
- 1MySQL表的操作『增删改查』_用mysql数据库,创建任务表,针对该表实现增删改查操作(注:最低要求要完成新增功能)
- 2OSTrack 中的边界框回归策略
- 3敏捷适合大规模开发吗?不该问的问题!
- 4git的使用详细步骤_git步骤
- 5Xcode下载模拟器报错Could not download iOS 17.4 Simulator (21E213).
- 6计算机专业高级职称评定条件,计算机职称考试初级高级中级职称评定申报条件...
- 7AIOT入门指南:探索人工智能与物联网的交汇点_aiot产品学习
- 8以太坊学习路线——(二、下)以太坊编程接口:web3.js_console.log(txreceipt);
- 92023年全国职业院校技能大赛信息安全管理与评估—网络安全事件响应、数字取证调查、应用程序安全参考答案_网络安全应急响应竞赛
- 10计算机软件职称聘用,关于做好2017年“以聘代评”系列职称聘任工作的通知
【李老师云计算】HBase+Zookeeper部署及Maven访问(HBase集群实验)_hbase maven怎么用
赞
踩
前言
本篇博客内容大部分参考了涛哥的博客,在此基础上进行了整合、补充以及融合了我自己的操作,向学长表示敬意!
本次操作,为什么说是操作不是实验呢,因为这个不算课内的作业,而是必须要完成的额外任务,是在完成了【李老师云计算】实验一:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计的前提下进行的。
后来又布置了一个新的实验也添加上了。
共分成四大部分,第一部分是Zookeeper的搭建,第二部分是HBase的搭建,第三部分是Maven访问,以及第四部分HBase集群实验。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下速通指南专栏。
1. Zookeeper
ZooKeeper是一个分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
1.1 主机下载Zookeeper安装包
我下载的版本是apache-zookeeper-3.7.1-bin.tar
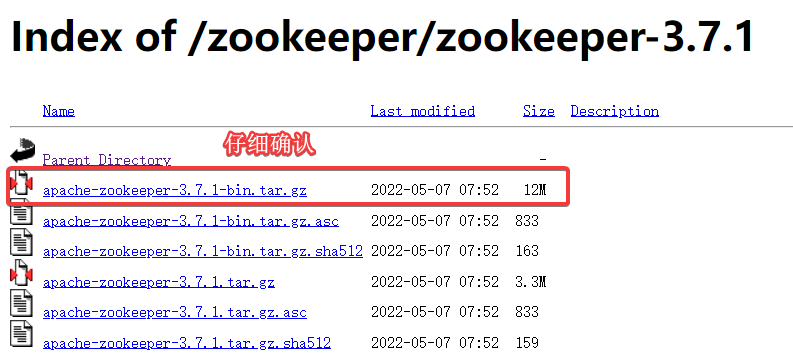
1.2 主机解压Zookeeper
将下载好的文件放到Master节点下的/usr/local/目录下
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz(根据自己下载的版本修改)

之后再继续使用以下指令:
mv apache-zookeeper-3.7.1-bin zookeeper来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为zookeeper。总之就是最终把解压出来的文件重命名为zookeeper即可。
1.3 ★解决解压后文件缺失
如果从桌面向虚拟机拖文件,可能压缩包没有完全的导入。
如果出现了下面的错误反而不会导入失败,只需要点击重试就可以了。
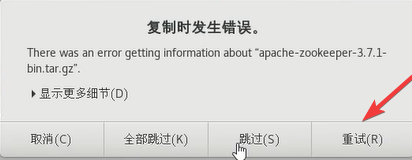
如果说压缩包的大小不一样就说明导入时出现错误了,可以尝试多导入几次或者用其他方法通过虚拟机获取。

1.4 主机配置Zookeeper文件
1.4.1 配置zoo_sample.cfg文件
进入到/usr/local/zookeeper/conf目录下。
首先把zoo_sample.cfg重命名为zoo.cfg,同样两种方法,使用下面的指令(确保此时终端位置是conf):
cp zoo_sample.cfg zoo.cfg
或者直接右键重命名都可以。
编辑zoo.cfg文件,将第12行的dataDir=/tmp/zookeeper并修改为dataDir=/usr/local/zookeeper/data/。
然后在文件末尾添加以下内容(注意把slave改成自己的slave主机名):
server.1=0.0.0.0:2881:3881
server.2=slave1-60:2881:3881
server.3=slave2-60:2881:3881
- 1
- 2
- 3
上面本机是0.0.0.0:2881:3881,另外两台机器都是主机名:2881:3881。
1.4.2 配置/data/myid文件
创建并配置/data/myid文件,执行以下指令即可:
mkdir -p /usr/local/zookeeper/data
cd /usr/local/zookeeper/data
touch myid
vi myid
- 1
- 2
- 3
- 4
打开myid文件后写入数字1
注意保证myid文件中只有数字1没有多余的内容(包括空格、换行、注释等),如果之后出现错误,请查看此文件。
1.5 主机传输Zookeeper文件到从机
因为配置Hadoop时已经关闭了防火墙,这里默认已经关闭了。
上面把master配置完了,我们可以直接把所有的文件都传输给从机,包括Zookeeper及其配置文件等。
把下面slave1-xx以及slave2-xx修改为自己的即可。
scp -r /usr/local/zookeeper slave1-60:/usr/local
scp -r /usr/local/zookeeper slave2-60:/usr/local
- 1
- 2
1.6 从机修改Zookeeper文件
虽然传过来了配置文件,但是还是要进行修改!
1.6.1 修改zoo.cfg文件
文件的路径是/usr/local/zookeeper/conf/zoo.cfg
打开以后dataDir我们已经在主机修改过了就不需要修改了。
把刚才在文件末尾添加的三行修改为以下内容(根据自己的slave主机名修改)
slave1:
server.1=master60:2881:3881
server.2=0.0.0.0:2881:3881
server.3=slave2-60:2881:3881
- 1
- 2
- 3
slave2:
server.1=master60:2881:3881
server.2=slave1-60:2881:3881
server.3=0.0.0.0:2881:3881
- 1
- 2
- 3
1.6.2 修改myid文件
文件的路径是/usr/local/zookeeper/data/myid
在slave1中内容修改为数字2,在slave2中内容修改为数字3。
注意保证myid文件中只有数字2或3没有多余的内容(包括空格、换行、注释等),如果之后出现错误,请查看此文件。
1.7 设置环境变量
在三台虚拟机上都进行以下的操作:vi ~/.bashrc进入.bashrc文件。
在文件末尾添加以下内容并wq保存退出:
export PATH=$PATH:/usr/local/zookeeper/bin
最后使用source ~/.bashrc来刷新环境变量。
在三台虚拟机都完成了以上操作之后进行下一步。
1.8 启动Zookeeper
Zookeeper的命令如下:
启动命令 zkServer.sh start
重启命令 zkServer.sh restart
关闭命令 zkServer.sh stop
状态命令 zkServer.sh status
- 1
- 2
- 3
- 4
在三台虚拟机上都使用指令打开Zookeeper:
zkServer.sh start
如果每个节点都显示以下提示说明到这里为止没什么问题。

使用zkServer.sh status查看状态可以发现其中一个是Mode:leader另外两个是Mode:follower,谁是leader无所谓不必在意。
1.9 ★解决无法启动Zookeeper
Zookeeper运行产生的data数据都在刚才创建的/usr/local/zookeeper/data/目录中,如果没有使用zkServer.sh stop关闭Zookeeper而关闭虚拟机可能会产生问题,此时删除该目录下除myid以外的所有文件即可。
1.10 验证Zookeeper安装成功
在master使用以下指令(修改为自己的master主机名):
zkCli.sh -server master60:2181
之后会出现以下的命令框:
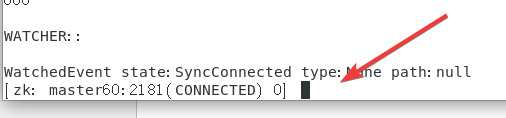
依次使用下面指令对照下图即可:
create /nihao nihao!get /nihaoquit

至此,Zookeeper成功安装。
1.11 ★解决找不到JAVA_HOME
如果没有遇到这个问题就别改
找到一个JDK路径添加进去vi /etc/profile(不要直接复制粘贴下面的)
注意区别JDK和JRE,JDK的目录里有bin文件也有JRE文件,然后JRE里还有一个bin文件。
我这里用的应该是当时用yum指令生成的另一个JDK。在里面添加:
JAVA_HOME=java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
JRE_HOME=java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
- 1
- 2
- 3
- 4
地址一定是JDK而不是JRE。JDK文件里有一个bin并且有一个jre并且jre里也有一个bin,具体什么是JDK什么是JRE请参考菜鸟教程。
source /etc/profile刷新。
2. HBase
2.1 主机下载HBase
我下载的版本是hbase-2.2.2-bin.tar.gz
2.2 主机解压HBase
将下载好的文件放到Master节点下的/usr/local/目录下.
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf hbase-2.2.2-bin.tar.gz(根据自己下载的版本修改)
之后再继续使用以下指令:
mv /usr/local/hbase-2.2.2 /usr/local/hbase来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为hbase。总之就是最终把解压出来的文件重命名为hbase即可。
2.3 主机配置HBase文件
目录的路径是/usr/local/hbase/conf,直接通过GUI进行操作即可。
2.3.1 hbase-env.sh文件
文件末尾添加以下内容,根据自己的情况修改。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
export HBASE_CLASSPATH=/user/hadoop/hadoop-3.3.1/etc/hadoop
export HBASE_MANAGES_ZK=false
- 1
- 2
- 3
JAVA_HOME之前配置过,如Hadoop的/etc/hadoop中hadoop-env.sh中有出现过。·
HBASE_CLASSPATH后面是Hadoop/etc/hadoop请根据自己Hadoop的路径修改。
2.3.2 hbase-site.xml文件
文件末尾添加以下内容,根据自己的情况修改。注意!configuration标签在文件中已经给出,请覆盖掉,否则会出现错误。
主要是把value标签内的东西给修改成自己的!!
<configuration> <property><name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.rootdir</name><value>hdfs://Master60:9000/hbase</value> </property> <property><name>hbase.zookeeper.quorum</name> <value>Master60,Slave1-60,Slave2-60</value> <description>The directory shared by RegionServers. </description> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/zookeeper</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
hdfs://Master60:9000/hbase的端口一般就是9000,如果在Hadoop中修改过,请查看Hadoop/etc/hadoopcore-site.xml文件。
2.3.3 regionservers文件
删掉原有的localhost,添加两台从机的主机名
slave1-60
slave2-60
- 1
- 2
2.4 主机配置环境变量
使用指令vi ~/.bashrc
添加下面的内容:
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
export PATH=$HBASE_HOME/lib:$PATH
- 1
- 2
- 3
并source ~/.bashrc刷新。
2.5 主机最后的调整
使用hbase version指令,可能出现的错误有以下两种:
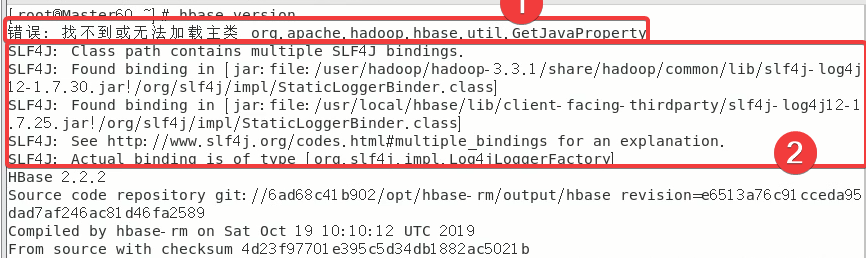
下面依次讲解如何解决以上错误
2.5.1 ★解决错误:找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty
进入到usr/local/hbase/bin目录下,我们来修改hbase文件。
共修改四处。
首先在大概327行附近修改两处
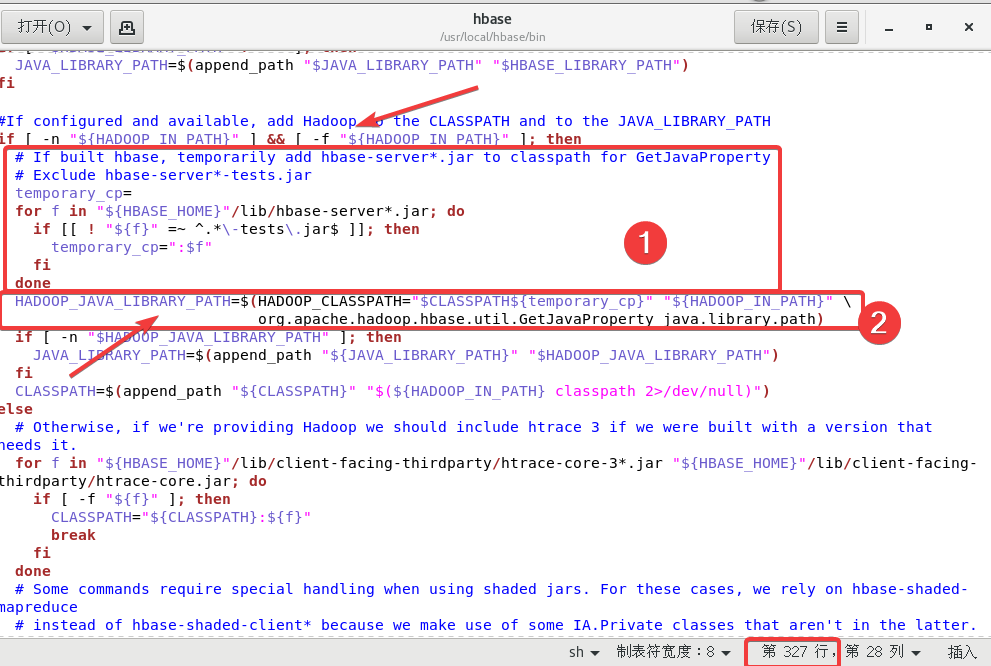
第一处在if [ -n "${HADOOP_IN_PATH}" ] && [ -f "${HADOOP_IN_PATH}" ]; then下面添加的代码如下:
# If built hbase, temporarily add hbase-server*.jar to classpath for GetJavaProperty
# Exclude hbase-server*-tests.jar
temporary_cp=
for f in "${HBASE_HOME}"/lib/hbase-server*.jar; do
if [[ ! "${f}" =~ ^.*\-tests\.jar$ ]]; then
temporary_cp=":$f"
fi
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第二处将HADOOP_JAVA_LIBRARY_PATH=$(HADOOP_CLASSPATH="$CLASSPATH" "${HADOOP_IN_PATH}" \修改为HADOOP_JAVA_LIBRARY_PATH=$(HADOOP_CLASSPATH="$CLASSPATH${temporary_cp}" "${HADOOP_IN_PATH}" \
最后第三处、第四处在大概187行附近
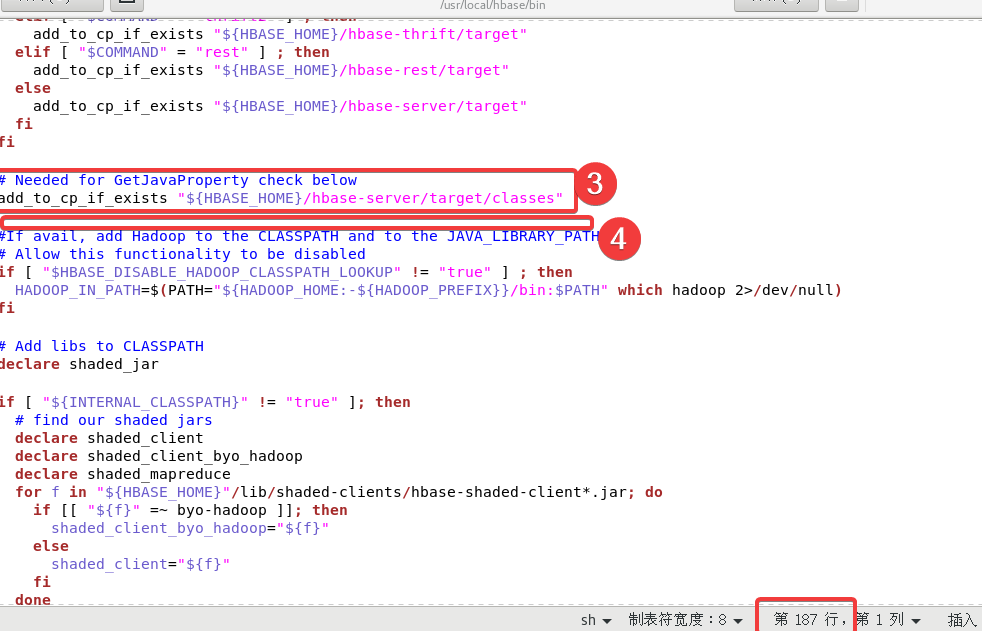
第三处在下面代码的下面
add_to_cp_if_exists "${HBASE_HOME}/hbase-server/target"
fi
fi
- 1
- 2
- 3
添加以下内容:
# Needed for GetJavaProperty check below
add_to_cp_if_exists "${HBASE_HOME}/hbase-server/target/classes"
- 1
- 2
第四处把一段代码删除,要删除的代码如下:
#add the hbase jars for each module
for f in $HBASE_HOME/hbase-jars/hbase*.jar; do
if [[ $f = *sources.jar ]]
then
: # Skip sources.jar
elif [ -f $f ]
then
CLASSPATH=${CLASSPATH}:$f;
fi
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.5.2 ★解决SLF4J:…
具体原因就是hadoop和hbase都有同一个jar包所以产生了冲突,因此只需要删除其中一个就可以了,这里删除hbase的文件。
因为rm -rf指令删除无法恢复请确保路径正确!如果错误删除只能重新解压HBase开始做。
后面的路径最好是直接复制报错中出现的
rm -rf /usr/local/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar
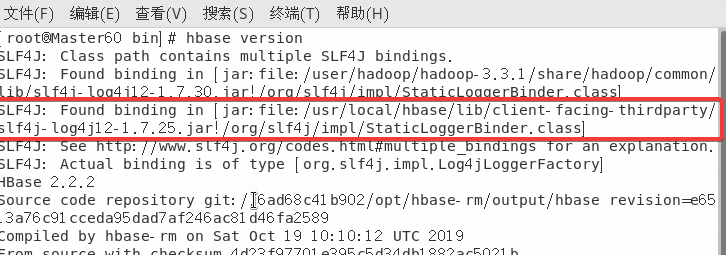
2.6 主机传输HBase文件到从机
先把HBase传给从机(改为自己的主机名):
scp -r /usr/local/hbase slave1-60:/usr/local/
scp -r /usr/local/hbase slave2-60:/usr/local/
- 1
- 2
把配置文件也传给从机:
scp -r ~/.bashrc slave1-60:~
scp -r ~/.bashrc slave2-60:~
- 1
- 2
记得给从机刷新一下配置文件:source ~/.bashrc。
2.7 主机启动HBase
一定要记住这条常用的命令:
-
启动HBase集群:
start-hbase.sh -
关闭HBase集群:
stop-hbase.sh
在主机启动HBase。
jps看一下主机有没有HMaster以及QuorumPeerMain。
从机有没有QuorumPeerMain以及HRegionServer
2.8 Hbase Shell
使用指令hbase shell
在内置命令行输入version以及status来测试。
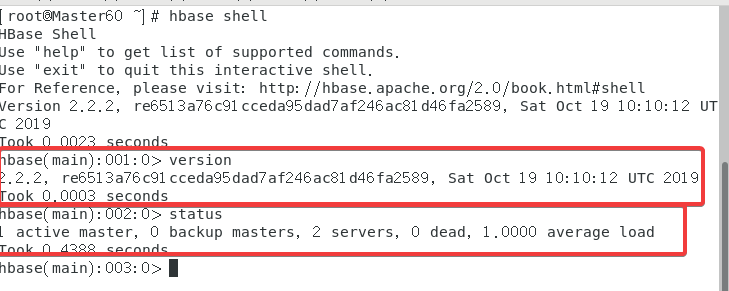
2.9 终极HBase测试
打开浏览器,输入网址192.168.64.60:16010(主机名或IP:16010),能打开这个并且看到两台机器就没啥问题了。

还能看到Zookeeper的设置
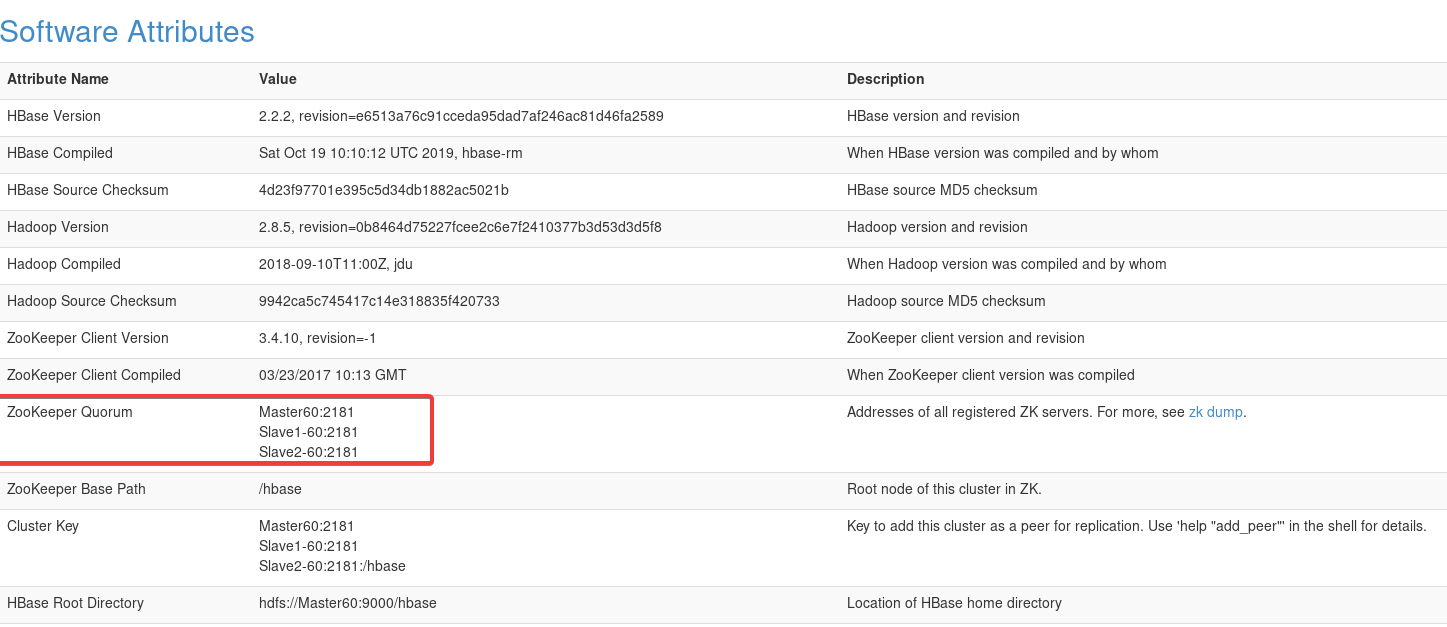
2.10 ★遇到解决不了的问题
当你肯定自己的配置文件一点问题也没有,但是还是无法成功运行。
重启三台虚拟机然后再(3.9)
打开Hadoop 主机使用start-all.sh;
打开Zookeeper 三台虚拟机使用 zkServer.sh start;
打开HBase 主机使用 start-hbase.sh。
3.Maven访问HBase
3.1 主机下载Maven
我下载的版本是apache-maven-3.6.3-bin.tar.gz
3.2 主机解压Maven
将下载好的文件放到Master节点下的/usr/local/目录下.
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf apache-maven-3.6.3-bin.tar.gz(根据自己下载的版本修改)
之后再继续使用以下指令:
mv /usr/local/apache-maven-3.6.3 /usr/local/maven来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为maven。总之就是最终把解压出来的文件重命名为maven即可。
3.3 配置环境变量
使用指令vi /etc/profile
文件末尾添加:
MAVEN_HOME=/usr/local/maven
PATH=$PATH:$MAVEN_HOME/bin
export PATH MAVEN_HOME
- 1
- 2
- 3
刷新source /etc/profile
查看一下mvn -version
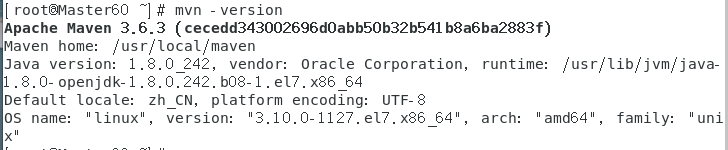
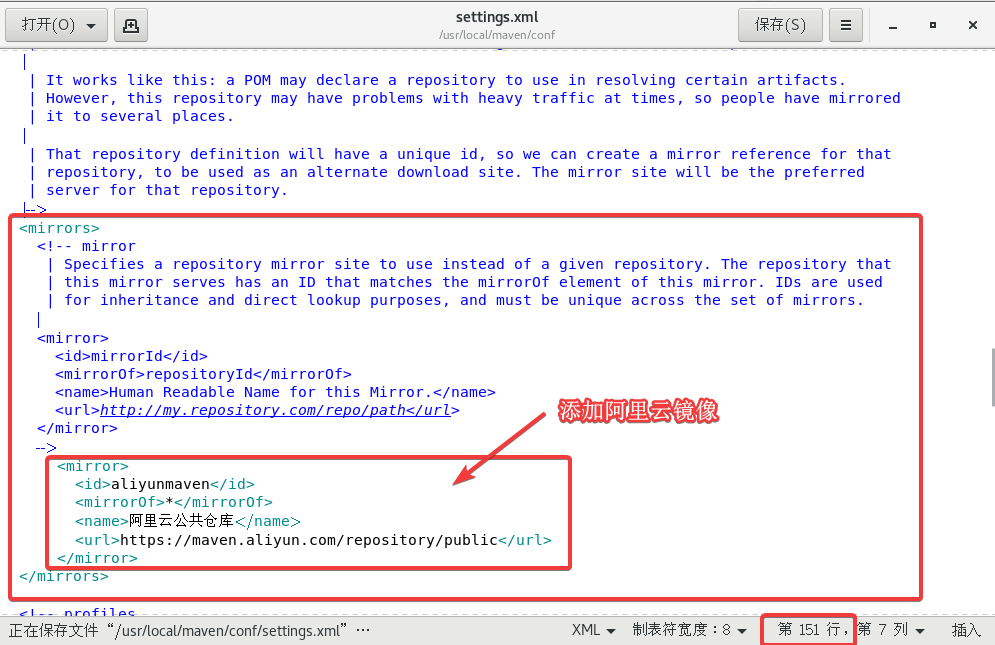
3.4 设置阿里云镜像
这个是为了加快依赖包的下载。
此时的文件路径是/usr/local/maven/conf/
打开settings.xml,大概在151行附近的mirrors标签中添加以下内容:
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
- 1
- 2
- 3
- 4
- 5
- 6
3.5 Maven项目
这一步可以只做3.5.1后面的想试一下也可以。3.6的开始会把3.5.1以外产生的文件全部清除。
3.5.1 创建项目
创建一个工作目录mkdir -p ~/workspace/source
进入workspace/source中右键终端。
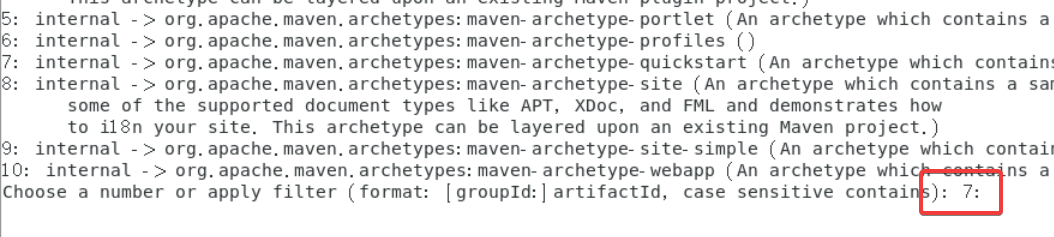
使用指令mvn archetype:generate。
如果提示没有mvn,再用一遍source /etc/profile。
首先会出现第一个暂停的点,在这个7后面直接回车。
之后会让你手动输入几个参数:
包括gtoupId、artifactId、version、package。
我分别用的com.test、maven_test、回车、main(用maven-archetype-quickstart没编译成功,因此后面改成了main)
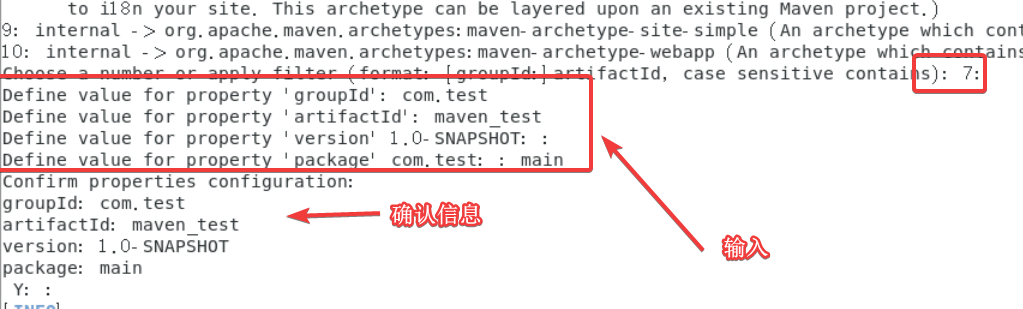
最后会出现一个Y,直接回车就可以,最后看到BUILD SUCCESS。
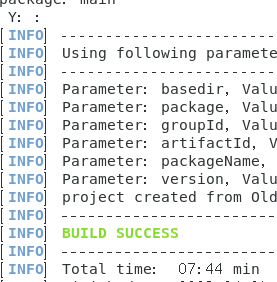
最终成功之后我们可以看到source里出现了一个新的目录,目录名是刚才设置的artifactId参数。
如果想了解一下具体Maven模板是什么可以看菜鸟教程。
3.5.2 如何编译项目
进入生成的目录,具体路径是/workspace/source/maven_test
右键打开终端,输入指令mvn compile,
我这边总是莫名奇妙用不了mvn然后刷新一次才可以用。
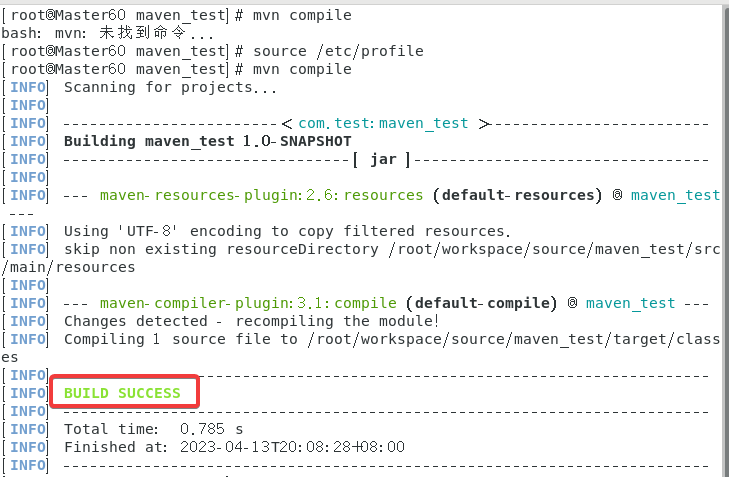
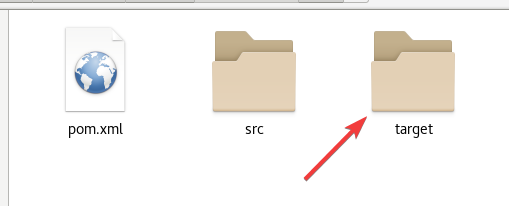
可以看到生成了一个target目录
3.5.3 如何测试项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn test
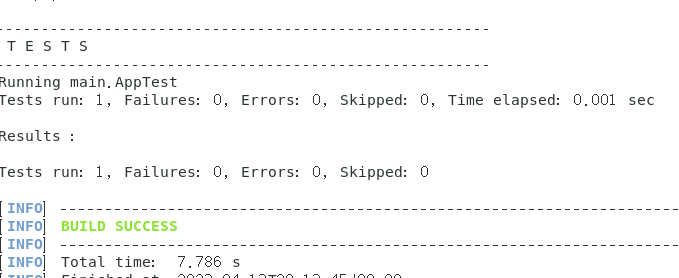
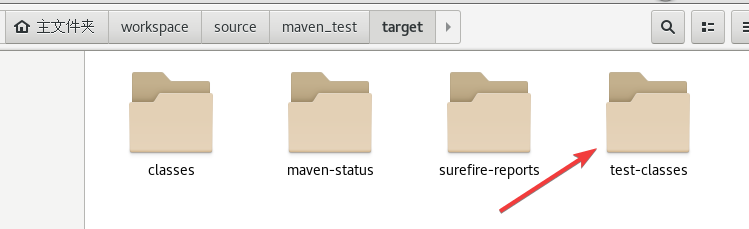
在target目录里又会生成test-classes目录。
3.5.4 如何打包项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn package
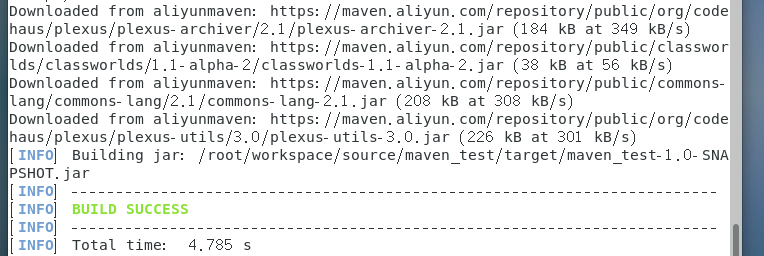
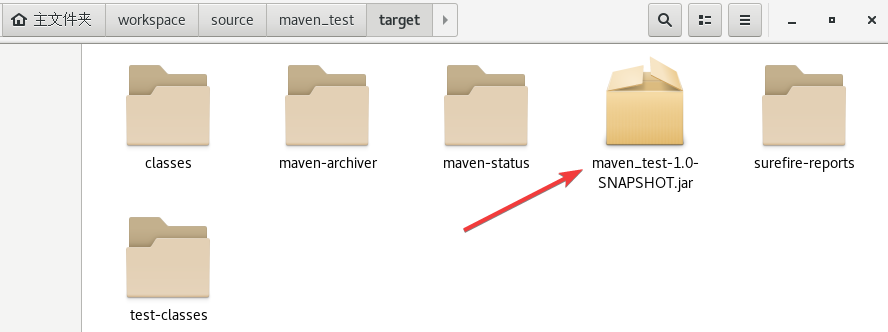
在target目录内生成了maven_test-1.0-SNAPSHOT.jar压缩包
3.5.5 如何安装项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn install

安装到的路径如上红框所示。
3.6 Eclipse打开Maven项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn clean
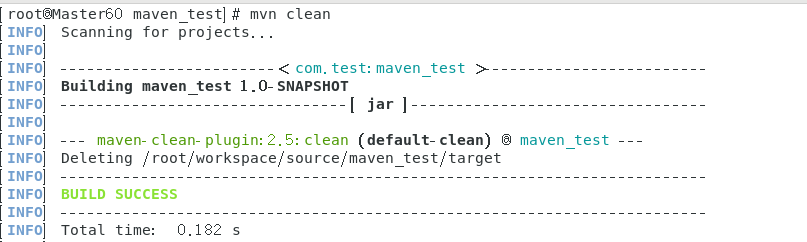
此时targer目录被清除。
执行下面两条指令:
cd ~/.m2
chmod 777 repository
- 1
- 2
之后我们打开eclipse,进入以后
之后
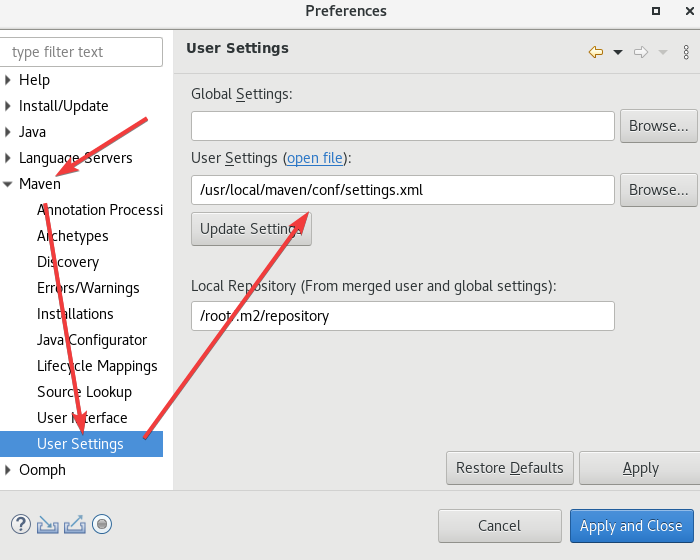
这里的User Settings打开的是maven的conf/settings.xml,如果按照上面来,位置应该是/usr/local/maven/conf/settings.xml。
点击Apply继续下一个设置。
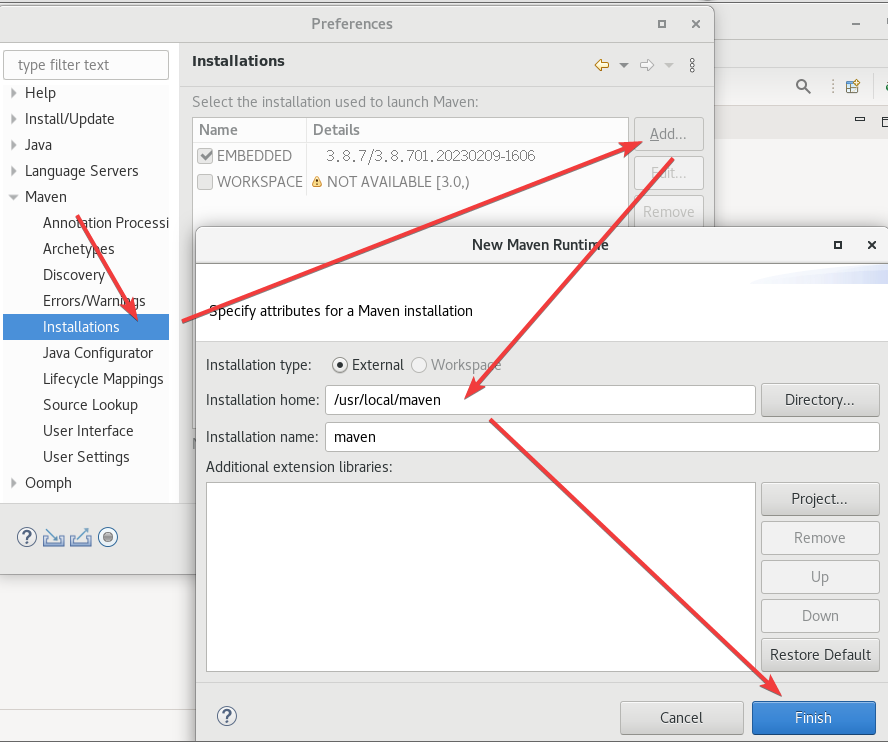
这里的路径是maven所在的位置。
然后选择刚创建的这个
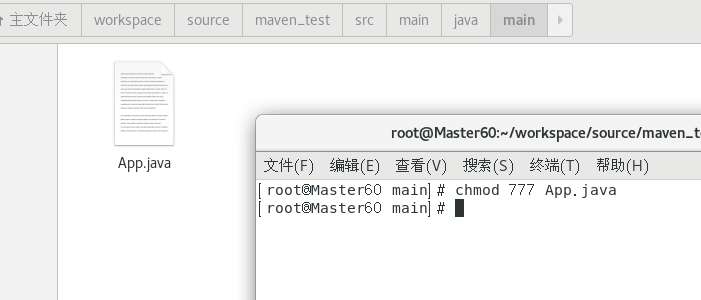
最后我们去给当时创建Maven项目时自动产生的App.java修改权限。chmod 777 App.java
3.7 Maven访问HBase
先把hbase拷贝一份给maven的工作目录
cp -a /usr/local/hbase ~/workspace/source/maven_test/HBase/
然后再Eclipse中打开项目。
之后打开这个maven_test项目
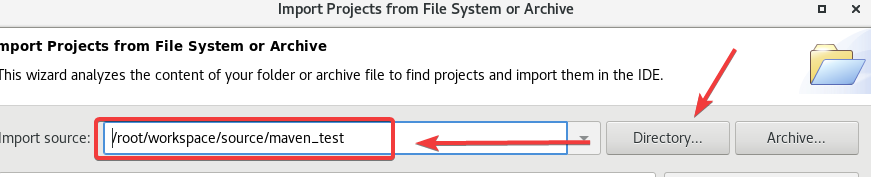
再继续配置
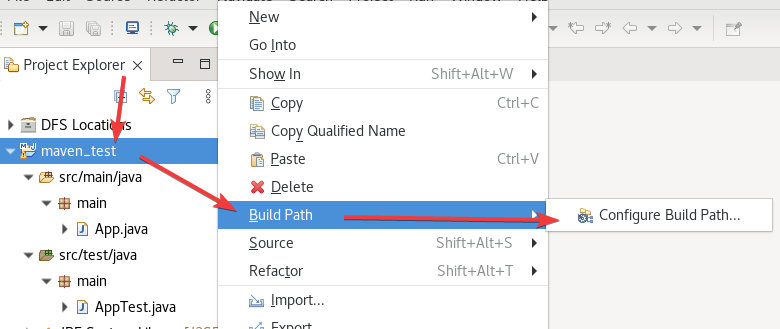
把所有jar包给加载了,如果你有class xx和model xx,导入到class里,我这里是没有这两个文件夹的。
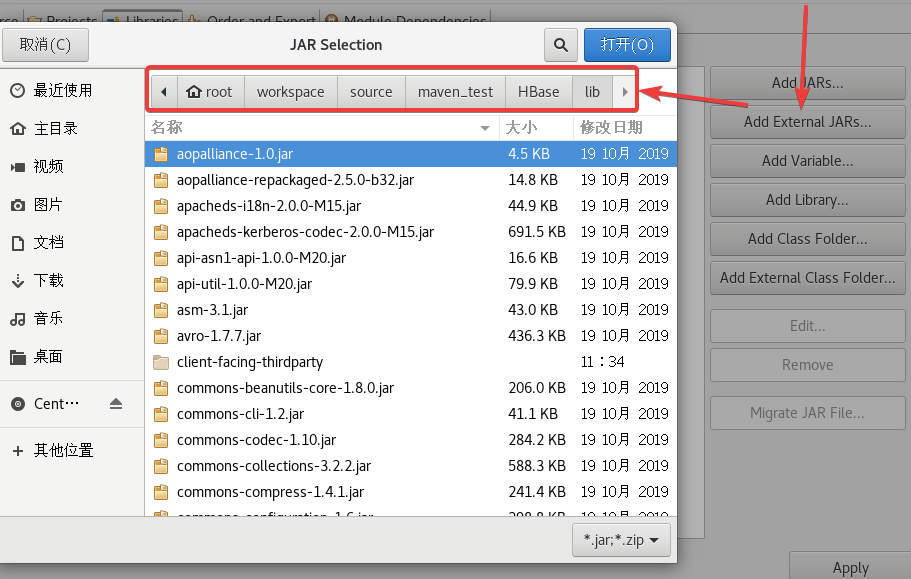
可以先ctrl+A全选ctrl+鼠标左键把目录(没有文件大小的)给取消了,然后就可以导入了。
然后再打开目录把目录里的jar包也给导入了。
在maven_test建一个conf目录复制一份文件(直接复制也行)
cp -a ~/workspace/source/maven_test/HBase/conf/hbase-site.xml ~/workspace/source/maven_test/conf/
给pom.xml开个权限
chmod 777 ~/workspace/source/maven_test/pom.xml
按照下图再添加一下
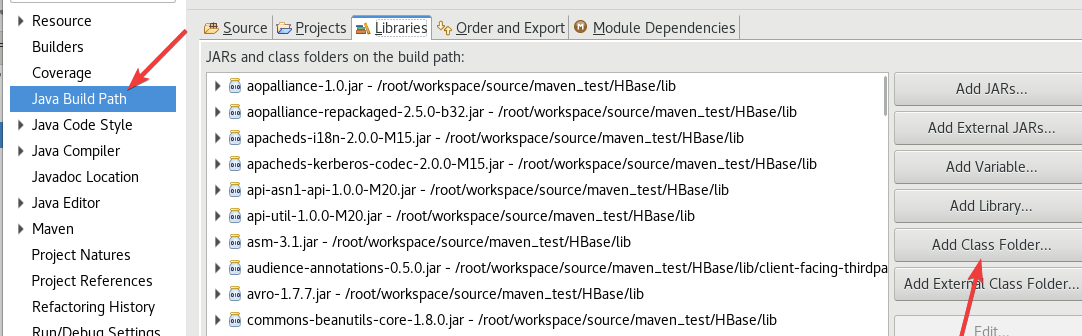

如果找不到,右键项目文件(maven_test)然后刷新(Refresh)。
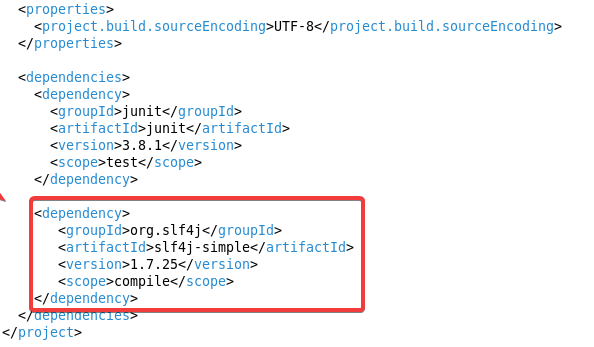
重新回到Eclipse,在pom.xml中新加一个dependency标签
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
<scope>compile</scope>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
打开App.java键入以下代码:
里面有一个主机名,修改成自己的。
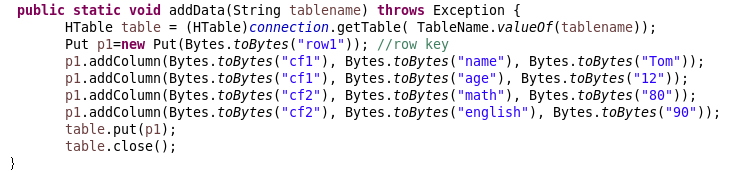
package main; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.regionserver.BloomType; import org.apache.hadoop.hbase.util.Bytes; public class App { static Configuration conf=HBaseConfiguration.create(); static Connection connection; public static void main( String[] args ) { String tablename="hbase_tb"; try { App.getConnect(); App.createTable(tablename); App.addData(tablename); } catch (Exception e) { e.printStackTrace(); } } public static void getConnect() throws IOException { conf.set("hbase.zookeeper.quorum", "master60"); conf.set("hbase.zookeeper.property.clientPort", "2181"); //conf.set("zookeeper.znode.parent", "/hbase"); try{ connection=ConnectionFactory.createConnection(conf); } catch(IOException e){ } } //创建一张表,通过HBaseAdmin HTableDescriptor来创建 public static void createTable(String tablename) throws Exception { TableName tableName= TableName.valueOf(tablename); Admin admin = connection.getAdmin(); if (admin.tableExists(tableName)) { admin.disableTable(tableName); admin.deleteTable(tableName); System.out.println(tablename + " table Exists, delete ......"); } @SuppressWarnings("deprecation") HTableDescriptor desc = new HTableDescriptor(tableName); @SuppressWarnings("deprecation") HColumnDescriptor colDesc = new HColumnDescriptor("cf1"); colDesc.setBloomFilterType(BloomType.ROWCOL); desc.addFamily(colDesc); desc.addFamily(new HColumnDescriptor("cf2")); admin.createTable(desc); admin.close(); System.out.println("create table success!"); } public static void addData(String tablename) throws Exception { HTable table = (HTable)connection.getTable( TableName.valueOf(tablename)); Put p1=new Put(Bytes.toBytes("row1")); //row key p1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("name"), Bytes.toBytes("Tom")); p1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), Bytes.toBytes("12")); p1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("math"), Bytes.toBytes("80")); p1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("english"), Bytes.toBytes("90")); table.put(p1); table.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
其中向这个分布式数据库中添加的数据是:
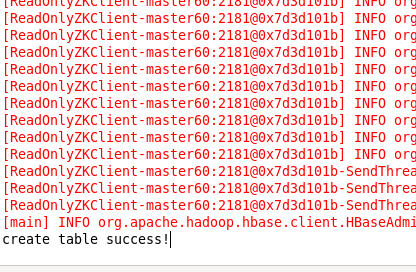
最终呈现的结果是:
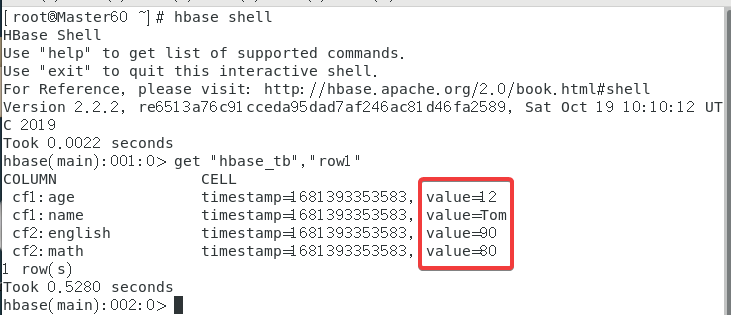
最后检查一下,终端输入hbase shell,之后使用get "hbase_tb","row1"来获取数据库内容。
3.8 ★解决代码爆红
比较玄学,我也没搞明白,我再pom.xml里添加了两个依赖,不爆红了但是不能运行,然后我又删了,也不爆红也能运行了……
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.9 ★虚拟机重启后需要进行的操作
打开Hadoop 主机使用start-all.sh;
打开Zookeeper 三台虚拟机使用 zkServer.sh start;
打开HBase 主机使用 start-hbase.sh。
4. HBase集群实验
下面是实验的描述,分的小标题混乱、不知所云,也不知从哪里冒出一个学生信息(下面代码里没写);表内容写的也抽象,后来才明白,是一班的同学写教师表,二班的同学写辅导员表,下面给出的是教师表,用辅导员表的同学只需要改一下参数就好了没有很大的难度。
1. 搭建HBase集群,一主两从,给出网页的截屏15分。
2. Eclispe/Idea Maven项目访问HBase
2.1 表内容
1班:教师,基本信息:年龄、性别、职称、职务,科研信息:发表文章数、横向项目数、纵向项目数。注意职务和科研信息中的所有属性根据实际确定。
2班:辅导员,基本信息:年龄、性别、职称、职务,业绩信息:红旗班次数、考研率超额次数、就业率超额次数。注意业绩信息根据实际填写。
2. 源程序评分
2.0 导入包和程序结构10分
2.1 创建表源程序和运行结果的截屏10分
2.2 添加三个典型行记录的源程序和运行结果后在HBase shell中看到的结果截屏20分
2.3 浏览所有记录的源程序和运行结果后HBase看到的结果截屏10分
3. 在HBase Shell浏览所有的学生信息10分
4. 根据浏览到的信息解释HBase的逻辑结构和物理结构15分
5. 分析HBase的插入和MySQL的插入有何不同10分。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.1 一班的代码
实际上就是上面代码的一个改进版,然后又多加了一个Teacher类(二班同学应该是Counselor类)。先给出一个项目栏的截图:

新建一个Teacher Class,这里直接用的public String是为了减少麻烦。
package main; public class Teacher { public String name; public String age; public String gender; public String title; public String position; public String articleCount; public String horizontalProjectCount; public String verticalProjectCount; // 构造函数 public Teacher(String name, String age, String gender, String title, String position, String articleCount, String horizontalProjectCount, String verticalProjectCount) { this.name = name; this.age = age; this.gender = gender; this.title = title; this.position = position; this.articleCount = articleCount; this.horizontalProjectCount = horizontalProjectCount; this.verticalProjectCount = verticalProjectCount; } // getter 和 setter 方法 // ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
以及App.java的内容
package main; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.regionserver.BloomType; import org.apache.hadoop.hbase.util.Bytes; public class App { static Configuration conf=HBaseConfiguration.create(); static Connection connection; public static void main( String[] args ) { String tablename="Teacher"; try { App.getConnect(); App.createTable(tablename); Teacher t1 = new Teacher("Jack","54","m","AssociateProfessor","Teacher","2","2","2"); Teacher t2 = new Teacher("Amy","45","m","AssociateProfessor","Teacher","4","4","4"); Teacher t3 = new Teacher("Mike","40","m","Professor","Teacher","6","6","6"); App.addData(tablename,t1,"row1"); App.addData(tablename,t2,"row2"); App.addData(tablename,t3,"row3"); } catch (Exception e) { e.printStackTrace(); } } public static void getConnect() throws IOException { conf.set("hbase.zookeeper.quorum", "master60"); conf.set("hbase.zookeeper.property.clientPort", "2181"); //conf.set("zookeeper.znode.parent", "/hbase"); try{ connection=ConnectionFactory.createConnection(conf); } catch(IOException e){ } } //创建一张表,通过HBaseAdmin HTableDescriptor来创建 public static void createTable(String tablename) throws Exception { TableName tableName= TableName.valueOf(tablename); Admin admin = connection.getAdmin(); if (admin.tableExists(tableName)) { admin.disableTable(tableName); admin.deleteTable(tableName); System.out.println(tablename + " table Exists, delete ......"); } @SuppressWarnings("deprecation") HTableDescriptor desc = new HTableDescriptor(tableName); @SuppressWarnings("deprecation") HColumnDescriptor colDesc = new HColumnDescriptor("basic_info"); colDesc.setBloomFilterType(BloomType.ROWCOL); desc.addFamily(colDesc); desc.addFamily(new HColumnDescriptor("research_info")); admin.createTable(desc); admin.close(); System.out.println("create table success!"); } public static void addData(String tablename,Teacher t,String key) throws Exception { HTable table = (HTable)connection.getTable( TableName.valueOf(tablename)); Put p=new Put(Bytes.toBytes(key)); //row key p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("name"), Bytes.toBytes(t.name)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("age"), Bytes.toBytes(t.age)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("gender"), Bytes.toBytes(t.gender)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("title"), Bytes.toBytes(t.title)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("position"), Bytes.toBytes(t.position)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("articleCount"), Bytes.toBytes(t.articleCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("horizontalProjectCount"), Bytes.toBytes(t.horizontalProjectCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("verticalProjectCount"), Bytes.toBytes(t.verticalProjectCount)); table.put(p); table.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
4.2 二班的代码
二班可以用以下的代码来运行,然后剩下的操作和
Counselor 类
package main; public class Counselor { public String name; public String age; public String gender; public String title; public String position; public String flagCount; public String PostgraduateCount; public String employmentCount; // 构造函数 public Counselor(String name, String age, String gender, String title, String position, String flagCount, String PostgraduateCount, String employmentCount) { this.name = name; this.age = age; this.gender = gender; this.title = title; this.position = position; this.flagCount = flagCount; this.PostgraduateCount = PostgraduateCount; this.employmentCount = employmentCount; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
App 类
package main; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.regionserver.BloomType; import org.apache.hadoop.hbase.util.Bytes; public class App { static Configuration conf=HBaseConfiguration.create(); static Connection connection; public static void main( String[] args ) { String tablename="Counselor"; try { App.getConnect(); App.createTable(tablename); Counselor t1 = new Counselor("Jack","33","m","lecturer","Counselor","2","2","2"); Counselor t2 = new Counselor("Amy","30","m","assistant","Counselor","4","4","4"); Counselor t3 = new Counselor("Mike","27","m","assistant","Counselor","6","6","6"); App.addData(tablename,t1,"row1"); App.addData(tablename,t2,"row2"); App.addData(tablename,t3,"row3"); } catch (Exception e) { e.printStackTrace(); } } public static void getConnect() throws IOException { conf.set("hbase.zookeeper.quorum", "master78"); conf.set("hbase.zookeeper.property.clientPort", "2181"); //conf.set("zookeeper.znode.parent", "/hbase"); try{ connection=ConnectionFactory.createConnection(conf); } catch(IOException e){ } } //创建一张表,通过HBaseAdmin HTableDescriptor来创建 public static void createTable(String tablename) throws Exception { TableName tableName= TableName.valueOf(tablename); Admin admin = connection.getAdmin(); if (admin.tableExists(tableName)) { admin.disableTable(tableName); admin.deleteTable(tableName); System.out.println(tablename + " table Exists, delete ......"); } @SuppressWarnings("deprecation") HTableDescriptor desc = new HTableDescriptor(tableName); @SuppressWarnings("deprecation") HColumnDescriptor colDesc = new HColumnDescriptor("basic_info"); colDesc.setBloomFilterType(BloomType.ROWCOL); desc.addFamily(colDesc); desc.addFamily(new HColumnDescriptor("research_info")); admin.createTable(desc); admin.close(); System.out.println("create table success!"); } public static void addData(String tablename,Counselor t,String key) throws Exception { HTable table = (HTable)connection.getTable( TableName.valueOf(tablename)); Put p=new Put(Bytes.toBytes(key)); //row key p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("name"), Bytes.toBytes(t.name)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("age"), Bytes.toBytes(t.age)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("gender"), Bytes.toBytes(t.gender)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("title"), Bytes.toBytes(t.title)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("position"), Bytes.toBytes(t.position)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("flagCount"), Bytes.toBytes(t.flagCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("PostgraduateCount"), Bytes.toBytes(t.PostgraduateCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("employmentCount"), Bytes.toBytes(t.employmentCount)); table.put(p); table.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
4.3 代码的一点解释
以一班的代码为例,其中:
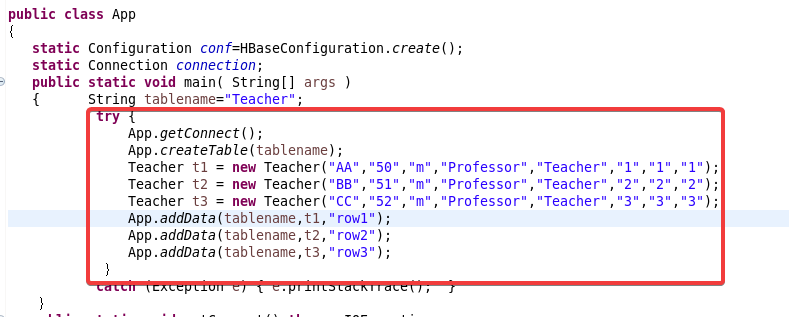
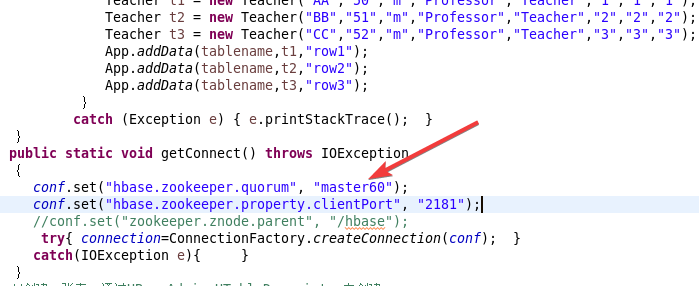
信息是通过构造函数直接搞得,在这里修改成自己的内容!还有表名也在这里修改↑
这里也改成自己的!
最后打开进入hbase shell使用指令scan 'Teacher'来查看
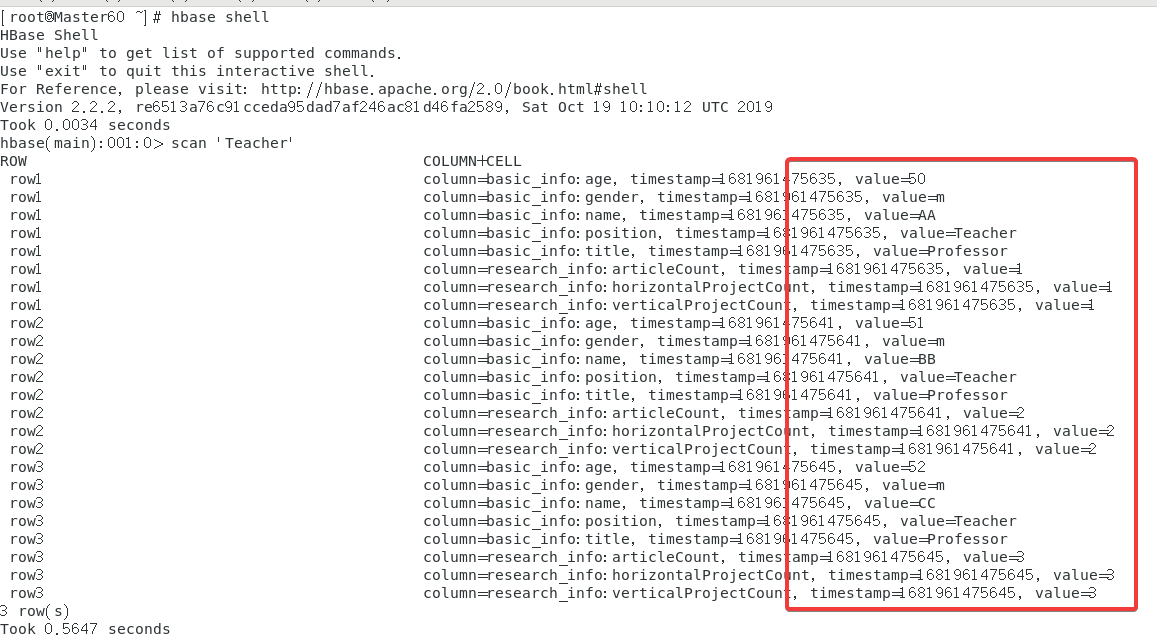
4.3 解释HBase的逻辑结构和物理结构
1. 逻辑结构:
- 表(Table):HBase 数据库中的基本单元,由多行和多列族组成,每行有唯一的行键(Row Key),每个列族包含多个列(Column)。
- 行(Row):HBase 表中的数据按行存储,每行都有唯一的行键,行键按照字典序排序,可以通过行键查找数据。
- 列族(Column Family):HBase 表中的数据按列族组织,每个列族包含多个列,每个列都有一个唯一的列名(Column Name),列名和列值一起构成了列。
- 列(Column):HBase 表中的数据由多个列组成,每个列由列名、时间戳和列值组成,列名和列值都是字节数组,时间戳是 long 类型的整数。
2. 物理结构:
- Region Server:HBase 的数据存储和查询都是通过 Region Server 来完成的,Region Server 是 HBase 集群中的一个节点,每个 Region Server 管理多个 Region。
- Region:HBase 表的数据被分为多个 Region 存储,每个 Region 是一段连续的行,每个 Region 包含一个主列族和多个次列族,Region 的大小由 HBase 的配置参数决定,通常在几百 MB 到几 GB 之间。
- HFile:HBase 数据在磁盘上是按 HFile 的格式存储的,HFile 是 HBase 中的一个重要的数据结构,它是一个稠密的、可变长的文件格式,用于存储一段连续的行。
- WAL:HBase 中的写操作会先写入 Write Ahead Log(WAL),WAL 是一种顺序写入的、不可修改的日志,用于保证数据写入的可靠性和一致性。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.4 分析HBase的插入和MySQL的插入有何不同10分
1. 数据模型: - MySQL 是关系型数据库,其数据存储在表格中,每个表格由一组列和行组成,每行代表一个记录,每列代表一个属性。 - HBase 是基于列族的 NoSQL 数据库,其数据存储在表格中,每个表格由多个列族和行组成,每行代表一个记录,每个列族下包含多个列,每个列可以包含多个版本。 2. 插入方式: - MySQL 的插入操作是通过 SQL 语句实现的,使用 INSERT INTO 语句将数据插入到指定的表格中。 - HBase 的插入操作是通过 Java API 或 HBase shell 命令实现的,使用 Put 操作将数据插入到指定的表格中。 3. 数据存储: - MySQL 的数据是存储在硬盘中的,每次插入数据时,MySQL 会将数据写入磁盘。 - HBase 的数据是存储在内存中和硬盘中的,每次插入数据时,HBase 会将数据先写入内存中的 MemStore,当 MemStore 中的数据达到一定大小时,会将数据写入硬盘中的 HFile 中。 4. 性能: - MySQL 的插入操作通常比 HBase 的插入操作更快,因为 MySQL 的数据存储方式更简单,且 MySQL 的数据通常是存储在本地磁盘上的,而 HBase 的数据存储在内存中和硬盘中,写入操作需要更多的计算资源和磁盘 I/O。 - HBase 的查询操作通常比 MySQL 的查询操作更快,因为 HBase 的数据存储方式更适合于大规模数据的存储和查询,且 HBase 支持快速的随机读取和扫描操作。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
后记
这一篇博客比上一篇要简单一些,但仍然步步是坑,有同学遇到而我没有遇到问题我同样也加了进来让这篇博客更加的“有用”,基本上写完之后一直到实验真正结束这一期间都在修改完善。
这次有更多的同学在对照鄙人博客进行实验的同时为我指正出没有发现的错误,还有的同学提出了宝贵的意见以及为完善博客提供了代码以及图片,同时我也在和同学们交流的时候整理出了更多解决错误的方法,尽管实验本身没什么意思,但是交流沟通解决问题是一件宝贵的事情,受益匪浅。在此向所有使用本博客以及为本博客提供了帮助的同学表示感谢!

