
热门标签
热门文章
- 1Python AttributeError: ‘NoneType‘ object has no attribute ‘shape‘如何解决_nonetype' object has no attribute 'shape
- 2Docker进阶:Docker Swarm(集群搭建) —实现容器编排的利器_docker swarm 批量创建容器
- 3通过AI写作赚钱方法分享
- 4AWS账号注册以及Claude 3 模型使用教程!
- 5动态规划(DP)之入门学习-数字三角形_动态规划算法数字三角
- 6PS必备人像脸部磨皮插件portraiture4.5.3滤镜磨皮插件下载安装_ps一键磨皮插件下载
- 7数据结构之链表(C语言)_链表c语言
- 8动态规划—— 01背包问题(一维,二维)_背包问题一维和二维
- 9pycharm快捷键、常用设置、配置管理
- 10HI3861学习笔记(25)——接入华为云物联网平台IoT_hi3861连接华为云
当前位置: article > 正文
VideoGPT:Video Generation using VQ-VAE and Transformers
作者:从前慢现在也慢 | 2024-04-15 12:28:39
赞
踩
VideoGPT:Video Generation using VQ-VAE and Transformers
1.introduction
对于视频展示,选择哪种模型比较好?基于似然->transformers自回归。在没有空间和时间溶于的降维潜在空间中进行自回归建模是否优于在所有空间和时间像素级别上的建模?选择前者:自然图像和视频包括了大量的空间和时间冗余,这些冗余可以通过学习高分辨率输入的去噪降维编码来消除,例如,空间和时间维度上的4倍降采样会导致64倍的分辨率降低,在潜在空间建模,不是像素空间,可以提高采样速度和计算需求。VideoGPT是基于VQVAE和GPT的视频生成架构,
VideoGPT利用3D conv和transposed conv along with axial attention,在VQVAE中的编码器中学习从视频帧原始像素中获取降维离散潜在值,利用GPT进行自回归。

2.VideoGPT
2.1 learning latent code
第一阶段:为了学习一组离散的潜在code,首先在视频数据上训练一个VQVAE,编码器结构包括一系列在时空维度上进行下采样的3D卷积,如图所示,
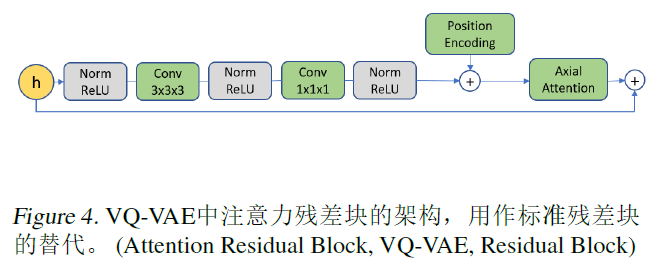
2.2 learning a prior
第二阶段:Image-GPT,学习第一阶段VQVAE潜在code的先验。
3.Experiments
3.1 Training details
所有的图像数据在训练前被缩放在-0.5-0.5之间,训练64x64的视频,长度是16.
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

