
- 1【网络安全】CTF入门教程(非常详细)从零基础入门到进阶,看这一篇就够了!_ctf网络安全大赛入门教程
- 2python利用Django框架开发WebDemo_django demo
- 3ChatGPT实用指南|ChatGPT十步搞定论文【全流程+提示词】_生成论文大纲提示词
- 42024年4月个人工作生活总结
- 5IntelliJ IDEA如何配置git_intellij2024设置git
- 6vue3日历时间 vite + vue3 日历时间_vue3-calendar
- 7Jmeter测试学习(02):单个线程组下多个HTTP请求_jmeter一个线程组下多个请求并行
- 8十、数据仓库详细介绍(数据质量)理论与经验_数据质量体现在数据仓库的采集转换存储应用等各个方面每个阶段对于数据质量有
- 9中文语料库
- 10Stable Diffusion修复老照片-图生图_stablediffusion老照片修复
pyspark使用方法_pyspark使用教程
赞
踩
来源,官网spark2.2.1版本
pyspark不同函数的形象化解释
SparkSession是Spark 2.0引入的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。 在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点。SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。
1、pyspark函数接口
pyspark.SparkConf()
是对spark应用进行设置的类
pyspark.SparkContext()
是spark应用的入口,也可以称为驱动
SparkContext.broadcast(value)函数:广播变量
广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。
Spark的动作通过一系列的步骤执行,这些步骤由分布式的洗牌操作分开。Spark自动地广播每个步骤每个任务需要的通用数据。这些广播数据被序列化地缓存,在运行任务之前被反序列化出来。这意味着当我们需要在多个阶段的任务之间使用相同的数据,或者以反序列化形式缓存数据是十分重要的时候,显式地创建广播变量才有用。
通过在一个变量v上调用SparkContext.broadcast(v)可以创建广播变量。广播变量是围绕着v的封装,可以通过value方法访问这个变量。举例如下:
- from pyspark import SparkContext
- from numpy import array
- sc=SparkContext()
- broadcast_var= sc.broadcast(array([1,2,3,4]))
- print(broadcast_var.value)
- #运行结果 [1 2 3 4]
- 1
- 2
- 3
- 4
- 5
- 6
在创建了广播变量之后,在集群上的所有函数中应该使用它来替代使用v.这样v就不会不止一次地在节点之间传输了。另外,为了确保所有的节点获得相同的变量,对象v在被广播之后就不应该再修改。
SparkContext.parallelize(c,numSlice=none)
将一个本地的python对象集群分布以创建一个RDD。如果是将一个范围实现RDD化,推荐使用xrange(),xrange与range的区别在于xrange是生成一个列表对象,而不是列表本身,因而不需要一上来就开辟一块内存区域,但是python3已经没有xrange了。
- sc=SparkContext()
- print(sc.parallelize([1,2,3,4,5,6],3).glom().collect())
- print(sc.parallelize([0,6,2],5).glom().collect())
- 1
- 2
- 3
结果如下:
- [[1, 2], [3, 4], [5, 6]]
- [[], [0], [], [6], [2]]
- 1
- 2
上面的程序中,parallelize的第二个参数是RDD的切片数目(这个跟分区有区别?),
同时可以看到,如果元素个数少于分区数,则会产生空的列表。
SparkContext.range(start,end=none,step=1,numSlice=none)
产生某个范围内元素组成的RDD
- sc=SparkContext()
- print(sc.range(1,7,2).collect())
- 1
- 2
结果如下:
[1, 3, 5]- 1
SparkContext.textFile(name, minPartitions=None, use_unicode=True)
从hdfs上,从本地等读取txt文件,并转换成RDD
SparkContext.wholeTextFiles(path, minPartitions=None, use_unicode=True)
读取整个文件夹下的txt文件
SparkContext.union(rdds)
将不同的RDD组合在一起
rdd.map(f)
将rdd中的每一个元素作一个一对一的映射,映射后的一可以是一个元素或一个组合,比如元组、列表等。如果输入是一个dataframe,比如使用sparksql读取hive数据表,此时rdd中的每一个元素对应原数据库中的一行。这样我们可以做针对行的组合操作。
比如使用map实现(key,values)操作:
- #我们首先创建这样的一个rdd
- input_data=sc.parallelize([['a',1],['b',2],['b',3],['c',4],['a',5],['b',6]],2)
- #查看结果:
- print(input_data.glom().collect())
- #结果如下:
- #[[['a', 1], ['b', 2], ['b', 3]], [['c', 4], ['a', 5], ['b', 6]]]
- #可以看到这样rdd有2个分区,每个分区中包含3个元素,每个元素均为一个列表
- #我们假如第一个是键,第二个是值,下面我们来构造键值对rdd,并对每个键进行求和。
- #首先利用map(f)构造键值对
- input_key_value=input_data.map(lambda x:(x[0],x[1]))
- #查看一下结果:
- #[[('a', 1), ('b', 2), ('b', 3)], [('c', 4), ('a', 5), ('b', 6)]]
- #从上面的结果可以看到,分区未发生变化。但每个元素的形式发生了变化
- #下面利用reduceByKey(f)来求和
- sum_value=input_key_value.reduceByKey(lambda x,y:x+y)
- #上式中lambda传入的参数x,y代表元素的值两两间进行,返回x+y表示两两求和,按键逐步聚合。
- print(sum_value.glom().collect())
- #结果如下:
- #[[('c', 4), ('b', 11)], [('a', 6)]]
- #上面的结果比较有意思的是,求reduceByKey求和后,仍然是两个分区。很显示这样存在分区间的数据传递。所以从效率的角度考虑这样的分区方式并不合理。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
下面用map实现函数映射,这里以kmeans为例.代码主体来源网上。
- #生成多类单标签数据集
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets.samples_generator import make_blobs
- center=[[1,1],[-1,-1],[1,-1]]
- cluster_std=0.3
- X,labels=make_blobs(n_samples=200,centers=center,n_features=2,
- cluster_std=cluster_std,random_state=0)
- print('X.shape',X.shape)
- print("labels",set(labels))
-
- unique_lables=set(labels)
- colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
- for k,col in zip(unique_lables,colors):
- x_k=X[labels==k]
- plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
- markersize=14)
- plt.title('data by make_blob()')
- plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
生成的数据
X.shape (200, 2)
labels {0, 1, 2}
其图像如下所示:
下面是基于map和reduceByKey完成的kmeans聚类

- #生成多类单标签数据集
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets.samples_generator import make_blobs
- center=[[1,1],[-1,-1],[1,-1]]
- cluster_std=0.3
- X,labels=make_blobs(n_samples=200,centers=center,n_features=2,
- cluster_std=cluster_std,random_state=0)
- # print('X.shape',X.shape)
- # print("labels",set(labels))
- #
- unique_lables=set(labels)
- colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
- for k,col in zip(unique_lables,colors):
- x_k=X[labels==k]
- plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
- markersize=14)
- # plt.title('data by make_blob()')
- # plt.show()
-
- from pyspark import SparkContext
-
- def closestPoint(p,centers):#计算某个元素的类别
- bestIndex = 0#初始化类别
- closest = float("+inf")#初始化某点与任意一聚类中心的最小距离为无穷大
- for i in range(len(centers)):
- tempDist = np.sum((p - centers[i]) ** 2)#某个元素到某个聚类中心的距离
- if tempDist < closest:
- closest = tempDist#更新与任意一聚类中心的最小距离
- bestIndex = i#更新类别
- return bestIndex
- sc=SparkContext()
- inputData=sc.parallelize(X).cache()#将原数据转换成rdd,每一个元素对应于一个样本点,并将数据缓存。这里每个元素是array([x1,x2])的形式。
- K=3#初始化类的数目
- convergeDist=0.01#初始化相临两次聚类中心的最小收敛距离,即如果新的聚类中心与上一次聚类中心距离很小了,就可以不用再继续优化了。
- tempDist = 1#初始化相临两次聚类中心的距离
- kPoints=inputData.takeSample(False,K,1)#随机抽取K个类中心,即初始化聚类中心。
- #print(kPoints)
- #结果[array([ 1.04321307, 1.43628205]), array([ 0.85610326, -0.81389251]), array([-1.42721827, -1.14799597])]
- while tempDist > convergeDist:
- closest = inputData.map(lambda p: (closestPoint(p, kPoints), (p, 1)))#将元素映射到这样的键值对,元素---->(类别,(元素,1))
- #print(closest.collect())
- #结果[(0, (array([ 1.68092639, 0.5636903 ]), 1)), ..., (2, (array([-1.36763066, -0.74669111]), 1))]
- pointStats = closest.reduceByKey(lambda p1_c1, p2_c2: (p1_c1[0] + p2_c2[0], p1_c1[1] + p2_c2[1]))#(类别,(元素,1))---->(类别,(array(sum(维度1),sum(维度2)), n))
- #print(pointStats.collect())
- #结果[(0, (array([ 67.85854692, 71.4189192 ]), 67)), (1, (array([ 62.88505036, -68.0744321 ]), 67)), (2, (array([-69.06467775, -68.44964606]), 66))]
- newPoints = pointStats.map(lambda st: (st[0], st[1][0] / st[1][1])).collect()#计算新的聚类中心
- #print(newPoints)
- #结果[(0, array([ 1.01281413, 1.06595402])), (1, array([ 0.93858284, -1.0160363 ])), (2, array([-1.04643451, -1.03711585]))]
- tempDist = sum(np.sum((kPoints[iK] - p) ** 2) for (iK, p) in newPoints)#计算相临两次聚类中心的距离
- #print(tempDist)
- #结果0.343022614898
- for (iK, p) in newPoints:#更新聚类中心
- kPoints[iK] = p
- print("Final centers: " + str(kPoints))
- newInput=closest.collect()
-
- #这里先这样画
- for p in newInput:
- if p[0]==0:
- plt.plot(p[1][0][0], p[1][0][1], '*', markerfacecolor='g', markeredgecolor='b',
- markersize=14)
- elif p[0]==1:
- plt.plot(p[1][0][0], p[1][0][1], '*', markerfacecolor='b', markeredgecolor='r',
- markersize=14)
- else:
- plt.plot(p[1][0][0], p[1][0][1], '*', markerfacecolor='r', markeredgecolor='g',
- markersize=14)
- plt.title('kmeansByPySpark')
- plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
得到的结果如下:
图中,圆圈是原始类别,五角星是通过聚类学习到的类别,可以看到聚类完全正确。

flatMap(f)
flatMap的用法与map类似,只不过map是一个输入元素对应一个输出元素,而flatMap一个输入元素对应多个输出元素。
- from pyspark import SparkContext
- sc=SparkContext()
- x=sc.parallelize([1,2,3])
- xFM1=x.flatMap(lambda x:(x,x*100,x**2))
- xFM2=x.flatMap(lambda x:[x,x*100,x**2])
- xFM3=x.flatMap(lambda x:(x,(x*100,x**2)))
- print(x.collect())
- print(xFM1.collect())
- print(xFM2.collect())
- print(xFM3.collect())
- #结果如下:
- #[1, 2, 3]
- #[1, 100, 1, 2, 200, 4, 3, 300, 9]
- #[1, 100, 1, 2, 200, 4, 3, 300, 9]
- #[1, (100, 1), 2, (200, 4), 3, (300, 9)]
- #所以不管是组合成一个元组,还是组合成一个列表,最后都会把里面的每一个单元当成是输出rdd的一个元素,这就是一对多;但是里面的单元只深入到第一层,不会继续拆分,否则就无法控制。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
mapValues(f)
将键值对形式的rdd的值用函数f来作用,而保持键不变,同时分区不变。
flatMapValues(f)[source]
综合flatMap和mapValues的特点。
mapPartitions(f, preservesPartitioning=False)
与map不同,map是对每一个元素用函数作用;而mapPartitions是对每一个分区用一个函数去作用,每一个分区的元素先构成一个迭代器iterator,iterator是一个像列表,但里面的元素又保持分布式特点的一类对象;输入的参数就是这个iterator,然后对iterator进行运算,iterator支持的函数不是太多,sum,count等一些spark定义的基本函数应该都是支持的。但如果要进行更为复杂的一些个性化函数运算,可以就用不了。实践中发生可以通过[x for i in iterator]的方式,将iterator转换为列表,然后就可以进行各种操作。但是这样在分区内部或分组内部就失去了分布式运算的特点。
- x=sc.parallelize([1,2,3],2)
- def f(iterator):yield sum(iterator)
- xMP=x.mapPartitions(f)
- print(x.glom().collect())
- print(xMP.glom().collect())
- #结果为:
- #[[1], [2, 3]]
- #[[1], [5]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
mapPartitionsWithIndex
与mapPartition相比,mapPartitionWithIndex能够保留分区索引,函数的传入参数也是分区索引和iterator构成的键值对。给了我们操作分区索引的机会,至于最后的结果要不要保留分区索引那是另一回事。
- x=sc.parallelize([1,2,3],2)
- def f1(partitionIndex,iterator):yield (partitionIndex,sum(iterator))
- def f2(partitionIndex,iterator):yield sum(iterator)
- xMP1=x.mapPartitionsWithIndex(f1)
- xMP2=x.mapPartitionsWithIndex(f2)
- print(x.glom().collect())
- print(xMP1.glom().collect())
- print(xMP2.glom().collect())
- #结果为:
- #[[1], [2, 3]]
- #[[(0, 1)], [(1, 5)]]
- #[[1], [5]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
partitionBy(numPartitions, partitionFunc=)
按给定的分区数和映射方法进行分区
- pairs = sc.parallelize([1, 2, 3, 4, 2, 4, 1]).map(lambda x: (x, x))
- print(pairs.collect())
- sets = pairs.partitionBy(2).glom().collect()
- print(sets)
- 1
- 2
- 3
- 4
结果如下:
- [(1, 1), (2, 2), (3, 3), (4, 4), (2, 2), (4, 4), (1, 1)]
- [[(4, 4), (2, 2), (4, 4), (2, 2)], [(1, 1), (3, 3), (1, 1)]]
- 1
- 2
rdd.coalesce(numPartitions,shuffle=none)
按时新的分区数重新分区
- print(sc.parallelize([1,2,3,4,5,6],3).glom().collect())
- print(sc.parallelize([1,2,3,4,5,6],3).coalesce(2).glom().collect())
- 1
- 2
结果如下:
- [[1, 2], [3, 4], [5, 6]]
- [[1, 2], [3, 4, 5, 6]]
- 1
- 2
rdd.repartition(numPartitions)
按时新的分区数重新分区
rdd.zip(other)
将第一个rdd的元素作用键,第二个rdd的元素作为值,组成新rdd的元素。
- x=sc.parallelize(['B','A','A'])
- y=x.map(lambda x:ord(x))
- z=x.zip(y)
- print(x.collect())
- #结果为:['B', 'A', 'A']
- print(y.collect())
- #结果为:[66, 65, 65]
- print(z.collect())
- #结果为:[('B', 66), ('A', 65), ('A', 65)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd.zipWithIndex()
将rdd的元素作键,索引(可以理解为看到的位置索引)作为值,组成新rdd的元素。
- x=sc.parallelize(['B','A','A'],2)
- y=x.zipWithIndex()
- print(x.collect())
- print(y.collect())
- #结果为:[['B'], ['A', 'A']]
- #结果为:[[('B', 0)], [('A', 1), ('A', 2)]]
- 1
- 2
- 3
- 4
- 5
- 6
rdd.zipWithUniqueId()
将rdd的元素作键,按公式算出的值作为值,组成新rdd的元素。
Zips this RDD with generated unique Long ids.
Items in the kth partition will get ids k, n+k, 2*n+k, …, where n is the number of partitions. So there may exist gaps, but this method won’t trigger a spark job, which is different from zipWithIndex
rdd.keyBy(f)
为rdd中的每个元素按照函数f生成一个键,新rdd的元素以元组形式存在。
- x=sc.parallelize([1,2,3])
- y=x.keyBy(lambda x:x**2)
- print(x.collect())
- #结果为[1, 2, 3]
- print(y.collect())
- #结果为[(1, 1), (4, 2), (9, 3)]
- 1
- 2
- 3
- 4
- 5
- 6
rdd.foreach(f)
对RDD中的每个元素使用函数来作用,由于是直接对每个元素操作并产生结果,所以得到的结果不是rdd,而是普通python对象。这与foreachPartition不同。
- from pyspark import SparkContext
- sc=SparkContext()
- rdd_data=sc.parallelize([1,2,3,4,5],2)
- print(rdd_data.glom().collect())
- def f(x):
- print(x)
- list_new=rdd_data.foreach(f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
- [[1, 2], [3, 4, 5]]
- 3
- 4
- 5
- 1
- 2
- 1
- 2
- 3
- 4
- 5
- 6
一个将rdd元素逐个写到文件中的例子:
- inputData=sc.parallelize([1,2,3])
- def f(x):#定义一个将内容追加于文件末尾的函数
- with open('./example.txt','a+') as fl:
- print(x,file=fl)
-
- open('./example.txt','w').close()#操作之前先关闭之前可能存在的对该文件的写操作
- y=inputData.foreach(f)
- print(y)
- #结果为:None,因为函数f没有返回值
- #查看写文件的结果
- with open('./example.txt') as fl:
- print(fl.read())
- #结果为:
- '''
- 1
- 2
- 3
- '''
- #说明每一个元素都被写到文件'./example.txt'中去了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
rdd.foreachpartition
对RDD的每一个分区使用函数来作用
- from pyspark import SparkContext
- sc=SparkContext()
- rdd_data=sc.parallelize([1,2,3,4,5],2)
- print(rdd_data.glom().collect())
- def f(iterator):
- for x in iterator:
- print(x)
- list_new=rdd_data.foreachPartition(f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果如下:
- [[1, 2], [3, 4, 5]]
- 1
- 3
- 2
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- 6
写分区内容的例子
- inputData=sc.parallelize([1,2,3],5)
- print(inputData.glom().collect())
- #结果为:
- #[[], [1], [], [2], [3]]
- def f(x):#定义一个将内容追加于文件末尾的函数
- with open('./example.txt','a+') as fl:
- print(list(x),file=fl)#先对分区序列进行转化再写入到文件中
-
- open('./example.txt','w').close()#操作之前先关闭之前可能存在的对该文件的写操作
- y=inputData.foreachPartition(f)
- print(y)
- #结果为:None,因为函数f没有返回值
- #查看写文件的结果
- with open('./example.txt') as fl:
- print(fl.read())
- #结果为:
- '''
- []
- []
- [2]
- [1]
- [3]
- '''
- #说明每一个分区序列都被写到文件'./example.txt'中去了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
rdd.groupByKey(numPartitions=None, partitionFunc=)
原rdd为键值对,groupByKey()则将原rdd的元素相同键的值编进一个sequence(不知道与list和iterator的不同有多大,可以暂时当成iterator看)
- rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- rddGp=rdd.groupByKey()
- print(rdd.collect())
- print(rddGp.collect())
- #结果如下:
- #[('a', 1), ('b', 1), ('a', 1)]
- #[('a', <pyspark.resultiterable.ResultIterable object at 0x7fe1e3f88710>), ('b', <pyspark.resultiterable.ResultIterable object at 0x7fe1e3f88668>)]
- #从结果看,确实是将键相同的值编到一个序列里了,但类型很奇怪。这样看没有什么用处。但是后面可以接其他函数,一般都接mapValues(f),这样就可以完成按对值的一些操作。
- def f(x):
- a=list(x)#直接使用x会报错,说明sequence并不能用for
- for i in range(len(a)):
- a[i]=a[i]*2
- return a
-
- gpMp1=rddGp.mapValues(len)
- gpMp2=rddGp.mapValues(list)
- gpMp3=rddGp.mapValues(f)
- print(gpMp1.collect())
- print(gpMp2.collect())
- print(gpMp3.collect())
- #结果如下:
- #[('a', 2), ('b', 1)],按键计算对应值的个数
- #[('a', [1, 1]), ('b', [1])],按键将值转换成列表形式
- #[('a', [2, 2]), ('b', [2])],通过自定义函数可以按键对值实现更复杂的操作。
- #groupByKey()+mapValues()与reduceByKey()的过程很像,但两者运行效率相差很大,在能够用reduceByKey()或aggregateByKey的时候,尽量不要用groupByKey()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
groupByKey()和flatPapValues()综合应用
rdd.groupBy(f, numPartitions=None, partitionFunc=)
groupBy()的用法与groupByKey相似,但传入参数多了f,传入的函数f可以把它当成用来生成新的key的。它也围绕这个潜在的key将值编进一个序列。可以看得出来,它比groupByKey更灵活。
- rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
- result=rdd.groupBy(lambda x:x%2)#按余数来分组
- #后面紧接着一般是mapValues函数做进一步处理,这里我们直接获取该数据而不做进一步处理。
- print(result.collect())
- #结果如下
- [(0, <pyspark.resultiterable.ResultIterable object at 0x7f336e26f550>), (1, <pyspark.resultiterable.ResultIterable object at 0x7f336e26f6a0>)]
- #所以要用for函数或在mapValues内部用list将pyspark.resultiterable.ResultIterable object转换出来
- resultGp=[(x,sorted(y)) for (x,y) in result.collect()]
- print(resultGp)
- #结果如下:
- [(0, [2, 8]), (1, [1, 1, 3, 5])]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
rdd.reduce(f)
reduce函数是将rdd中的每个元素两两之间按函数f进行操作,然后再结果再两两之间按f进行操作,一直进行下去,即所谓的shuffle过程。reduce得到的结果是普通的python对象,而不是rdd.
rdd.keys()
原rdd的元素为键值对,返回原rdd元素的键为元素的rdd
rdd.values()
原rdd的元素为键值对,返回原rdd元素的值为元素的rdd
rdd.reduceByKey(func, numPartitions=None, partitionFunc=)
reduceByKey函数与reduce相似,但它是按key分组,在组内,将元素两两之间按函数f操作。可以看成是将value参数传入了,但最终结果又不丢失key的信息。更详细的使用,可参考上面介绍map函数时的例子。reduceByKey得到的结果是普通的python对象,而不是rdd.
rdd.reduceByKeyLocally(f)
其他与reduceByKey一样,只不过聚合后立即将键,值对以字典的形式传给到集群master
- from operator import add
- inputRdd=sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- rddRBKL=inputRdd.reduceByKeyLocally(add)
- print(inputRdd.collect())
- #结果为:[('a', 1), ('b', 1), ('a', 1)]
- print(rddRBKL)
- #结果为:{'a': 2, 'b': 1}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
fold(zeroValue, op)[source]
与partitionBy很像,只不过有一个起始值。fold函数是按分区对每个元素进行操作,即先每个元素与起始值按op进行操作,得到的结果再两两之间按op操作,一直进行下去得到分区结果,然后再将分区结果按op操作。
- >>> from operator import add
- >>> x=sc.parallelize([1,2,3],2)
- >>> y=x.fold(1,lambda valueInitial,accumulated:accumulated+valueInitial)#这里的valueInitial,accumulated可以随便取名字,只表示输入
- print(x.collect())
- #结果为:[1, 2, 3]
- >>> print(y)
- #结果为9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
关于python内置操作op有哪些,可以使用help(‘operator’)进行查询,operator是一个专门的模块。这个模块是mapValues(f),reduce(),aggregate()等相似功能函数都能使用的。详细列举如下:
- Help on module operator:
-
- NAME
- operator - Operator interface.
-
- DESCRIPTION
- This module exports a set of functions implemented in C corresponding
- to the intrinsic operators of Python. For example, operator.add(x, y)
- is equivalent to the expression x+y. The function names are those
- used for special methods; variants without leading and trailing
- '__' are also provided for convenience.
-
- CLASSES
- builtins.object
- attrgetter
- itemgetter
- methodcaller
-
- class attrgetter(builtins.object)
- | attrgetter(attr, ...) --> attrgetter object
- |
- | Return a callable object that fetches the given attribute(s) from its operand.
- | After f = attrgetter('name'), the call f(r) returns r.name.
- | After g = attrgetter('name', 'date'), the call g(r) returns (r.name, r.date).
- | After h = attrgetter('name.first', 'name.last'), the call h(r) returns
- | (r.name.first, r.name.last).
- |
- | Methods defined here:
- |
- | __call__(self, /, *args, **kwargs)
- | Call self as a function.
- |
- | __getattribute__(self, name, /)
- | Return getattr(self, name).
- |
- | __new__(*args, **kwargs) from builtins.type
- | Create and return a new object. See help(type) for accurate signature.
- |
- | __reduce__(...)
- | Return state information for pickling
- |
- | __repr__(self, /)
- | Return repr(self).
-
- class itemgetter(builtins.object)
- | itemgetter(item, ...) --> itemgetter object
- |
- | Return a callable object that fetches the given item(s) from its operand.
- | After f = itemgetter(2), the call f(r) returns r[2].
- | After g = itemgetter(2, 5, 3), the call g(r) returns (r[2], r[5], r[3])
- |
- | Methods defined here:
- |
- | __call__(self, /, *args, **kwargs)
- | Call self as a function.
- |
- | __getattribute__(self, name, /)
- | Return getattr(self, name).
- |
- | __new__(*args, **kwargs) from builtins.type
- | Create and return a new object. See help(type) for accurate signature.
- |
- | __reduce__(...)
- | Return state information for pickling
- |
- | __repr__(self, /)
- | Return repr(self).
-
- class methodcaller(builtins.object)
- | methodcaller(name, ...) --> methodcaller object
- |
- | Return a callable object that calls the given method on its operand.
- | After f = methodcaller('name'), the call f(r) returns r.name().
- | After g = methodcaller('name', 'date', foo=1), the call g(r) returns
- | r.name('date', foo=1).
- |
- | Methods defined here:
- |
- | __call__(self, /, *args, **kwargs)
- | Call self as a function.
- |
- | __getattribute__(self, name, /)
- | Return getattr(self, name).
- |
- | __new__(*args, **kwargs) from builtins.type
- | Create and return a new object. See help(type) for accurate signature.
- |
- | __reduce__(...)
- | Return state information for pickling
- |
- | __repr__(self, /)
- | Return repr(self).
-
- FUNCTIONS
- __abs__ = abs(...)
- abs(a) -- Same as abs(a).
-
- __add__ = add(...)
- add(a, b) -- Same as a + b.
-
- __and__ = and_(...)
- and_(a, b) -- Same as a & b.
-
- __concat__ = concat(...)
- concat(a, b) -- Same as a + b, for a and b sequences.
-
- __contains__ = contains(...)
- contains(a, b) -- Same as b in a (note reversed operands).
-
- __delitem__ = delitem(...)
- delitem(a, b) -- Same as del a[b].
-
- __eq__ = eq(...)
- eq(a, b) -- Same as a==b.
-
- __floordiv__ = floordiv(...)
- floordiv(a, b) -- Same as a // b.
-
- __ge__ = ge(...)
- ge(a, b) -- Same as a>=b.
-
- __getitem__ = getitem(...)
- getitem(a, b) -- Same as a[b].
-
- __gt__ = gt(...)
- gt(a, b) -- Same as a>b.
-
- __iadd__ = iadd(...)
- a = iadd(a, b) -- Same as a += b.
-
- __iand__ = iand(...)
- a = iand(a, b) -- Same as a &= b.
-
- __iconcat__ = iconcat(...)
- a = iconcat(a, b) -- Same as a += b, for a and b sequences.
-
- __ifloordiv__ = ifloordiv(...)
- a = ifloordiv(a, b) -- Same as a //= b.
-
- __ilshift__ = ilshift(...)
- a = ilshift(a, b) -- Same as a <<= b.
-
- __imatmul__ = imatmul(...)
- a = imatmul(a, b) -- Same as a @= b.
-
- __imod__ = imod(...)
- a = imod(a, b) -- Same as a %= b.
- __imul__ = imul(...)
- a = imul(a, b) -- Same as a *= b.
- __index__ = index(...)
- index(a) -- Same as a.__index__()
- __inv__ = inv(...)
- inv(a) -- Same as ~a.
- __invert__ = invert(...)
- invert(a) -- Same as ~a.
- __ior__ = ior(...)
- a = ior(a, b) -- Same as a |= b.
- __ipow__ = ipow(...)
- a = ipow(a, b) -- Same as a **= b.
- __irshift__ = irshift(...)
- a = irshift(a, b) -- Same as a >>= b.
- __isub__ = isub(...)
- a = isub(a, b) -- Same as a -= b.
- __itruediv__ = itruediv(...)
- a = itruediv(a, b) -- Same as a /= b
- __ixor__ = ixor(...)
- a = ixor(a, b) -- Same as a ^= b.
- __le__ = le(...)
- le(a, b) -- Same as a<=b.
- __lshift__ = lshift(...)
- lshift(a, b) -- Same as a << b.
- __lt__ = lt(...)
- lt(a, b) -- Same as a<b.
- __matmul__ = matmul(...)
- matmul(a, b) -- Same as a @ b.
- __mod__ = mod(...)
- mod(a, b) -- Same as a % b.
-
- __mul__ = mul(...)
- mul(a, b) -- Same as a * b.
-
- __ne__ = ne(...)
- ne(a, b) -- Same as a!=b.
-
- __neg__ = neg(...)
- neg(a) -- Same as -a.
-
- __not__ = not_(...)
- not_(a) -- Same as not a.
-
- __or__ = or_(...)
- or_(a, b) -- Same as a | b.
-
- __pos__ = pos(...)
- pos(a) -- Same as +a.
-
- __pow__ = pow(...)
- pow(a, b) -- Same as a ** b.
-
- __rshift__ = rshift(...)
- rshift(a, b) -- Same as a >> b.
-
- __setitem__ = setitem(...)
- setitem(a, b, c) -- Same as a[b] = c.
-
- __sub__ = sub(...)
- sub(a, b) -- Same as a - b.
-
- __truediv__ = truediv(...)
- truediv(a, b) -- Same as a / b.
-
- __xor__ = xor(...)
- xor(a, b) -- Same as a ^ b.
-
- abs(...)
- abs(a) -- Same as abs(a).
-
- add(...)
- add(a, b) -- Same as a + b.
-
- and_(...)
- and_(a, b) -- Same as a & b.
-
- concat(...)
- concat(a, b) -- Same as a + b, for a and b sequences.
-
- contains(...)
- contains(a, b) -- Same as b in a (note reversed operands).
-
- countOf(...)
- countOf(a, b) -- Return the number of times b occurs in a.
-
- delitem(...)
- delitem(a, b) -- Same as del a[b].
-
- eq(...)
- eq(a, b) -- Same as a==b.
-
- floordiv(...)
- floordiv(a, b) -- Same as a // b.
-
- ge(...)
- ge(a, b) -- Same as a>=b.
-
- getitem(...)
- getitem(a, b) -- Same as a[b].
-
- gt(...)
- gt(a, b) -- Same as a>b.
-
- iadd(...)
- a = iadd(a, b) -- Same as a += b.
-
- iand(...)
- a = iand(a, b) -- Same as a &= b.
-
- iconcat(...)
- a = iconcat(a, b) -- Same as a += b, for a and b sequences.
-
- ifloordiv(...)
- a = ifloordiv(a, b) -- Same as a //= b.
-
- ilshift(...)
- a = ilshift(a, b) -- Same as a <<= b.
-
- imatmul(...)
- a = imatmul(a, b) -- Same as a @= b.
-
- imod(...)
- a = imod(a, b) -- Same as a %= b.
- imul(...)
- a = imul(a, b) -- Same as a *= b.
- index(...)
- index(a) -- Same as a.__index__()
- indexOf(...)
- indexOf(a, b) -- Return the first index of b in a.
- inv(...)
- inv(a) -- Same as ~a.
- invert(...)
- invert(a) -- Same as ~a.
- ior(...)
- a = ior(a, b) -- Same as a |= b.
- ipow(...)
- a = ipow(a, b) -- Same as a **= b.
- irshift(...)
- a = irshift(a, b) -- Same as a >>= b.
- is_(...)
- is_(a, b) -- Same as a is b.
- is_not(...)
- is_not(a, b) -- Same as a is not b.
- isub(...)
- a = isub(a, b) -- Same as a -= b.
- itruediv(...)
- a = itruediv(a, b) -- Same as a /= b
- ixor(...)
- a = ixor(a, b) -- Same as a ^= b.
- le(...)
- le(a, b) -- Same as a<=b.
- length_hint(...)
- length_hint(obj, default=0) -> int
- Return an estimate of the number of items in obj.
- This is useful for presizing containers when building from an
- iterable.
- If the object supports len(), the result will be
- exact. Otherwise, it may over- or under-estimate by an
- arbitrary amount. The result will be an integer >= 0.
- lshift(...)
- lshift(a, b) -- Same as a << b.
- lt(...)
- lt(a, b) -- Same as a<b.
- matmul(...)
- matmul(a, b) -- Same as a @ b.
- mod(...)
- mod(a, b) -- Same as a % b.
-
- mul(...)
- mul(a, b) -- Same as a * b.
-
- ne(...)
- ne(a, b) -- Same as a!=b.
-
- neg(...)
- neg(a) -- Same as -a.
-
- not_(...)
- not_(a) -- Same as not a.
-
- or_(...)
- or_(a, b) -- Same as a | b.
-
- pos(...)
- pos(a) -- Same as +a.
-
- pow(...)
- pow(a, b) -- Same as a ** b.
-
- rshift(...)
- rshift(a, b) -- Same as a >> b.
-
- setitem(...)
- setitem(a, b, c) -- Same as a[b] = c.
-
- sub(...)
- sub(a, b) -- Same as a - b.
-
- truediv(...)
- truediv(a, b) -- Same as a / b.
-
- truth(...)
- truth(a) -- Return True if a is true, False otherwise.
-
- xor(...)
- xor(a, b) -- Same as a ^ b.
-
- DATA
- __all__ = ['abs', 'add', 'and_', 'attrgetter', 'concat', 'contains', '...
- FILE
- c:\users\csw\miniconda2\envs\guanwang\lib\operator.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
foldByKey(zeroValue, func, numPartitions=None, partitionFunc=)[source]
foldByKey的操作与fold几乎一样,只不过前者按键来分组,后者按分区分组,前者不同键不再进一步操作,后者不同分区结果还会进一步操作。foldByKey最终结果也是普通python对象,而不是rdd。一个键占一个元组的空间,存放在list中。
- >>> from operator import add
- >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- >>> rddFB=sorted(rdd.foldByKey(1, add).collect())
- >>> print(rdd.collect())
- #结果为:[('a', 1), ('b', 1), ('a', 1)]
- >>> print(rddFB)
- #结果为:[('a', 4), ('b', 2)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
RDD.aggregate(zeroValue, seqOp, combOp)
aggregate与fold相似又很不同。
seqOp操作会聚合各分区中的元素,然后combOp操作把所有分区的聚合结果再次聚合,两个操作的初始值都是zeroValue. seqOp的操作是遍历分区中的所有元素(T),zeroValue跟第一个T做操作,结果再作为与第二个T做操作的zeroValue,直到遍历完整个分区。combOp操作是把各分区聚合的结果,再聚合,zeroValue与第一个分区结果聚合,聚合结果相当于新的zeroValue,再与第二个分区结果聚合,一直进行下去。aggregate函数返回一个跟RDD不同类型的值。因此,需要一个操作seqOp来把分区中的元素T合并成一个U,另外一个操作combOp把所有U聚合。
- seqOp=(lambda x,y:(x[0]+y,x[1]+1))
- combOp=(lambda x,y:(x[0]+y[0],x[1]+y[1]))
- x=sc.parallelize([1,2,3,4,5,6],2)
- print(x.glom().collect())
- #结果为:[[1, 2, 3], [4, 5, 6]]
- y=x.aggregate((1,2),seqOp,combOp)
- print(y)
- #结果为:(24, 12)
-
- #计算过程如下:
- #(1,2)--》(1+1,2+1)-->(2+2,3+1)-->(4+3,4+1)-->(7,5);
- #(1,2)--》(1+4,2+1)-->(5+5,3+1)-->(10+6,4+1)-->(16,5);
- #(1,2)--》(1+7,2+5)-->(8+16,7+5)-->(24,12);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
RDD.aggregateByKey(zeroValue, seqFunc, combFunc, numPartitions=None, partitionFunc=)
aggregate是按分区进行,而aggregateByKey是按键来进行,但是zeroValue与aggregate中的用法很不一样,这里的zeroValue是一个值,它即可以跟这样键聚合,也可以跟那个键聚合,而且zeroValue必须与键内聚合时定义的形式一致。
- x=sc.parallelize([('B', 1), ('B', 2), ('B', 3), ('A', 4), ('A', 5),('A', 6)])
- zeroValue=[7]
- mergeVal=(lambda aggregated,el:aggregated+[(el,el**2)])
- mergeComb=(lambda agg1,agg2:agg1+agg2)
- y=x.aggregateByKey(zeroValue,mergeVal,mergeComb)
- print(x.collect())
- #结果为:[('B', 1), ('B', 2), ('B', 3), ('A', 4), ('A', 5), ('A', 6)]
- print(y.collect())
- #结果为:[('A', [7, (4, 16), (5, 25), (6, 36)]), ('B', [7, (1, 1), (2, 4), (3, 9)])]
- #计算过程如下:
- #('B', [7]);('B', (1,1**2))-->('B', [7,(1,1)])-->('B', [7,(1,1)]);('B', (2,2**2))-->('B', [7,(1,1),(2,4)])...-->[('B', [7, (1, 1), (2, 4), (3, 9)])]
- 同时'A'也进行这样的过程
- #[('B', [7, (1, 1), (2, 4), (3, 9)])];[('A', [7, (4, 16), (5, 25), (6, 36)])]-->[('A', [7, (4, 16), (5, 25), (6, 36)]), ('B', [7, (1, 1), (2, 4), (3, 9)])]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
combineByKey(createCombiner, mergeValue, mergeCombiners, numPartitions=None, partitionFunc=)
与foldByKey()的做法很相似,但是它没有初始值,而且可以定义多个环节的操作函数,所以功能会更加灵活。
createCombiner: V => C ,这个函数把各元素的值作为参数,此时我们可以对其做些附加操作(类型转换)并把它返回 (这一步类似于初始化操作),对当前值作一个变换,相当于map内部的函数。
mergeValue: (C, V) => C,该函数把元素多个元素值合并到一个元素值C(createCombiner)上 (这个操作在每个键内进行),这一步是定义怎么来合并同一个键对应的值。
mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同键间进行),在不同键之间进行合并
- sc=SparkContext()
- x=sc.parallelize([('a',1),('a',2),('b',1),('b',3),('c',5),('c',6)])
- def to_list(a):
- return [a]
- def append(a,b):
- a.append(b)
- return a
- def extend(a,b):
- a.extend(b)
- return a
- print(x.collect())
- print(x.combineByKey(to_list,append,extend).collect())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果如下:
- [('a', 1), ('a', 2), ('b', 1), ('b', 3), ('c', 5), ('c', 6)]
- [('c', [5, 6]), ('b', [3, 1]), ('a', [1, 2])]
- #计算过程如下:
- #('a', 1)-->('a', [1]);...;('c', 6)-->('c', [6])
- #('a', [1]);('a', [2])-->('a', [1,2]);...;-->('c', [5]);('c', [6])-->('c', [5,6])
- #('a', [1,2]);('b', [3, 1]);('c', [5,6])-->[('a', [1,2]),('b', [3, 1]),('c', [5,6])];当然这一结果并没有立即计算出来,而是定义了这种操作方法。
- 1
- 2
- 3
- 4
- 5
- 6
rdd.sortByKey()
首先rdd的元素需要为键值对,然后sortByKey()就能实现对每个元素按键的大小来排序
- x=sc.parallelize([('B',1),('A',2),('C',3)])
- y=x.sortByKey()
- print(x.collect())
- print(y.collect())
- #结果为
- #[('B', 1), ('A', 2), ('C', 3)]
- #[('A', 2), ('B', 1), ('C', 3)]
- #从结果可以看到默认是升序排列
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
rdd.sortBy()
- x=sc.parallelize(['Cut','Alice','Bat'])
- y=sc.parallelize([('a',2),('b',1),('c',0)])
- def f(x):
- return x[1]
- xS=x.sortBy(f)
- yS=y.sortBy(f)
- print(x.collect())
- print(xS.collect())
- print(y.collect())
- print(yS.collect())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果如下:
- ['Cut', 'Alice', 'Bat']
- ['Bat', 'Alice', 'Cut']
- [('a', 2), ('b', 1), ('c', 0)]
- [('c', 0), ('b', 1), ('a', 2)]
- 1
- 2
- 3
- 4
从上面可以看到,sortBy与sortByKey完成相似的功能,只不过sortBy比sortByKey更加的灵活,可以按不同维度来排序。
rdd.glom()
glom()定义了将原rdd相同分区的元素放在一个列表中构成新的rdd的转换操作。
rdd.collect()
返回由rdd元素组成的列表
rdd.collectAsMap()
将键值对形式的RDD以字典的形式返回给master
**
Note:
this method should only be used if the resulting data is expected to be small, as all the data is loaded into the driver’s memory. **
m=sc.parallelize([(1,2),(3,4)]).collectAsMap()- 1
结果如下:
{1: 2, 3: 4}- 1
rdd.stats()
lookup(key)[source]
Return the list of values in the RDD for key key. This operation is done efficiently if the RDD has a known partitioner by only searching the partition that the key maps to.
- 1
- 2
rdd.stats()
计算rdd中全体元素的均值、方差、最大值、最小值和个数的信息
- samp=sc.parallelize(1,2,3,4).stats()
- print(samp)
- 1
- 2
结果如下:
(count: 4, mean: 2.5, stdev: 1.11803398875, max: 4.0, min: 1.0)- 1
stats得到的对象为’StatCounter’ object
rdd.max()
计算rdd所有元素中的最大值。
rdd.first()[source]
计算rdd所有元素中第一个元素(未排序)。
- sc.parallelize([5, 3, 4]).first()
- #结果为:5
- 1
- 2
rdd.take(num)[source]
计算rdd所有元素中最前面的几个元素。
rdd.takeOrdered(num, key=None)
计算rdd所有元素中按升序排列后的最前面的几个元素。通过key可以实现降序或其他操作。
- inputData=sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7])
- inputTakeOrdered=inputData.takeOrdered(num=6)
- #结果为[1, 2, 3, 4, 5, 6]
- inputTakeOrdered2=inputData.takeOrdered(num=6,key=lambda x:-x)
- print(inputTakeOrdered2)
- #结果为:[10, 9, 7, 6, 5, 4]
- 1
- 2
- 3
- 4
- 5
- 6
rdd.top(num, key=None)[source]
计算rdd所有元素按降序排列后最顶部的几个元素。如果元素为数据型或可以转换为数值型的,就是值最大的几个元素。
rdd.min ()
计算rdd所有元素中的最小值。
rdd.mean()
计算rdd所有元素均值
- mean_test=sc.parallelize([1,2,3,4]).mean()
- print(mean_test)
- 1
- 2
结果如下:
2.5- 1
rdd.variance()
计算rdd元素的方差,# divides by N
rdd.stdev()
计算标准差, # divides by N
- stdev_test=sc.parallelize([1,2,3,4]).stdev()
- print(stdev_test)
- 1
- 2
结果如下:
1.11803398875- 1
rdd.sampleVariance()
计算rdd元素的方差,# divides by N-1
rdd.sampleStdev()
计算标准差, # divides by N-1
rdd.sum ()
计算rdd所有元素之和
rdd.count()
计算rdd所有元素个数
rdd.countByValue()
统计rdd所有元素中各元素的个数
- inputData=sc.parallelize([1,3,1,2,3])
- inputCountBV=inputData.countByValue()
- print(inputCountBV)
- #结果为:defaultdict(<class 'int'>, {1: 2, 2: 1, 3: 2})
- 1
- 2
- 3
- 4
rdd.countByKey()
按键为组统计rdd元素的个数
- >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- >>> sorted(rdd.countByKey().items())
- [('a', 2), ('b', 1)]
- 1
- 2
- 3
rdd.histogram(buckets)
对rdd中的元素进行频数统计,统计区间有两种,一种是给出段数,一种是直接给出区间。需要注意的是:The buckets are all open to the right except for the last which is closed. e.g. [1,10,20,50] means the buckets are [1,10) [10,20) [20,50], which means 1<=x<10, 10<=x<20, 20<=x<=50。返回的结果为普通python对象list,包含:对应的区间和频率数。
- inputData=sc.parallelize([1,3,1,2,3])
- inputHB1=inputData.histogram(buckets=2)
- print(inputHB1)
- #结果:([1, 2, 3], [2, 3])
- inputHB2=inputData.histogram([0,0.5,1,1.5,2,2.5,3,3.5])
- print(inputHB2)
- #结果:([0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5], [0, 0, 2, 0, 1, 0, 2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
pipe(command, env=None, checkCode=False)
通过管道向后面环节输出command处理过的结果,具体功能就体现在command,command为linux命令。
比如打印结果
- print(sc.parallelize(['1', '2', '', '3']).pipe('cat').collect())#pipe函数中的'cat'为linux命令,表示打印内容。
- #结果如下:
- #['1', '2', '', '3']
- 1
- 2
- 3
再比如正则匹配来筛选
- >>> x=sc.parallelize(['A','Ba','C','DA'])
- >>> y=x.pipe('grep -i "A"')
- >>> print(x.collect())
- >>> print(y.collect())
- #结果为:['A', 'Ba', 'C', 'DA']
- #['A', 'Ba', 'DA']
- 1
- 2
- 3
- 4
- 5
- 6
rdd.filter(f)
- x=sc.parallelize([1,2,3],2)
- xFt=x.filter(lambda x:x%2==1)#过滤掉被2整除的数
- print(x.collect())
- print(xFt.collect())
- #结果为:
- #[1, 2, 3]
- #[1, 3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
distinct()
对RDD中的元素进行去重
- >>> sorted(sc.parallelize([1, 1, 2, 3]).distinct().collect())
- [1, 2, 3]
- 1
- 2
- x=sc.parallelize([('a',1),('b',2),('a',3),('b',2)])
- xDist=x.distinct()#元素本身必须是可hash映射的,否则会出错,比如列表就不行,而元组可以,同时完全一样才会被过滤掉
- print(x.collect())
- print(xDist.collect())
- #结果如下:
- #[('a', 1), ('b', 2), ('a', 3), ('b', 2)]
- #[('b', 2), ('a', 3), ('a', 1)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
sample(withReplacement, fraction, seed=None)
按一定比例对原样本进行抽样,如何控制抽样后的元素个数还要研究一下。
- x=sc.parallelize(range(7))
- print('x=%s'%(x.collect()))
- xSamList=[x.sample(withReplacement=False,fraction=0.5) for i in range(5)]#xSamList这个列表的元素是rdd,而每个rdd又是由一系列元素构成。
- for i in range(len(xSamList)):
- print('Sample%s:y=%s'%(i,xSamList[i].collect()))
- #结果如下:
- #x=[0, 1, 2, 3, 4, 5, 6]
- #Sample0:y=[2, 3, 5]
- #Sample1:y=[0, 2, 4, 6]
- #Sample2:y=[0, 3, 4, 5, 6]
- #Sample3:y=[0, 2, 4, 5]
- #Sample4:y=[3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
rdd.takeSample(withReplacement, num, seed=None)
以指定的随机种子随机抽样出数量为num的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样
(例如):从RDD中随机且有放回的抽出num个数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
takeSample()函数和sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行collect(),返回结果的集合为单机的数组。
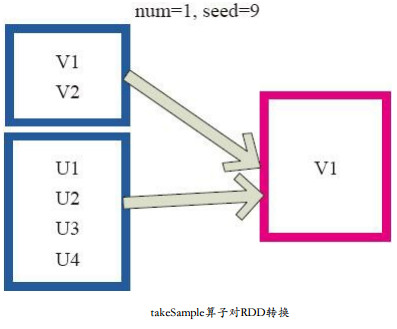
- >>> rdd = sc.parallelize(range(0, 10))
- >>> print(rdd.collect())
- [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- >>> print(rdd.takeSample(True, 20, 1))
- [4, 0, 9, 2, 7, 6, 4, 9, 1, 3, 5, 0, 9, 1, 5, 6, 7, 7, 1, 7]
- #结果为20,因为是有放回取样
- >>> print(rdd.takeSample(False, 5, 2))
- [4, 1, 6, 2, 3]
- >>> print(rdd.takeSample(False, 15, 3))
- [1, 5, 7, 6, 0, 3, 8, 9, 4, 2]
- #总共10个元素无放回抽15,顶了天也就是把所有的元素都取回来。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
rdd.sampleByKey(withReplacement, fractions, seed=None)
按照key来取样
rdd1.union(rdd2)
合并不同rdd中的元素,不去重
- x=sc.parallelize(range(4))
- y=sc.parallelize(range(3,6))
- z=sc.parallelize([('a',1),('b',2)])
- u1=x.union(y)
- u2=x.union(z)
- print(x.collect())
- print(y.collect())
- print(u1.collect())
- print(u2.collect())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果如下:
- [0, 1, 2, 3]
- [3, 4, 5]
- [0, 1, 2, 3, 3, 4, 5]
- [0, 1, 2, 3, ('a', 1), ('b', 2)]
- 1
- 2
- 3
- 4
可以看到union即可以合并相同的元素类型,也可以合并不同元素类型,对元素不去重。
rdd1.intersection(rdd2)
获取两个rdd共同的元素
- x=sc.parallelize(range(4))
- y=sc.parallelize(range(3,6))
- z=sc.parallelize([('a',1),('b',2)])
- i1=x.intersection(y)
- i2=x.intersection(z)
- print(x.collect())
- print(y.collect())
- print(i1.collect())
- print(i2.collect())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果如下:
- [0, 1, 2, 3]
- [3, 4, 5]
- [3]
- []
- 1
- 2
- 3
- 4
rdd.subtract(other, numPartitions=None)
移除第一个rdd中同时存在第二个rdd中的元素。
- x=sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
- y=sc.parallelize([('C',8),('A',2),('D',1)])
- z=x.subtract(y)
- print(x.collect())
- #结果为:[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
- print(y.collect())
- #结果为:[('C', 8), ('A', 2), ('D', 1)]
- print(z.collect())
- #结果为:[('A', 1), ('C', 4), ('B', 3)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd.subtractByKey(other, numPartitions=None)
如果第一个rdd的元素其键存在第二个rdd中的,则移除这样的元素,获得新的rdd。
- x=sc.parallelize([('C',1),('B',2),('A',3),('A',4)])
- y=sc.parallelize([('A',5),('D',6),('A',7),('D',8)])
- z=x.subtractByKey(y)
- print(x.collect())
- #结果为:[('C', 1), ('B', 2), ('A', 3), ('A', 4)]
- print(y.collect())
- #结果为:[('A', 5), ('D', 6), ('A', 7), ('D', 8)]
- print(z.collect())
- #结果为:[('C', 1), ('B', 2)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd.cartesian(other)
计算一个rdd与另一个rdd的迪卡尔积,结果中的元素为(a,b),其中 a,b分别是第一个rdd和第二个rdd中的元素。
- x=sc.parallelize([('a',1),'b'])
- y=sc.parallelize(['c',['d',2]])
- z=x.cartesian(y)
- print(x.collect())
- print(y.collect())
- print(z.collect())
- 1
- 2
- 3
- 4
- 5
- 6
结果如下:
- [('a', 1), 'b']
- ['c', ['d', 2]]
- [(('a', 1), 'c'), (('a', 1), ['d', 2]), ('b', 'c'), ('b', ['d', 2])]
- 1
- 2
- 3
rdd1.join(rdd2)
跟mysql中的leftjoin有点像,但有键的概念。
用rdd1中的键去rdd2中寻找与之键相同的元组,然后将两者的放在一个元组构成与原键对应的新的值,形式为 (k, (v1, v2));如果在rdd2中找不到相同的键,那么为空,不出现在最终的结果里。
- x = sc.parallelize([("a", 1), ("b", 4)])
- y = sc.parallelize([("a", 2), ("a", 3)])
- z=x.join(y)
- print(x.collect())
- #结果为[('a', 1), ('b', 4)]
- print(y.collect())
- #结果为[('a', 2), ('a', 3)]
- print(z.collect())
- #结果为[('a', (1, 2)), ('a', (1, 3))]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd1.leftOuterJoin(rdd2, numPartitions=None)
与join功能相似,不同的是如果在第二rdd找不到相同的key,则其值用None代替。
- x = sc.parallelize([("a", 1), ("b", 4)])
- y = sc.parallelize([("a", 2), ("a", 3)])
- z=x.leftOuterJoin(y)
- print(x.collect())
- #结果为[('a', 1), ('b', 4)]
- print(y.collect())
- #结果为[('a', 2), ('a', 3)]
- print(z.collect())
- #结果为[('b', (4, None)), ('a', (1, 2)), ('a', (1, 3))]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd1.rightOuterJoin(rdd2, numPartitions=None)
就是用第二个rdd的key去第一个rdd中寻找,在value组合的时候还是第一个rdd的值在前,第二个rdd的值在后。其他与leftOuterJoin完全一样。
- x = sc.parallelize([("a", 1), ("b", 4)])
- y = sc.parallelize([("a", 2), ("a", 3)])
- z=x.rightOuterJoin(y)
- print(x.collect())
- #结果为[('a', 1), ('b', 4)]
- print(y.collect())
- #结果为[('a', 2), ('a', 3)]
- print(z.collect())
- #结果为[('a', (1, 3)), ('a', (1, 2))]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rdd.cogroup(other,numPartitions=none)
先在rdd内部按键将值编进一个可迭代序列;然后将一个rdd或另一个rdd中的键作为元组的第一个元素,双方与该键对应的迭代序列组成的元组作为第二个元素,如果某一方中不存在与该键对应的值,则元组的对应位置用空列表表示。形成这样一个按键组合双方值的新rdd。
- x=sc.parallelize([('C',4),('B',(3,3)),('A',2),('A',(1,1))])
- y=sc.parallelize([('A',8),('B',7),('A',6),('D',(5,5))])
- z=x.cogroup(y)
- print(x.collect())
- #结果为:[('C', 4), ('B', (3, 3)), ('A', 2), ('A', (1, 1))]
- print(y.collect())
- #结果为:[('A', 8), ('B', 7), ('A', 6), ('D', (5, 5))]
- print(z.collect())
- #结果为:[('A', (<pyspark.resultiterable.ResultIterable object at 0x7fbda3be4908>, <pyspark.resultiterable.ResultIterable object at 0x7fbda3be4b70>)), ('C', (<pyspark.resultiterable.ResultIterable object at 0x7fbda3be4be0>, <pyspark.resultiterable.ResultIterable object at 0x7fbda3be4c88>)), ('B', (<pyspark.resultiterable.ResultIterable object at 0x7fbda3be4c50>, <pyspark.resultiterable.ResultIterable object at 0x7fbda3be4cf8>)), ('D', (<pyspark.resultiterable.ResultIterable object at 0x7fbda3be4c18>, <pyspark.resultiterable.ResultIterable object at 0x7fbda3be4cc0>))]
- #下面将pyspark.resultiterable.ResultIterable object 转换出来
- ResultIterableToList=[]
- for key,value in z.collect():
- ResultIterableToList.append((key,[list(i) for i in value]))
- print(ResultIterableToList)
- #结果为:[('A', [[2, (1, 1)], [8, 6]]), ('C', [[4], []]), ('B', [[(3, 3)], [7]]), ('D', [[], [(5, 5)]])]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
rdd.groupWith(other, *others)
groupWith是cogroup的增强版,可以同时处理多个rdd.
2、运行过程中的一些错误
2.1、
Exception: Randomness of hash of string should be disabled via PYTHONHASHSEED- 1
网上的解释
- Since Python 3.2.3+ hash of str, byte and datetime objects in Python is salted using random value to prevent certain kinds of denial-of-service attacks. It means that hash values are consistent inside single interpreter session but differ from session to session. PYTHONHASHSEED sets RNG seed to provide a consistent value between session.
-
- You can easily check this in your shell. If PYTHONHASHSEED is not set you'll get some random values:
- 1
- 2
- 3
大致意思是python3以上版本中,出于安全的考虑,在做hash映射的时候,对于字符串、字节和时间对象,即使是同一个值,不同时候映射值也不一样。这就会造成不同时候不同机器的映射关系不固定。解析就会出现问题。
解决方法:在不同机器上通过设置PYTHONHASHSEED将映射关系固定下来。
- #PYTHONHASHSEED的具体值自己随机选取,下面的方法还没验证
- # Set PYTHONHASHSEED locally
- echo "export PYTHONHASHSEED=0" >> /root/.bashrc
- source /root/.bashrc
-
- # Set PYTHONHASHSEED on all slaves
- pssh -h /root/spark-ec2/slaves 'echo "export PYTHONHASHSEED=0" >> /root/.bashrc'
-
- # Restart all slaves
- sh /root/spark/sbin/stop-slaves.sh
- sh /root/spark/sbin/start-slaves.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
同时还需要配置 Spark ./conf文件夹下spark-defaults.conf,将spark.executorEnv.PYTHONHASHSEED 0#具体值可以自己设置加入到上面的配置文件中。
2.2、
AttributeError: 'NoneType' object has no attribute '_jvm'- 1
原因可能是对象为空
3、spark中如何找到使用中位数
来源
解决方案
Spark 2.0+:
Python:
df.approxQuantile(“x”, [0.5], 0.25)
Scala:
df.stat.approxQuantile(“x”, Array(0.5), 0.25)
where the last parameter is a relative error. The lower the number the more accurate results and more expensive computation.
Spark < 2.0
如果数据量比较小,可如下操作:
- import numpy as np
- np.random.seed(323)
- rdd = sc.parallelize(np.random.randint(1000000, size=700000))
- np.median(rdd.collect())
- 1
- 2
- 3
- 4
数据量比较大时:
- from numpy import floor
- import time
-
- def quantile(rdd, p, sample=None, seed=None):
- """Compute a quantile of order p ∈ [0, 1]
- :rdd a numeric rdd
- :p quantile(between 0 and 1)
- :sample fraction of and rdd to use. If not provided we use a whole dataset
- :seed random number generator seed to be used with sample
- """
- assert 0 <= p <= 1
- assert sample is None or 0 < sample <= 1
-
- seed = seed if seed is not None else time.time()
- rdd = rdd if sample is None else rdd.sample(False, sample, seed)
-
- rddSortedWithIndex = (rdd.
- sortBy(lambda x: x).
- zipWithIndex().
- map(lambda (x, i): (i, x)).
- cache())
-
- n = rddSortedWithIndex.count()
- h = (n - 1) * p
-
- rddX, rddXPlusOne = (
- rddSortedWithIndex.lookup(x)[0]
- for x in int(floor(h)) + np.array([0L, 1L]))
-
- return rddX + (h - floor(h)) * (rddXPlusOne - rddX)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Language independent (Hive UDAF):
If you use HiveContext you can also use Hive UDAFs. With integral values:
- rdd.map(lambda x: (float(x), )).toDF(["x"]).registerTempTable("df")
-
- sqlContext.sql("SELECT percentile_approx(x, 0.5) FROM df")
- 1
- 2
- 3
With continuous values:
sqlContext.sql("SELECT percentile(x, 0.5) FROM df")
