
- 1【AI绘画】Stable Diffusion 本地部署教程!小白必收藏!!_智能绘画本地部署
- 2数据结构与算法——排序算法_用两个栈实现冒泡排序
- 3深度神经网络 FPGA 设计与现状
- 4oracle使用EXISTS函数_oracle exists函数
- 5(免费版?)CLion Nova 强势登陆 C 和 C++ 开发领域
- 6Git(3): VS2019 + Gitee 回滚代码、删除分支_vs git 还原
- 7Ansible总结-基础部分(ansible-doc与常用模块)
- 8[RK3568 Android11] 教程之VMware虚拟机安装步骤_vmware安装安卓11
- 9最新免费 ChatGPT、GPTs、AI换脸(Suno-AI音乐生成大模型)
- 10Android Studio 使用SQLite数据库来创建数据库+创建数据库表+更新表再次往表添加字段_android studio 数据库
数据库数据采集利器FlinkCDC_flinkcdc支持哪些库
赞
踩
持续分享有用、有价值、精选的优质大数据干货
致力于打造全网最优质的大数据专题
目录
一、Flink CDC概述
(一)Flink CDC是啥
Flink CDC是Flink社区开发的flink-cdc-connectors 组件,这是⼀个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
⽬前也已开源,开源地址:
https://github.com/ververica/flink-cdc-connectors
以下是官⽹:
https://ververica.github.io/flink-cdc-connectors/master/
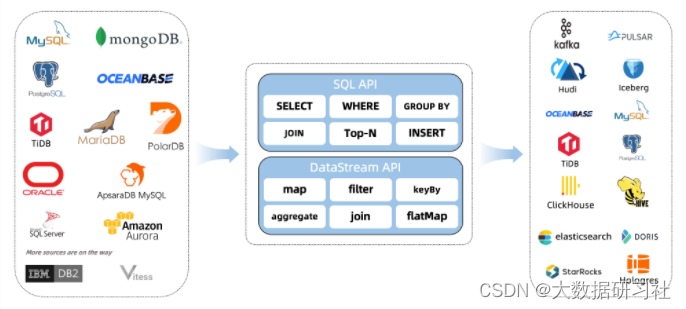
(二)支持的连接器
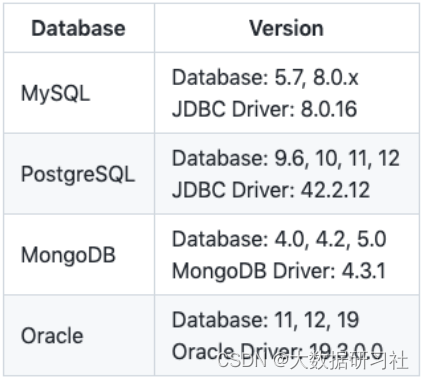
1、最新稳定版2.1.1⽀持列表
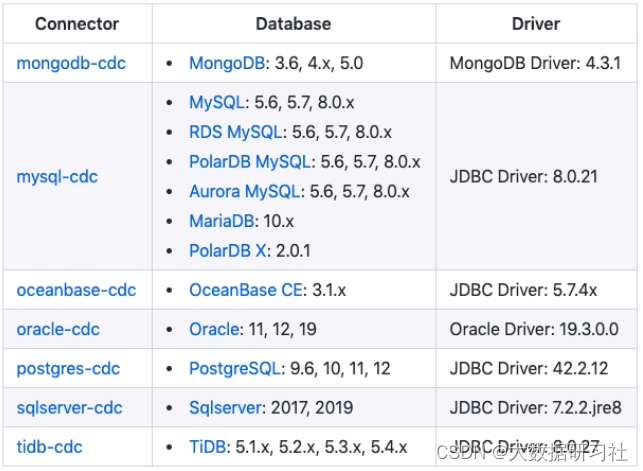
2、即将发布的2.2.0支持列表(master分支)
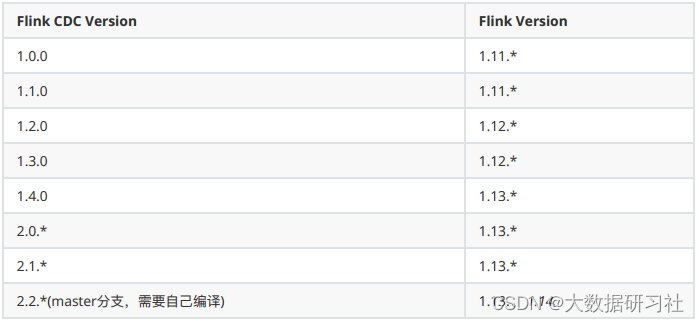
(三)支持的Flink版本
二、为什么需要Flink CDC
(一)传统CDC的不足
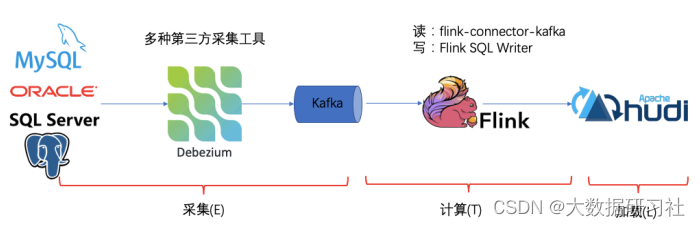
传统的基于 CDC 的 ETL 分析中,数据采集⼯具是必须的,国外⽤户常⽤ Debezium,国内⽤户常⽤阿⾥开源的Canal,采集⼯具负责采集数据库的增量数据,⼀些采集⼯具也⽀持同步全量数据。采集到的数据⼀般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这⼀部分数据写⼊到⽬的端,⽬的端可以是各种 DB,数据湖,实时数仓和离线数仓。
注意, Flink 提供了 changelog-json format,可以将 changelog 数据写⼊离线数仓如 Hive / HDFS;对于实时数仓, Flink ⽀持将 changelog 通过 upsert-kafka connector 直接写⼊ Kafka。
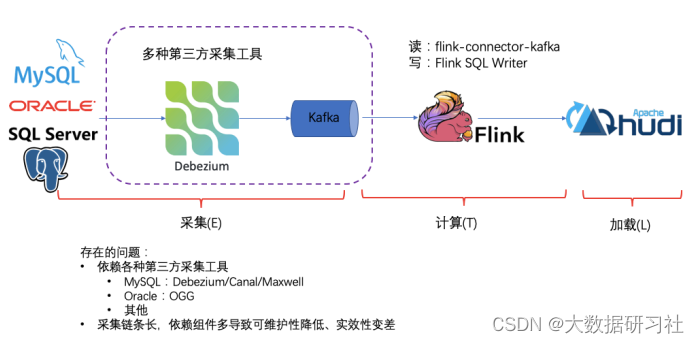
Flink CDC的基本理念就是去替换上图中虚线框内的采集组件和消息队列,从⽽简化传输链路,降低维护成本。同时更少的组件也意味着数据时效性能够进⼀步提⾼。
(二)Flink CDC采集方案
Flink CDC1.0主要想解决三个⽅⾯的问题:
(1)统⼀采集⼯具:封装Debezium⽀持主流的数据库
(2)简化ETL链路:将采集⼯具和Kafka整体替换
(3)降低使⽤⻔槛:⽀持Flink SQL⼤⼤降低使⽤⻔槛
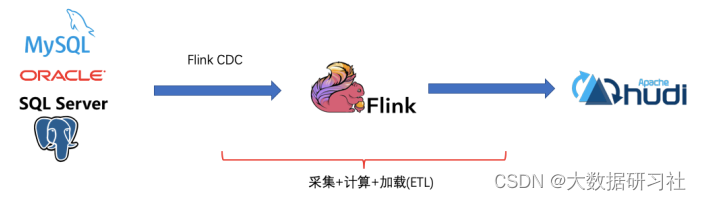
基于FlinkCDC,我们只需要通过⼀个 Flink SQL 作业就完成了 CDC 的数据采集,加⼯和同步,下⾯是⼀个例⼦:
- --需求:同步MySQL的orders表到TiDB的orders表
- --1、定义MySQL中orders表的cdc源表
- CREATE TABLE mysql_orders (
- id INT NOT NULL,
- product_id BIGINT,
- ...
- PRIMARY KEY(id)
- ) WITH (
- 'connector' = 'mysql-cdc',
- 'hostname' = 'xx',
- 'port' = '3306',
- 'username' = 'xx',
- 'password' = 'xx',
- 'database-name' = 'xx',
- 'table-name' = 'orders'
- );
- --2、创建TiDB结果表
- CREATE TABLE tidb_orders(
- id INT NOT NULL,
- product_id BIGINT,
- ...
- PRIMARY KEY(id)
- )
- WITH (
- 'connector' = 'jdbc',
- 'url' = 'jdbc:mysql://localhost:3306/xx',
- 'table-name' = 'orders'
- );
- --3、从源表读取数据写⼊结果表
- INSERT INTO tidb_orders
- SELECT * FROM mysql_orders;

所以基于Flink CDC的⽅案是⼀个纯 SQL 作业,⼤⼤降低了降低了使⽤⻔槛。当然,我们也可以利⽤ Flink SQL 提供的丰富语法进⾏数据清洗、分析、聚合,⽽不仅仅是简单的数据同步。利⽤ Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以⾮常容易地完成实时打宽,以及各种业务逻辑加⼯。
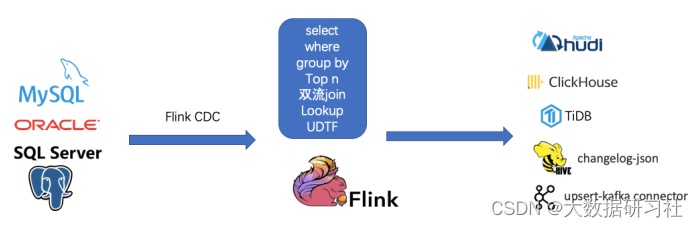
三、常见CDC方案比较
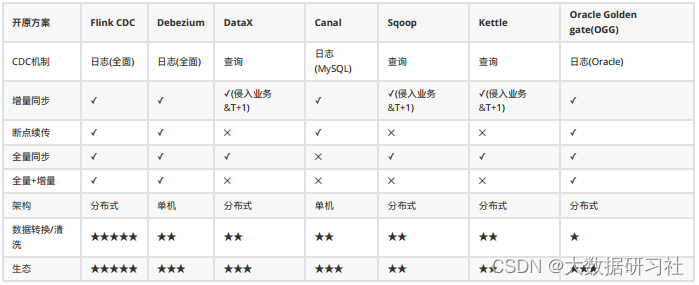
1、对⽐增量同步能⼒
(1)基于⽇志的⽅式,可以很好的做到增量同步(准实时);
(2)⽽基于查询的⽅式必须侵⼊业务才能做到增量同步的,⽽且是T+1的增量同步。
2、对⽐全量同步能⼒,基于查询或者⽇志的 CDC ⽅案基本都⽀持,除了 Canal。
3、⽽对⽐全量 + 增量同步的能⼒,只有 Flink CDC、 Debezium、 Oracle Goldengate ⽀持较好。
4、从架构⻆度去看,该表将架构分为单机和分布式,这⾥的分布式架构不单纯体现在数据读取能⼒的⽔平扩展上,更重要的是在⼤数据场景下分布式系统接⼊能⼒。例如 Flink CDC 的数据⼊湖或者⼊仓的时候,下游通常是分布式的系统,如 Hive、 HDFS、 Iceberg、 Hudi 等,那么从对接⼊分布式系统能⼒上看, Flink CDC 的架构能够很好地接⼊此类系统。
5、在数据转换 / 数据清洗能⼒上,当数据进⼊到 CDC ⼯具的时候是否能较⽅便的对数据做⼀些过滤或者清洗,甚⾄聚合?
(1)在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
(2)但是像 DataX、 Debezium 等则需要通过脚本或者模板去做,所以⽤户的使⽤⻔槛会⽐较⾼。
6、另外,在⽣态⽅⾯,这⾥指的是下游的⼀些数据库或者数据源的⽀持。 Flink CDC 下游有丰富的 Connector,例如写⼊到 TiDB、 MySQL、 Pg、 HBase、 Kafka、 ClickHouse 等常⻅的⼀些系统,也⽀持各种⾃定义connector。

