
热门标签
热门文章
- 12024年MathorCup数学建模A题移动通信网络中PCI规划问题解题文档与程序
- 2windows下的redis配置_--loglevel verbose
- 3kubernetes中的静态POD
- 4MySQL中格式化数据 format()与date_format()!!!_mysql 格式化
- 5Zynq PS无法读取SD卡(TF卡)异常分析及如何读写SD卡_zynq sd卡挂载失败
- 6【软件测试】终于有人讲明白:bug的分类和定级了!
- 7[手把手超简单]教你搭建Novel AI服务器_novel-naifu-aki
- 8史上最牛逼的fiddler抓包操作,【工具】Fiddler使用教程_抓包工具fiddler
- 9LLaMA Pro: Progressive LLaMA with Block Expansion
- 10Redis缓存_长时间储存用户信息,采用什么缓存
当前位置: article > 正文
【推荐系统】TensorFlow复现论文DeepCrossing特征交叉网络结构_tensorflow 类别特征中和数值特征
作者:从前慢现在也慢 | 2024-04-27 03:39:10
赞
踩
tensorflow 类别特征中和数值特征
一、导包
from collections import namedtuple # 使用具名元组
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,LabelEncoder
import pandas as pd
import numpy as np
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
二、读取数据
"""读取数据"""
data = pd.read_csv('./data/criteo_sample.txt')
- 1
- 2
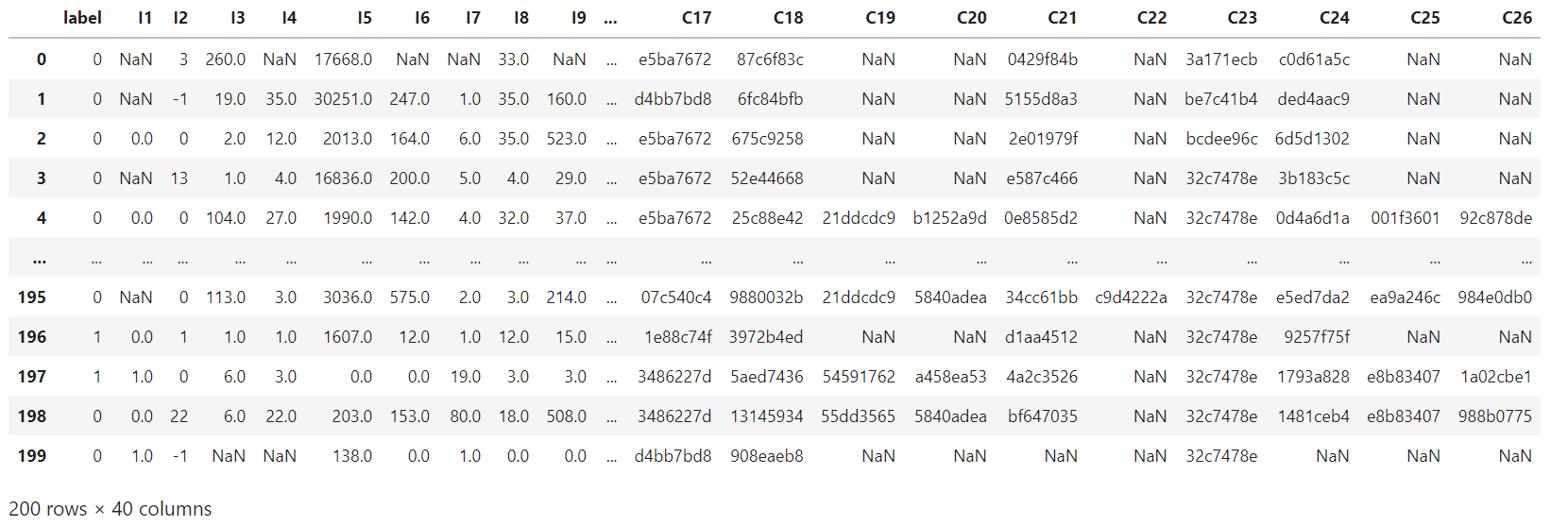
三、获取分类特征和数值特征
"""获取分类特征和数值特征"""
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]
- 1
- 2
- 3
- 4
四、数据处理
"""数据处理"""
def data_process(data, dense_features, sparse_features):
# 将数值特征的空值位置填补为0
data[dense_features] = data[dense_features].fillna(0.0)
# 调整分布
for f in dense_features:
data[f] = data[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
# 将分类特征进行编码,由于原数据中的类别都是字符串,所以要使用LabelEncoder编码成数值
data[sparse_features]=data[sparse_features].fillna("0") # 将类别特征进行填补,使用字符串
for f in sparse_features:
le = LabelEncoder()
data[f]=le.fit_transform(data[f])
return data[dense_features + sparse_features]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
train_data # (200,40)
- 1
- 2
- 3
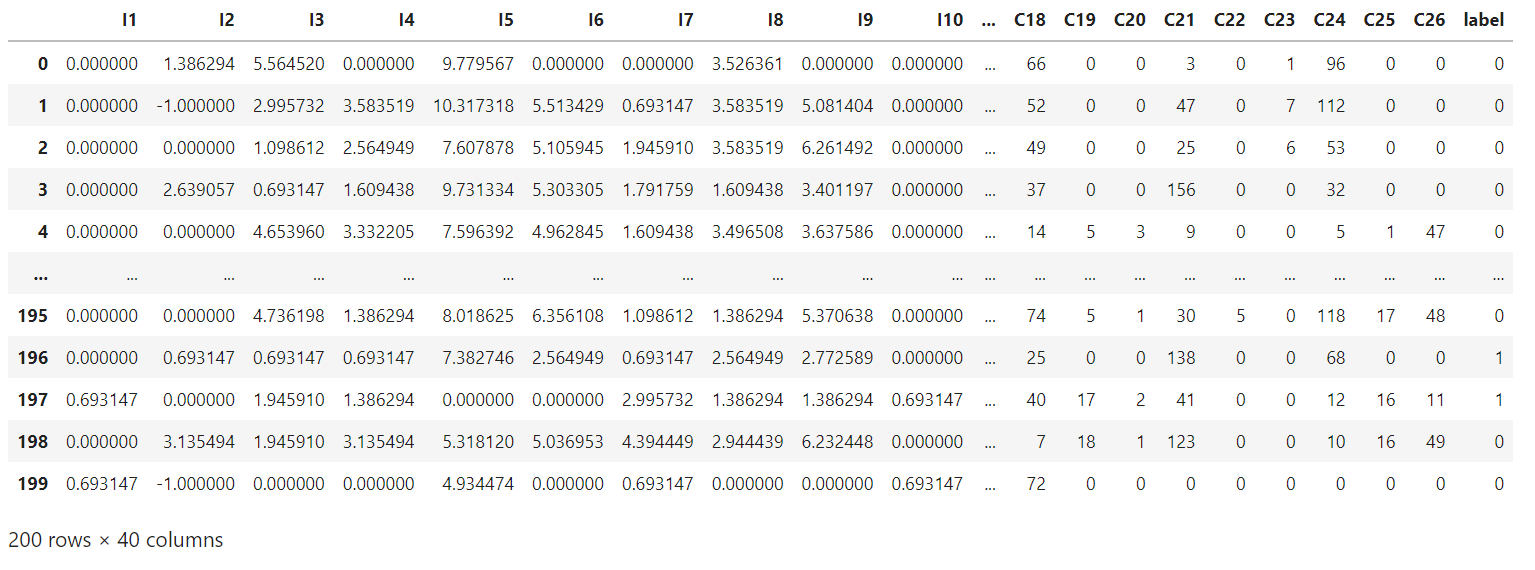
五、使用具名元组为特征做标记
"""使用具名元组为特征做标记"""
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
DenseFeat = namedtuple('DenseFeat', ['name', 'dimension'])
dnn_features_columns = [SparseFeat(name=feat, vocabulary_size=data[feat].nunique(), embedding_dim = 4) for feat in sparse_features] + [DenseFeat(name=feat, dimension=1) for feat in dense_features]
dnn_features_columns
- 1
- 2
- 3
- 4
- 5
- 6

六、构建模型
6.1 构建输入层
"""构建输入层"""
def build_input_layers(dnn_features_columns):
dense_input_dict, sparse_input_dict = {}, {}
for f in dnn_features_columns:
if isinstance(f, SparseFeat):
sparse_input_dict[f.name] = Input(shape=(1, ), name=f.name)
elif isinstance(f, DenseFeat):
dense_input_dict[f.name] = Input(shape=(f.dimension, ), name=f.name)
return dense_input_dict, sparse_input_dict
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.2 将类别特征进行embedding
"""将类别特征进行embedding"""
def build_embedding_layers(dnn_features_columns, input_layers_dict, is_linear):
embedding_layer_dict = {}
# 将sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x,SparseFeat), dnn_features_columns)) if dnn_features_columns else []
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
if is_linear:
for f in sparse_feature_columns:
embedding_layer_dict[f.name] = Embedding(f.vocabulary_size + 1, 1, name='1d_emb_' + f.name)
else:
for f in sparse_feature_columns:
embedding_layer_dict[f.name] = Embedding(f.vocabulary_size + 1, f.embedding_dim, name='kd_emb_' + f.name)
return embedding_layer_dict
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.3 将所有的sparse特征embedding进行拼接
"""将所有的sparse特征embedding进行拼接"""
def concat_embedding_list(dnn_features_columns, input_layer_dict, embedding_layer_dict, flatten=False):
# 筛选sparse特征
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_features_columns))
embedding_list = []
for f in sparse_feature_columns:
_input = input_layer_dict[f.name]
_embed = embedding_layer_dict[f.name]
embed = _embed(_input)
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.4 构建残差块
"""构建残差块"""
class ResidualBlock(Layer):
def __init__(self, units):
super(ResidualBlock, self).__init__()
self.units = units
def build(self, input_shape):
out_dim = input_shape[-1]
self.dnn1 = Dense(self.units, activation='relu')
self.dnn2 = Dense(out_dim, activation='relu')
def call(self, inputs):
x = inputs
x = self.dnn1(x)
x = self.dnn2(x)
x = Activation('relu')(x + inputs)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.5 构建输出层
"""构建输出层"""
def get_dnn_logits(dnn_inputs, block_nums=3):
dnn_out = dnn_inputs
for i in range(block_nums):
dnn_out = ResidualBlock(64)(dnn_out)
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logits
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6.6 构建模型
"""构建模型"""
def DeepCrossing(dnn_features_columns):
# 1.构建输入层
dense_input_dic, sparse_input_dic = build_input_layers(dnn_features_columns)
input_layers = list(dense_input_dic.values()) + list(sparse_input_dic.values())
# 2.将类别特征进行embedding
embedding_layer_dict = build_embedding_layers(dnn_features_columns, sparse_input_dic, is_linear=False)
# 3.将数值型特征拼接在一起
dense_dnn_list = list(dense_input_dic.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list)
# 4.将类别Embedding向量进行Flatten
sparse_dnn_list = concat_embedding_list(dnn_features_columns, sparse_input_dic, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list)
# 6.将数值特征和类别特征进行拼接
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs])
# 7.将所有特征输入到残差模块中
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
# 8.构建模型
model = Model(input_layers, output_layer)
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
七、训练模型
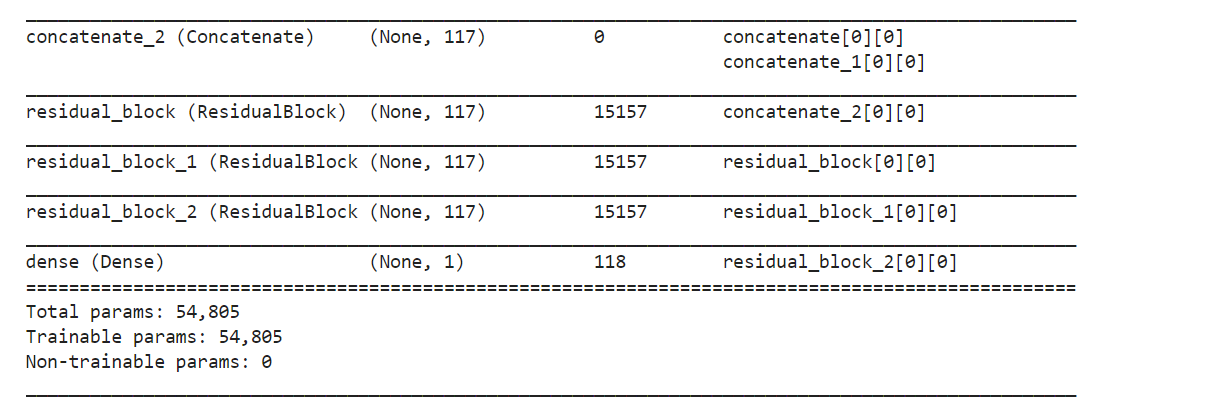
7.1 构建模型
history = DeepCrossing(dnn_features_columns)
history.summary()
- 1
- 2
7.2 编译模型
history.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_crossentropy', tf.keras.metrics.AUC(name='auc')])
- 1
- 2
- 3
7.3 准备输入数据
train_model_input = {name: data[name] for name in dense_features + sparse_features}
- 1
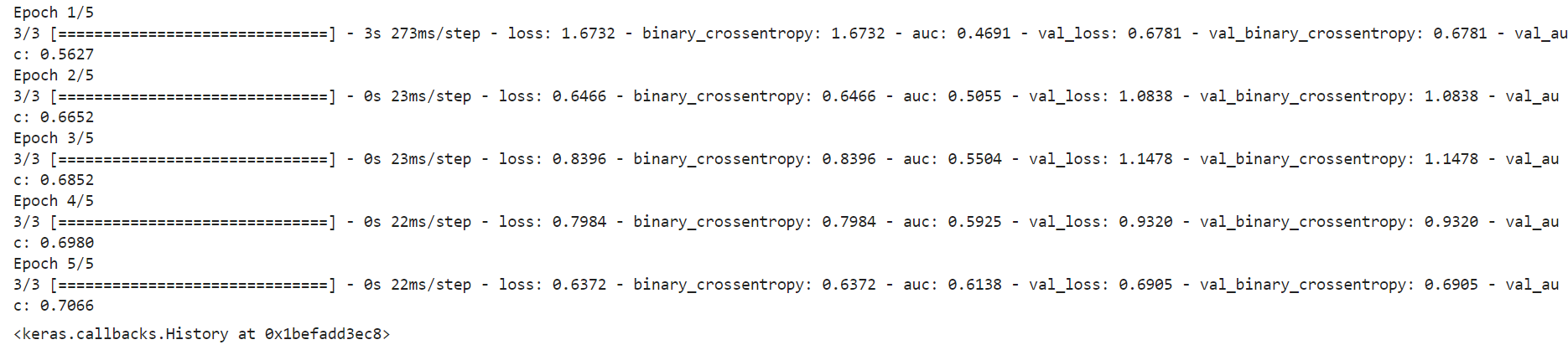
7.4 模型训练
history.fit(train_model_input,
train_data['label'].values,
batch_size=64,
epochs=5,
validation_split=0.2)
- 1
- 2
- 3
- 4
- 5
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/494594
推荐阅读
相关标签

