
- 1计算机毕业设计Java-ssm毕业论文管理系统源码+系统+数据库+lw文档_论文系统源码是什么文件
- 2使用Github-Action持续部署Springboot或vue_github actions runs-on 指定标签
- 3JSON文件读写_json写入文件
- 4python中的*args与**kwargs的含义与作用
- 5从加密到签名:如何使用Java实现高效、安全的RSA加解密算法?_java rsa加密
- 6AI应用 | 【AI+工业】LLM(大型语言模型)在工业领域中的十个应用_大语言模型在工业界的应用
- 7基于Android的购物商城系统应用设计与实现(论文+源码)_基于android的购物系统
- 8Docker Dockerfile Docker容器对外的22端口的监听_dockerfile 22端口
- 9综述 | 一文读懂自然语言处理NLP(附学习资料)
- 1002 socket套接字编程---udp服务端和客户端_soket udp 客户端
如何用VOSviewer分析CNKI关键词共现?
赞
踩
用VOSviewer尝试CNKI中文文献关键词共现(keyword co-occurence)分析时,你可能会踩到一个大坑。本文帮助你绕开这个坑,或是从坑里爬出来。

(由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
疑惑
在《如何用VOSviewer分析CNKI数据?》一文中,我们提到了如何用VOSviewer可视化分析CNKI文献。
依照文中的步骤,我们从CNKI下载并导出《图书情报知识》期刊2016年全年文献数据,通过Endnote作为中转,最终导出了VOSviewer可以读取的RIS文件。
我把这个几经辗转得来的RIS文件存放到了这里,你可以直接下载使用。
利用该数据文件,我们用VOSviewer分析合作者(Co-authorship),做出了这张图。

有的读者很兴奋,立即打算用同样的方法,做CNKI中文文献的关键词共现分析(keyword co-occurence)。
很快,他们就遇到了问题。因为用样例数据,虽然可以做出分析结果图,却是这个样子的:
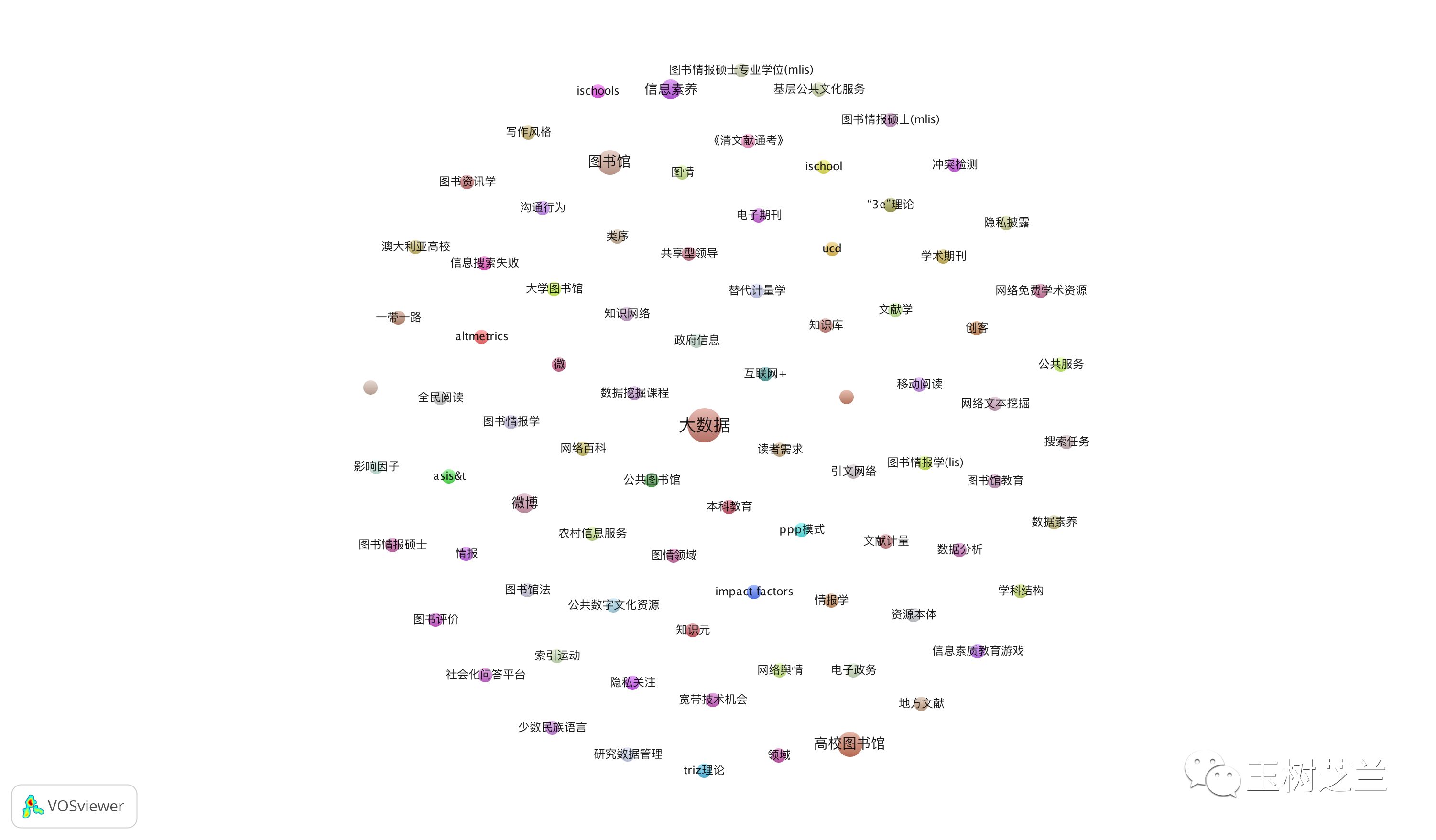
图里面只有关键词,没有任何关键词之间的连接。这叫什么共现分析?!
有读者很沮丧地把这幅图发给了我。问我这是否意味着,VOSviewer不能胜任中文文献的关键词共现分析?
当然不是。
VOSviewer做的是统计和可视化。对于它来说,中文和英文关键词没有本质区别。只要来源数据处理得当,分析的结果都应该是正确的。
那么问题究竟出在哪里呢?
原因
我们用样例数据,重新走一遍流程。复现读者遇到的困境。
VOSviewer主界面里,我们选择File -> map -> create,新建一个分析图。
第一个对话框问我们映射方式。
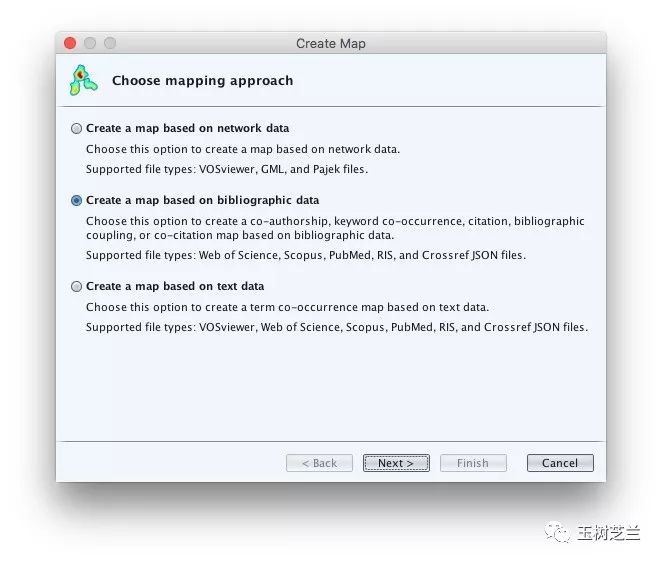
我们从中选择第二项。
然后新弹出的对话框会询问分析源文件的格式。
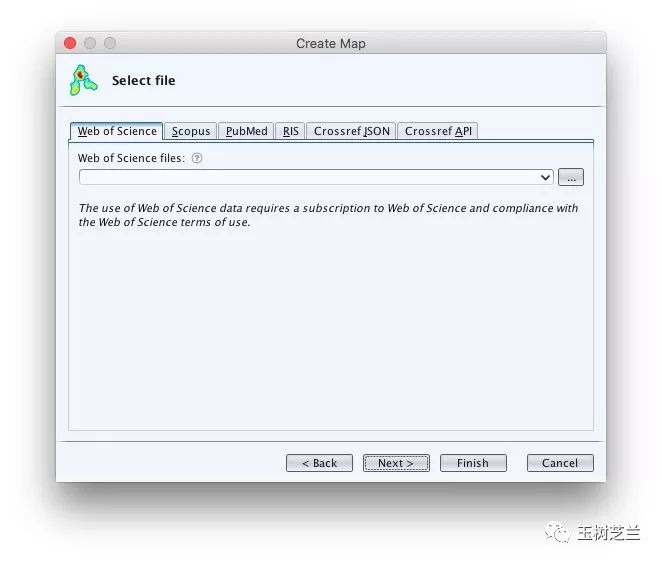
我们选择RIS。

下面的对话框,询问分析类型。默认是合作者分析(Co-authorship)。

我们选择关键词共现分析(Co-occurence)。

然后VOSviewer询问我们阈值的选择。
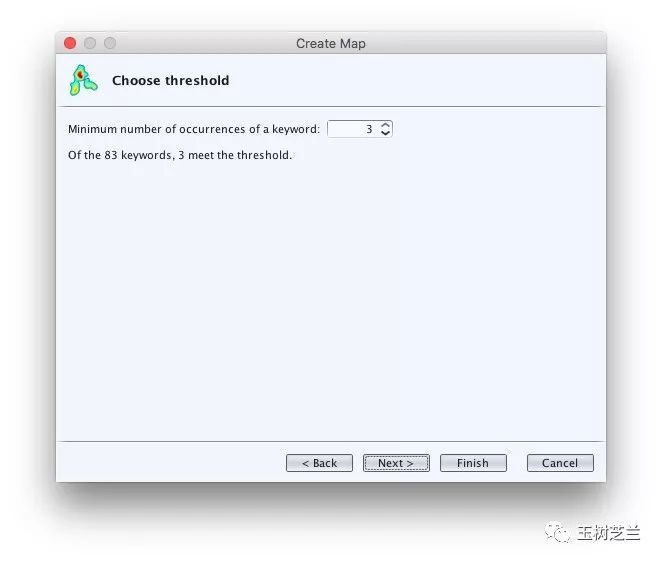
注意默认的阈值为3,可是这样只有3个关键词满足阈值。最终的图上如果只有3个节点,就太稀疏了。于是我们降低阈值到1。

VOSviewer提示我们,通过阈值过滤的关键词有83个。
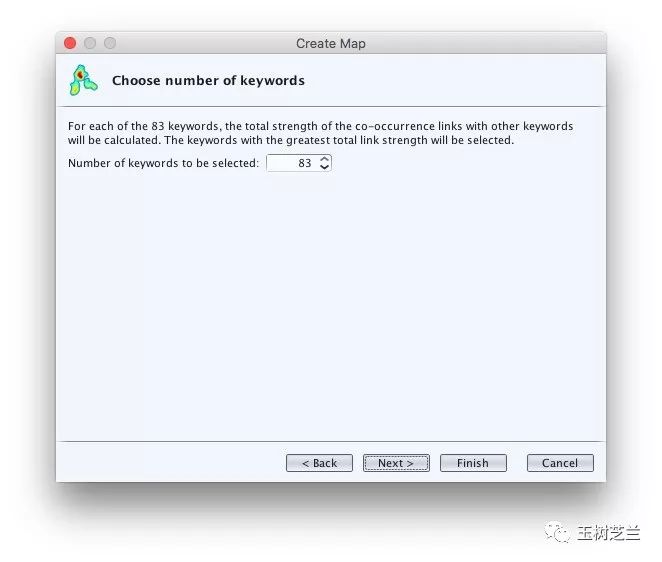
我们选择下一步。这时可以看到全部关键词列表。

我们可以从中选择或者反选关键词做分析。
但是此处别着急进行下一步。我们看到了非常奇异的现象。
注意图中列表的最后一列,是连接强度,也就是这一行的关键词与其他关键词共同出现的总次数。默认从大到小排列,可是所有的关键词共现次数居然都是0次。
难怪我们点击下一步的时候,会出现关键词节点间,全无链接。
为什么关键词同时出现次数分析值都是0呢?难道每篇论文只有1个关键词?关键词之间从来没有同时出现过?
这不符合常识。
我们发表期刊论文或者写毕业论文时,一般情况关键词至少也要列出3个吧。
带着这样的疑惑,我们就要检查一下RIS源文件了。
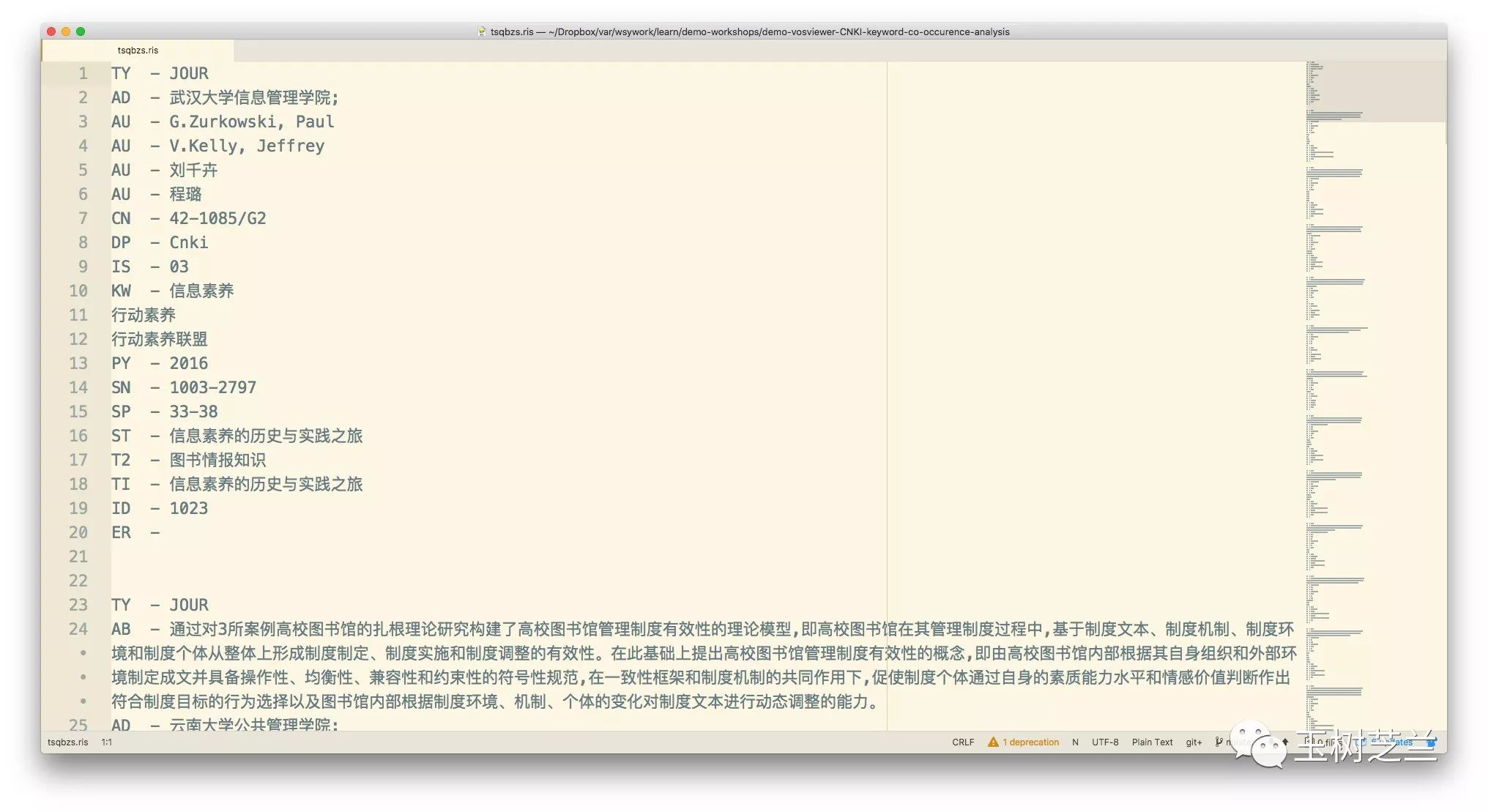
以其中的第一篇《信息素养的历史与实践之旅》为例,我们看到关键词一共有3个,分别为“信息素养”、“行动素养”和“行动素养联盟”。
如何识别它们是关键词呢?
因为前面有个KW -前缀作为标志。
然而问题来了,我们看到作者信息部分,每个作者名字前,都有AU -前缀。
AU - G.Zurkowski, Paul
AU - V.Kelly, Jeffrey
AU - 刘千卉
AU - 程璐
可是关键词这里,除了第一个有KW -前缀,其他都没有。
KW - 信息素养
行动素养
行动素养联盟
会不会是因为这个缘故,导致合作者分析链接正常,而关键词共现分析链接消失呢?
我们做个实验,验证一下咱们的猜测。
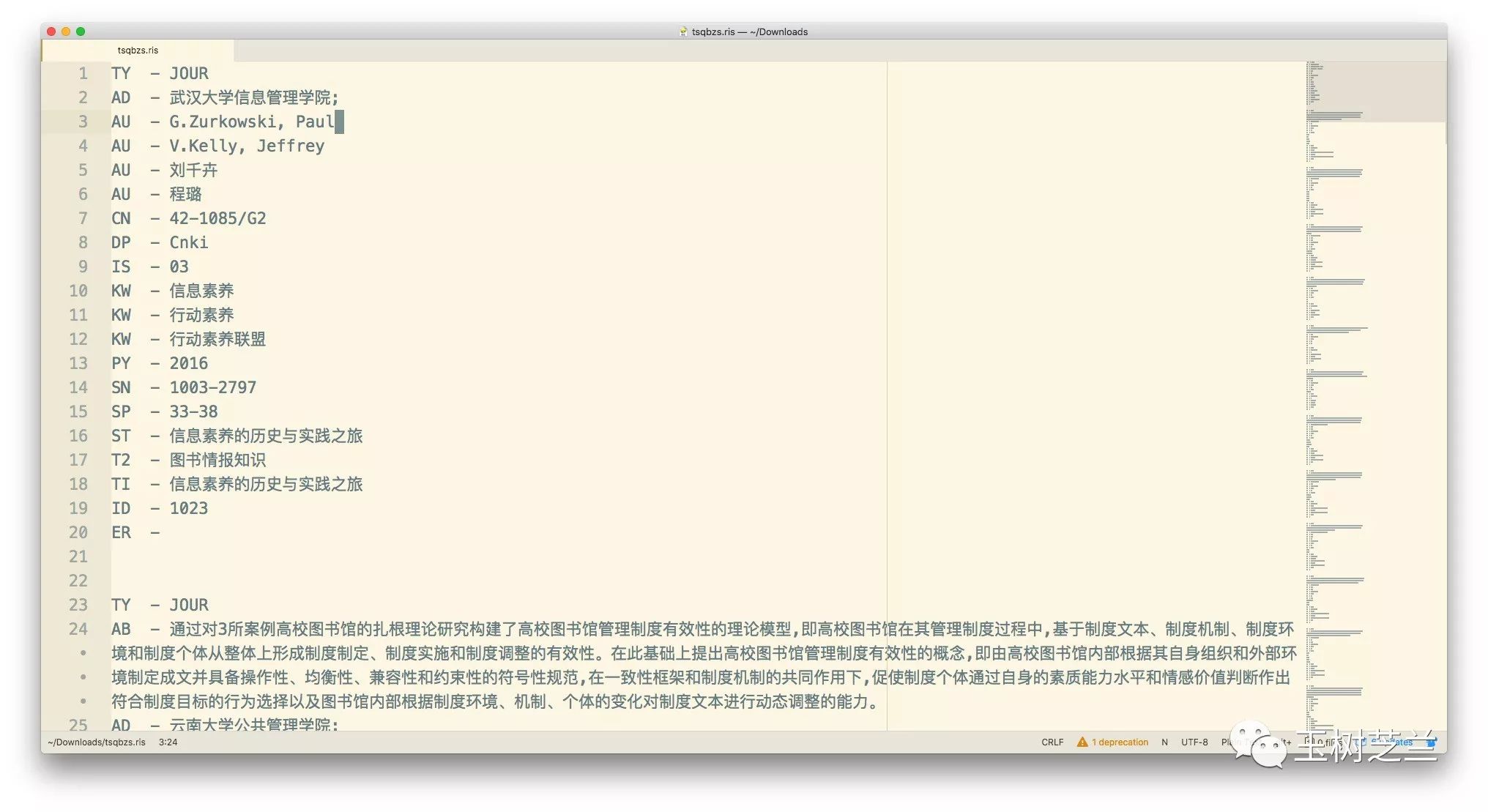
实验的方法很简单。我们把第一篇文献的另外两个关键词之前,都加上KW -前缀。其他文献的关键词不做任何处理。
修改后的RIS文件,就成了这样子:
我们回到VOSviewer,重新分析。前面的步骤和上一节完全一致。直至最后一步。

我们非常明显地对比出,关键词总链接强度(Total Link Strength)一项发生了变化,有几个关键词,不再是0了。
发生改变的这几个关键词,恰恰是刚才添加过前缀的那几个。

这个简单的实验,验证了我们的猜测。
并不是VOSviewr的处理能力有缺失,而是中文文献元数据,经由Endnote导出为RIS格式的时候有纰漏,导致多关键词的前缀没有全部正确添加。
效率
问题找到了。
下面我们该怎么办?
很简单,把所有关键词的前缀都添上就好了啊。
你可能立即觉得天旋地转。
把前缀都添上?说得轻巧!
样例数据里,文献有数十篇。一篇篇找关键词,添加前缀,虽然会做个头晕脑涨,但毕竟还有个盼头儿。
问题是,要分析的文献有好几千篇。都添完的时候,是不是下学期都该开学了?
也没那么夸张了。
想想愚公移山,精卫填海……先贤的精神力量还不够给你以感召吗?

精神固然要有,但效率也是要追求的。
我们当然不能一条条手动查找关键词并添加前缀,那样效率太低。我们要用工具来自动化解决这个问题。
好消息是,工具我已经帮你编写好了。
下面我详细告诉你,该怎么使用。
工具
我帮你编写的工具,是个Python脚本。
我们需要安装Python运行环境Anaconda,来使用这个脚本。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。
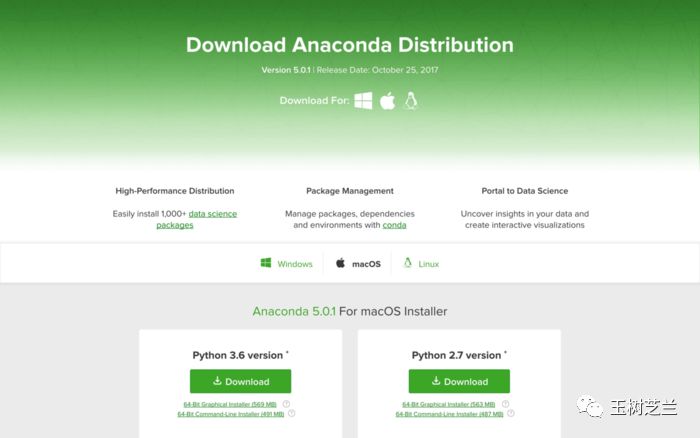
下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。

安装好Anaconda后,我们来下载脚本。
我把脚本存储在了Github项目里。请从这个位置下载压缩包。
下载后解压到本地,这个目录就是咱们的演示目录。

请进入终端(macOS或者Linux),用cd命令进入到这个目录。如果你用的是Windows,请运行Anaconda Prompt程序,并进入该目录。

下面,请执行以下命令。
python ris-add-kw-prefix.py tsqbzs.ris如果你要尝试处理自己的RIS文件,请把它拷贝到这个演示目录里面,然后把上面命令语句中最后部分(文件名)改成你自己的RIS文件。
执行后,你会发现目录下多了一个文件,叫做output.ris。
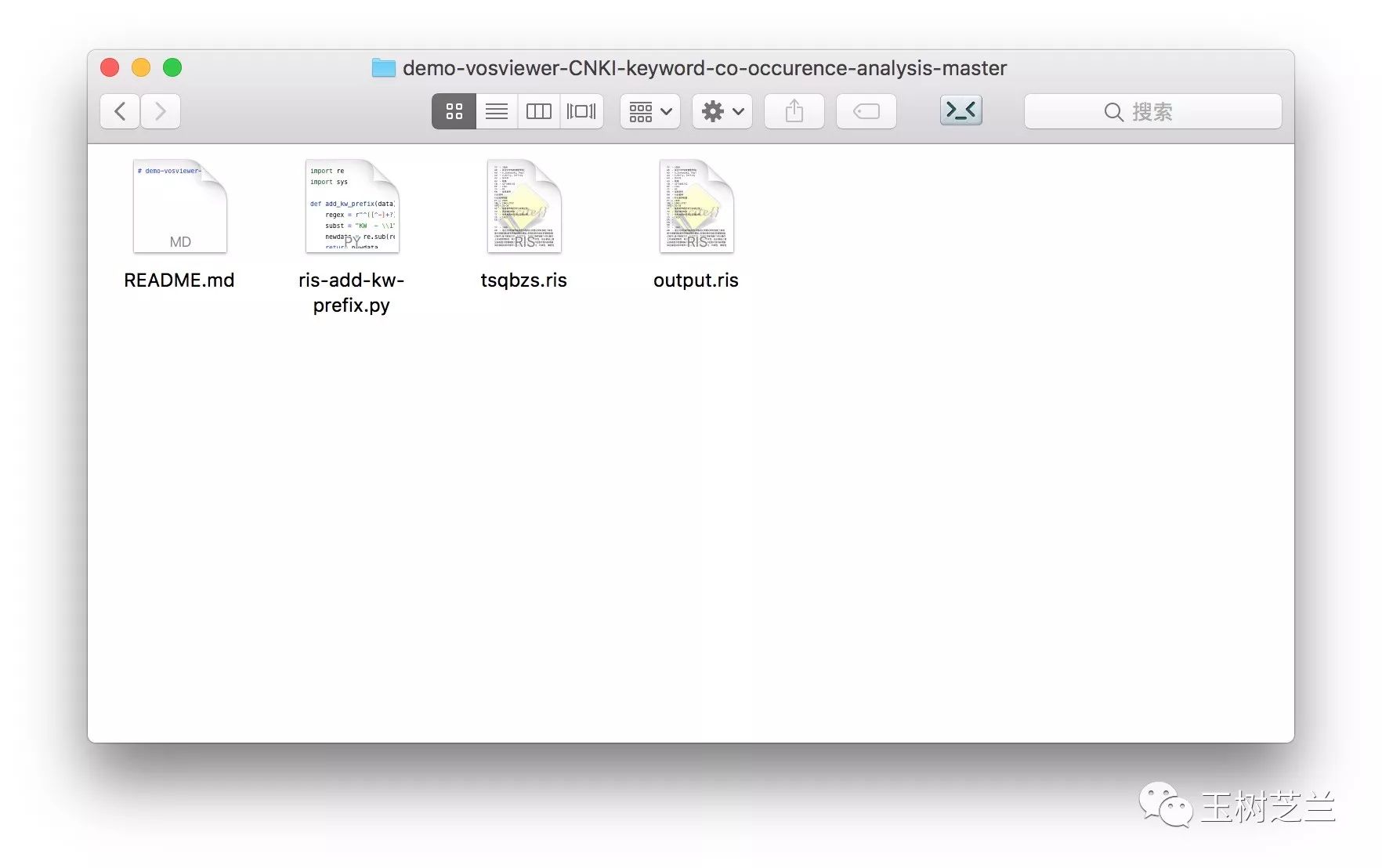
我们打开这个新生成的RIS文件。

可以看到,所有的未加前缀的关键词,都已经自动添加了前缀。
我们尝试将这个output.ris输入到VOSviewer,这次的分析结果列表如下:
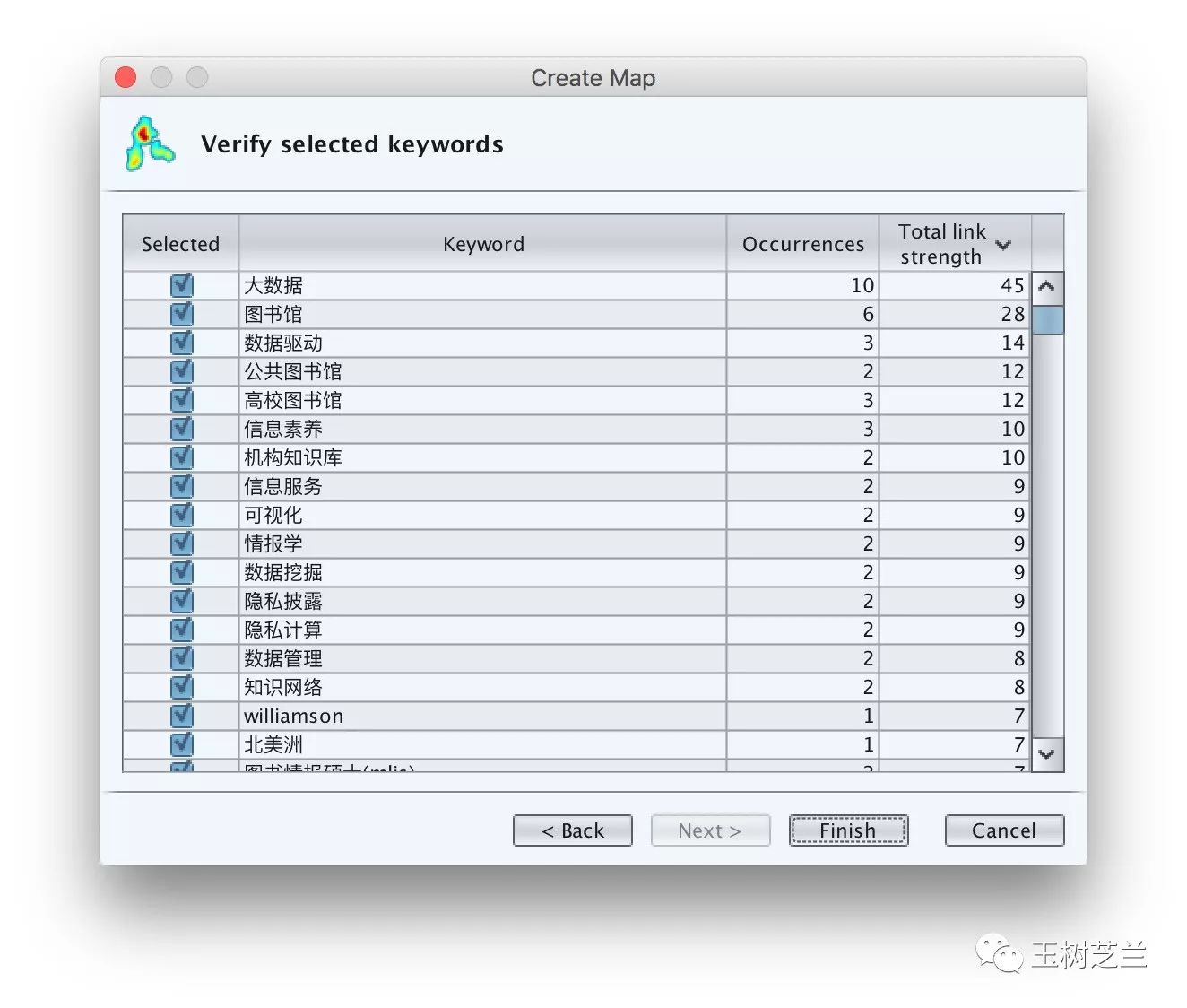
这时候再看关键词链接数量,就合理多了。
利用这个分析结果来可视化,你会看到以下生成的图形:
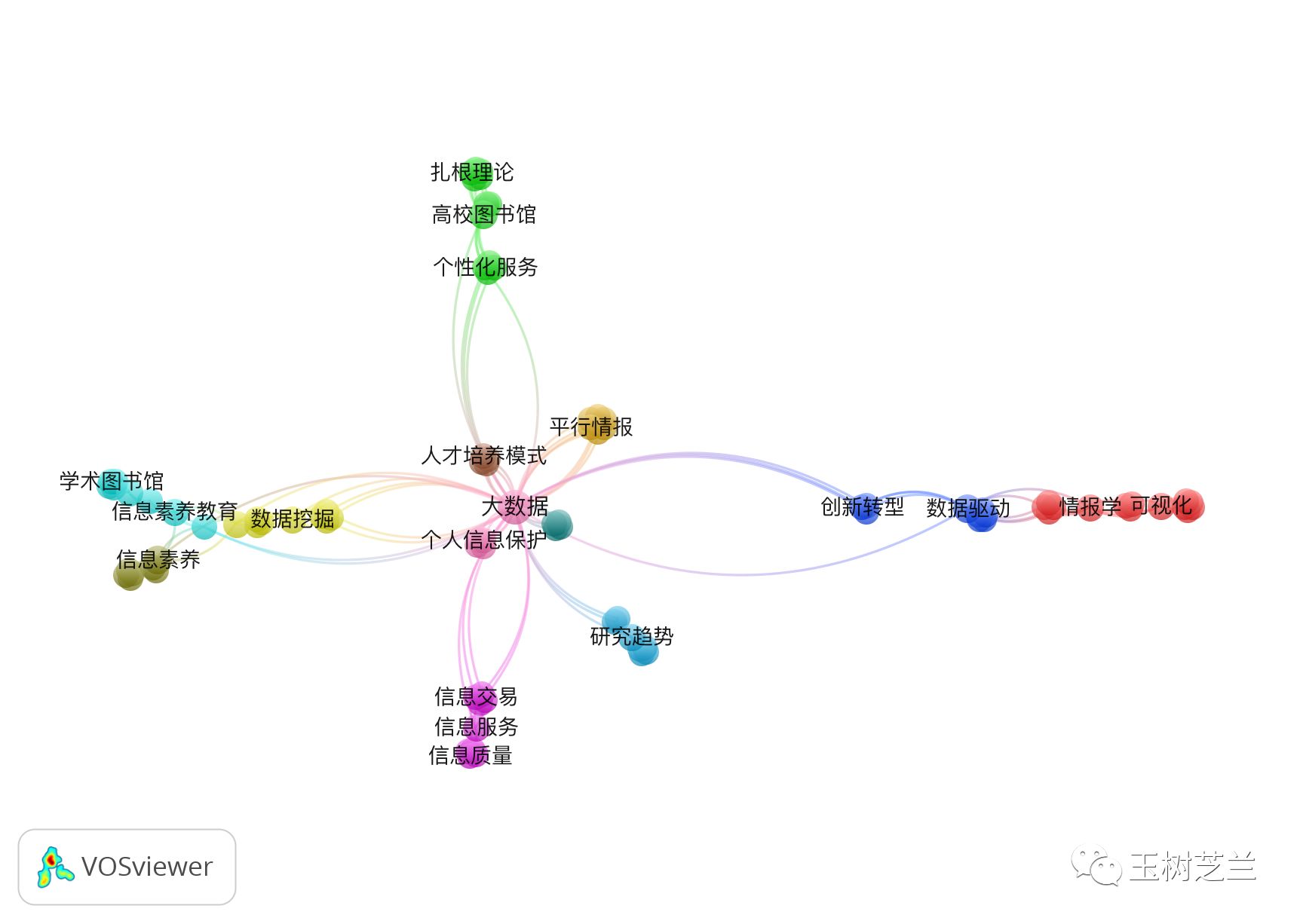
在这个样例中,我们只有几十篇文献。利用脚本处理前缀,显得有些大炮轰蚊子。
但如果你需要处理几千、几万篇文献的记录信息,用这个脚本也一样可以瞬间完成操作。效率的差别就体现得淋漓尽致了。
好了,到这里为止,你已经了解如何利用咱们编写的工具,对Endnote导出的中文文献做关键词处理,在VOSviewer中正确分析关键词共现了。
目标达成。
如果你对原理和技术细节不感兴趣,下面就可以跳到小结部分了。
如果你还没走,我来猜猜你在想什么。
这么高效的处理方法,是不是令你感觉不可思议?
老师你的工具至少有300行语句吧?
没有。
其实程序从头到尾,只有20多行。

而其中的核心部分,只有3行。
老师动用了什么黑魔法?!
魔法
我当然不会魔法。
我们使用的,是计算机最简单的能力——根据指令,重复执行枯燥劳动。
从第一行开始,依次检查每一行的文字。如果该行不是空行,而且其中不包含前缀连接符号“-”,那么我们就将其当成未加前缀的关键词。
我们让计算机在这行文字的最前面,加上KW -前缀。
就是这么简单,一点也不炫酷。
但是计算机怎么理解“不是空行”、“不包含符号‘-’”呢?
请看我们Python文件中的核心函数代码。
def add_kw_prefix(data): regex = r"^([^\-\s]+?)\s+$" subst = "KW - \\1" newdata = re.sub(regex, subst, data, 0, re.MULTILINE) return newdata我们用到的工具,叫做正则表达式(regular expression),简称re。

它是计算机处理文本模式的一种经典工具。
我们之前谈到机器学习的时候,曾经说过。机器学习模型,是人不知道怎么描述规则的时候,让计算机自己学。
而正则表达式,则恰恰相反,是人类可以很准确地描述规则时,为机器定义的模式。
正确定义模式后,计算机就会检查文本中是否包含这种模式,并且做出对应的处理。
正则表达式的功能非常强大,不过学起来需要花一番功夫。
如果你对正则表达式感兴趣,希望自己也能操纵计算机程序,对文本精确地做出模式识别与处理,可以参考DataCamp上的这篇教程来学习。

小结
通过本文,希望你已经了解了以下内容:
VOSviewer可以正确处理中文文献的关键词共现分析;
CNKI文献元数据经由Endnote导出成RIS时,关键词处理有瑕疵,需要添加对应前缀;
你可以利用我提供的Python脚本,来快速完成前缀添加工作;
正则表达式的使用,可以有效提升大规模文本模式匹配与处理操作的效率。
讨论
用本文的方法,你做出了正确的CNKI文献关键词共现分析了吗?在此之前,你是如何处理关键词共现分析的?有没有什么更加简便高效的方法?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
如果你对我的文章感兴趣,欢迎点赞,并且微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果本文可能对你身边的亲友有帮助,也欢迎你把本文通过微博或朋友圈分享给他们。让他们一起参与到我们的讨论中来。
如果喜欢我的文章,请微信扫描下方二维码,关注并置顶我的公众号“玉树芝兰”。

如果你希望支持我继续输出更多的优质内容,欢迎微信识别下方的赞赏码,打赏本文。感谢支持!

欢迎微信扫码加入我的“知识星球”圈子。第一时间分享给你我的发现和思考,优先解答你的疑问。


