
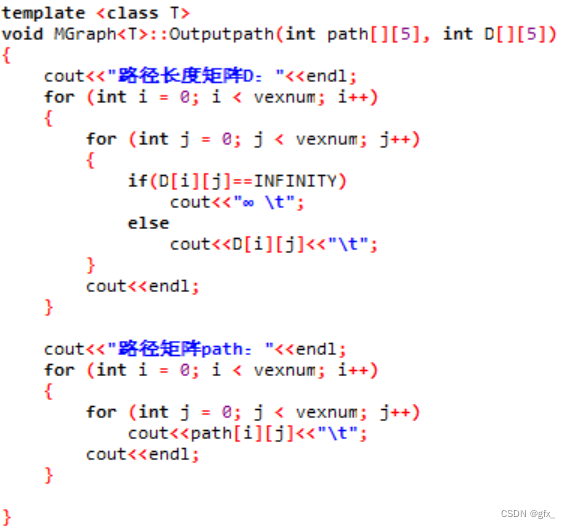
- 1实例6,stc8a8k单片机开发板4脚的OLED显示数据(I2C通信)_4脚oled原理图及引脚分析
- 2docker部署访问postgres数据库(一次到位)_connection reset by peer postgres docker
- 3FPGA极易入门教程----工具篇(1)建立你的第一个FPGA工程(点亮LED)_fpga教程
- 4Python实现图的最短路径算法_python 图 最短路径
- 5快速入门pyspark(总结)_import findspark
- 6第10课:主流的分布式消息队列方案解读及比较_分布式队列实现方案
- 7Git-多账户配置SSH免密登录_gitlab 多ssh config
- 8云客服怎么搜题答案?七个受欢迎的搜题分享了 #学习方法#经验分享#学习方法_云客服可以方便用什么工具来记录新的内容
- 9HarmonyOS应用开发系列课
- 10K8s系列之:job批处理调度_queue with pod per work item
数据结构集合
赞
踩
题 目:排序及其可视化+管道铺设施工最优方案
目录
1.6.1 Visual Studio MFC打不开资源文件.rc. 13
2.3.1 Prim算法求解管道铺设施工最优方案... 16
2.3.2 Kruskal算法求解管道铺设施工最优方案... 18
1 排序算法
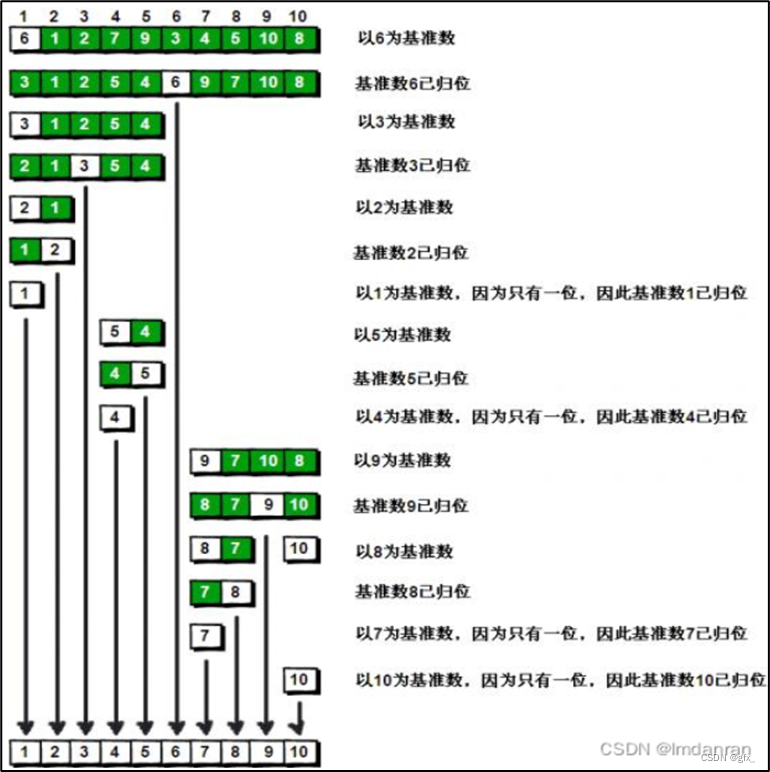
编程实现希尔、快速、堆排序、归并排序算法。要求首先随机产生10000个数据存入磁盘文件,然后读入数据文件,分别采用不同的排序方法进行排序并将结果存入文件中。
希尔排序是对插入排序的优化,基本思路是先选定一个整数作为增量,把待排序文件中的所有数据分组,以每个距离的等差数列为一组,对每一组进行排序,然后将增量缩小,继续分组排序,重复上述动作,直到增量缩小为1时,排序完正好有序。每一对分组进行排序后,整个数据就会更接近有序,当增量缩小为1时,就是插入排序,但是现在的数组非常接近有序,移动的数据很少,所以效率非常高,所以希尔排序又叫缩小增量排序。每次排序让数组接近有序的过程叫做预排序,最后一次插入是直接插入排序。
|
例:数组: 5 3 2 8 6 4 7 1
第一组:5 8 7 第二组:3 6 1 第三组:2 4
第一组:5 7 8 第二组:1 3 6 第三组:2 4 第一次排序数组变为:5 1 2 7 3 4 8 6
第一组:5 2 3 8 第二组:1 7 4 6
第一组:2 3 5 8 第二组:1 4 6 7 第二次排序数组变为:2 1 3 4 5 6 8 7
第三次排序数组变为:1 2 3 4 5 6 7 8 |
希尔排序之所以能够比普通的插入排序效率更高,主要是因为希尔排序采用了分组插入排序的策略,通过每次以增量的步数空出插入位置,使得数组逐渐变得接近有序。这种预排序的方式使得插入排序需要移动的次数变得更少,从而提高了排序的效率。希尔排序在越大的数组上更能发挥优势,因为步子迈的更大,减少插入排序的移动次数更多。
快速排序的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另一部分的所有数据要小,再按这种方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,使整个数据变成有序序列。
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。
快速排序只是使用数组原本的空间进行排序,所以所占用的空间应该是常量级的,但是由于每次划分之后是递归调用,所以递归调用在运行的过程中会消耗一定的空间,在一般情况下的空间复杂度为 O(logn),在最差的情况下,若每次只完成了一个元素,那么空间复杂度为 O(n)。所以我们一般认为快速排序的空间复杂度为 O(logn)。
快速排序是一个不稳定的算法,在经过排序之后,可能会对相同值的元素的相对位置造成改变。
总的来说,快速排序基本上被认为是相同数量级的所有排序算法中,平均性能最好的。
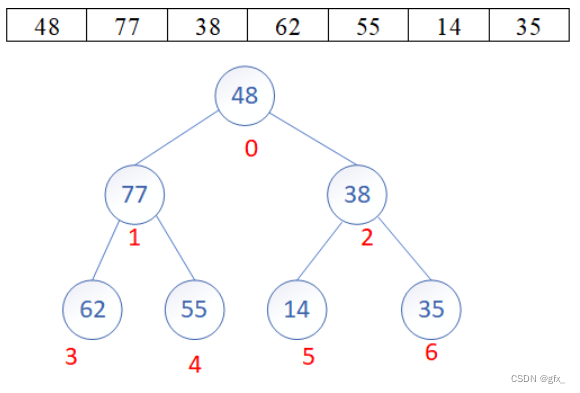
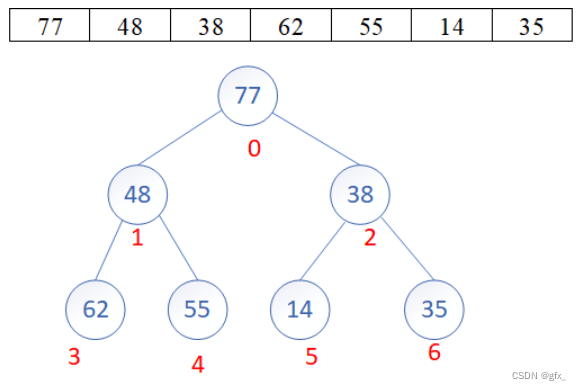
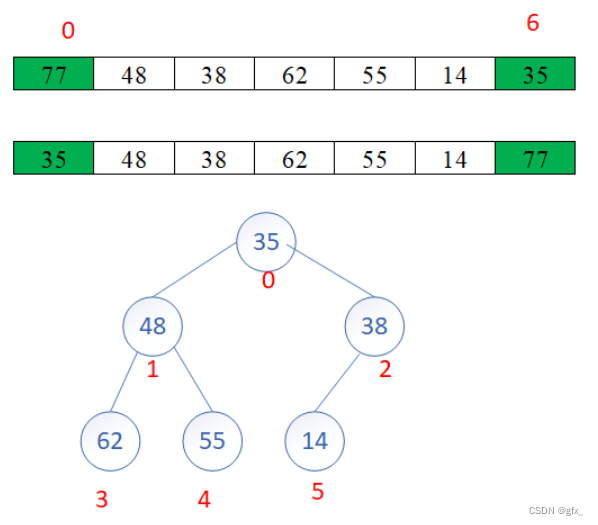
堆排序(Heap Sort)是一种基于堆数据结构的排序算法,其核心思想是将待排序的序列构建成一个最大堆(或最小堆),然后将堆顶元素与最后一个元素交换,再将剩余元素重新调整为最大堆(或最小堆),重复以上步骤直到所有元素都有序。
堆排序的实现过程如下:
(1)构建堆:首先将待排序的序列构建成一个最大堆(或最小堆),可以从最后一个非叶子节点开始,从右至左,从下至上依次将每个节点调整为符合堆的性质。
(2)堆排序:将堆顶元素与最后一个元素交换,然后将剩余元素重新调整为最大堆(或最小堆),再次将堆顶元素与倒数第二个元素交换,如此循环直到排序完成。
其优点主要包括:
(1)时间复杂度较低:堆排序的时间复杂度为O(nlog n),相对于其他排序算法,其排序速度较快。
(2)不占用额外空间:堆排序是一种原地排序算法,不需要额外的空间来存储排序结果。
(3)适用于大数据量的排序:堆排序的时间复杂度不随数据量的增加而变化,因此适用于大数据量的排序。
堆排序具有不稳定性,由于堆排序是通过交换元素来实现排序的,因此在排序过程中可能会破坏原有的相对顺序,导致排序结果不稳定。
总的来说,堆排序适用于需要对大量数据进行排序的场景,特别是在数据量较大、内存有限的情况下,堆排序可以通过原地排序的方式,节省额外空间的使用。

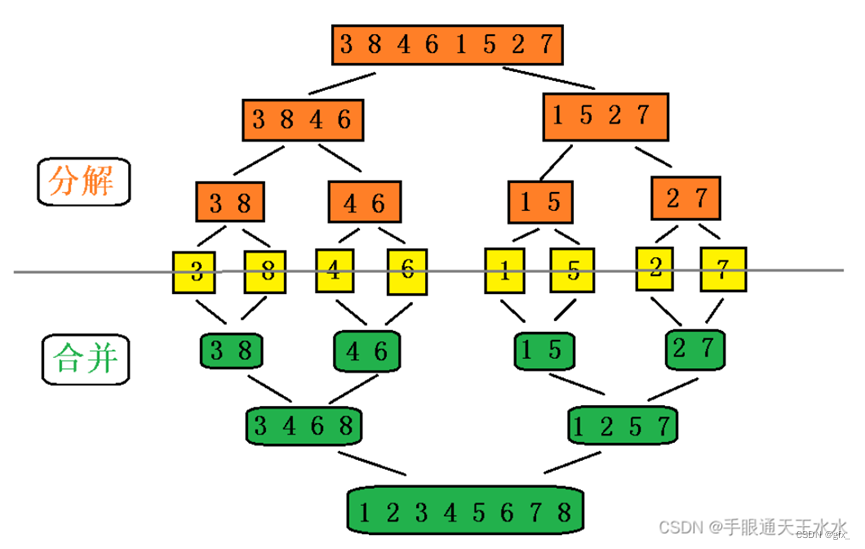
归并排序是建立在归并操作上的一种有效的排序算法,采用分治法排序,分为分解、合并两个步骤:
(1)分解:将数组分割成两个数组,再分别将两个数组又细分成2个数组,直到,最后每个数组都是一个元素,这时将该单元素数组看为有序数组
(2)合并:将分割的有序数组进行排序,排成有序数组后继续为上一个分割它的数组合并,直到数组被合并成原来的数组,此时已经排好序了。
归并排序是否稳定取决于merge函数,在合并有序数组过程中,如[1,1,2],[1,3],会依次将左边数组的1,1放入临时数组中,再放入右边数组的1,所以左边数组的两个相同元素先后顺序没有改变,右边数组的1也没有插入左边数组两个1的中间。因此,该算法是稳定的。
最好情况、最坏情况、平均时间复杂度都是O(nlogn)。
归并排序的时间复杂度和待排序数据的有序性无关,因此这三个时间复杂度相同。
空间复杂度是O(n),因为merge函数需要创建临时数组存放两个有序数组排好序之后的数组。
在搜集资料的过程中,我对排序算法可视化很感兴趣,觉得这是一个辅助学习算法很好的工具。我搜索到GitHub上实现了九种排序算法可视化的项目,并根据README.md配置了cv2、numpy、pygame,运行看看效果。
效果截图如下(动态图附在课程设计文件压缩包中):
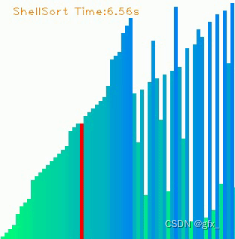
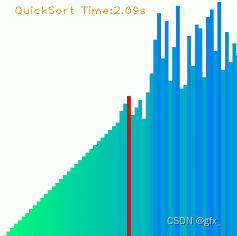
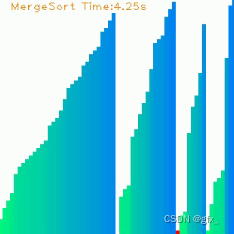
调试该项目的过程中也遇到过问题,项目更新了播放声音的功能,sndarray这个函数要接收的至少是个二维数组,报错了。删掉播放声音的功能,项目就可以正常运行了。
在此基础上我尝试写了数字1-32的排序过程python短代码,运行效果截图如图所示:
希尔排序:
快速排序:
堆排序:
我还在探索过程中发现了一个便于学习算法的算法可视化网站,相见恨晚。
网址:通过动画可视化数据结构和算法<br> - VisuAlgo
希尔排序:
适用于中等规模的数组排序,效率取决于增量序列的选择。
平均复杂度界于 O(n) 到 O(n^2) 之间,普遍认为它最好的时间复杂度为 O(n^1.3)
快速排序:
适用于大规模数据排序,实现简单,性能较好。
平均情况下时间复杂度为O(nlogn),最坏情况下为O(n^2),通常情况下表现优异。
堆排序:
适用于大规模数据排序,空间复杂度为O(1)。
时间复杂度稳定为O(nlogn),不受输入数据的影响。
归并排序:
归并排序是一种稳定的排序算法,基于分治和合并的策略实现排序。
适用于任何规模的数据排序,性能稳定。
时间复杂度始终为O(nlogn),空间复杂度较高为O(n)。
-
- 遇到的问题及解决方案
- Visual Studio MFC打不开资源文件.rc
- 遇到的问题及解决方案
窗口(W)->关闭所有选项卡(L)
1.6.2执行程序后,对话框的大小不可调
更改对话框的属性,Border改成Resizing,Minimize Box跟Maxmize Box选上。
1.6.3在编辑框中追加文本并换行
将编辑框的属性:
Auto HScroll 设置为 False
MultiLine 设置为 True
Want Return 设置为 True
N(N>10)个居民区之间需要铺设煤气管道。假设任意两个居民区之间都可以铺设煤气管道,但代价不同。要求事先将任意两个居民区之间铺设煤气管道的代价存入磁盘文件中。设计一个最佳方案使得这N个居民区之间铺设煤气管道所需代价最小,并将结果以图形方式在屏幕上输出。
Prim算法或Kruskal算法搜索最小生成树是解决这类问题的最佳选择,该算法可以找到连接所有节点的最小代价的树结构,从而使得铺设煤气管道的总代价最小。
-
-
- Prim算法搜索最小生成树
-
(1)选择一个起始节点作为最小生成树的起点。
(2)将该起始节点加入最小生成树集合,并将其标记为已访问。
(3)在所有与最小生成树集合相邻的边中,选择权重最小的边和它连接的未访问节点。
(4)将该边和节点加入最小生成树集合,并将该节点标记为已访问。
重复步骤(3)和步骤(4),直到最小生成树集合包含了图中的所有节点。
-
-
- Kruskal算法搜索最小生成树
-
依次判断两个顶点之间加入其他顶点后路径会不会缩短,若缩短则记录路径值和加入顶点值。首先先定义一个结构存储所有的边,然后再按权值从小到大的排序,从头开始遍历,每一次取出来的边都是权值最小的一条边。每次先判断取出的边的两点是否已经在一个集合中了,不在一个集合中就合并,记录权值,反之就跳过本次循环。循环结束,就将所有的结点都加到了一个集合中。
1.设计prim算法的数据结构和初始化过程
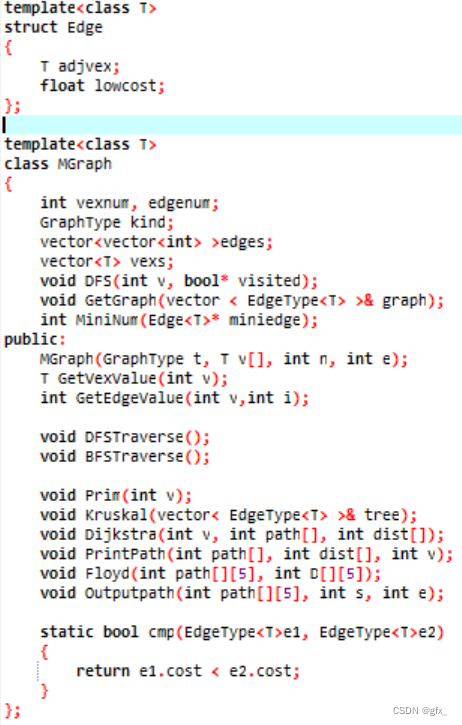
- 定义顶点数据类型:最小生成树的绘制需要记录顶点(居民区)的坐标。顶点数据类型定义为结构体类型,包括x坐标,y坐标和顶点(居民区)名称data。
- 定义图的信息:包括点集vexs数组、邻接矩阵a数组、点的个数vexnum和边的个数arcnum。
定义候选最短边集:包括候选最短边的邻接点adjvex 和权值lowcost。
2.文件输入与结果保存
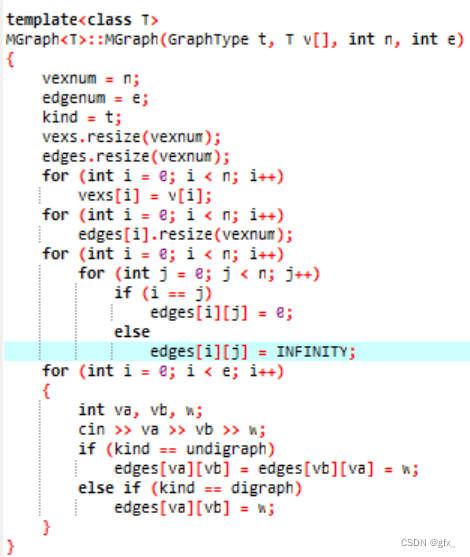
读取顶点的数量和边的数量,逐个读取每个顶点的名称、坐标信息,以及每个顶点之间的边的权值。最后关闭文件流,完成从文件中获取数据初始化图的操作。
3.最小生成树动态过程绘制(图形化)
(1)下载图形库EasyX
下载网址EasyX Graphics Library for C++
安装Visual对应版本即可
(2)#include<graphics.h> 头文件
initgraph(x,y,SHOWCONSOLE) 用于创建一个窗口,x表示长,y表示高
closegraph 用于关闭窗口
fillcircle(x0,y0,r) 绘制一个有边框的填充圆
setfillcolor(blue) 设置填充颜色
line(x0,y0,x1,y1) 两点分别为线的起始点和终止点坐标
setlinecolor(blue) 填充线条颜色
outtextxy(x0,y0,str) x0,y0表示输出位置,str是输出的字符
-
-
- Kruskal算法求解管道铺设施工最优方案
-
1.设计Kruskal算法的数据结构和初始化过程
(1)定义顶点数据类型:最小生成树的绘制需要记录顶点(居民区)的坐标。顶点数据类型定义为结构体类型,包括x坐标,y坐标和顶点(居民区)名称data。
(2)定义边的信息:包括该边的顶点v1,该边的顶点v2,边权(代价)w。
(3)定义图的信息:包括点集vexs数组、边集edges数组、邻接矩阵a数组、点的个数vexnum和边的个数edgenum。
2.文件输入与结果保存
详同上文prim算法
3.最小生成树动态过程绘制(图形化)
详同上文prim算法
2.4.1 outtextxy函数报错
Visual Studio中点击项目(P)->属性(P)
配置属性->高级->高级属性->字符集->使用多字节字符集
如何在两点连线中间添加代价数值
参考outtextxy_outtextxy函数-CSDN博客
运用springf函数把整数打印到字符串中。
springf还可以做strcat的功能:
sprintf(s, "%s love %s.", who,whom); //产生:"I love C++. "
2.4.3 EasyX基础知识
1.颜色函数:
RGB(int red,int green,int blue),三个参数的值取值范围都是[0,255],用RGB宏合成颜色,实际上合成出来的颜色是一个十六进制的整数。
2.坐标:
坐标的原点默认在窗口的左上角,x轴向右为正,y轴向下为正,度量单位是像素点。
3.窗口函数:initgraph(int width,int height,int flag)
flag有三个值:SHOWCONSOLE,NOCLOSE,NOMINIMIZE
SHOWCONSOLE:在显示自己创建的窗口的同时,显示控制台窗口。
NOCLOSE:自己创建的窗口,关闭功能失效。
NOMINIMIZE:自己创建的窗口,最小化功能失效。
收获与体会
希尔排序是插入排序的一种改进版本,通过改变插入排序的步长和预排序策略来提高排序效率。适用于中等规模的数组排序,效率取决于增量序列的选择。时间复杂度介于O(n)和O(n^2)之间,普遍认为它最好的时间复杂度为 O(n^1.3),平均情况下性能较好。
快速排序是一种基于分治策略的排序算法,通过选取一个基准值将数组分成左右两部分递归排序。适用于大规模数据排序,实现简单,性能较好。平均情况下时间复杂度为O(nlogn),最坏情况下为O(n^2),但通常情况下表现优异。
堆排序是利用堆这种数据结构进行排序的一种排序方法,基于完全二叉树的性质进行排序。适用于大规模数据排序,空间复杂度为O(1)。时间复杂度稳定为O(nlogn),不受输入数据的影响。
归并排序是一种稳定的排序算法,基于分治和合并的策略实现排序。适用于任何规模的数据排序,性能稳定。时间复杂度始终为O(nlogn),空间复杂度较高为O(n)。
在探索排序算法可视化的过程中,我在GitHub上找到了实现九种排序算法可视化的项目,从下载项目源码到配置环境再到校正报错,我在这个过程中得到了锻炼和提升,并在此基础上尝试写了数字1-32的排序可视化python代码,让可视化过程更加简明。还找到了不止于排序算法的算法可视化网站,有助于后续算法的学习,是一大利器。
在设计排序算法图形化界面时,MFC提供了丰富的界面设计工具和控件,使得程序界面展示更加直观。用户可以通过图形化界面方便地进行操作和获取信息,提升了用户体验。通过学习利用MFC设计程序界面,我不仅提升了软件开发技能,也为自己的技术发展开辟了新的领域。
在解决 N 个居民区之间铺设煤气管道代价最小的问题中,最佳选择是使用 Prim 算法或 Kruskal 算法来搜索最小生成树。这两种算法可以有效找到连接所有节点的最小代价的树结构,从而使得铺设煤气管道的总代价最小。
通过掌握 EasyX 基础知识,能更灵活地绘制图形,优化用户界面,同时结合 sprintf 函数可以方便地将整数转换为字符串,实现在图形中显示数值信息的功能。我通过这些技能的学习和应用,更好地完成了图形界面的设计和展示,提高用户体验和交互效果。
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
实现二叉排序树上的查找算法
(1)用二叉链表做存储结构,输入若干整数,建立一棵二叉排序树。
(2)判断是否是二叉排序树。
(3)在二叉排序树上插入结点。
(4)删除二叉排序树上的某一个结点。
(5)输入关键字,在二叉排序树上实现查找。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)

四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)

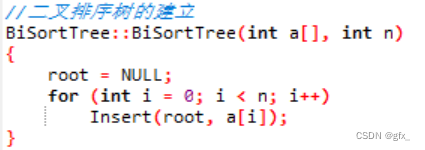
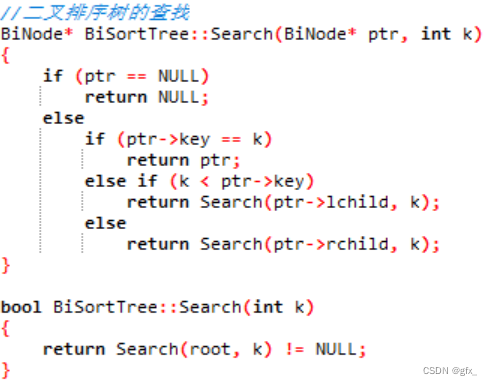

第一种方式是递归查找,使用了递归函数`Search`来实现。该函数首先判断当前节点是否为空,若为空则返回NULL表示未找到;若不为空,则判断当前节点的关键字与目标关键字k的大小关系,如果相等则返回当前节点指针;如果k小于当前节点关键字,则递归调用`Search`函数在左子树中查找;如果k大于当前节点关键字,则递归调用`Search`函数在右子树中查找。最终,当找到目标节点时,返回该节点的指针;未找到则返回NULL。
第二种方式是非递归查找,使用了循环来实现。该函数使用一个while循环,检查当前节点是否为空,如果为空则表示未找到,返回NULL;如果不为空,则判断当前节点的关键字与目标关键字k的大小关系,如果相等则返回当前节点指针;如果k小于当前节点关键字,则将当前节点指针指向其左子节点;如果k大于当前节点关键字,则将当前节点指针指向其右子节点。循环直到找到目标节点或者遍历完整个二叉排序树。最终,当找到目标节点时,返回该节点的指针;未找到则返回NULL。
两种方式的差异在于实现方式上的不同。递归方式更为简洁,但在处理较大的二叉排序树时可能会因为函数调用的层级过深而导致栈溢出。非递归方式则避免了函数调用的开销,更为节省内存,但需要使用额外的指针操作来实现循环查找。选择哪种方式取决于具体的应用场景和性能需求。

`Delete`函数是一个递归函数,用于在以指定节点`ptr`为根的二叉排序树中删除关键字为`k`的节点。`Delete(int k)`是一个对外接口函数,用于在整个二叉排序树中删除关键字为`k`的节点。
在`Delete`函数中,首先判断当前节点`ptr`是否为空。如果为空,表示未找到关键字为`k`的节点,直接返回。如果不为空,则判断`k`与当前节点关键字的大小关系,如果`k`小于当前节点关键字,则递归调用`Delete`函数在左子树中删除关键字为`k`的节点。如果`k`大于当前节点关键字,则递归调用`Delete`函数在右子树中删除关键字为`k`的节点。如果`k`等于当前节点关键字,则根据不同情况进行节点的删除操作。
如果当前节点有左子树和右子树,则将其左子树中最大的关键字替换为当前节点的关键字,并递归调用`Delete`函数在左子树中删除该节点。如果当前节点只有左子树或者只有右子树,则修改父节点的指针指向当前节点的左子树或右子树,并删除当前节点。如果当前节点没有子节点,则直接删除当前节点。
注:使用了引用指针`BiNode*&`来传递节点指针,确保对指针的修改能够在递归中生效。

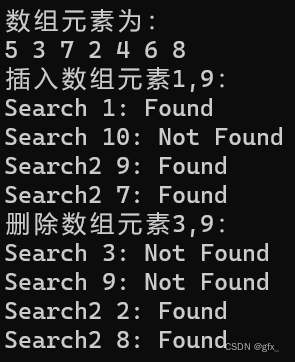
运行结果:
五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1. 怎么理解二叉排序树
若它的左子树不空,则左子树上所有结点的值均小于它根结点的值。
若它的右子树不空,则右子树上所有结点的值均大于它根结点的值。
它的左、右树又分为二叉排序树。
显然,二叉排序树与二叉树一样,也是通过递归的形式定义的。因此,它的操作也都是基于递归的方式。
性质:二叉排序树中序遍历:按顺序从小到大
2. 递归与非递归两种查找方式的区别:
差异在于实现方式上的不同。递归方式更为简洁,但在处理较大的二叉排序树时可能会因为函数调用的层级过深而导致栈溢出。
非递归方式则避免了函数调用的开销,更为节省内存,但需要使用额外的指针操作来实现循环查找。选择哪种方式取决于具体的应用场景和性能需求。
3.二叉排序树的删除
(1)被删除结点为叶子结点
直接从二叉排序中删除即可,不会影响到其他结点。
(2)被删除结点D仅有一个孩子
如果只有左孩子,没有右孩子,那么只要把要删除结点D的左孩子连接到要删除结点的父亲结点,然后删除D结点;
如果只有右孩子,没有左孩子,那么只要将要删除结点D的右孩子连接到要删除结点的父亲结点,然后删除D结点。
(3)被删除结点左右孩子都在

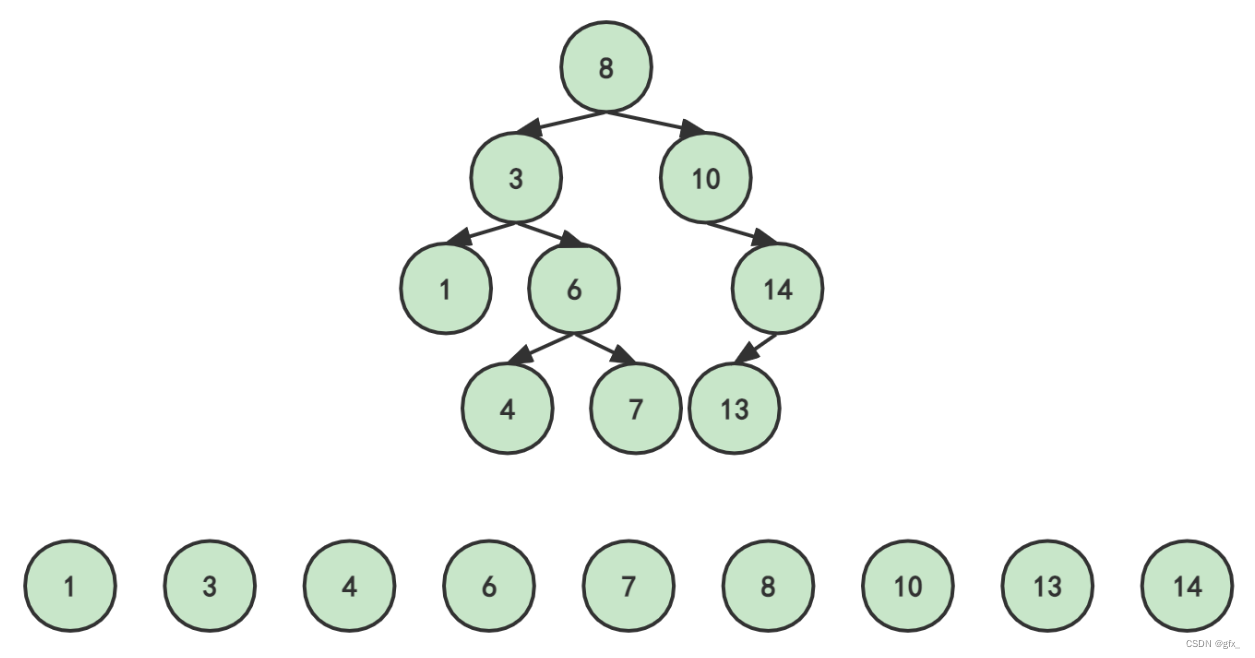
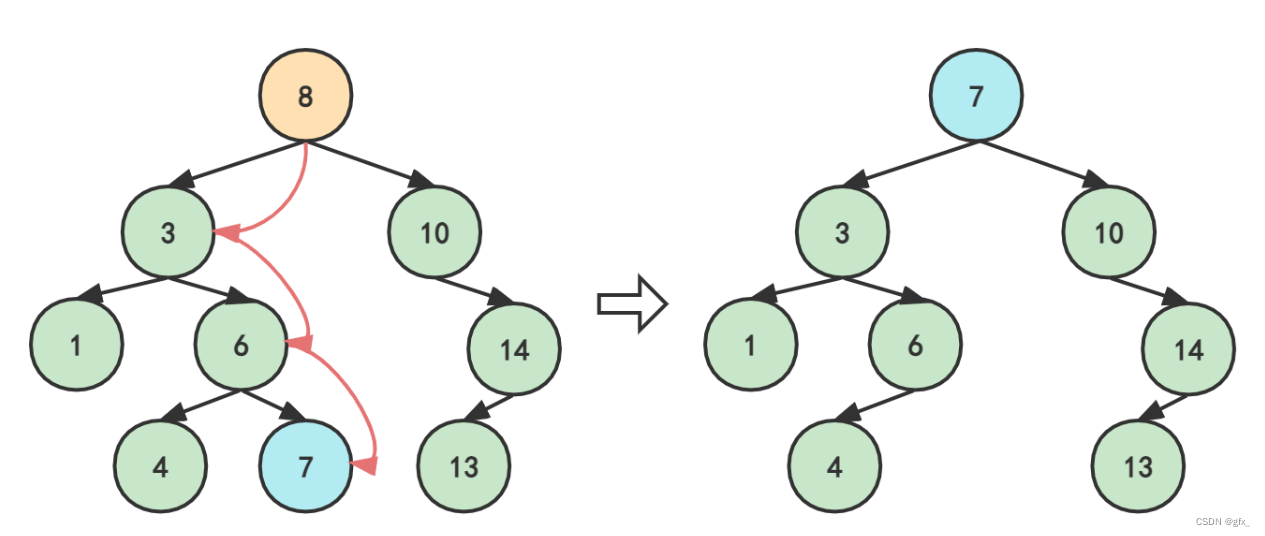
先假设删除根节点8:
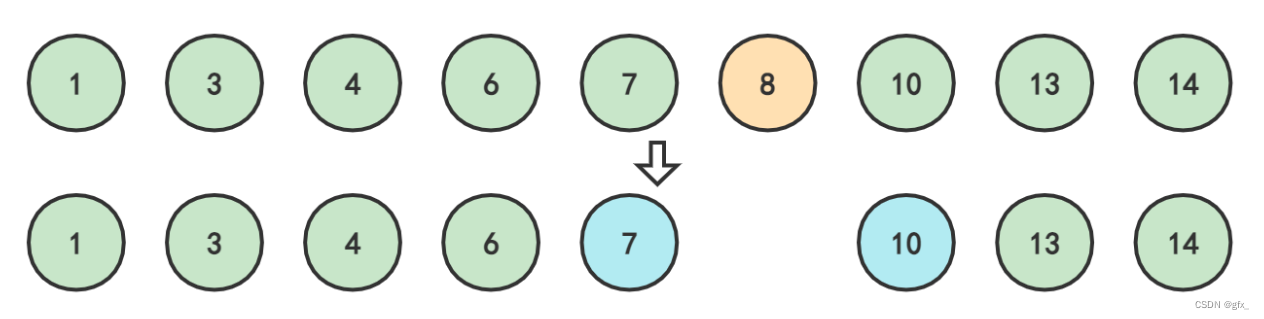
要保证删除结点8后,再次中序遍历它,仍不改变其升序的排列方式。 那么我们只有用7或者10来替换8原来的位置:
7顶替位置:
10顶替位置:

为什么是7或者10来替换8的位置?
7与10是挨着8的,如果用其他元素替换则会打扰其顺序。
那7和10怎么在二叉排序树中找到呢?
显然,7在8左子树的“最右边”,10在8右子树的“最左边”。根据二叉排序树的插入方式,比8小的元素一定在左子树,而我们又要找到比8小的最大的数,这样才能保证他们俩在顺序上是挨着的,所以它又会在8的左子树的最右边。同理也可以找到10。
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1. 理解二叉排序树
二叉排序树(Binary Search Tree,BST)是一种特殊的二叉树,其中每个节点都有一个值,并且左子树上所有节点的值小于该节点的值,右子树上所有节点的值大于该节点的值。这个特性使得BST能够实现高效的查找、插入和删除操作。
通过这种排序规则,可以保持BST的有序性,使得在BST中进行查找操作时能够按照特定顺序快速找到目标值。插入和删除操作也能够保持树的有序性,不破坏BST的特性。
二叉排序树的构建和操作都涉及到节点的比较和移动,因此在实现时需要注意平衡性的问题。如果树的结构不平衡,可能会导致操作的效率下降,甚至出现性能问题。为了解决这个问题,衍生出了平衡二叉树(如AVL树、红黑树等)来确保树的平衡性。
总的来说,二叉排序树通过简单的排序规则,能够实现快速的查找和操作,是一种常用的数据结构,被广泛应用于各种领域的算法和数据处理中。
若它的左子树不空,则左子树上所有结点的值均小于它根结点的值。
若它的右子树不空,则右子树上所有结点的值均大于它根结点的值。
它的左、右树又分为二叉排序树。
操作基于递归的方式。
性质:二叉排序树中序遍历:按顺序从小到大
2. 二叉排序树删除操作
(1)被删除结点为叶子结点
直接从二叉排序中删除即可,不会影响到其他结点。
(2)被删除结点D仅有一个孩子
只有左孩子,没有右孩子,把要删除结点D的左孩子连接到要删除结点的父亲结点,然后删除D结点;
只有右孩子,没有左孩子,将要删除结点D的右孩子连接到要删除结点的父亲结点,然后删除D结点。
(3)被删除结点左右孩子都在
找到左子树的“最右边”的结点/右子树的“最左边”的结点替换删除结点的位置。
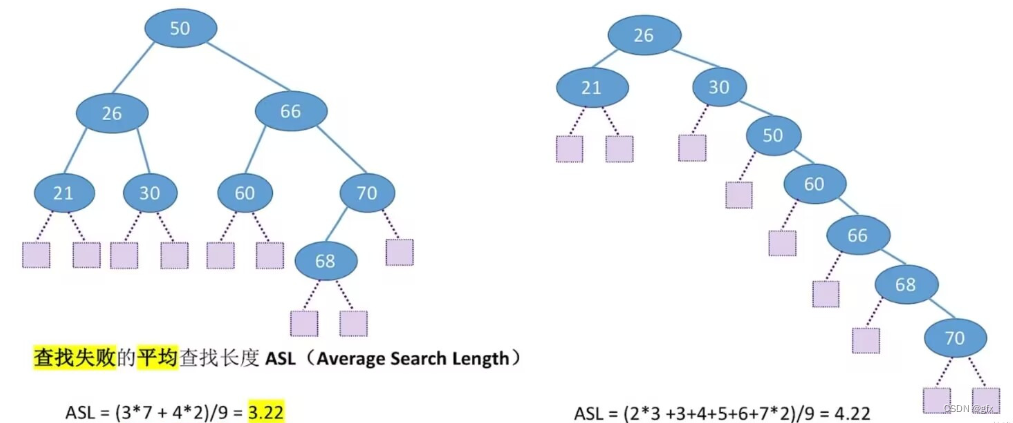
3.查找时间效率分析
在查找运算中,需要对比关键字的次数称为查找长度,反映查找操作时间复杂度
查找成功的平均查找长度
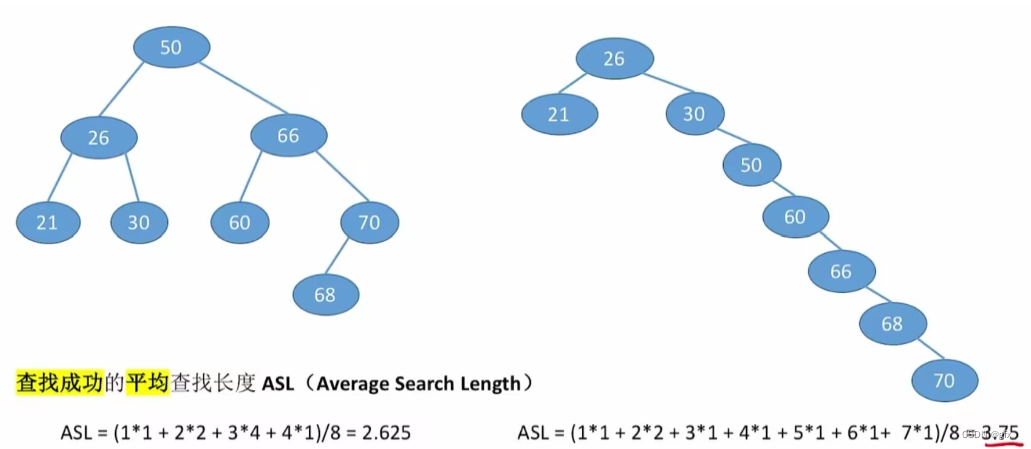
查找失败的平均查找长度
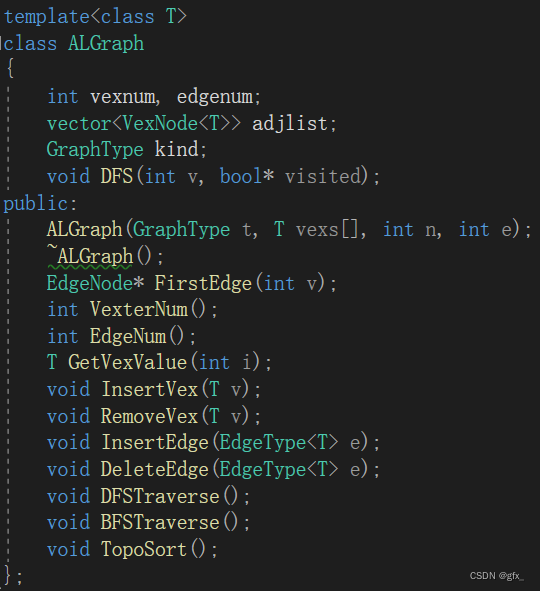
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
编写程序,建立教材P171所示的图的邻接表结构,并基于该结构实现:
构造函数;
图的遍历;
拓扑排序算法;
及其他相关函数。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.构造函数与图的遍历:
(1)构造函数注意:
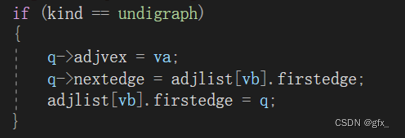
这个操作实际上是为了保证无向图中每条边的两个顶点的邻接表都要有相应的记录。因为无向图中的边是双向的,所以在处理每条边时,都需要将边的两端分别加入到对方的邻接表中。
当处理一条从`va`到`vb`的无向边时,会先在起始顶点`va`的邻接表中添加一个指向结束顶点`vb`的边`p`。同时,为了确保结束顶点`vb`的邻接表中也有指向起始顶点`va`的边,还需要新建一个指向起始顶点`va`的边`q`,将它插入到结束顶点`vb`的邻接表中。
这样,就实现了无向图中每条边的两个顶点之间的连接。
(2)图的遍历:

2.拓扑排序算法:
创建数组 indegree,用于记录每个顶点的入度,初始化所有顶点的入度为0。
遍历图中的每个顶点,更新每个顶点的入度。对于每个顶点,遍历它的所有邻接顶点,将邻接顶点的入度加1。
创建一个队列 s,用于存储入度为0的顶点。
遍历图中的每个顶点,如果顶点的入度为0,则将其加入到队列 s 中。
创建一个计数器 c,用于记录已输出的顶点个数。
当队列 s 不为空时,执行以下操作:
(1)从队列 s 中取出一个顶点 i。
(2)输出顶点 i 的数据。
(3)将计数器 c 加1。
(4)遍历顶点 i 的所有邻接顶点,将它们的入度减1。如果邻接顶点的入度变为0,则将其加入到队列 s 中。
如果计数器 c 小于图中的顶点个数 vexnum,则说明图中存在环。
这段代码通过计算图中每个顶点的入度,并使用队列 s 存储入度为0的顶点,来实现了拓扑排序的过程。在排序过程中,首先输出入度为0的顶点,然后更新邻接顶点的入度,直到所有顶点都被输出。如果存在环,则无法完成拓扑排序。
运行结果:

3.其他函数实现

五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1. AOV网的特点
(1)若是从i到j有一条有向路径,则i是j的前驱,j是i的后继
(2)若<i,j> 是网中有向边,则i是j的直接前驱,j是i的直接后继
(3)AOV网中不允许有回路,因为如果有回路存在,则表明某项活动以自己为先决条件,显然不可能
2.拓扑排序:
在AOV网没有回路的前提下,我们将全部活动排列成一个线性序列,使得AOV网中有弧<i,j>存在 则在这个序列中,i一定排在j的前面具有这种线性序列称为拓扑有序序列,相应的拓扑有序排序的算法称为拓扑排序。
3.拓扑排序过程:
(1)找一个入度为零的端点,如果有多个,则从编号小的开始找;
(2)将该端点的编号输出;
(3)将该端点删除,同时将所有由该点出发的有向边删除;
(4)循环进行 2 和 3 ,直到图中的图中所有点的入度都为零;
(5)拓扑排序结束;
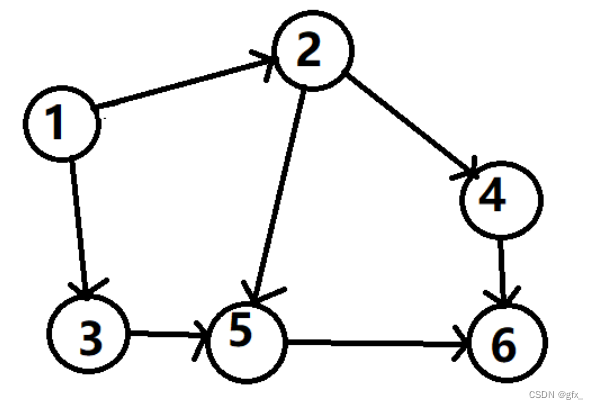
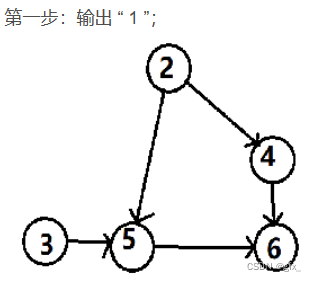
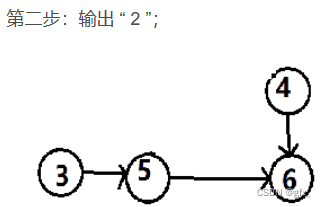
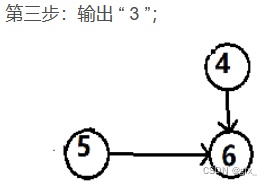
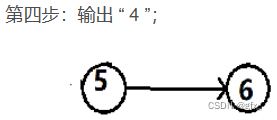

最后,输出 “ 6 ”,排序结束。
所以,最终拓扑排序的结果是1 2 3 4 5 6
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1.拓扑排序要点:
(1)有向无环图;
(2)序列里的每一个点只能出现一次;
(3)任何一对u和v,u总在v之前(这里的两个字母分别表示的是一条线段的两个端点,u表示起点,v表示终点);
2.拓扑排序过程:
使用队列 s 存储入度为0的顶点,来实现了拓扑排序的过程。在排序过程中,首先输出入度为0的顶点,然后更新邻接顶点的入度,直到所有顶点都被输出。如果存在环,则无法完成拓扑排序。
(1)找一个入度为零的端点,如果有多个,则从编号小的开始找;
(2)将该端点的编号输出;
(3)将该端点删除,同时将所有由该点出发的有向边删除;
(4)循环进行 2 和 3 ,直到图中的图中所有点的入度都为零;
(5)拓扑排序结束;
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
编写程序,建立教材P167所示的图的邻接矩阵结构,并基于该结构实现:
构造函数;
图的遍历;
最小生成树Prim和Kruskal算法;
最短路径Dijkstra和 Floyd 算法;
及其他相关函数。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.构造函数与图的遍历
(1)构造函数
初始化时:
无向图:
![]()
有向图:
![]()
(2)图的遍历
DFS
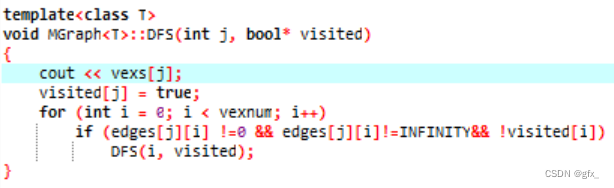
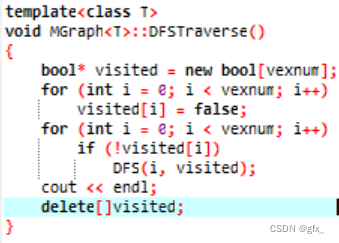
BFS
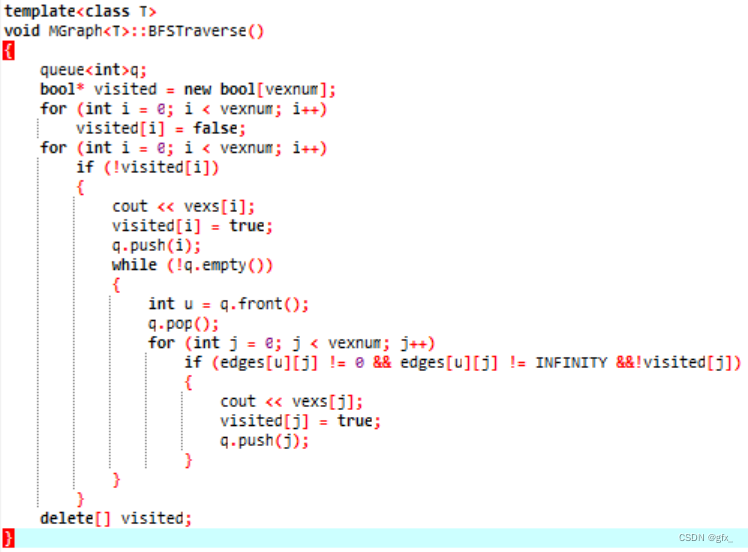
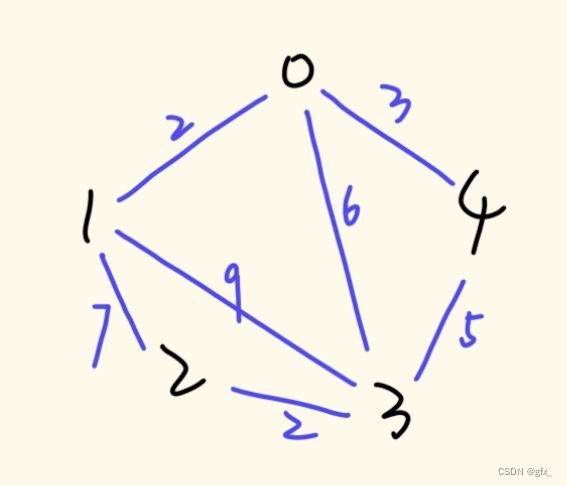

2. 最小生成树Prim和Kruskal算法
(1) Prim算法求最小生成树:初始时任取一结点,在已经过的顶点所连接的边中,选定权值最小的边,且满足连接后不能成环。
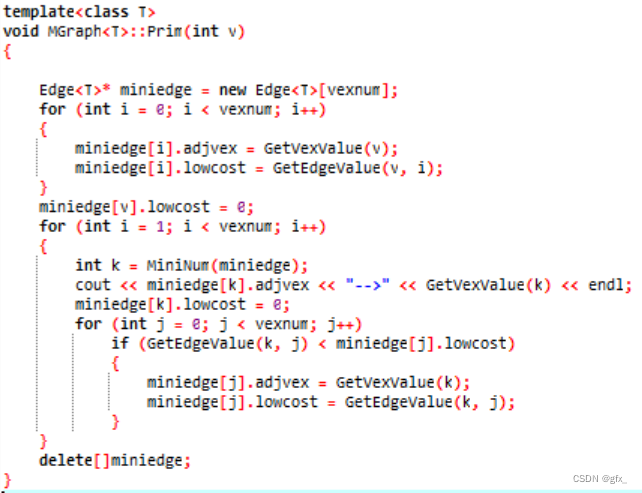
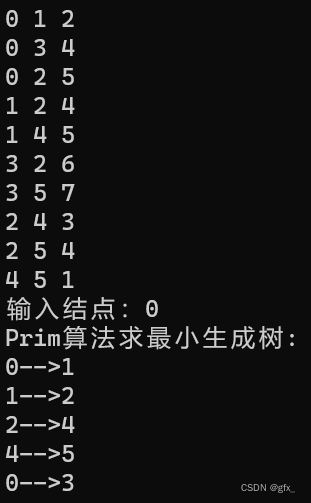
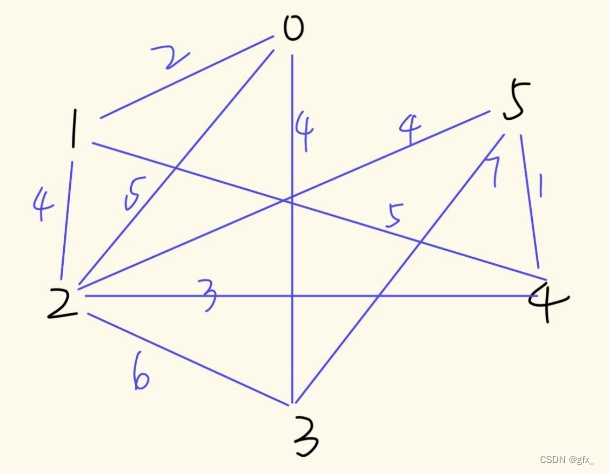
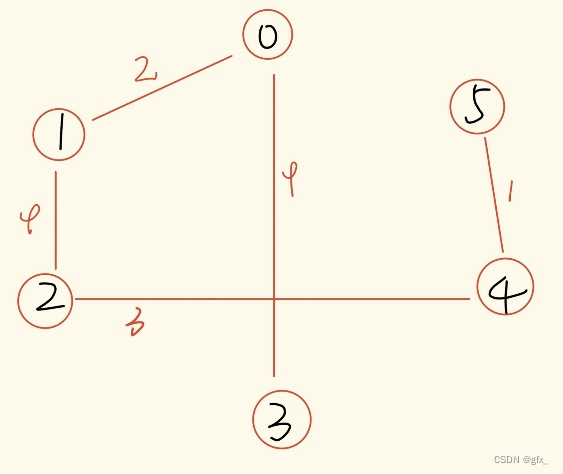
(2)Kruskal算法求最小生成树:找图中最小的边,且满足选定的边不能成环。

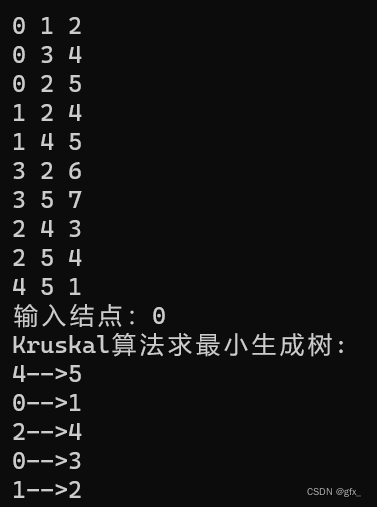
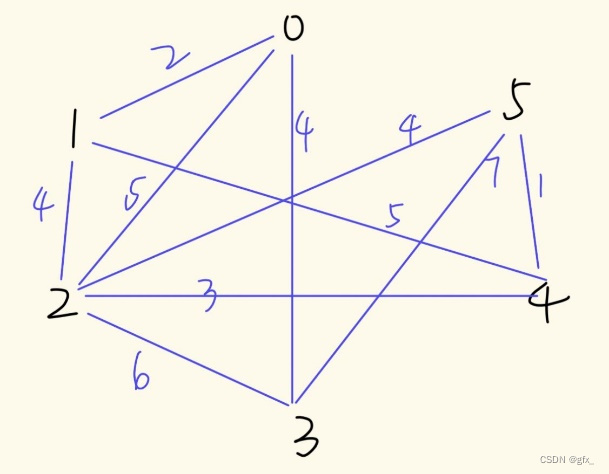
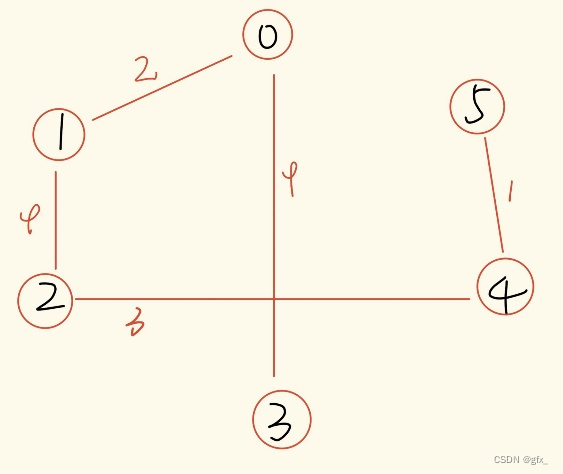
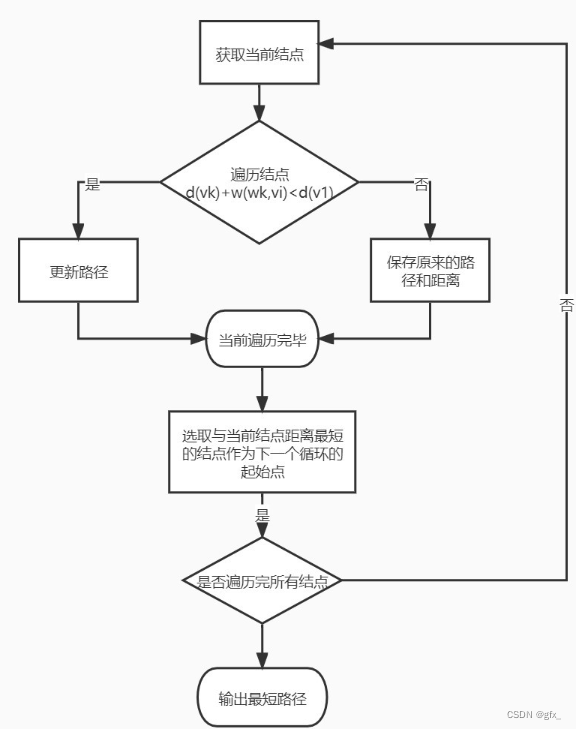
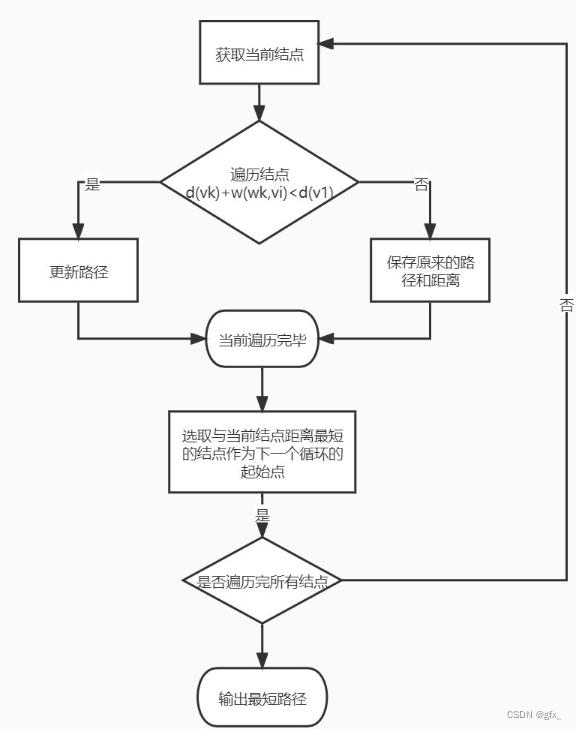
3. Dijkstra算法
用到的函数:

流程图:
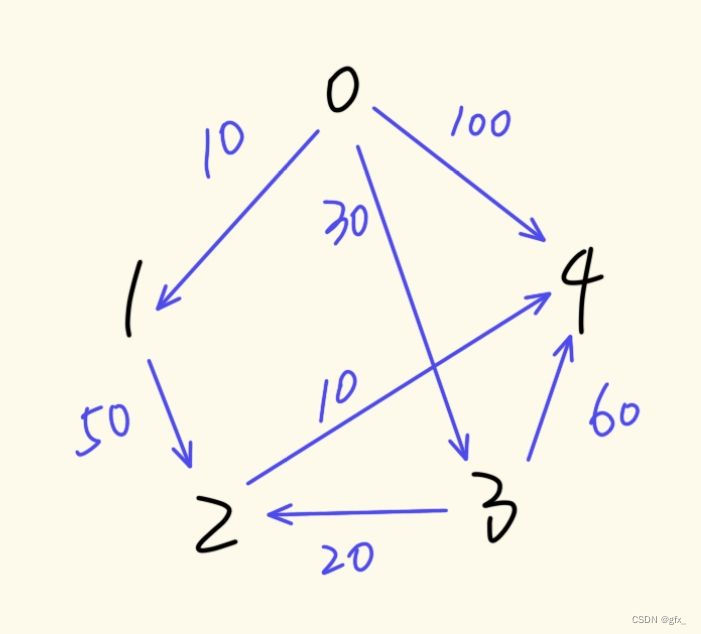
例:输入:va vb weight
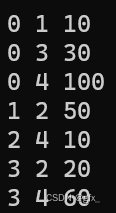
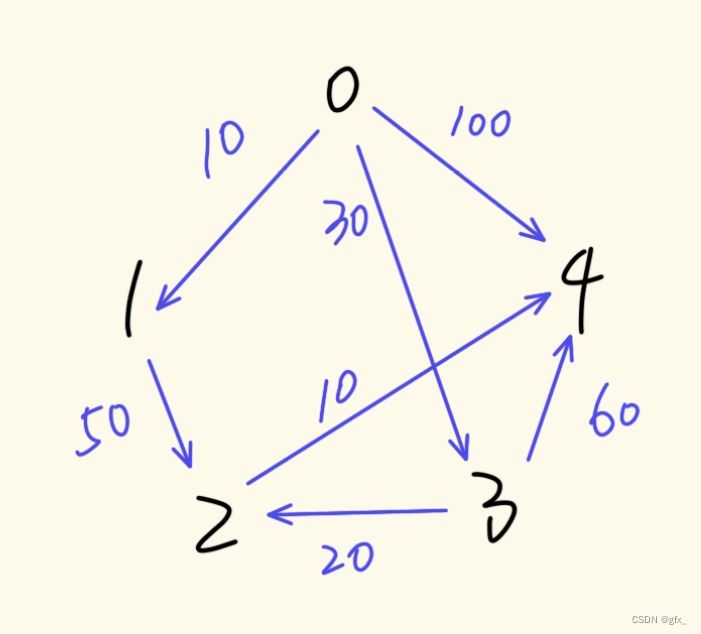

v为设定的源点,即求源点v到各点的最短路径。Path[vi]表示v到vi的最短路径,dist[vi]表示v到vi最短路径的长度。
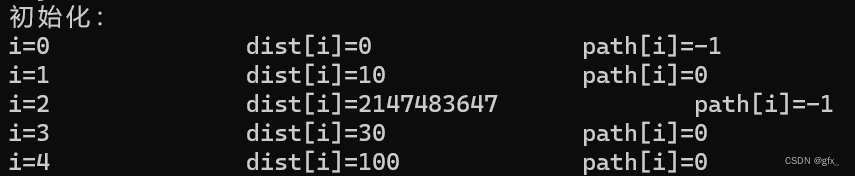
(1)初始化:若<v,vi>存在,则存放到path[vi]中,对应权值放到dist[vi]中。

(2)比较过程:从未解顶点中选择一个dist值最小的顶点,则当前path[v]和dist[v]就是顶点v的最终解。
由于可能存在更近的路径,于是将当前点w的dist[w]与相邻点k(即GetEdgeValue(k,w)!=INFINITY)的dist[k]+GetEdgeValue(k,w)进行比较,修改路径及其对应长度的值。


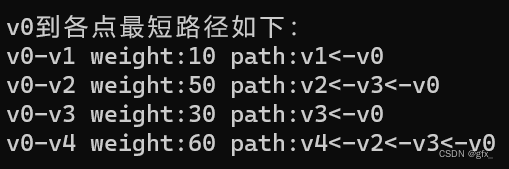
(3)输出路径:每条路径直到path=-1到头。

4. Floyd 算法
使用二维表格,D表格对角线元素记为0(自己到自己的距离为0),path表格若距离为无穷大则记为-1。
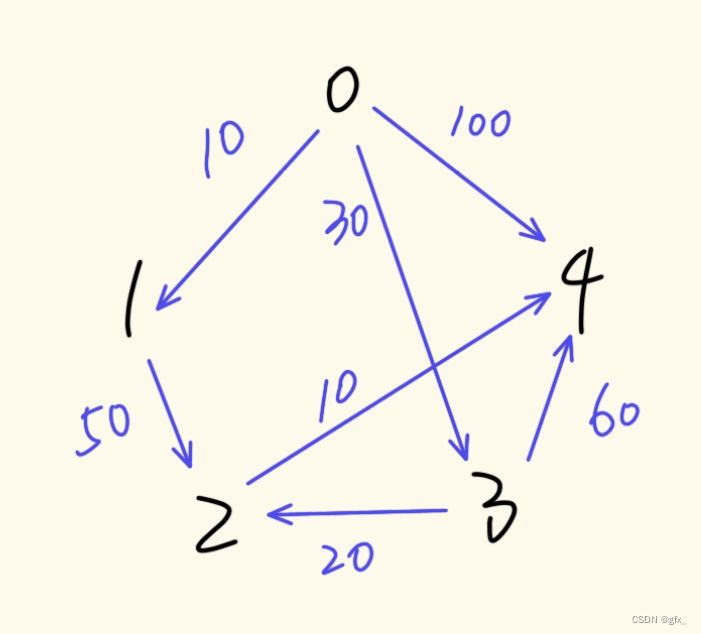
对角线数据标绿色,不变。粉色为比较基准,继承上一表格中的数据。蓝色为比较后更新的数据,D中数据根据粉色十字进行更新,path中更新数据根据粉色竖列。


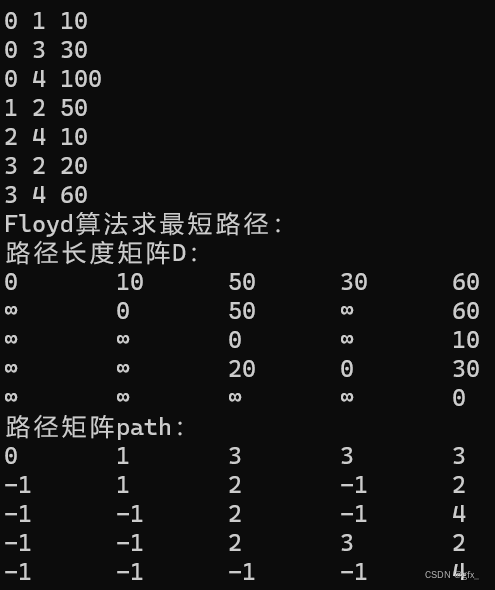
运行结果:
五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1.Dijkstra算法
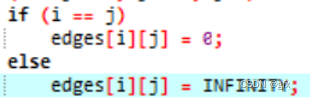
(1)在取距离最近的点时,要设INFINITY为足够大的数。
![]()
(2)当前点为w,则要找相邻点k做比较。
![]()
(3)对源点的初始化,path=-1,dist=0,s=true

六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1.构造函数
初始化时:
无向图:
![]()
有向图:
![]()
2. (1)Prim算法
选择一个起始节点作为最小生成树的起点。
将该起始节点加入最小生成树集合,并将其标记为已访问。
在所有与最小生成树集合相邻的边中,选择权重最小的边和它连接的未访问节点。
将该边和节点加入最小生成树集合,并将该节点标记为已访问。
重复步骤3和步骤4,直到最小生成树集合包含了图中的所有节点。
(2) Kruskal算法
首先先定义一个结构存储所有的边,然后再按权值从小到大的排序,从头开始遍历,每一次取出来的边都是权值最小的一条边。每次先判断取出的边的两点是否已经在一个集合中了,不在一个集合中就合并,记录权值,反之就跳过本次循环。循环结束,就将所有的结点都加到了一个集合中。
3. Dijkstra算法
v为设定的源点,即求源点v到各点的最短路径。Path[vi]表示v到vi的最短路径,dist[vi]表示v到vi最短路径的长度。
(1)初始化:若<v,vi>存在,则存放到path[vi]中,对应权值放到dist[vi]中。
(2)比较过程:从未解顶点中选择一个dist值最小的顶点,则当前path[v]和dist[v]就是顶点v的最终解。
由于可能存在更近的路径,于是将当前点w的dist[w]与相邻点k(即GetEdgeValue(k,w)!=INFINITY)的dist[k]+GetEdgeValue(k,w)进行比较,修改路径及其对应长度的值。
(3)输出路径:每条路径直到path=-1到头。
4. Floyd 算法
使用二维表格,D表格对角线元素记为0(自己到自己的距离为0),path表格若距离为无穷大则记为-1。
对角线数据标绿色,不变。粉色为比较基准,继承上一表格中的数据。蓝色为比较后更新的数据,D中数据根据粉色十字进行更新,path中更新数据根据粉色竖列。

一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
编写程序,实现教材P129线索二叉树类及若干应用算法。
(1)创建二叉树
(2)求中序遍历中的后继,前驱结点
(3)利用线索进行中序遍历
(4)求父结点地址
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
(1) 线索二叉树的结点结构
(2) 根据先序序列创建线索二叉树
(3) 中序线索遍历二叉树
(4) 求中序遍历中的后继结点
(5) 求中序遍历中的前驱结点
(6) 查找结点中的父结点

四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
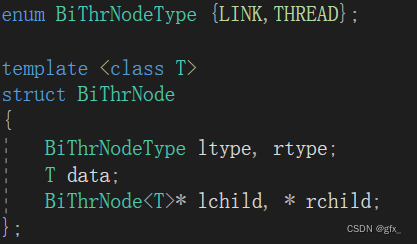
1.线索二叉树的结点结构:
| ltype | lchild | data | rchild | rtype |
其中标记域ltype与rtype只能取两种值,用LINK(0)与THREAD(1)表示。
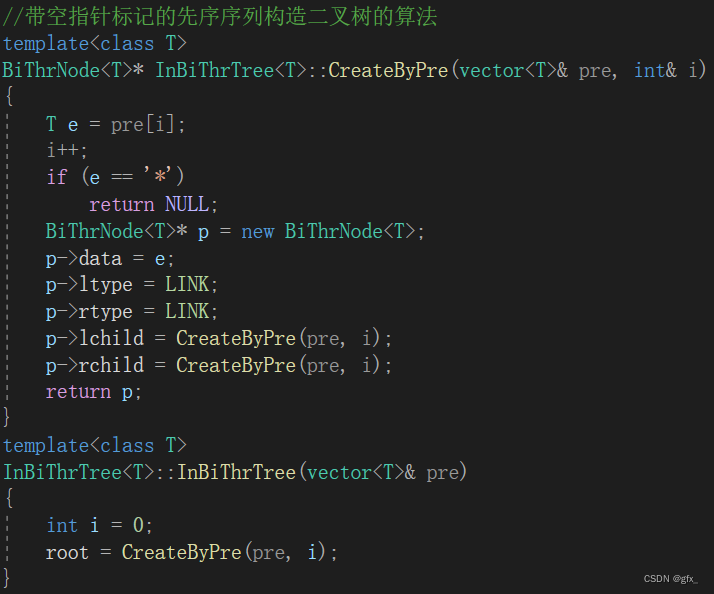
2. 根据先序序列创建线索二叉树:
与二叉树的构造函数类似,但是不同的是,需要在p->data=e后面加上p->ltype=LINK与p->rtype=LINK即可,因为多了两个标记域。
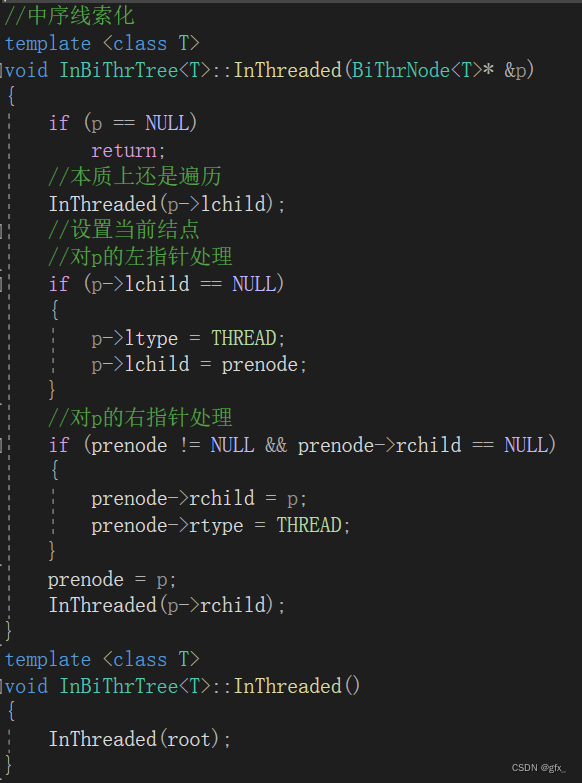
3. 中序线索遍历二叉树:
对当前节点p的左子树进行线索化,通过递归调用InThreaded(p->lchild)实现。然后,对当前节点p进行线索化。
线索化的过程分为两部分。首先判断p的左子树是否为空,如果为空,则将p的左标志ltype设置为线索,左指针lchild指向前驱节点prenode。
判断前驱节点prenode是否存在并且其右子树为空,如果满足条件,则将前驱节点prenode的右指针rchild指向当前节点p,并将其右标志rtype设置为线索。
更新前驱节点prenode为当前节点p。
完成对当前节点p的线索化后,继续对其右子树进行线索化,通过递归调用InThreaded(p->rchild)实现。
通过中序线索化,二叉树中的空指针将被利用起来,指向其在中序遍历下的前驱或后继节点,从而实现了在不使用递归或栈的情况下,直接访问二叉树的前驱或后继节点的功能。
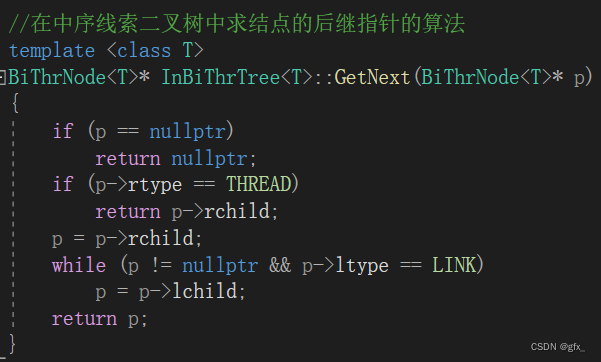
4. 求中序遍历中的后继结点
要考虑到指针p==nullptr的情况。
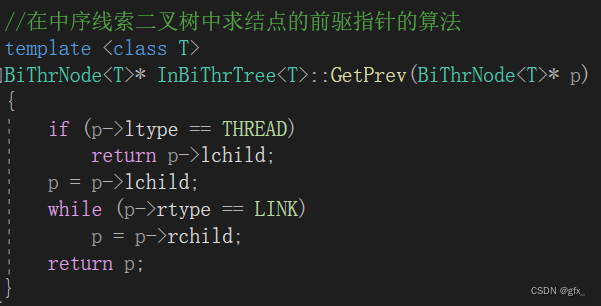
5. 求中序遍历中的前驱结点
6. 查找结点中的父结点

运行结果:


五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1. 线索二叉树结点的右孩子线索指的是后继,左孩子线索指的是前驱。
2. 在中序线索二叉树中求结点的后继指针的算法要考虑到指针p==nullptr的情况。
3.析构函数:
确保处理节点的顺序正确。由于在线索二叉树中,前驱线索指向的是节点在中序遍历中的前一个节点,因此在析构的过程中,需要先找到最左子节点,然后按照中序遍历的顺序依次删除节点。
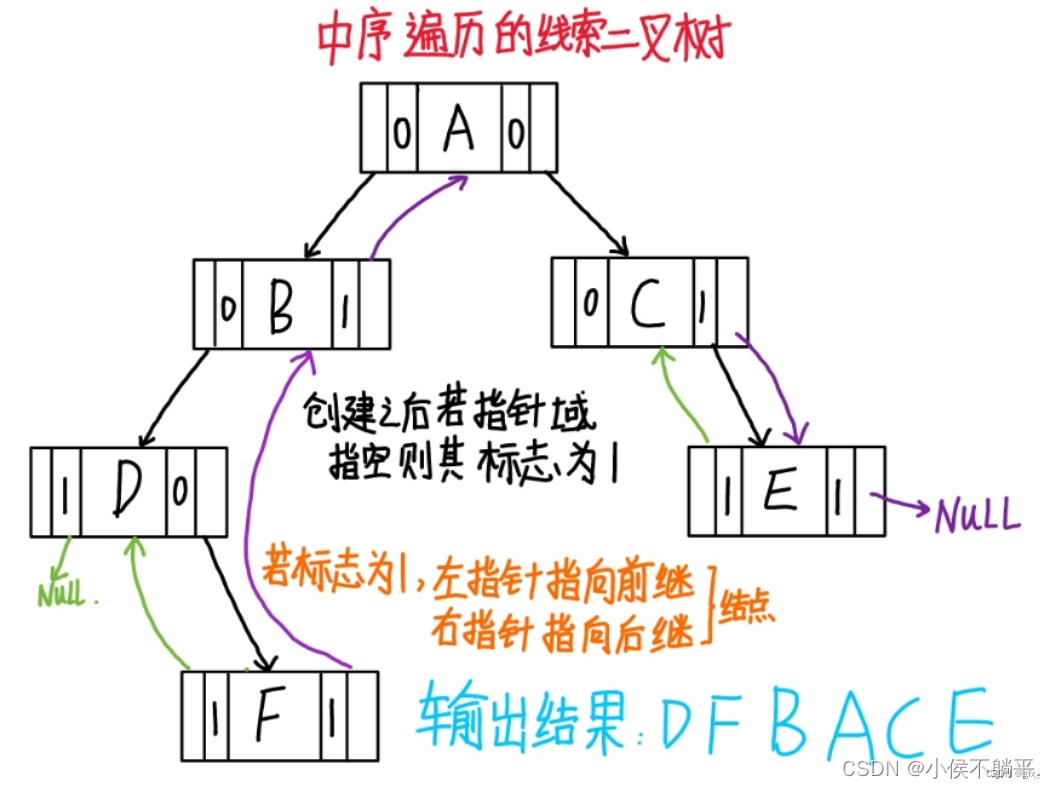
4.为什么要用线索二叉树?
对于一个有n个节点的二叉链表,每个节点有指向左右节点的2个指针域,整个二叉链表存在2n个指针域。而n个节点的二叉链表有n-1条分支线,那么空指针域的个数=2n-(n-1) = n+1个空指针域,从存储空间的角度来看,这n+1个空指针域浪费了内存资源。
如果我们想知道按中序方式遍历二叉链表时B节点的前驱节点或者后继节点时,必须要按中序方式遍历二叉链表才能够知道结果,每次需要结果时都需要进行一次遍历,需要考虑提前存储这种前驱和后继的关系来提高时间效率。
综合以上两方面的分析,可以通过充分利用二叉链表中的空指针域,存放节点在某种遍历方式下的前驱和后继节点的指针。我们把这种指向前驱和后继的指针成为线索,加上线索的二叉链表成为线索链表,对应的二叉树就成为“线索二叉树(Threaded Binary Tree)”。
线索化的实质就是将二叉链表中的空指针改为指向前驱节点或后继节点的线索;
线索化的过程就是修改二叉链表中空指针的过程,可以按照前序、中序、后序的方式进行遍历,分别生成不同的线索二叉树;
有了线索二叉树之后,我们再次遍历时,就相当于操作一个双向链表。
使用场景:如果我们在使用二叉树过程中经常需要遍历二叉树或者查找节点的前驱节点和后继节点,可以考虑采用线索二叉树存储结构。
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
二叉树是一种非线性结构,遍历二叉树几乎都是通过递归或者用栈辅助实现非递归的遍历。用二叉树作为存储结构时,取到一个节点,只能获取节点的左孩子和右孩子,不能直接得到节点的任一遍历序列的前驱或者后继。
为了保存这种在遍历中需要的信息,我们利用二叉树中指向左右子树的空指针来存放节点的前驱和后继信息。
n个节点的二叉树中含有n+1个空指针域。利用二叉树中的空指针域来存放在某种遍历次序下的前驱和后继 ,这种指针叫“线索”。这种加上了线索的二叉树称为线索二叉树。
如果所用的二叉树经常要遍历或查找结点时需要某种遍历序列中的前驱后继,那么采用线索二叉链表的存储结构就是非常不错的选择。
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
必做题:实现稀疏矩阵转置的朴素方法和快速方法。
选做题:实现稀疏矩阵的加法和乘法。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
定义两个模板类:Triple和SparseMatrix。
Triple类表示矩阵中的一个元素,包含三个成员:r表示行号,c表示列号,elem表示元素的值。
SparseMatrix类表示稀疏矩阵,使用Triple来存储非零元素。有以下成员函数:
构造函数SparseMatrix(): 创建一个空的稀疏矩阵。
构造函数SparseMatrix(Triple<T> *tlist,int rs,int cs,int n): 使用指定的Triple数组tlist、行数rs、列数cs和元素个数n创建稀疏矩阵。
void trans1(SparseMatrix& B): 实现稀疏矩阵转置的朴素方法。
void trans2(SparseMatrix& B): 实现稀疏矩阵转置的快速方法。
SparseMatrix& plus(SparseMatrix& B): 将当前矩阵与矩阵B相加,并返回结果。
SparseMatrix& mult(SparseMatrix& B): 将当前矩阵与矩阵B相乘,并返回结果。
void print(): 打印当前矩阵。

四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.矩阵构造:
Triple<T>* tlist:一个三元组的数组,其中每个元素表示矩阵中的一个非零元素。
int rs, int cs, int n:此矩阵的行数、列数和非零元素的数量。
分别将参数中的行数、列数和非零元素数量赋值给类成员变量 rows、cols 和 num。
triList.resize(rs*cs);重新分配三元组列表triList的大小,以便它可以存储所有可能的元素。因为在稀疏矩阵中,大多数元素都是零,因此将所有可能的元素存储在矩阵中不是最优的做法。更好的方法是仅存储非零元素。
triList存储矩阵的所有非零元素。

运行结果:

2.朴素转置:

B.triList.resize(cols*rows);
重新分配B的三元组列表triList的大小,以便它可以存储转置后的矩阵的所有可能元素。
如果是空矩阵,则直接返回,因为转置后的矩阵仍然是空矩阵。
循环遍历当前矩阵的每列,并查找对应列的非零元素。对于每个找到的非零元素,将其行号、列号和元素值分别赋值给 B 的三元组列表中的相应位置,并递增计数器q。这样,B 的三元组列表 triList就存储了当前矩阵转置后的所有非零元素。
最终,B被更新为当前矩阵的转置。
运行结果:

3.快速转置:
B.triList.resize(cols*rows);
重新分配B的三元组列表triList的大小,以便它可以存储转置后的矩阵的所有可能元素。
如果是空矩阵,则直接返回,因为转置后的矩阵仍然是空矩阵。
声明两个 int 类型数组 cnum 和 cpot,分别用于存储转置后每列的非零元素数量和每列在转置后的三元组列表 B.triList 中起始位置的下标。初始化时将 cnum 数组中的所有元素赋值为 0。
循环遍历当前矩阵中的所有非零元素,统计每列中的非零元素数量。
计算每列在转置后的三元组列表 B.triList 中起始位置的下标:第一列的起始位置下标为0,后续列的起始位置下标等于前一列的起始位置下标加上前一列中的非零元素数量。
这段代码将当前矩阵中的非零元素转置存储到三元组列表 B.triList 中。对于每个非零元素 (行号、列号、元素值),其转置后的元素应该是 (列号、行号、元素值)。从 triList 中取出三元组,计算它在转置后的三元组列表 B.triList 中的位置下标 q,然后将该三元组转置并转存到 B.triList 中。之后将 cpot 数组中对应列的起始位置下标 cpot[col] 加一,以便下一个该列的三元组存储到 B.triList 中。
最后释放动态分配的内存,避免内存泄漏。

运行结果:

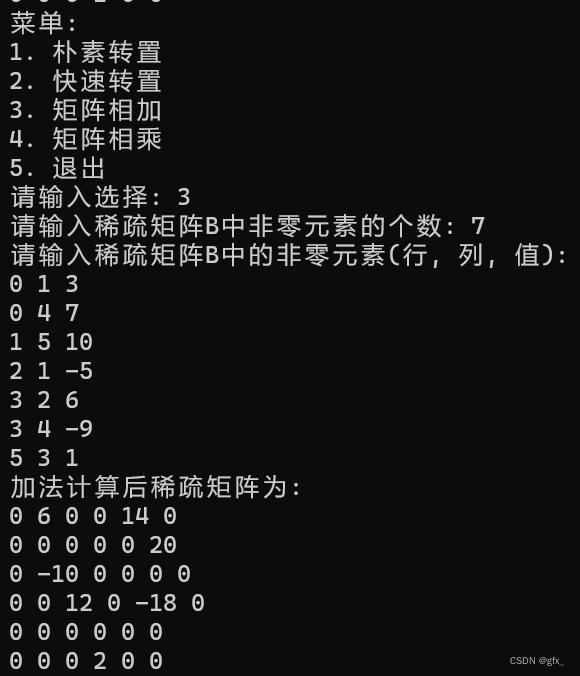
4.矩阵相加:
创建一个新的稀疏矩阵 C,用于存储两个矩阵相加的结果。接下来,将当前矩阵(调用函数的对象)的行数和列数赋值给新矩阵 C,同时分配足够的空间来存储结果。
接下来是一个 while 循环,循环条件是两个矩阵都还有元素未处理。在循环中,根据当前元素的行和列进行比较,确定哪个元素应该放入结果矩阵 C。如果当前矩阵的行小于另一个矩阵的行,则将当前元素放入 C,否则将另一个矩阵的元素放入 C。如果两个元素的行相等,则根据列的比较来确定应该放入哪个元素,或是将它们的元素相加并放入 C。
循环结束后,如果当前矩阵还有剩余元素未处理,则将它们一一复制到结果矩阵 C 中。同样地,如果另一个矩阵 B 还有剩余元素未处理,则将它们复制到结果矩阵 C 中。
最后,将结果矩阵 C 中的元素数量更新为实际存储的元素个数,并将结果赋值给调用函数的对象(当前矩阵),返回当前矩阵的引用。
运行结果:
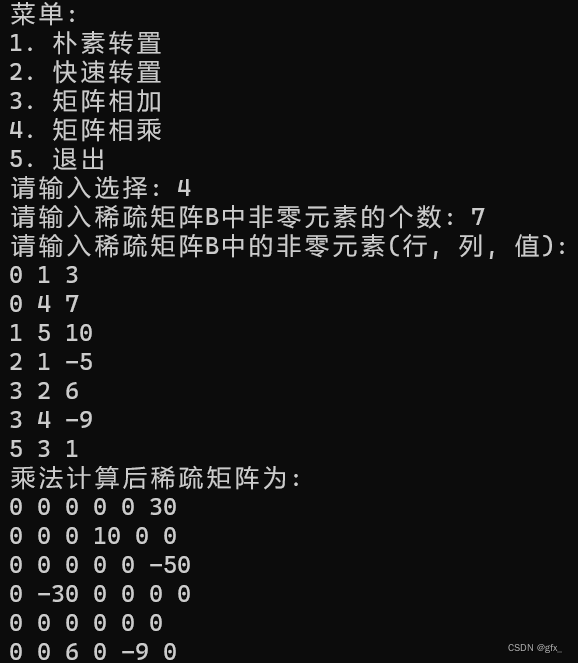
5.矩阵相乘:

创建一个新的稀疏矩阵C,用于存储两个矩阵相乘的结果。然后设置矩阵 C 的属性,包括元素数量、行数和列数,并为结果矩阵的三元组列表分配足够的空间。
接下来是两个嵌套的 for 循环。外层循环遍历当前矩阵的三元组列表,内层循环遍历矩阵 B 的三元组列表。在循环中,通过比较当前矩阵的列和 B 矩阵的行来确定是否存在可以相乘的元素。
如果存在可以相乘的元素,就创建一个新的三元组并将其添加到结果矩阵 C 的三元组列表中。新的三元组的行和列分别等于当前矩阵的行和 B 矩阵的列,元素值等于当前矩阵元素和 B 矩阵元素的乘积。
内层循环结束后,更新结果矩阵 C 的元素数量为实际存储的元素个数,然后将结果赋值给调用函数的对象(当前矩阵)。
最后,返回当前矩阵的引用。
运行结果:
五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1.压缩矩阵:
压缩矩阵通常使用三元组(Triple)来实现。三元组实质上将矩阵的每个非零元素的信息存储为一个带有行列信息和元素值的三元组。
2.朴素转置与快速转置的区别:
朴素转置主要时间耗费是在col和p的两重循环上。对于一个m行n列且非零元素个数为:的稀疏矩阵而言,该算法的时间复杂度为O(t*n)。在最坏情况下,稀疏矩阵中的非零元素个数t与m*n具有相同的数量级,上述算法的时间复杂度为0(m*n2)。朴素矩阵转置算法的效率较低。
提高效率的方法是减少对矩阵A的三元组表进行扫描的趟数。一种快速的矩阵转置算法思想是直接按矩阵A的行序进行转置,即通过一趟扫描矩阵A的三元组表,同时将每个非零元素转置后直接放入矩阵B的三元组表中的适当位置。
实现此算法的关键是每次从矩阵A的三元组表中取出一个非零元素后,确定该元素转置后在矩阵B的三元组表中的相应位置。如果能预先确定矩阵A的每一列的第一个非零元素在矩阵B的三元组表中的位置,每一列的其他非零元素则依次排在该位置的后面;那么在按行序扫描矩阵A的每一个非零元素时,就可以直接对它们在矩阵B的三元组表中进行定位了。
引入两个辅助数组:cnum[cols],每个分量表示矩阵 A 的某一列的非零元素个数;cpot[cols],每个分量的初始值表示矩阵A的某一列的第一个非零元素在B中的位置。
显然,对数组cnum的各个元素值的初始化可以通过对矩阵A的三元组表扫描一趟完成。在数组cnum初始化的基础上,对数组cpot的初始化可按如下的递推关系给出:
cpot[0]=0;
cpot[col]=cpot[col-1]+cnum[col-1] 1≤col≤cols-1
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1.压缩矩阵:
压缩矩阵通常使用三元组来实现。三元组实质上将矩阵的每个非零元素的信息存储为一个带有行列信息和元素值的三元组。
2.朴素转置与快速转置:
朴素矩阵转置算法效率较低。为了提高效率,可以采用直接按矩阵行序进行转置的方法。这种方法通过一次遍历矩阵的三元组表,将每个非零元素转置后直接放入转置后矩阵的适当位置。
关键是确定每个非零元素转置后在转置矩阵中的位置。为此,引入两个辅助数组:cnum和cpot。
cnum数组:表示矩阵A的每一列的非零元素个数。通过一次扫描矩阵的三元组表,可以初始化cnum数组。
cpot数组:表示矩阵A的每一列的第一个非零元素在转置矩阵的位置。通过递推关系进行初始化:
cpot[0] = 0
cpot[col] = cpot[col-1] + cnum[col-1],其中1≤col≤cols-1
在初始化cnum和cpot数组后,对于矩阵A的每个非零元素,在转置矩阵中直接定位其位置即可。
3.矩阵相加关键:若当前矩阵的行小于另一个矩阵的行,则将当前元素放入结果矩阵 C;若两个元素的行相等,则根据列的比较来确定应该放入哪个元素,或是将它们的元素相加后放入 C。
4.矩阵相乘关键:若存在可以相乘的元素,创建一个新的三元组,并将其添加到结果矩阵C的三元组列表中。新的三元组的行和列分别等于当前矩阵A的行和矩阵B的列,元素值等于当前矩阵A元素和矩阵B元素的乘积。
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
基本要求:
按照教材P49介绍,输入包含+、-、*、/、圆括号和正整数组成的中缀算术表达式,以'@'作为表达式结束符。计算该表达式的运算结果。
拓展要求:
1)能够对带小数的数据进行计算。
2)去掉@,使得表达式的输入符合习惯。
3)能够进行括号是否匹配等表达式合法性的判断。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
1.实现中缀表达式计算的基本功能
2.实现中缀表达式转后缀表达式并计算的功能
(1)处理小数
(2)去掉@
(3)进行括号匹配的判断
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.整数10以内(不包括10)的加减乘除等中缀算数表达式计算:
(1)字符间大小比较:
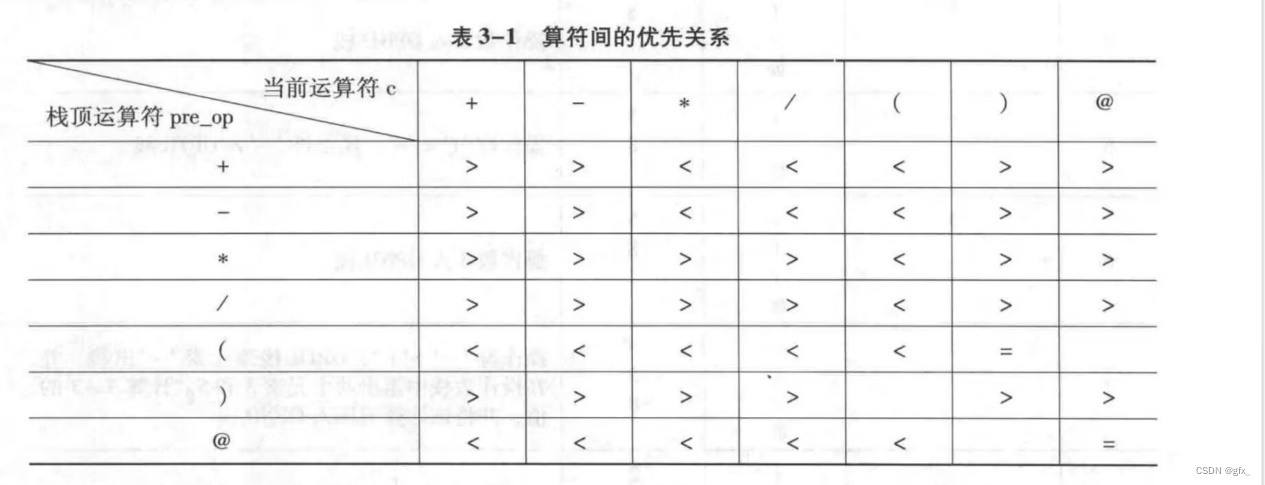 用prcd数组存储上图算符优先关系,用optrToInt函数定位数组元素,Precede函数返回两算符的优先关系。
用prcd数组存储上图算符优先关系,用optrToInt函数定位数组元素,Precede函数返回两算符的优先关系。

(2)操作函数Operate()

(3)运行结果:

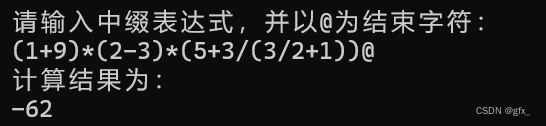

2.扩展:去掉@,使得表达式的输入符合习惯:
(1)利用bool类型的flag变量,用于控制运算循环。
检查 OPTR 栈是否为空,如果为空,则直接将当前运算符 ch 入栈,并将 flag 设置为 0,结束本次循环。
若 OPTR 栈不为空,则根据运算符的优先级比较进行如下操作:
如果栈顶运算符的优级比当前运算符低(或者相同),将当前运算符 ch 入栈,并将 flag 设置为 0,结束本次循环。
如果栈顶运算符的优先级比当前运算符高,则进行以下操作:
弹出 OPTR 栈顶运算符,并将其存储在 pre_op 变量中。
根据 pre_op 进行计算,取出 OPND 栈顶两个操作数 b 和 a,进行相应的运算。
将运算结果 x 压入 OPND 栈中。

(2)运行结果:



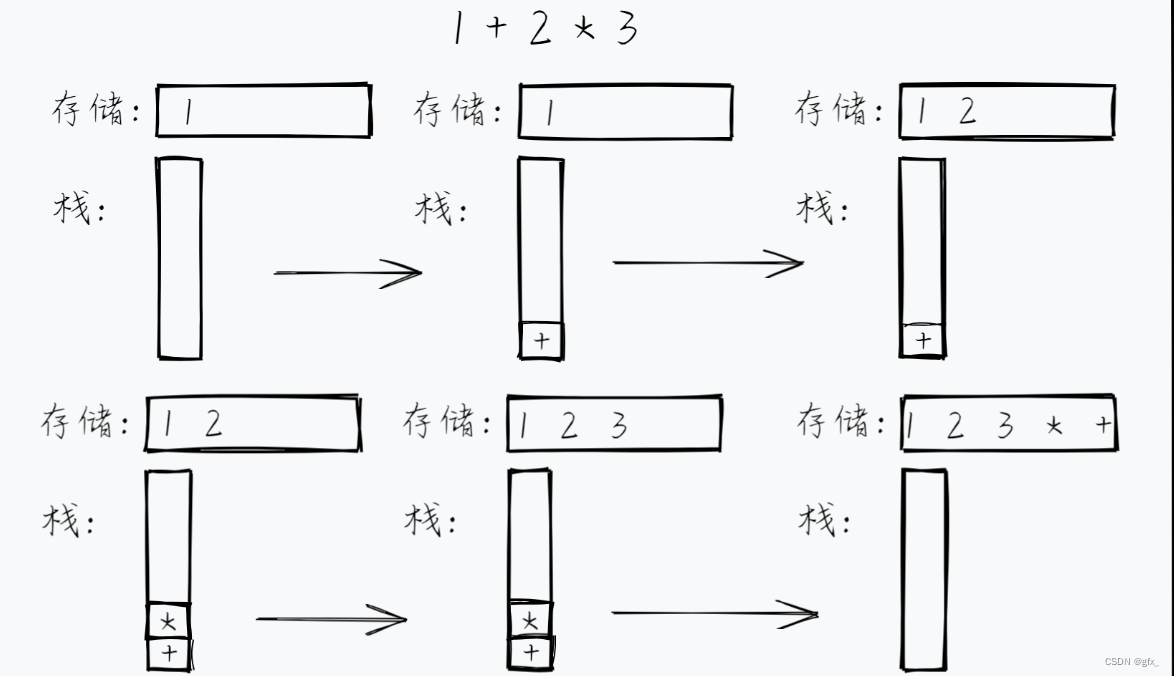
3.中缀表达式转后缀表达式,并由后缀表达式求解:
我们用一个栈来临时存储中间遇到的操作符:
(1)遇到操作数,直接存储/输出
(2)遇到操作符
(2.1)栈为空 or 该操作符的优先级比栈顶的操作符的优先级高 → 将该操作符压栈
(2.2)该操作符的优先级比栈顶的操作符优先级低 or 相同 → 弹出栈顶操作符存储,并将该操作符压栈
(3)遍历结束后将栈里的操作符依次全部弹出
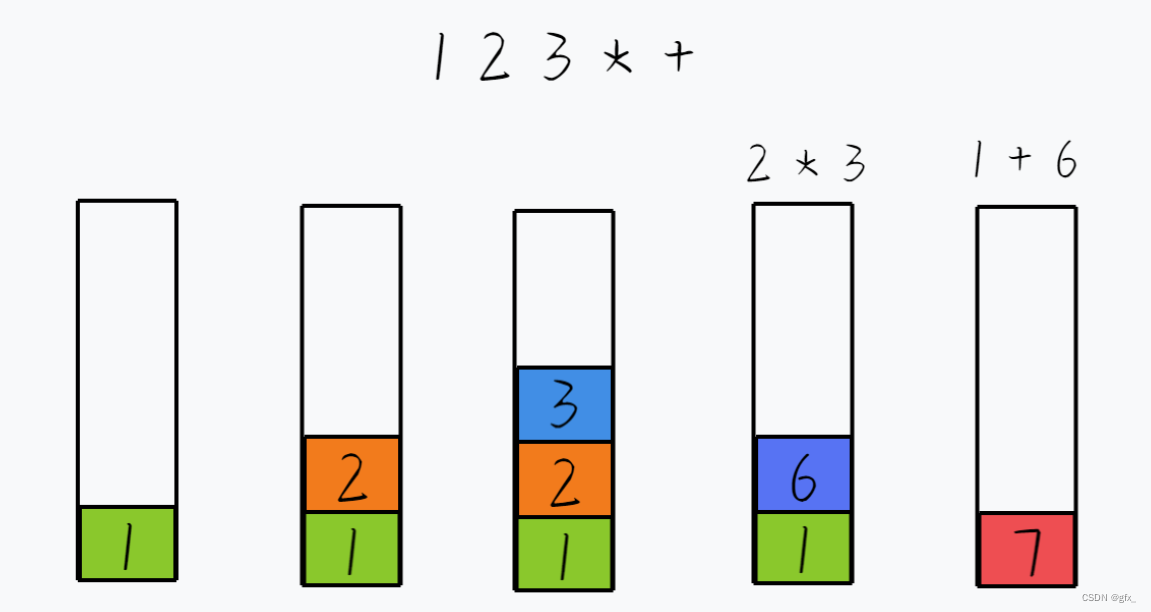
(4)求解后缀表达式:
遇到操作数 → 直接入栈
遇到操作符 → 取出栈顶的两个数据进行运算,将计算结果压栈
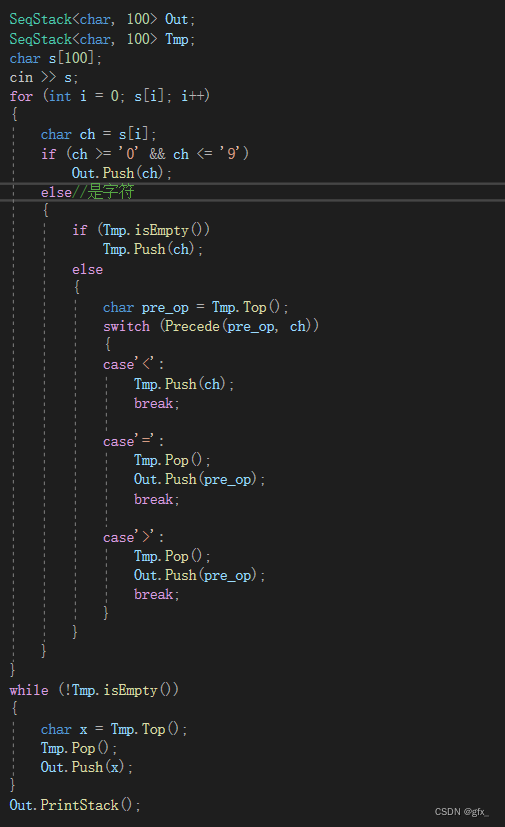

4.进阶:考虑小数、负数、括号
(1)思路:
-
- 输入的中缀表达式括号是否匹配
(1.1.1)扫描到左括号,入栈
(1.1.2)扫描到右括号,栈为空 ->匹配失败
(1.1.3)栈不为空,栈顶元素出栈,与当前字符比较,若当前字符为‘)’而栈顶元素不为‘(’ ->匹配失败
(1.1.4)扫描整个中缀表达式后,若栈空 ->匹配成功
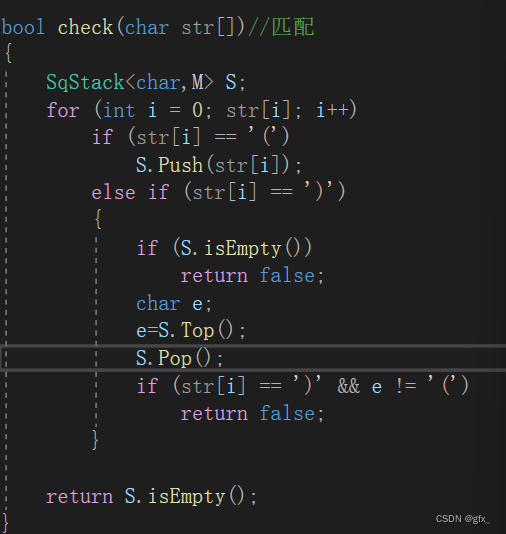
-
- 中缀表达式转后缀表达式
(1.2.1)初始化一个空栈
(1.2.2)负数判断:
->表达式首位‘-’
->括号前的‘-’

(1.2.3)小数处理:遇到数字和小数点直接输出,一个数字完整输出后使用空格与其它运算符或数字分隔开

(1.2.4)遇到左括号直接入栈

(1.2.5)遇到右括号直接出栈,直到左括号出栈(左括号不输出)

(1.2.6)遇到‘+’或‘-’:
->栈空/栈顶为左括号:直接入栈
->否则一直出栈,直到栈空/栈顶为左括号,再入栈

(1.2.6)遇到‘*’或‘/’:
->栈空/栈顶为左括号/栈顶操作符为+ or -:直接入栈
->否则一直出栈,直到栈空/栈顶为左括号/栈顶操作符为+or-,再入栈
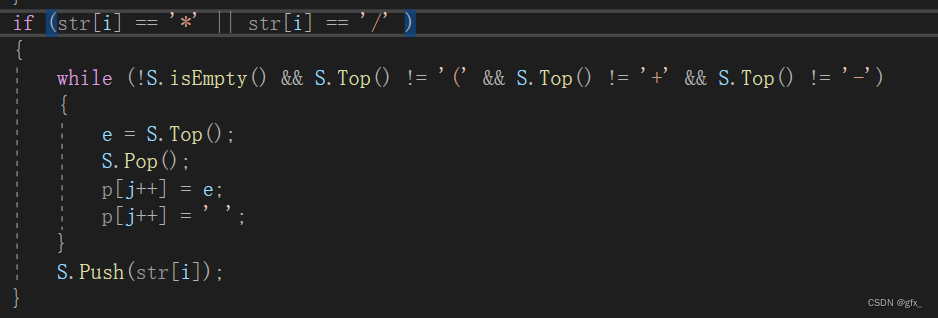
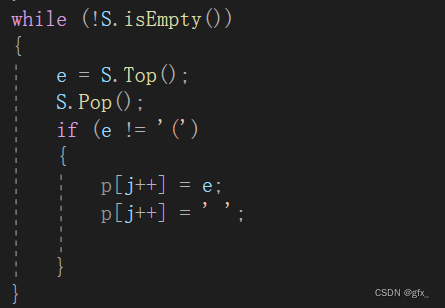
(1.2.7)中缀表达式遍历完成,还需检查栈中是否有未输出字符。判断栈空,非空则直接出栈并输出(左括号不用输出)
-
- 计算后缀表达式
->字符为操作数 :
直接入栈(先分析出完整的运算数并将其转换为对应的数据类型)
->字符为操作符 :
连续出栈两次,使用出栈的两个数据进行相应计算,并将计算结果入栈
(1.3.1)遇到‘-’:当做负号符号/运算符
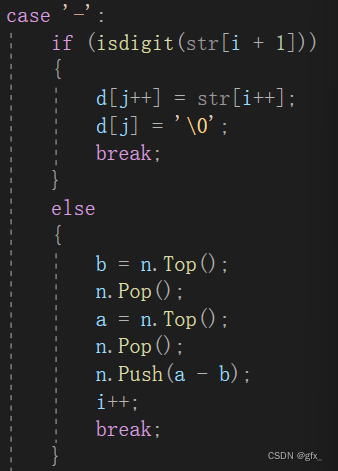
(1.3.2) 遇到‘+’或 ‘*’或 ‘/’:(以‘+’为例)

(1.3.3) 遇到‘ ’:跳过
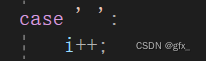
(1.3.4) 遇到数字:

(2)运行结果:
正常输出:


健壮性:


五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
(1)对‘-’的处理:要判断是负数符号还是运算符号:
表达式首位是‘-’,则一定是作为负数符号;
‘-’前面是‘(’,则一定是作为负数符号;
否则为运算符号。

运行结果:
(1.1)无上述代码时:

这里的 -6 应该才是一个完整的运算数,但是在后缀表达式中 '-' 号和数字 '6' 被拆分开来了,得到的结果也不正确。因为代码中对于 '-' 号一律是作为操作符处理,所以面对像 -6 这样的负数时不能分析出完整正确的运算数。
(1.2)添加上述代码后:

(2)对数字的处理:
处理负数:同(1)中把‘-’视作负号符号。
处理小数:利用isdigit()函数判断字符是否为数字,利用字符数组d暂时存储小数每一位(包括数字及小数点),后用atof()函数,将字符数组d转成double类型数字。
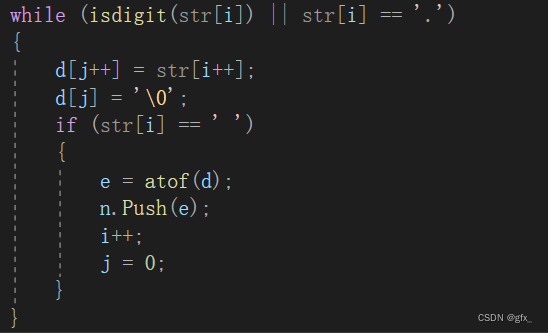
(2.1)atof()函数:
引用头文件:#include <stdlib.h> 和 #include <math.h>
功能:将字符串转换成double型数据。atof()会扫描参数字符串,跳过前面的空格字符,直到遇上数字或正负符号才开始做转换,而后严格按照格式要求来判断,直到格式违规或遇到字符串结束标志‘\0’才会结束转换,返回一个double类型的数据。
注意:如果输入无法转换成该类型的数据,则返回值为0。
如果atof()函数的返回值大于其返回类型的最大值就会出现溢出现象,从而导致传回来数据的某部分丢失。
(2.2)isdigit()函数:
引用头文件:#include <ctype.h>
功能:检查参数c是否为阿拉伯数字0到9。
注意:若参数c不是阿拉伯数字,则返回值为0。
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
(1)算数表达式求值由于数值与运算符类型不同,要设置两个栈,一个栈存放操作符,一个栈存放操作数。
(2)prcd数组存储运算符优先关系,optrToInt函数定位数组元素,Precede函数返回两算符的优先关系。
(3)考虑小数、负数、括号:
->小数的存储问题:利用isdigit()和atof()函数。
->负号是负数符号还是运算符号:
表达式首位是‘-’,则一定是作为负数符号;
‘-’前面是‘(’,则一定是作为负数符号;
否则为运算符号。
->括号是否匹配:
扫描到右括号且栈为空,则匹配失败,提示重新输入;
栈不为空,栈顶元素出栈,与当前字符比较,若当前字符为‘)’而栈顶元素不为‘(’,则匹配失败,提示重新输入;
否则匹配成功,计算结果。
(4)整体框架:
->输入的中缀表达式括号是否匹配
->中缀表达式转后缀表达式
->计算后缀表达式
- 实验目的和要求:(本次实验所涉及并要求掌握的知识点)
链栈类模板的实现与功能测试
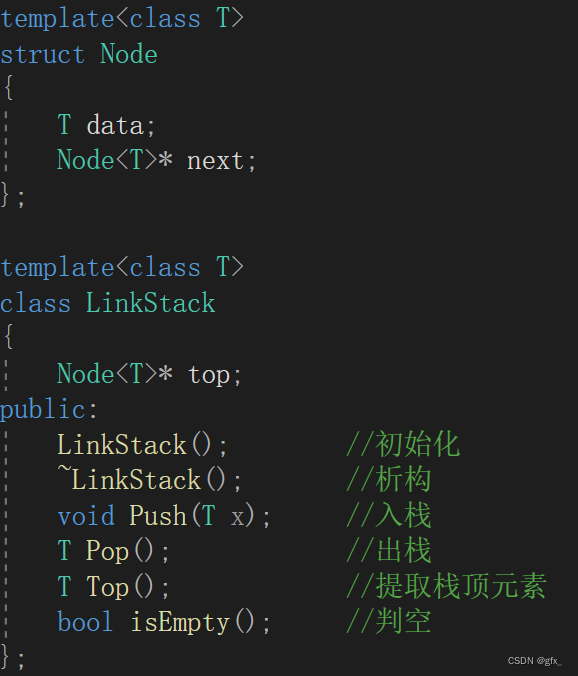
- 实验环境:(本次实验所需要的平台和相关软件)
Visual Studio 2022
- 实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
- 建立LinkStack类
- 声明函数
(1)入栈
(2)出栈
(3)提取栈顶元素
(4)判空
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.菜单选择:

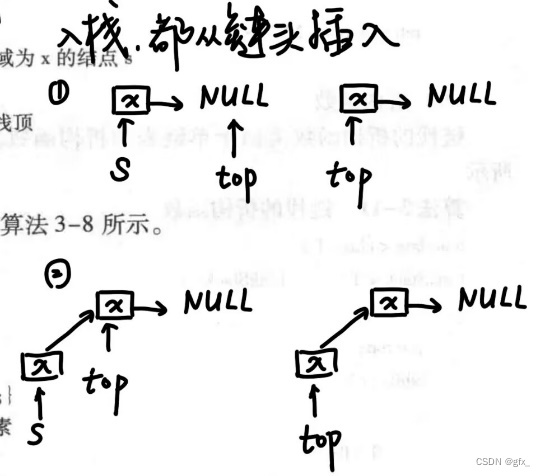
2.入栈:如图示所示:


3.出栈:如图示所示:
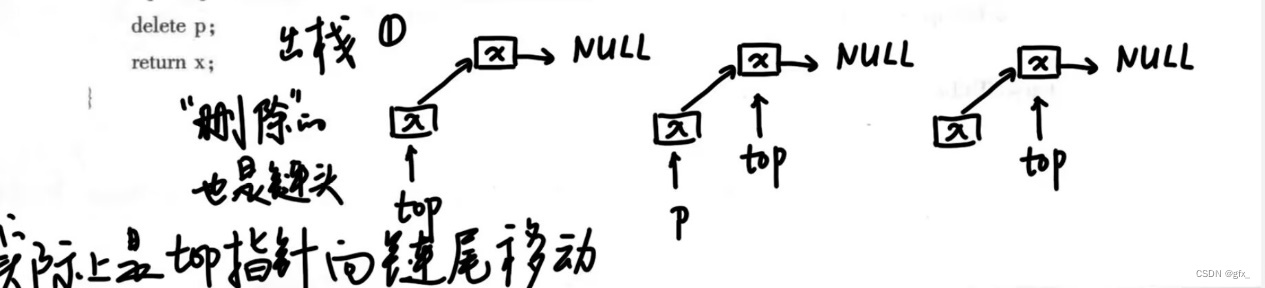

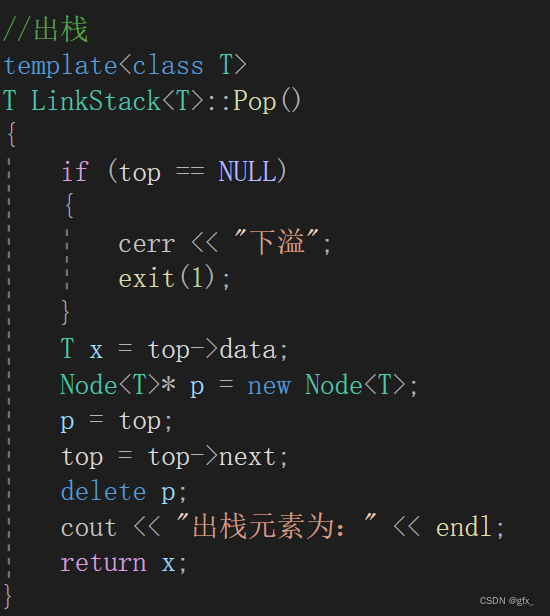
健壮性:链栈为空时,无元素出栈,“下溢”。
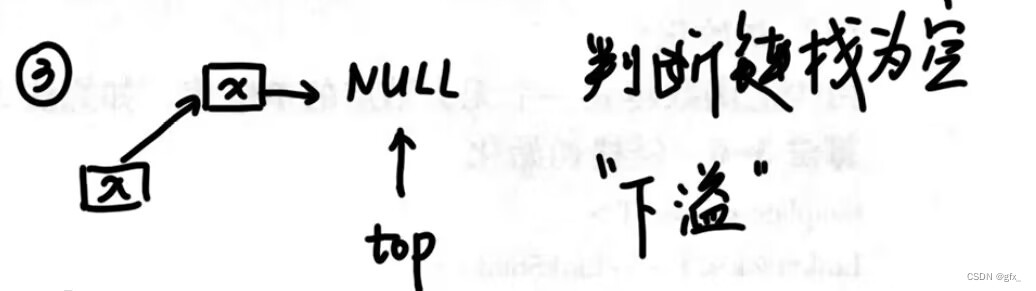

4.取栈顶元素:如图所示
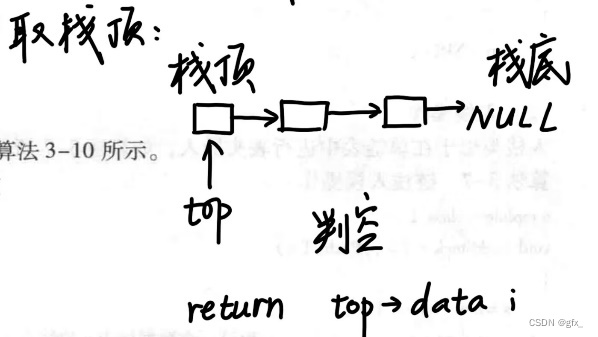

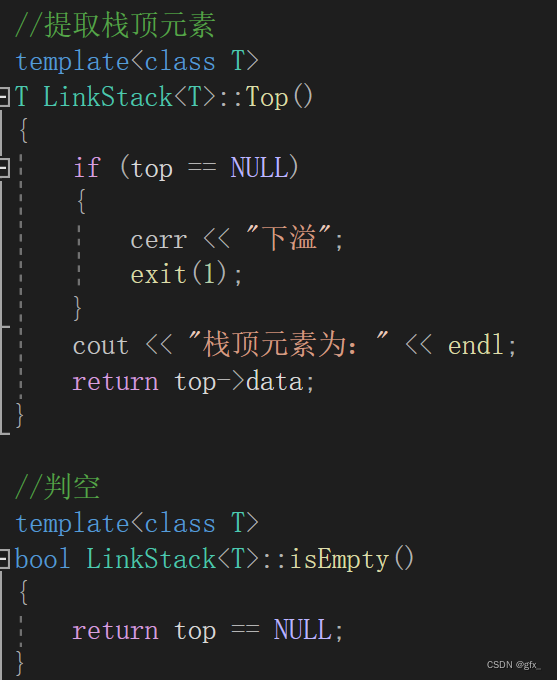

健壮性:栈为空时,无栈顶元素输出:

5.析构:如图所示:
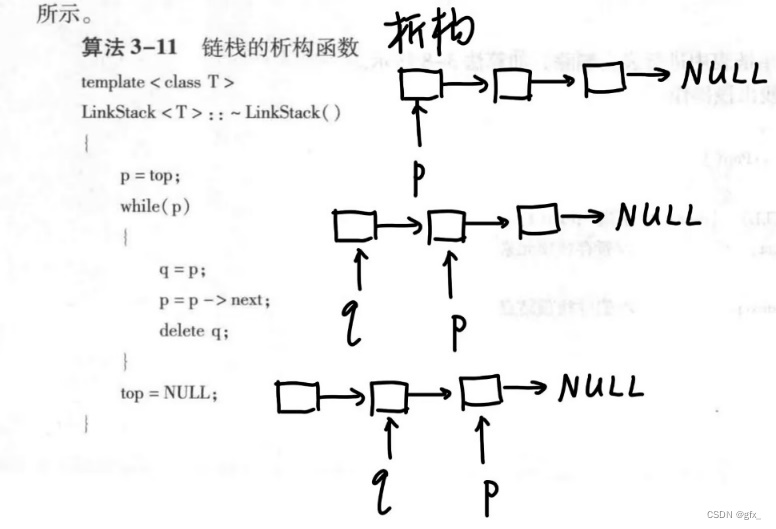


五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1.入栈时不需要判满:
由于链栈的内存动态分配,其长度可以根据实际需求进行增长,链栈通常不会出现栈满的情况。但删除时,要释放空间。
2.new与malloc的区别:
(1)malloc()动态配置内存,大小由size决定,分配成功时返回值为任意类型指针,指向一段可用内存(虚拟内存)的起始地址。分配失败时为NULL。
void * malloc(size_t size)
free()释放动态申请的内存空间,调用free( )后ptr所指向的内存空间被收回,如果ptr指向未知地方或者指向的空间已被收回,则会发生不可预知的错误,如果ptr为NULL,free不会有任何作用。
void free(void *ptr)
malloc函数动态申请的内存空间是在堆里(一般局部变量存于栈里),并且该段内存不会被初始化,如果不采用手动free()加以释放,则该段内存一直存在,直到程序退出才被系统,所以为了合理使用内存,在不适用该段内存时,应该调用free()。malloc要配对使用free,否则容易造成内存泄露。
(2)new是动态分配内存的运算符,自动计算需要分配的空间,在C++中,属于重载运算符,可以对多种数据类型形式进行分配内存空间,比如int型、char型、结构体型和类等的动态申请的内存分配,分配类的内存空间时,同时调用类的构造函数,对内存空间进行初始化,即完成类的初始化工作。用new分配数组空间不能指定初值,若无法正常分配,则new会返回一个空指针NULL或者抛出bad_alloc异常。
new int
new char[100]
float *p=new float(3.14157)
delete是撤销动态申请的内存运算符。delete与new通常配对使用,与new的功能相反,可以对多种数据类型形式的内存进行撤销,包括类,撤销类的内存空间时,它要调用其析构函数,完成相应的清理工作,收回相应的内存资源。
int *p = new int; delete p;
Obj *p = new Obj[100]; delete[] p;
3.链栈不需要头结点:
因为链栈是运算受限的单链表,其插入和删除操作仅限制在表头位置上进行,只能在链表头部进行操作,故链栈不需设置头结点。
而在单链表中数据插入的位置不一定在表头位置,为了使空链表与非空链表处理一致,我们通常设一个头结点。
4.链栈与顺序栈的比较:
链栈和顺序栈都是栈的实现方式,但它们之间有一些区别:
1. 存储结构:
- 顺序栈:使用数组实现,所有元素在内存中是连续存储的。
- 链栈:使用链表实现,每个元素通过指针连接,内存中不一定是连续存储的。
2. 操作效率:
- 顺序栈:在插入和删除元素时,需要移动元素位置,操作效率较低。
- 链栈:插入和删除元素时只需要修改指针指向,操作效率较高。
3. 大小限制:
- 顺序栈:需要预先分配固定大小的内存空间,容量有限。
- 链栈:没有固定大小限制,可以根据需要动态扩展。
4. 空间利用:
- 顺序栈:可能存在空间浪费,因为大小固定,即使栈中只有少量元素也会占用一定大小的连续内存空间。
- 链栈:根据需要分配内存空间,灵活利用内存,避免空间浪费。
总的来说,链栈适合在元素数量不确定或需要频繁插入删除操作的情况下使用,而顺序栈适合在元素数量固定或需要频繁访问栈顶元素的情况下使用。选择使用哪种栈取决于具体应用场景和需求。
时间性能:都是O(1)
空间性能:
顺序栈:有元素个数限制和空间浪费的问题。
链栈:没有栈满的问题,只有当内存没有可用空间时才会出现栈满,但每个元素都需要一个指针域,从而产生了结构性开销。
总之,当栈的使用过程中元素个数变化较大时,用链栈。反之用顺序栈。
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1.链栈LinkStack类模板的基本功能实现
2.入栈不需要判满,出栈需要判空
3.链栈不需要设置头结点:与元素插入位置有关
4.链栈与顺序栈的比较:与元素个数变化有关
5.new与malloc的区别
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
1.体会递归问题的两个基本条件。
2.比较递归与显式用栈实现的方法。
3.思考递归编程存在的局限性及解决方法。
4.完成实验报告。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
1.编写把十进制正整数转换为S进制(S=2,8,16)数输出的递归算法。
2.编写出计算Fib(n)的递归算法。并分析递归算法和非递归算法的时间复杂度和空间复杂度。
3.杨辉三角形的递归实现。
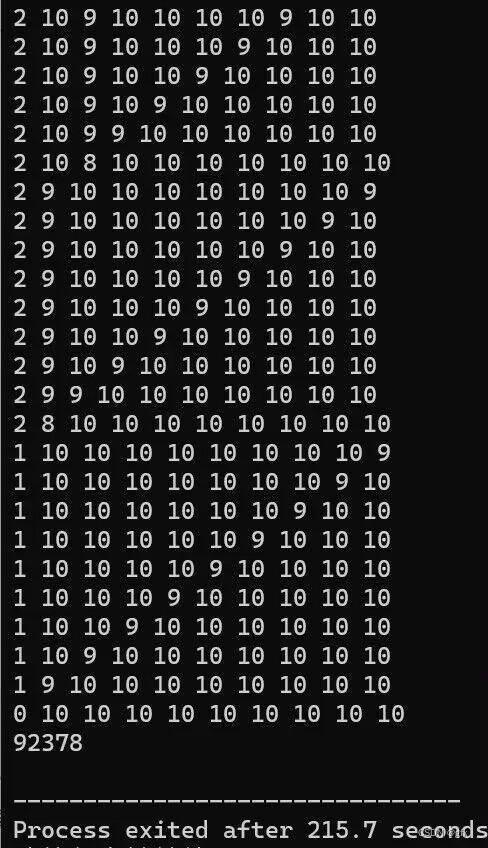
4.一个射击运动员打靶,靶一共有10环,连开10枪打中90环的可能性有多少种?试用递归算法实现。 程序结果一共有92 378种可能。
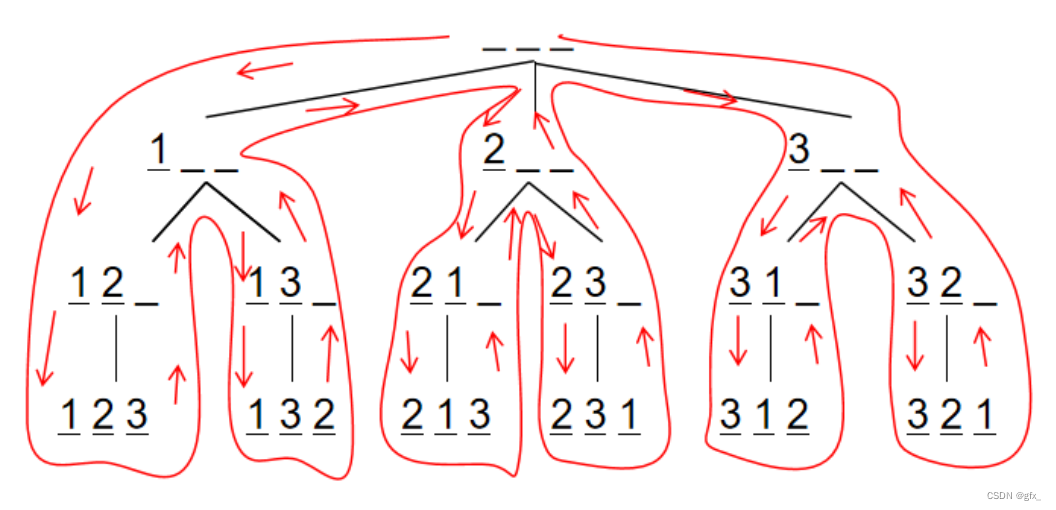
5.编写一个递归算法,输出自然数1~n这n个数的全排列
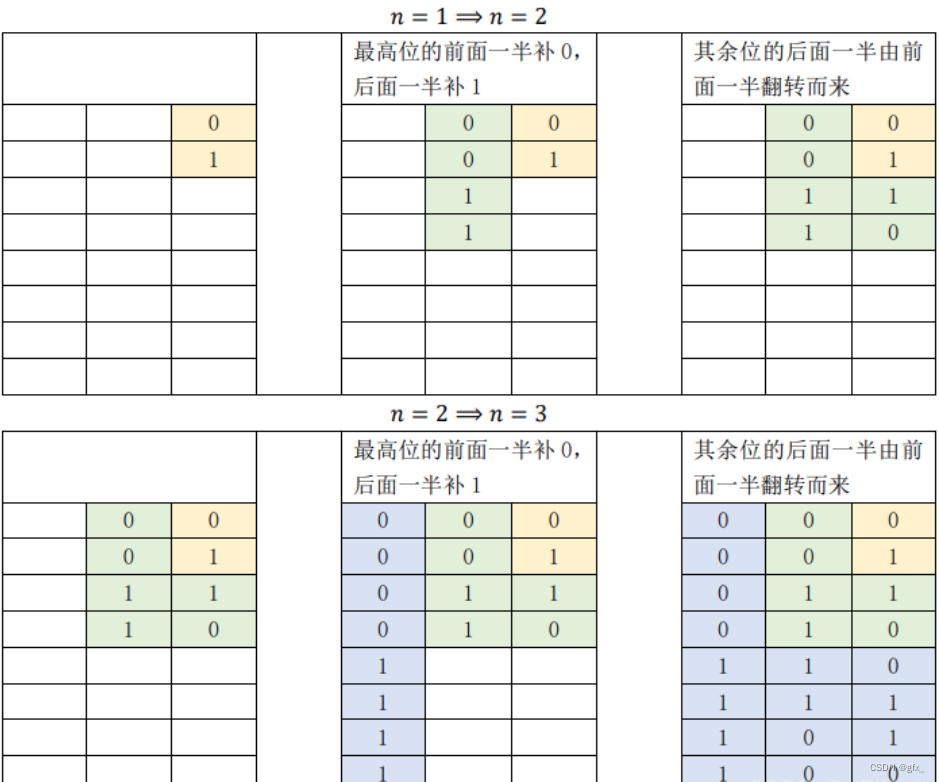
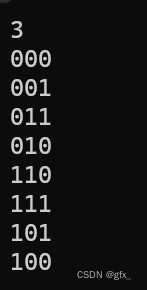
6.编写GRAY码的递归算法。
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.进制转换:
(1)进制转换递归实现:
每一次取余的操作都是一致的。且终止条件存在,为n==0。

正常输入输出: 健壮性:


(2)进制转换链栈实现:
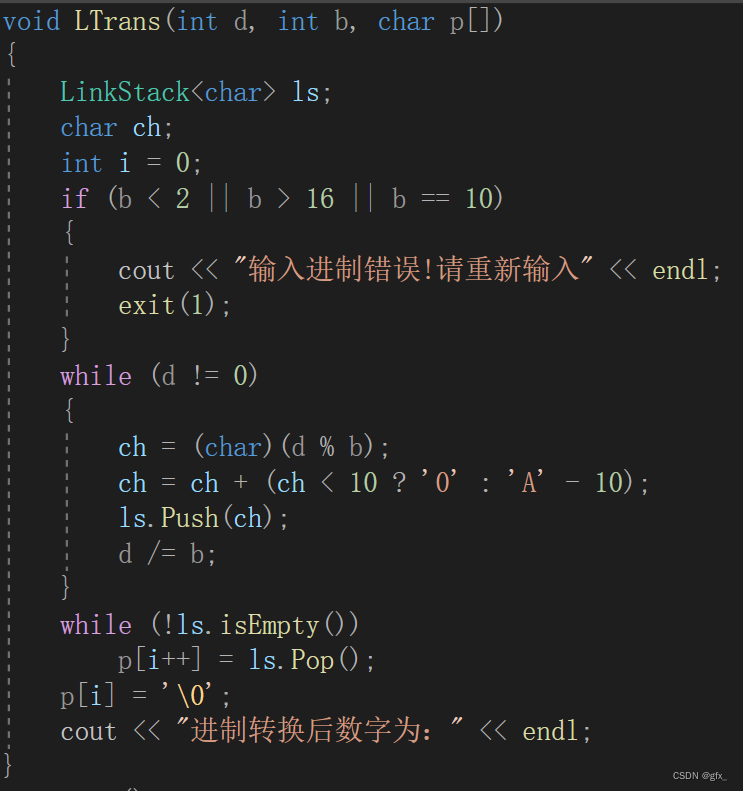
将余数转换成字符压入栈内,随后让所有元素依序出栈,改变余数字符的存储顺序,存入字符数组内并输出。
正常输入输出: 健壮性:


2.斐波那契数列:
(1)递归实现:第一和第二个元素为1,后续元素等于前两个元素之和。


<1>计算时间复杂度:
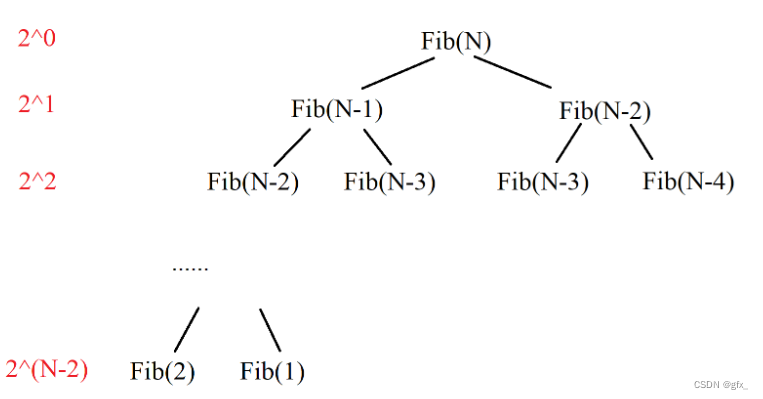
调用总次数为2^(N-1)-1,则时间复杂度为O(2^n)
<2>计算空间复杂度:
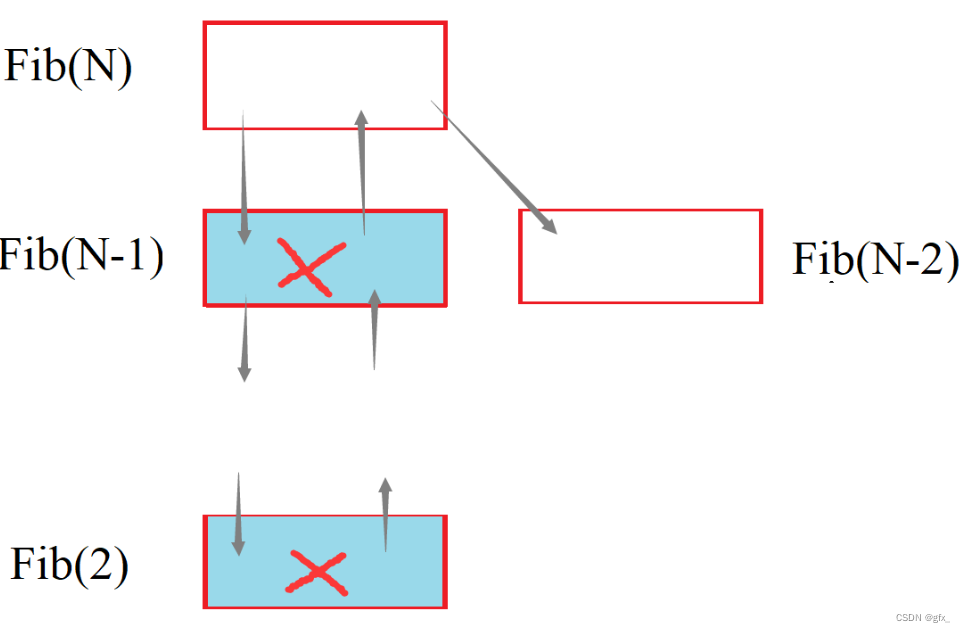
递归的斐波那契数列的空间复杂度是O(n)。Fib(N-1)一路沿Fib(2)返回后消毁栈帧,调用Fib(N-2)并建立栈帧后,实际上 Fib(N-2)与Fib(N-1)用的是同一块栈帧空间。这是由于时间是累积的,而空间是可以重复利用的。
(2)非递归实现:
法一:迭代实现


<1>时间复杂度:O(n)
<2>空间复杂度:O(1)
法二:用三个变量来回计算


<1>时间复杂度:O(n)
<2>空间复杂度:O(1)
3.杨辉三角递归:第一列和正对角线上的数字全为1,其他数字为其上方和左上方的数字之和。


4.射击运动员打靶递归:
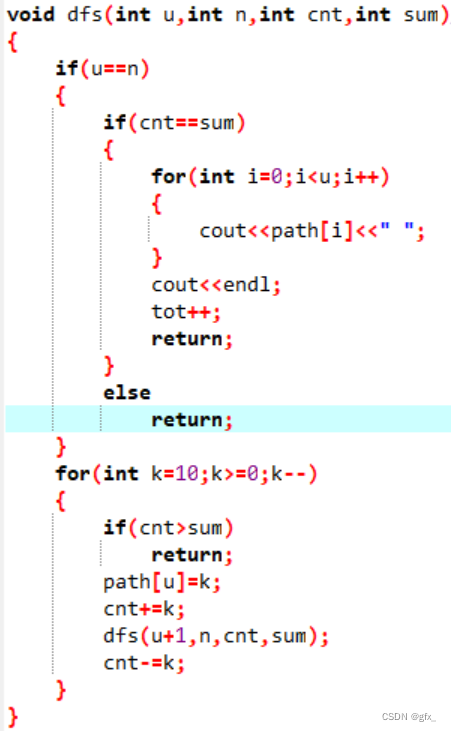
当前为第u个靶子,共有n个靶子,cnt为当前环数总和,sum是环数总和。
第u个靶子可以取的环数范围为0~10,若到达最后一个靶子后,当前环数总和与最后环数总和相等,则输出存储各靶子环数的数组path,否则退回最后一个靶子,重新从0~10取环数。以此类推。
5.全排列递归:总共有n个数字的位置,第u个位置, 用1~n的数字填充且不能重复,用w数组记录数字是否使用过,用path数组记录当前数字,由于填充的位置下标为0~n-1,所以当到达第n个位置时,输出path数组中存储的数字。以此类推,返回并采用当前位置未使用过的数字。

6.GRAY码递归:求num个n位Gray码,分治到只有1位Gray码的情况;将求解n位Gray码的问题划分成求解n-1位Gray码的问题,n位Gray码的前半部分最高位置0,其余位不变,n位Gray码的后半部分最高位置1,其余位由n-1位Gray码翻转而来。

五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
1.递归与尾递归的区别:
(1)实现斐波那契数列的递归函数:
int fib (int n)
{
if (n <= 1)
return n;
else
return fib (n - 1) + fib (n - 2);
}
这个递归函数会不断地调用自己来计算斐波那契数列。这个实现在小规模的输入上是有效的,但当输入值较大时,递归的层数会变得很深,导致性能下降,并可能导致栈溢出的问题。
(2)实现斐波那契数列的尾递归函数:
int fib (int n, int a = 0, int b = 1)
{
if (n == 0)
return a;
else
return fib(n - 1, b, a + b);
}
在这个尾递归函数中,递归调用位于函数的最后一步,并且使用新的参数直接取代了之前的参数。这样就避免了在递归调用之后还需要进行额外的计算或操作。这个方式下,递归调用并不会增加栈的深度,因此不会有栈溢出的风险。尾递归函数可以通过对参数的更新来实现迭代的效果,从而提高性能和减少内存的使用。
2.斐波那契数列三种方法的时空复杂度计算:
(1)递归:
<1>时间复杂度:
由于每次递归调用都会生成两个新的递归调用,且递归树是指数级的,因此时间复杂度为 O(2^n)。
<2>空间复杂度:
每个递归调用会在栈中创建一个新的函数帧,而递归栈的深度取决于输入值 n,因此空间复杂度为 O(n)。
(2)迭代:
<1>时间复杂度:
迭代方式的斐波那契数列计算仅需要一次循环遍历,每次迭代都在常数时间内完成。因此,时间复杂度为 O(n)。
<2>空间复杂度:
尽管数组大小为 100,但实际上只使用了数组中的前 n 个元素,其中 n 是输入的斐波那契数列位置。因此,在实际计算过程中,空间复杂度是与 n 相关的。不过根据该代码实现中 n 的输入上限为 100,因此空间复杂度可以视为常数级别。
(3)三变量:
<1>时间复杂度:
迭代方式的斐波那契数列计算使用了一个循环来计算第 n 位的数值。循环的次数与输入值 n 相关,因此时间复杂度为 O(n)。
<2>空间复杂度:
在迭代方式中,只使用了几个整数变量来保存中间结果和计算,没有使用数组或其他额外的数据结构。因此,空间复杂度为 O(1),即常数级别的空间复杂度。
六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
1.什么是递归:
递归函数直接调用自己或通过一系列调用语句间接调用自己。
有些问题使用传统的迭代算法是很难求解甚至无解的,而使用递归却可以很容易的解决。比如汉诺塔问题。但递归的使用也是有它的劣势的,因为它要进行多层函数调用,所以会消耗很多堆栈空间和函数调用时间。
递归是一种编程技术,指的是函数直接或间接调用自身的过程。在递归过程中,函数会重复执行相似的操作,但针对规模更小的输入数据。递归的核心思想是将大问题分解为相似的子问题,然后通过不断调用自身来解决这些子问题,最终求解整个大问题。
在递归函数中,通常包括两个部分:基本案例和递归案例。基本案例是指当输入达到一定条件时,不再需要继续递归调用,直接返回结果。递归案例则是指在函数内部调用自身以解决规模更小的子问题。递归函数必须具有明确的结束条件,否则会导致无限递归,导致栈溢出等问题。
递归在编程中常用于解决树、图、分治、动态规划等问题,能够简洁地实现复杂的算法逻辑。然而,需要注意递归调用会消耗更多的内存和时间,并且可能存在性能问题,因此在使用递归时需要慎重考虑。
2.递归问题的两个基本条件:
(1)大问题可以分解为具有相同形式、相同解法的小问题。
(2)递归存在明确的终止条件。
3.递归与显式用栈实现的方法比较:
递归的优点是代码简洁易懂,可以自然地表达问题的逻辑。然而,递归也有一些缺点。由于每次函数调用都需要保存现场,递归在大规模问题上耗费的空间很大。此外,递归的执行过程中会有多次函数调用和返回,这在一些情况下可能导致性能问题。
显式用栈,指的是显式地使用栈数据结构来解决问题。通过手动操作栈的入栈和出栈操作,可以模拟递归的行为。相比于递归,使用显式栈的方式可以对栈中的数据和状态进行更加灵活的控制。同时,显式用栈不会出现递归过程中的函数调用和返回操作,因此性能会相对较好。然而,显式使用栈需要手动维护栈的状态和数据,这可能会增加编码的复杂度。
在空间要求较高、问题规模较大、性能要求较高的情况下,显式用栈会更适合。而在问题逻辑较为简单、代码易读易写的情况下,递归会更方便使用。
4.什么是栈溢出:
当一个函数被调用时,程序会在栈上为其分配一块内存区域,用于存储函数的参数、局部变量和返回地址等信息。每个函数调用都会在栈上创建一个新的栈帧,以保存这些信息。当函数执行完毕后,对应的栈帧会被销毁,释放对应的内存。
当递归函数无限递归调用,或者函数内部使用大量的局部变量导致栈空间无法容纳时,就会发生栈溢出。此时,栈空间被耗尽,无法继续为新的函数调用创建栈帧,导致程序异常终止。
栈溢出是指当程序执行时,栈空间中的内容超出了栈的大小限制,导致数据溢出到了其他内存区域。栈是用来存储函数调用和局部变量的内存区域,每次函数调用都会在栈上创建一个新的栈帧,包含函数参数、返回地址和局部变量等。如果程序递归调用的层次过深,或者在函数内部不断创建大量的局部变量,会导致栈空间不足,从而发生栈溢出。
栈溢出通常是由于递归调用过深,导致栈空间耗尽而发生的。当栈溢出发生时,程序会抛出栈溢出异常,通常是操作系统自动检测到栈空间溢出并终止程序的执行。为避免栈溢出,可以考虑减少递归深度、优化递归算法、减少局部变量的使用等方式来降低栈空间的消耗,或者使用动态内存分配来代替栈空间。要注意栈溢出可能导致程序崩溃,因此在编写代码时需要注意控制递归深度和栈空间的使用。
5.使用栈缓解栈溢出的问题:
(1)优化递归算法:递归算法是常见的导致栈溢出的原因之一。可以考虑优化递归算法,将其转换为迭代算法或者使用尾递归优化,以减少函数调用的层次。
(2)减少局部变量的使用:局部变量会占用栈空间。如果函数中使用的局部变量较多,可以尝试减少或者合并局部变量的使用,以降低栈的负担。
(3)动态内存分配:将一部分数据从栈空间转移到堆空间,通过动态内存分配(如使用new或malloc函数)来存储大量数据或者较大的数据结构,以减轻对栈空间的占用。
(4)使用循环代替递归:如果递归不是必要的,可以考虑使用循环来替代递归调用,这样可以避免递归过深而导致的栈溢出问题。
一、实验目的和要求:(本次实验所涉及并要求掌握的知识点)
采用顺序存储方式存储串,建立两个字符串s,t,编程实现BF模式匹配算法和KMP模式匹配算法。
二、实验环境:(本次实验所需要的平台和相关软件)
Windows 11
Visual Studio 2022
Dev-C++5.10
三、实验内容及步骤:(本次实验计划安排的实验内容和具体实现步骤)
1.建立两个字符串s,t
2.实现BF模式匹配算法
3.实现KMP模式匹配算法
4.优化KMP模式匹配算法
四、实验过程和结果:(记录实验过程和结果、以及所出现的问题和解决方法)
1.BF模式匹配算法:
思想:
- 主串和模式串逐个字符进行比较
- 当出现字符不匹配时,主串的比较位置重置为起始位置的下一个字符位置,模式串的比较位置重置为起始字符
- 回溯关系的确定:i = i - j + 1; //主串指针回溯到比较起始位置的下一个字符位置
- 匹配成功返回主串中匹配串的起始位置,否则返回-1

运行结果:
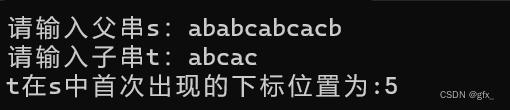
BF算法的思想比较简单,在最好情况下时间复杂度为O(n+m)。但当在最坏情况下,算法的时间复杂度为O(n*m),其中n和m分别是父串和子串的长度。这个算法的主要事件耗费在失配后的比较位置有回溯,因而比较次数过多。为降低时间复杂度可采用无回溯的算法。
2. KMP模式匹配算法:
(1)引入:
一个字符串最长相等前缀和后缀:
字符串 abcdab
前缀的集合:{a,ab,abc,abcd,abcda}
后缀的集合:{b,ab,dab,cdab,bcdab}
最长相等前后缀为:ab
(2)分析:
第一串代表主串,第二串代表子串。红色部分代表两串中已匹配的部分,绿色和蓝色部分分别代表主串和子串中不匹配的字符。
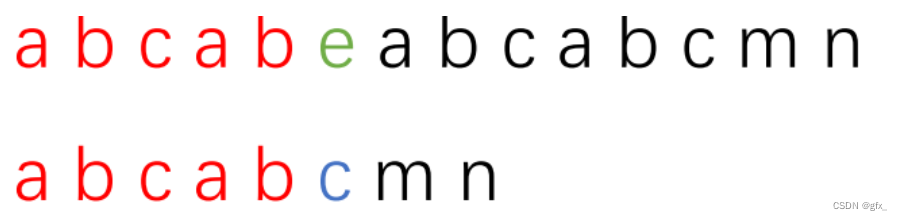
现在发现了不匹配的地方,根据KMP的思想,要将子串向后移动,现在解决要移动多少的问题。根据最长相等前后缀的概念,红色部分也有最长相等前后缀。灰色部分就是红色部分字符串的最长相等前后缀,子串移动的结果就是让子串的红色部分最长相等前缀和主串红色部分最长相等后缀对齐。

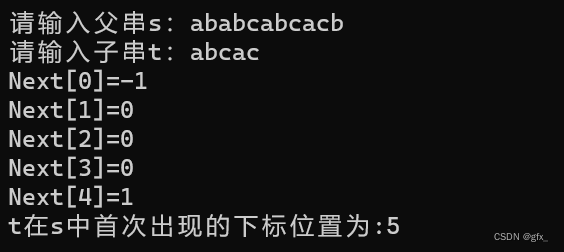
我们单独用一个Next数组存储子串的最长相等前后缀的长度。Next数组的数值只与子串本身有关。
next[i]=j含义是:下标为i 的字符前的字符串最长相等前后缀的长度为j。
next数组作用有两个:
->next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度
->表示该处字符不匹配时应该回溯到的字符的下标
KMP算法中多了一个求数组的过程,多消耗了一点点空间。设主串s长度为n,子串t的长度为m。求next数组时时间复杂度为O(m),因后面匹配中主串不回溯,比较次数可记为n,所以KMP算法的总时间复杂度为O(m+n),空间复杂度记为O(m)。相比于朴素的模式匹配时间复杂度O(m*n),KMP算法提速是非常大的,这一点点空间消耗换得极高的时间提速是非常有意义的。
(3)运行结果:
3.优化KMP模式匹配算法:
(1)需要改进的原因:
主串s=“aaaaabaaaaac”
子串t=“aaaaac”
这个例子中当‘b’与‘c’不匹配时应该‘b’与’c’前一位的‘a’比,这显然是不匹配的。'c’前的’a’回溯后的字符依然是‘a’。
我们知道没有必要再将‘b’与‘a’比对了,因为回溯后的字符和原字符是相同的,原字符不匹配,回溯后的字符自然不可能匹配。但是KMP算法中依然会将‘b’与回溯到的‘a’进行比对。这就是我们可以改进的地方了。我们改进后的next数组命名为:nextval数组。KMP算法的改进可以简述为: 如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。
(2)getnext()函数:
Next数组与Nextval数组比较:
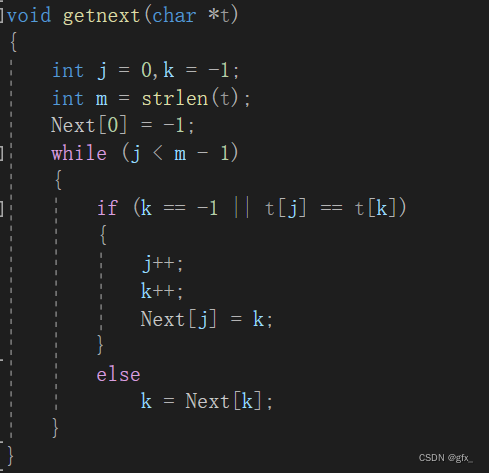
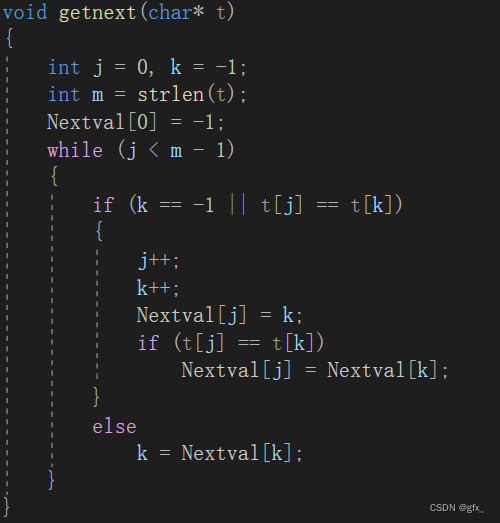
(3)运行结果:
Next数组与Nextval数组比较:


五、实验中的问题及解决:(本次实验中在编程中碰到的错误等问题及解决方法)
(1)对Next数组的理解:
next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度,表示该处字符不匹配时应该回溯到的字符的下标。
(2)KMP算法思想:
关键:前后缀相等
改进:如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。

六、实验总结和思考:(填写收获和体会,分析成功或失败的原因):
(1)BF算法采用主串和模式串逐个字符进行比较的暴力法,关键在于回溯关系的确定:i = i - j + 1; //主串指针回溯到比较起始位置的下一个字符位置。最坏时间复杂度为O(n*m)。BF算法是一种简单直接的字符串匹配算法,它通过逐个字符比较主串和模式串来寻找匹配的子串。关键在于确定回溯关系,即当字符不匹配时,主串指针要回溯到比较起始位置的下一个字符位置。这导致了BF算法的最坏时间复杂度为O(n*m),其中n为主串长度,m为模式串长度。
(2)相较于BF算法,KMP算法通过预处理出一个Next数组来实现更高效的字符串匹配。Next数组用于存储子串的最长相等前后缀的长度,从而在匹配过程中能够快速回溯到匹配失败的位置。具体而言,Next数组中的值表示下标为i的字符前的字符串最长相等前后缀的长度,当字符不匹配时应该回溯到的字符的下标。
KMP算法需要对子串预处理出一个Next数组,用于存储子串的最长相等前后缀的长度。next数组作用有两个:
->next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度
->表示该处字符不匹配时应该回溯到的字符的下标
(3)KMP算法的优化:如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。
KMP算法的优化主要体现在Next数组的计算上。如果某一位字符与它Next值指向的字符相等,那么该字符的Next值就指向指向的字符的Next值;如果不相等,则该字符的Next值为它自己的Next值。这样可以减少不必要的比较,提高匹配效率。KMP算法在实际应用中有着广泛的应用,是一种高效的字符串匹配算法。

