
- 1云计算与大数据课程笔记(九)之虚拟化技术(下)
- 2Java基于的个人图集管理系统(源码+mysql+文档)
- 3SpringDataElasticSearch - NativeSearchQueryBuilder过滤聚合高亮查询
- 4IntelliJ idea 撤回已经commit并未push的文件_idea已经commit没有pull
- 5广州南沙番禺联想SR530服务器主板传感器故障维修
- 6EECS 280 Machine Learning
- 72006-2022年上市公司彭博ESG数据
- 8解决 AttributeError: type object ‘Callable‘ has no attribute ‘_abc_registry‘_attributeerror: type object 'callable' has no attr
- 9RabbitMq之应答模式_rabbitmq自动应答
- 10Git 小乌龟(TortoiseGit)的详细使用_git小乌龟拉取代码
Transformer架构在大型语言模型(LLM)中的应用与实践_基于transformer的llm
赞
踩
Transformer架构是当今最前沿的语言模型技术之一,它已经在谷歌的BERT、OpenAI的GPT系列中取得了显著的成就。这一架构之所以独特,是因为它打破了传统的序列处理模式,引入了创新的“自注意力”机制。
Transformer架构的核心是自注意力机制,它使模型能够识别和重视输入数据中不同部分的相对重要性。这种机制的引入,不仅提高了模型处理长文本的能力,也让其在理解语境和语义关系方面更为高效和准确。
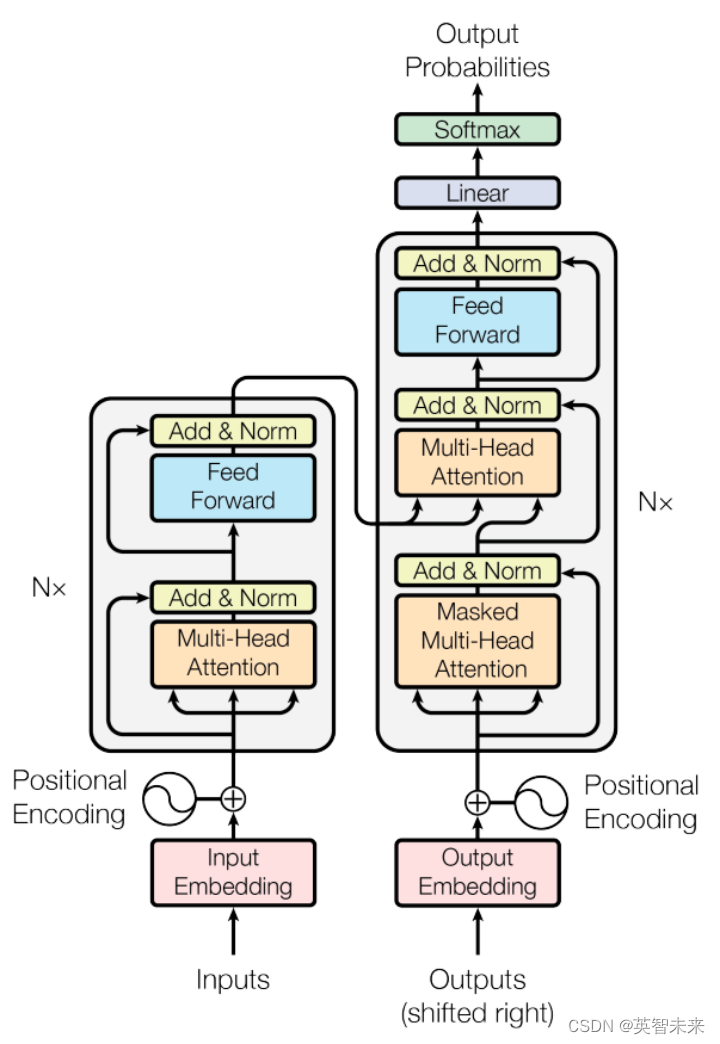
尽管早期的序列模型如RNN和LSTM在某些NLP任务上取得了成功,但在处理长距离依赖和复杂语境方面存在明显的不足。这些局限性促使了基于Transformer的LLM的发展,这些模型通过其独特的架构和训练方式,能够更深入地理解和生成自然语言。
常用方法
1、BERT - Devlin et al. (2018) 提出的BERT模型采用双向Transformer架构,通过掩码语言模型(MLM)和下一句预测(NSP)两种预训练任务让模型预测词汇,预测句子是否顺序排列,从而增强对上下文的理解能力。BERT的双向上下文理解特别适合在复杂语境中的语义理解,通常使用在情感分析、问答系统、语言推理等NLP任务。
2、GPT - Radford et al. (2018) 的GPT模型使用单向Transformer架构进行生成式预训练,使模型能够生成连贯且有意义的文本。这种能力使得GPT在创造性写作、自动新闻生成和聊天机器人的开发中展现了强大的能力。
3、T5 - Raffel et al. (2019) 提出的T5模型将所有NLP任务统一为文本到文本的格式,这种灵活的框架使得T5能够在多个领域应用,如文本摘要、翻译等。
4、XLNet - Yang et al. (2019) 的XLNet模型结合了BERT的双向上下文和GPT的生成能力,通过排列语言模型(PLM)考虑所有可能的词的排列组合,从而提高文本理解的深度和准确性。
5、RoBERTa - Liu et al. (2019) 对BERT进行优化和改进,通过更大的数据集和更长时间的训练,提高了模型的鲁棒性和准确性,特别是在细粒度的文本分类任务上表现优异。

这些模型的成功证明了Transformer架构在处理复杂语言任务时的强大能力。对于需要深层次文本理解和精准分类的任务,例如法律文件分析或医学研究文本处理,BERT 或 RoBERTa 更为适合,因为它们能更准确地把握文本的细节和复杂性。而在需要高度自然和流畅的文本生成,如创意写作或对话系统,GPT 系列展现出更大的优势。

这些模型不仅在处理复杂语言任务上展示了强大的能力,还为未来的研究和应用开辟了新的道路。随着技术的不断发展和优化,未来可能会出现融合多种模型优势的新架构,比如结合BERT的细粒度文本理解和GPT的文本生成能力。这种融合可能进一步推动NLP技术的边界,尤其在处理复杂的多任务和跨领域的NLP应用中展现更高的效能和准确性。这些发展不仅是技术层面的突破,更是人类与机器交互方式的重大转变,为人类与机器的语言交互提供更丰富、更智能的可能性。

