cm_ec = rdma_create_event_channel();
9. 创建连接标识并将其与事件通道关联。可以将任何数量的连接标识与事件通道关联。 struct rdma_cm_id rdma_id; rdma_create_id(client_cm_context.cm_ec, &rdma_id, NULL, RDMA_PS_TCP)
10. 客户机使用 ConnectionID.ResolveAddress() 方法查询服务器系统的地址。当接收到事件类型 RDMA_CM_EVENT_ADDRESS_RESOLVED 时,客户机发送应答。rdma_resolve_addr(rdma_id, NULL, (struct sockaddr)addr, RDMA_RESOLVE_ADDR_TIMEOUT_MS) case RDMA_CM_EVENT_ADDR_RESOLVED: 执行回调rc = on_addr_resolved(&evt_cpy); -> rdma_resolve_route(evt->id, RDMA_RESOLVE_ROUTE_TIMEOUT_MS)
11. 客户机使用 ConnectionID.ResolveRoute() 方法查询服务器系统的路由。当接收到事件类型 RDMA_CM_EVENT_ROUTE_RESOLVED 时,客户机发送应答。收到事件: case RDMA_CM_EVENT_ROUTE_RESOLVED: -> rc = on_client_route_resolved(&evt_cpy);
12. 在建立客户机和服务器之间的连接之前分配必要的 RDMA 结构。需要以下步骤来创建 RDMA 结构:
获取设备的上下文,该上下文可用于查询设备、端口或全局唯一标识 (GUID)。struct rdma_cm_id id = evt->id; struct rdma_device_context dev_ctx = get_dev_context(evt->id->verbs, rdma_name);
分配保护域。struct rdma_connection_priv priv_data;
为发布完成事件创建完成通道。struct ibv_qp_init_attr qp_attr;
创建完成队列。poller_ctx->cq = ibv_create_cq(rdma_ctx, 8192, NULL, poller_ctx->comp_ec, 0)
针对完成队列通知发出工作请求。rc = ibv_req_notify_cq(poller_ctx->cq, 0);
创建队列对。 rdma_create_qp(evt->id, dev_ctx->pd, &qp_attr)
为数据传输分配并注册直接字节缓冲区。
发送对列: qp_attr.send_cq = dev_ctx->poller_ctx[conn->rdma_poller_index].cq;
接收队列: qp_attr.recv_cq = dev_ctx->poller_ctx[conn->rdma_poller_index].cq;
6.(可选)可以启动完成队列处理线程。有关发生的事件的更多信息,请参阅完成队列处理。
13. 向服务器发出发布接收请求。
14. 向服务器发出连接请求。这会生成事件类型 RDMA_CM_CONNECT_REQUEST 并将其发送到服务器。rdma_connect(evt->id, &cm_params)
15. 客户机等待直至从服务器接收到事件类型 RDMA_CM_EVENT_ESTABLISHED。此事件指示已建立连接且可以进行数据传输。
16. 发布发送或接收工作请求,该请求会在服务器和客户机系统之间启动数据传输。
17. 当工作请求完成时,断开连接。客户机会生成事件类型 RDMA_CM_EVENT_DISCONNECTED。
18. 按照以下顺序移除为数据传输创建的 RDMA 结构:
清除并注销缓冲区。
移除完成队列。
移除完成通道。
移除队列对。
19. 要断开客户机与服务器的连接以阻止进一步的 RDMA 操作,请移除连接标识。
20. 移除事件通道。
完成队列处理
下图扩展在选择处理完成队列时所需的编程步骤。此过程在第一张图中显示为以“完成队列处理”标示的单个步骤,该步骤使用编号 3 进行标记。
图中显示了以下步骤:
21. 客户机或服务器使用 getCQEvent() 和 pollCQEvent() 方法来从触发处理的事件队列通道检索类型为 RDMA_CM_EVENT ESTABLISHED 的事件。
22. 处理工作完成。
23. 向完成队列发送应答以确认工作完成。
24. 针对完成队列通知发出请求以确保完成队列接收到应答。
DAOS与RDMA

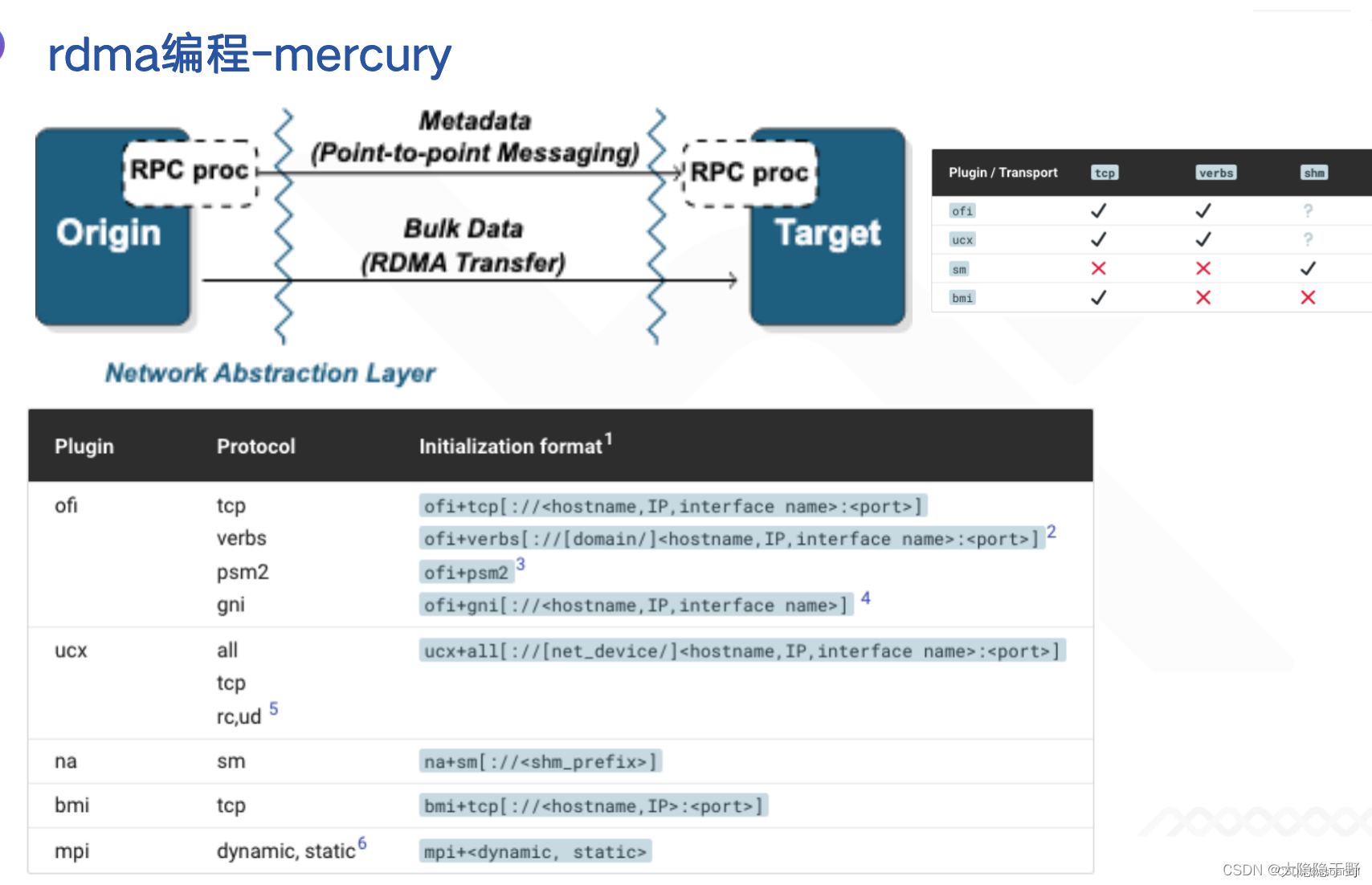
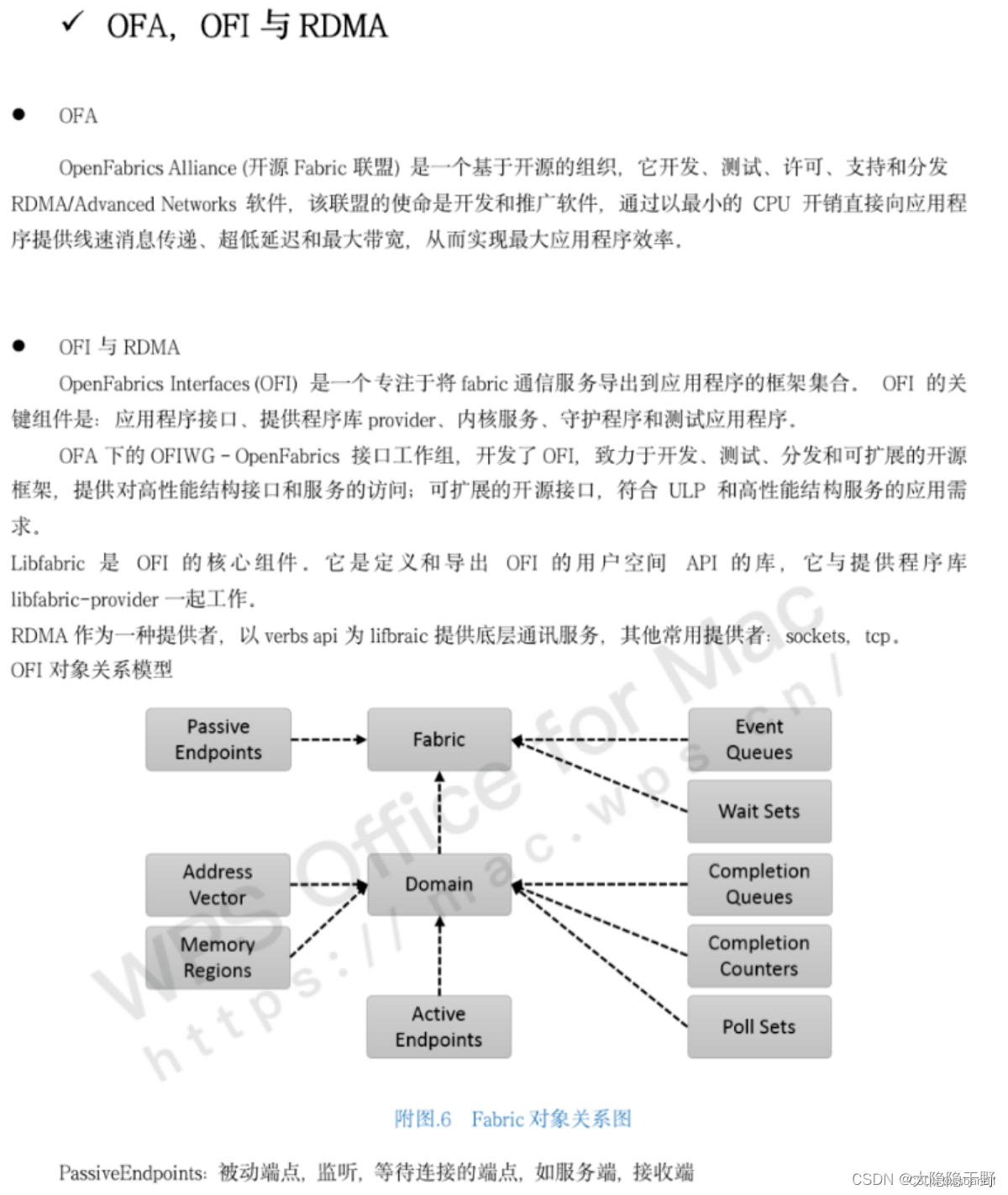
Libfabric与RDMA
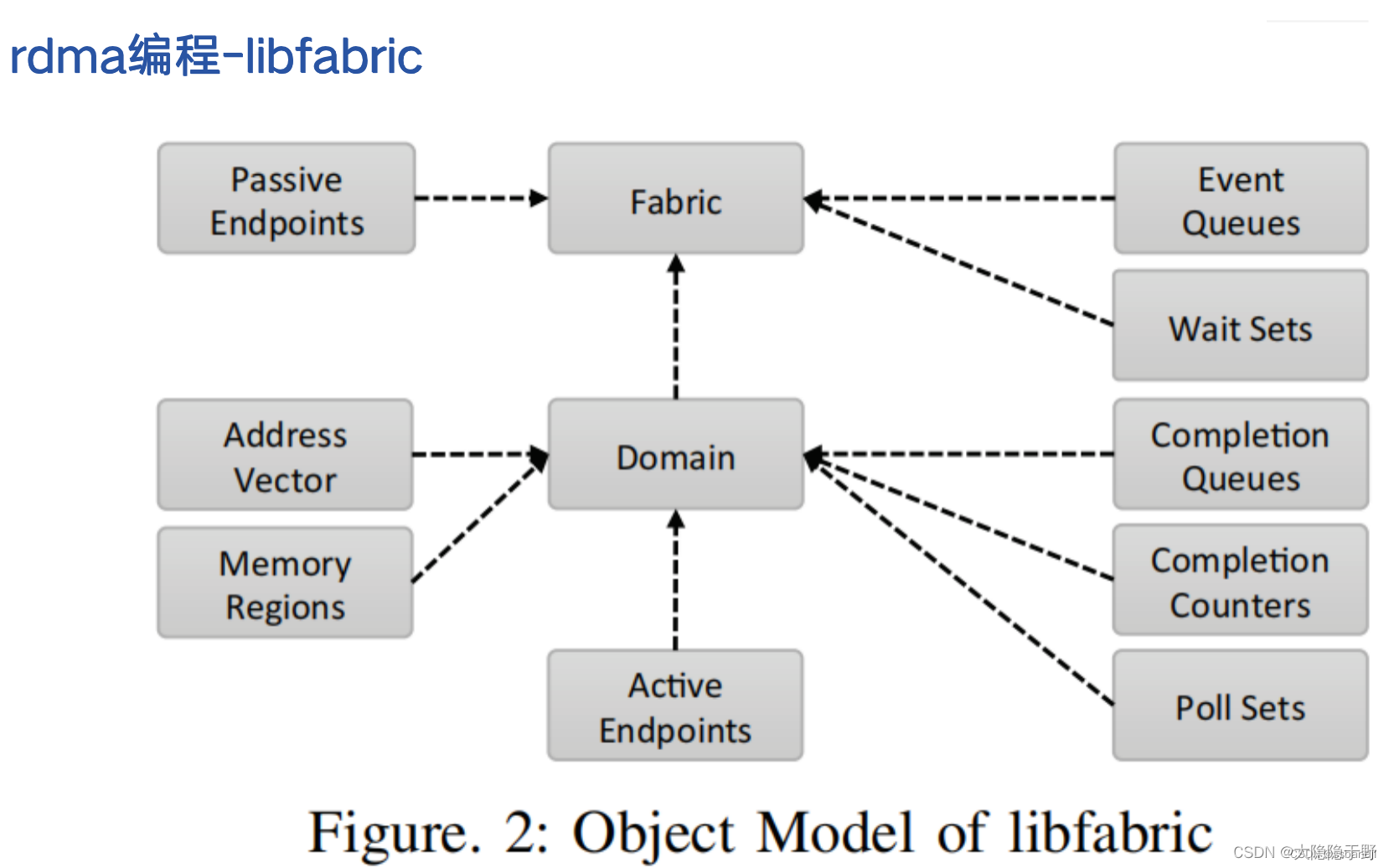
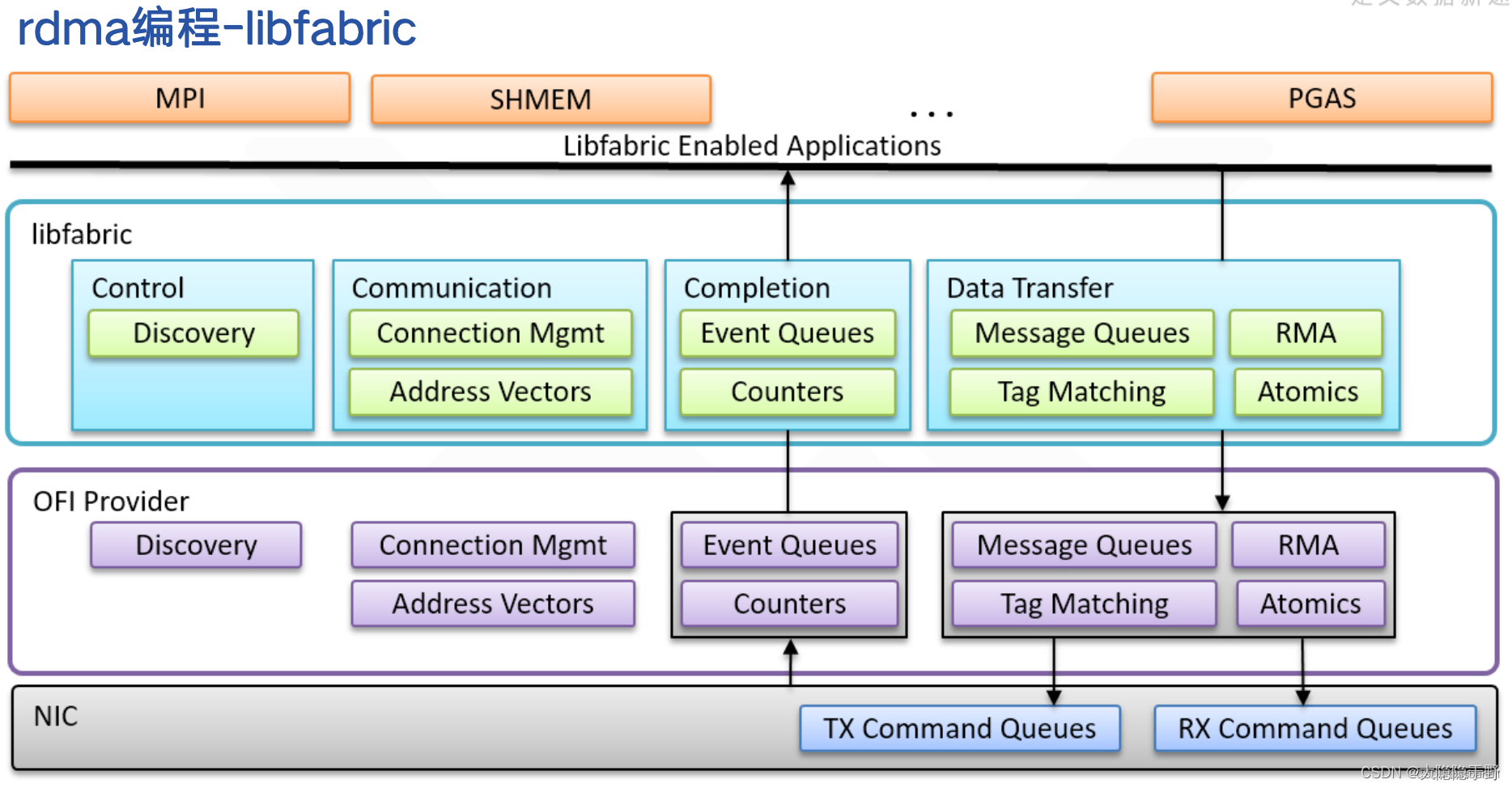
操作
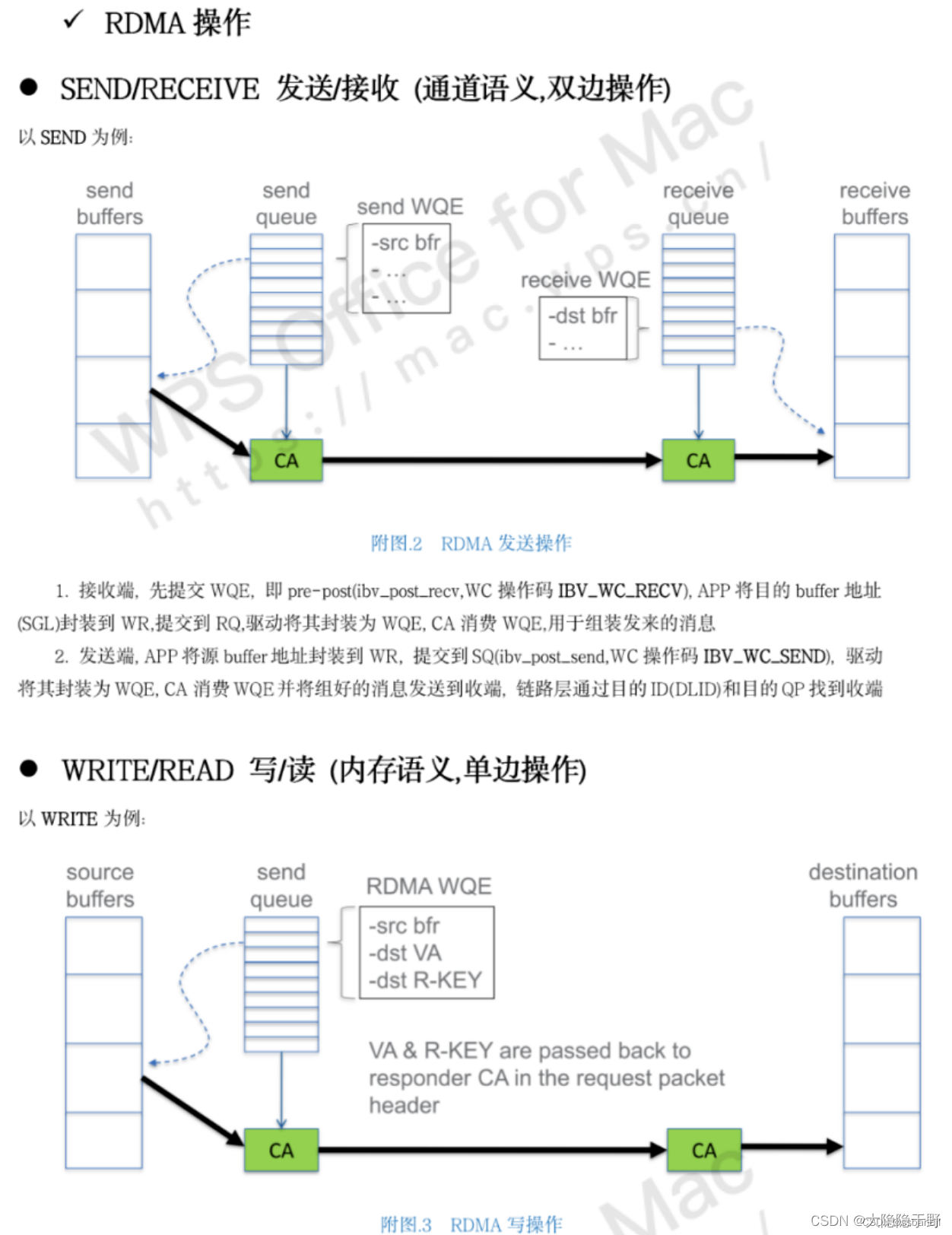

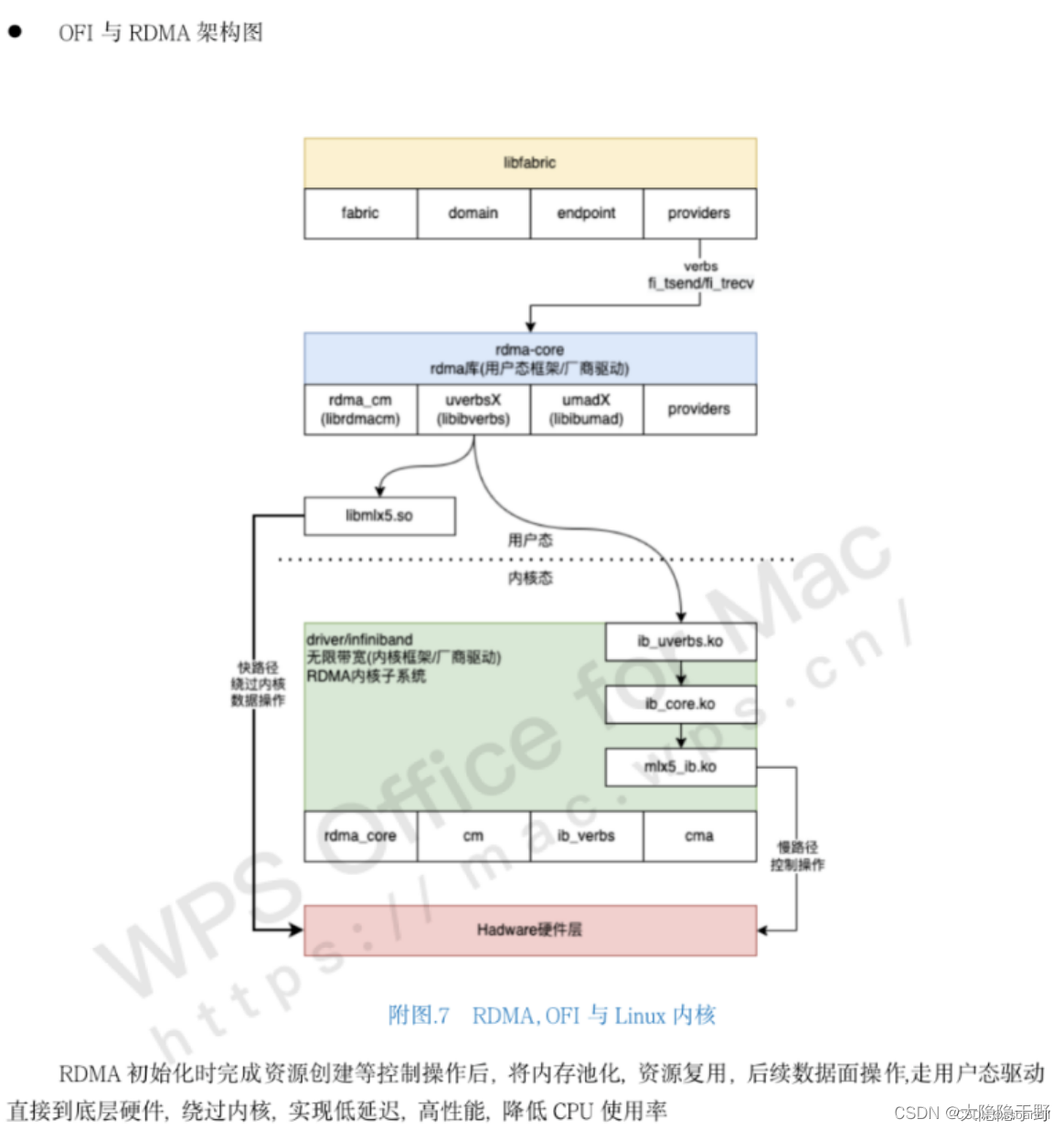
OFI与Mercury(水银HG)
Mercury 是 Mochi(麻糬)微服务生态系统的核心组件,是 R&D 100 获奖项目,对libfabric封装,提供网络抽象NA,点对点RPC(对应RDMA的send/recv),大块Bulk数据传输(如将RDMA的write/read封装为put/get), 提供了灵活的RPC注册, 回调, RPC飞行队列/等待队列拥塞控制, 单个RPC超时时间设置和跟踪,重试机制, 存储池等,充分利用底层网络性能
CaRT(集体和 RPC 传输)与Mercury
CaRT 是用于大数据和 百亿级 HPC 的开源 RPC 传输层。它支持传统的 P2P RPC 和集体 RPC,后者通过可扩展的基于树的消息传播在一组目标服务器上调用 RPC。Cart将Mercury封装,对应用程序提供初始化上下文,创建请求,发送请求,请求回调等数据通道接口,典型的上层应用如心跳swim,rank管理, 持久内存和Nvme读写io。

