
- 1条件随机场 (CRF) 的损失函数以及faiss 的原理介绍_crf损失函数
- 2PCA降维-原理(一)_pca降维原理
- 3几个学习LoRa的重要网站_lora模型网站
- 4Llama3-8B+ LLaMA-Factory 中文微调_llama3 factory
- 5台式计算机颜色如何矫正,win10电脑显示器颜色不对如何调整|win10系统校正显示器色调的三种方法...
- 6ChatGPT能预测未来特定事件,准确率高达97%
- 7简单几何算法集合comp.graphics.algorithms Frequently Asked Questions(转)_qhull求half space交集
- 8[激光原理与应用-74]:数据采集卡 - 数模转换芯片AD7606_高速数据采集adc
- 9selinux 基础知识
- 10掌握AI助手的魔法工具:解密Prompt(提示)在AIGC时代的应用「上篇」_aigc prompt
车辆ReIDの深度学习_veri-776
赞
踩
本文广泛探讨了应用于车辆ReID的深度学习技术。它概述了这些方法的分类,包括监督和无监督方法,深入研究这些类别中的现有研究,介绍数据集和评估标准,并阐明未来的挑战和潜在研究方向。文章全面的评估考察了深度学习在车辆ReID中的应用,并建立了未来工作的基础和起点。
车辆重识别(ReID)旨在将来自分布式网络摄像机拍摄的不同交通环境中的车辆图像进行关联。这项任务在以车辆为中心的技术领域中占据着至关重要的地位,在部署智能交通系统(ITS)和推进智慧城市倡议方面发挥着关键作用。近年来,深度学习的快速发展显著推动了车辆ReID技术的演变。因此,对以深度学习为核心的车辆ReID方法进行全面调查已成为迫切且无法避免的需求。
本文广泛探讨了应用于车辆ReID的深度学习技术。它概述了这些方法的分类,包括监督和无监督方法,深入研究这些类别中的现有研究,介绍数据集和评估标准,并阐明未来的挑战和潜在研究方向。这篇全面的评估考察了深度学习在车辆ReID中的应用,并建立了未来工作的基础和起点。它旨在通过突出挑战和新兴趋势,促进利用深度学习模型在车辆ReID方面的进展和应用。
I Introduction
车辆是社交生活中最受欢迎和重要的部分。近年来与车辆相关技术的进步,如车辆检测、车辆类型识别、车辆跟踪、车辆检索等,已经促使智能交通系统(ITS)和智能城市的实现。在这个技术领域中,搜索特定车辆轨迹并探索其运动在加强智能城市框架中的公共安全方面具有重要意义。
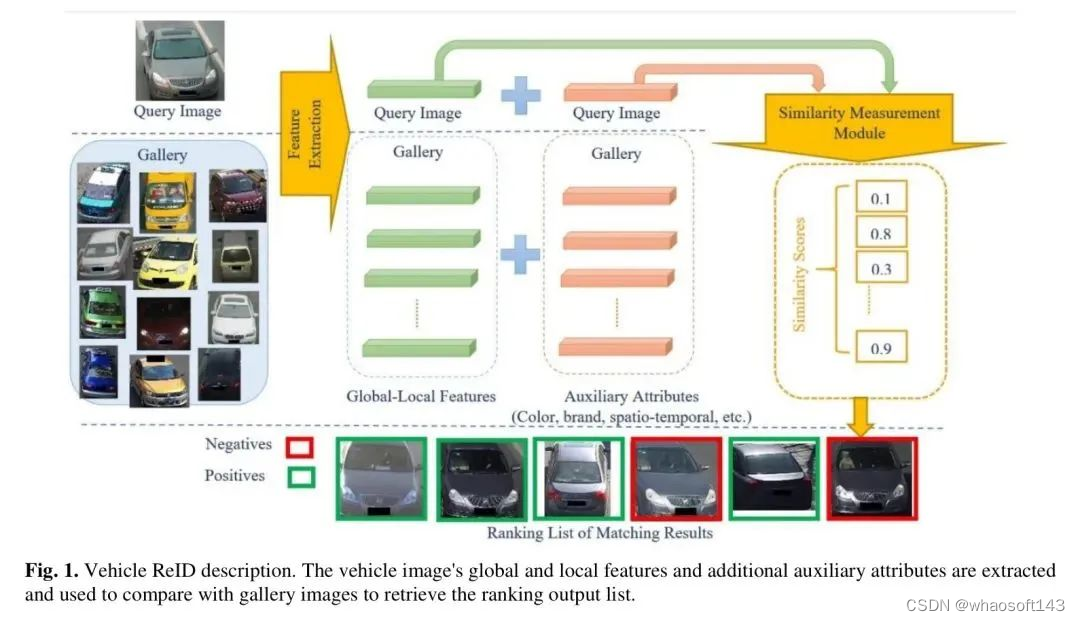
如图1所示,这项努力涉及从车辆图像中提取全局和局部特征,并结合相关的辅助属性,包括颜色、类型、品牌和时空数据。这些提取的特征然后用于比较画廊图像,检索与 Query 图像相似的图像,缩小检索范围,并最终提高结果的质量。这个过程中关键元素是提取和比较从车辆图像中提取的特征,通常称为车辆ReID。车辆ReID旨在在由各种相机在不同的时刻捕获的车辆图像的广泛存储库中识别特定车辆。它在广泛的智能交通系统中尤为突出,并应用于各种视频监控场景,包括定位丢失的车辆、跨地区跟踪特定车辆等。
近年来,随着深度学习技术的快速发展和其在高性能自动目标检测方面的成功,车辆ReID已经引起了许多研究行人和工业界人士的关注。根据对几篇研究论文的调查,作者总结出了基于深度学习的车辆ReID方法的分类,如图2所示。
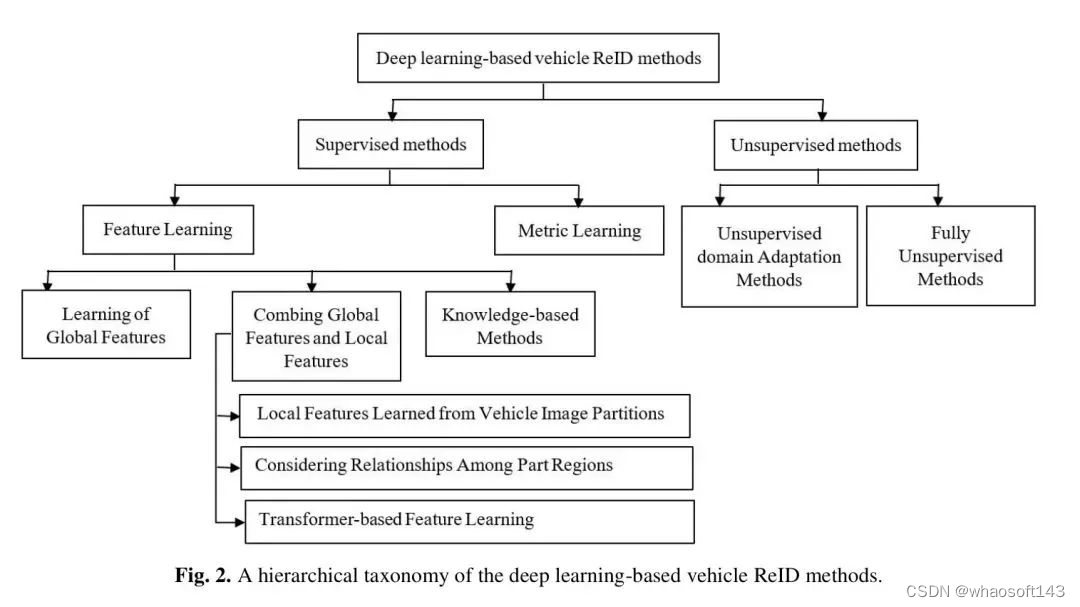
如图2所示,车辆ReID方法可以分为两个关键类别:监督方法和不监督方法。
在监督方法中,一些研究行人主要专注于从车辆图像中学习独特的视觉特征作为分类问题,而其他人则专注于通过损失函数进行深度度量学习。
为了学习视觉特征,通常,卷积神经网络(CNN)及其变体已经被广泛应用于从车辆图像中识别全局特征。此外,一些方法建议将不同层的特征图与CNN的最终输出相结合。这些方法只关注车辆的全局特征,而没有考虑其丰富的细节,因此不适合用于区分视觉上相似的车辆。为了解决这个问题,一些工作已经进行了局部和全局特征的集成。例如,车辆品牌或装饰从不同视角提供的局部特征可以反映额外的细节。这些方法主要强调从图像分区中学习局部特征,考虑区域之间的关系,或学习局部和全局特征之间的交互。最近, Transformer 的能力已经被应用于从车辆图像中学习全局和局部特征。除了车辆图像,一些方法已经利用知识为基础的信息,包括但不仅限于车辆属性(如车辆颜色、类型、品牌和时空特征,如车辆轨迹)。
深度度量学习旨在通过深度模型获得多维特征空间,以便具有相同类别标签的实例接近,而具有不同类别标签的实例远离彼此。用于度量深度学习的两种主要损失函数是对比损失和Triplet Loss。关于最近的研究,Triplet Loss在车辆ReID任务中优于对比损失。此外,这些损失函数的某些适应性版本已经专门针对与车辆ReID相关的限制进行了调整。
无监督方法试图在没有类别标签的数据中完全发现适当的信息,可以分为两个组:无监督域自适应和完全无监督。前者方法专注于应用一些修改过的对抗网络(GAN),如PTGAN,SPGAN,和CycleGAN,从源域生成具有相同类别标签的合成图像。这些图像以监督方式消耗以训练深度网络。后者主要旨在开发聚类算法和训练策略,从目标域数据中仅发现适当的信息,而不考虑其他辅助信息。与监督方法不同,这些方法从 未标注 的数据中推理车辆ReID,使其更适合并加强实际场景。
虽然最近的成就主要集中在提高车辆ReID模型的性能并解决其问题,但较少的研究关注对这些发展和改进的全面审查。据作者所知,没有对全面研究的彻底回顾,以概括和发现这个主题的所有方面,除了对监督方法的一些调查。因此,有必要回顾当前的最好状态,为这个主题的未来研究提供建议。
在这次回顾中,作者全面调查了使用深度学习方法的车辆ReID,介绍了这些方法的通用分类,包括监督和无监督方法,回顾了这些类别的现有研究,解释了知名数据集和评估标准,并描述了未来研究的挑战和可能的方向。这次回顾检查了基于深度学习的车辆ReID的现状。它为未来的工作提供了基础和起点,指出了相应的挑战和趋势。最终结果将对未来使用深度学习模型开发和应用车辆ReID有所帮助。
II Problem Formulation

III Supervised Vehicle Re-Identification
正如前面提到的,监督方法主要关注使用监督学习技术从车辆图像中学习有用的视觉特征,以实现车辆ReID问题的解决。这是通过两种不同的策略实现的:特征学习和度量学习。前者利用深度学习模型通过学习车辆图像中的稳健和有鉴别性的特征来处理车辆ReID问题。相比之下,后者专注于设计距离和损失函数,以便具有相同类别标签的实例接近,而具有不同类别标签的实例远离彼此。本节全面概述了这些策略。
Feature Learning
最近的研究主要集中在采用各种CNN来提取全局或局部特征,并将它们与聚合模块结合,通过特征学习来重识别车辆。根据聚合模块的机制,这些方法可以分为三类:
-
学习全局特征
-
结合全局和局部特征
-
知识驱动方法
Iii-A1 Learning of Global Features

为了考虑问题的内在挑战并提高ReID模型的实际泛化能力,提出了一些扩展的想法。在[13]中,采用了一个卷积神经网络(CNN)和四部分从粗到细的排名损失函数,以同时考虑所有重要挑战并提取车辆的外观特征。第一步,使用分类损失函数将具有相同模型的车辆聚类在一起,并隔离具有不同模型的车辆。然后,引入了粗糙的排名损失,以提高不同模型车辆之间的鉴别性,同时保持同一模型内车辆之间的差异。同一模型内不同车辆之间的差异也由细粒度的排名损失进行表示。还利用了成对损失,将同一辆车的样本尽可能地靠近。最后,他们应用随机梯度下降方法优化CNN网络权重并训练视觉外观模型。尽管该模型已经形式化了车辆ReID的主要问题,但模型验证数据集不适用,一些挑战,包括不同视角、遮挡、日夜变化和不同天气条件,也没有得到评估。
除了车辆图像,一些工作尝试从不同视角提取车辆图像的空间-时间属性和关联,以提高车辆ReID模型的有效性。在[45]中,将车辆图像之间的关系表示为多个颗粒。还提出了两种方法,即广义成对方法和多颗粒列表排序,以提高车辆检索问题的效率。这些方法通过CNN提取全局特征实现。
[46]中的作者开发了一个集成的CNN基础框架,用于发现车辆图像的独特视觉表示。该框架有效地集成了四个不同的子网络,包括识别、属性识别、验证和三元组,以学习各种特征和样本之间的关系。前两个子网络提取单个实例的详细特征,而接下来的两个子网络则专注于样本之间的关系。更具体地说,验证和三元组分别限制了两个样本和三个样本之间的关系。最后,为了训练框架,他们提出了一种同时优化这些子网络四个目标函数的方法。
除了基于CNN的外观特征和辅助特征(如颜色、类型、品牌和纹理),一些研究行人专注于其他特定的特征,如车牌和时空信息,以使检索结果更准确并增强重排机制。在[47]中,作者提出了一种多级深度网络作为粗糙滤波器,用于获取车辆视觉外观特征。然后,他们通过添加诸如车辆纹理、颜色和类型的属性来扩展粗糙滤波器。接着,车牌识别被应用于使搜索更精确。Query 图像和库图像之间的时空关系被调整以修改检索图像的排名[48]。
最近,一些研究考虑了车辆图像的多分辨率性质,即不同相机可能捕获的图像。在[14]中,提出了一种两阶段的深度模型,用于从多分辨率图像中发现独特的视觉特征。在第一阶段,开发了一个多分枝网络,以获取不同尺度的特定属性。每个分枝都由类似的结构CNN网络组成,以产生其尺度特定的视觉特征。这些特征作为输入传递到集成网络,以产生最终的视觉外观模型。两阶段的输出之间的交互利用提高了模型的效率。除了多分辨率视图外,一些工作考虑了注意力机制和全局外观特征,以捕获更有信息量的关键点。这些工作可以归类为结合全局和局部特征。
然而,一些这些方法并没有将车辆图像划分为有意义的地方,并从车辆图像中仅获得一些全局关键点。作者将它们放在当前部分中讨论。例如,在[49]中,提出了一种两分支深度模型,以提取全局和局部特征。在第一分支中,通过多级基于CNN的网络提取全局外观模型。还受到[50]和[51]的工作启发,建立了一个完全两阶段的CNN基于注意力方法,以提取关键点。这些特征被连接并后处理,以提取最终的视觉特征。他们的评估结果证实了注意力机制在克服车辆ReID问题方面的有效性。
总之,尽管已经提出了许多有价值的工作,但全局特征学习只考虑了车辆的整体视图,忽略了对于车辆ReID至关重要的区分性局部特征;因此,这些车辆ReID模型无法实现可接受的性能。因此,仅学习全局特征对于车辆ReID是不够的,还需要考虑局部特征以反映车辆的细节。
Ii-B2 Combining Global and Local Features
车辆之间的颜色、品牌、类型和型号等属性是普遍存在的,因此仅基于全局视觉特征进行车辆ReID似乎是不可能的,而车辆风挡玻璃上的装饰和检查贴纸等局部区域可能更有效。
此外,由于相机角度变化、不同天气和光线条件以及车辆之间的相似性等挑战,使得深度模型在没有考虑局部特征的情况下学习全局视觉特征无法有效克服车辆ReID的挑战。本子节对局部特征学习方法的分类及其最突出的模型进行了全面的审查。
图(2)显示,局部特征学习方法可以分为三个类别。一些研究行人只专注于对车辆图像进行静态或动态分割以提取局部特征。然而,一些工作继续调查分割部分之间的关系,以提高模型的泛化能力。最后,最近的努力已经考虑了全局和局部特征之间的交互作用。
从车辆图像分区学习的局部特征 局部特征学习方法可以概括为恒定空间分区和部分检测方法。除了卷积神经网络,注意机制和 Transformer 在两种方法中学习局部特征方面都发挥着重要作用。
常数空间分区间方法通常将特征图在水平或垂直方向上分成几部分,然后分别对每个部分进行池化。例如,在[19]中,提出了一种分叉的深度模型,包括条纹型和属性感知型,同时考虑局部和全局特征。前者包括平均池化层和维数约简卷积层,以发现局部视觉特征图。同时,后者通过监测车辆属性标签来提取全局特征图,以区分具有不同属性标注的相似身份。最后,将车辆图像的视觉特征图构建为将提取的局部和全局特征图 ConCat 起来。
在[16]中,引入了一种名为RAM1的模型,该模型从一系列局部和全局区域中提取局部特征。该模型最初使用基于CNN的网络生成一个共享特征图。然后,四个深度卷积模型处理这个特征图,产生不同的全局和局部特征。此外,RAM训练通过在多个分类任务中逐步优化softmax损失,同时考虑车辆ID、类型或模型以及颜色。

类似地,在[17]中,提出了一种Partition and Reunion Network (PRN),用于提取具有固定全局特征图分区的局部特征。ResNet-50卷积神经网络被用作全局特征向量提取器。然后,在ResNet-50的卷积4_1层之后,复制卷积层将ResNet-50的 Backbone 部分分为高度/宽度分支。每个分支都被分为高度/宽度和通道特征图。因此,这些三个特征图,包括高度、宽度和通道特征图,被生成并连接以获得最终的特征图。作者们开发了一种由硬部分级和软像素级注意力模块组成的两级注意力网络,以学习更独特的视觉外观特征。第一个模块揭示了车辆的部分,例如挡风玻璃和汽车头,而第二个模块则更注重每个车辆部分中的独特特征。此外,他们开发了一种多粒度排序损失函数,该函数制定了类内紧凑性和类间区分目标,以提高学习特征的判别能力。
在C. Liu等人[20]的研究中,提出了一种自注意力模型,用于从车辆图像中提取更细微的特征,以获得用于车辆ReID的独特特征。该模型包括一个预训练的ResNet50网络作为 Backbone 网络,该网络由四个并行的自注意力模块组成,终止于一个最大池化层和一个卷积层。四个 Backbone 网络输出被输入到包含多个卷积层的四个CNN块中,以提取全局特征。这些全局特征及其修改被作为输入,进入十个自注意力分支,以提取多级局部特征。最后,这些特征通过最大池化和卷积层处理,生成特征图的最终视觉外观。该模型通过交叉熵损失和Triplet Loss进行训练。此外,通过贝叶斯模型提取车辆运动路径的一些时空信息,以重新排序模型的结果。
类似地,在[21]中,X. Ma等人受到Yu的研究启发,部署了一个两阶段的基于注意力的深度模型,以尽可能提取出用于车辆ReID的 discriminative特征。他们采用了STN3和网格生成器来自动隔离没有先前限制的车辆,并将其分成三个常数部分。这些部分被作为输入,输入到三个残差注意模型中,以提取更具有鉴别性的外观视觉特征。
正如之前提到的,部分检测方法是另一种学习局部特征的方式。这种方法通常使用一个著名的目标检测器,如YOLO,来找到车辆部分并发现区分性局部特征。主要缺点是部分检测模块通常是一个深度网络,因此需要大量的手动标注、批量训练和推理计算。例如,B. He等人[56]考虑了三个关键的车辆部分,包括灯(大灯和尾灯)、窗(前窗和后窗)和车辆品牌。他们应用YOLO在库中检测这些部分,并检测图像。然后,将原始图像和三个部分输入到四个单独的ResNet-50网络中,以提取一个全局特征图和三个局部特征图。最后,聚合模块将这三个特征图融合在一起,以获得用于车辆ReID的独特特征图。
在[31]中,作者们提出了VAC21数据集,用于学习车辆图像的局部属性和支持车辆ReID模型,从中发现车辆图像中的关键信息。这个数据集包括一个包含7129张不同类型车辆的库,这些车辆用21类层次属性标注(见表1)和边界框标注。据作者所知,这是唯一一个全面标注了车辆图像广泛细微属性的数据集。此外,他们在该数据集上训练了单张SSD网络[57]作为各种计算机视觉任务的属性检测模型,如车辆ReID。例如,[58]采用了这个预训练的SSD检测器来提取车辆属性。他们只选择了21个属性中的16个,并将其输入到部分引导的注意力网络中,以识别关键部件的领域,并将提取的局部和全局特征图融合在一起,以获得更明显的视觉特征。
除了从车辆图像中提取有意义的部分外,一些研究还关注于自动定位车辆图像中的几个关键点,并从中学习局部特征。例如,在Gu等人的研究中,开发了一种两步关键点近似方法。在前一步中,通过采用VGG-16网络,近似了二十个关键点和一个56x56热力图的协调。在下一步中,使用双堆叠小时glass作为细化网络,以增强热力图并减少由于难以察觉的关键点引起的伪影。卷积网络处理这些关键点和车辆方向估计信息,以选择自适应关键点和提取局部特征。同时,使用预训练的ResNet-50网络提取全局特征。最后,将局部和全局特征连接并处理,通过全连接层提取最终视觉特征。
此外,在Z. Wang等人的研究中,引入了一种深度模型,可以自动识别车辆部件并提取除了全局特征以外的方向不变的局部特征。更具体地说,使用小时glass网络估计二十个垂直关键点的位置,然后使用四个区域 Proposal Mask进行聚类。这些Mask与原始图像一起用于发现全局特征向量和四个局部特征向量。最后,通过一个自定义卷积层将这些特征组合在一起,得到方向不变的特征向量。
类似地,在Zheng等人的研究中,引入了一种基于关键点的图像分割模型,将原始车辆图像分割成几个前景部分,并检测每个部分是否具有区分性。深度网络处理一组具有区分性的部分和原始图像,以提取在笛卡尔域中具有明显相似性的视觉特征图。
总之,恒定空间分区的首要优点是不需要进行部分标注,并节省了相关的计算时间复杂度。然而,这些方法可能会因为部分分区的匹配问题而出现效率低下。相比之下,部分检测方法可以减轻匹配问题,但与手动部分标注和训练计算的时间复杂度有关。无论如何划分原始图像和如何检测部分,这两个类别都可以独立地学习每个部分区域上的局部特征,而不考虑部分之间的关系。
考虑部分区域之间的关系
这些方法通常是通过将GCN4s与CNN结合来考虑部分区域之间的关系而开发的。CNN通常发现全局特征,而GCN用于学习部分区域计算的局部特征之间的关系。GCN是一种深度神经网络,可以识别图结构实体的空间关系。以X. Liu等人[22]提出的PCRNet5为例,该模型将车辆图像划分为部分,发现部分级独特的特征,并确定车辆ReID中部分之间的关系。将车辆图像通过图像分割网络分解为部分后,PCRNet采用两个独立的模块分别发现局部和全局特征。开发了一个基于CNN的模型来发现全局特征。基于车辆车身结构的局部特征之间的关联关系,构建了一个部分邻接图。然后,使用一组GCN来在部分之间传播局部特征并提取不同视点的最具有区分性的局部视觉特征。
类似地,受GCN启发的HSS-SCN6在[23]中被提出,以了解车辆车身部件之间的层次关联并提取更多的独特特征用于车辆ReID。与大多数先前的作品一样,这个框架包括两个模块来提供全局和局部特征图。全局特征模块通过ResNet-50网络实现,然后被输入到局部特征模块以形成结构图网络。在局部特征模块中,采用了恒定空间分区方法将全局特征图划分为五个局部区域,包括特征的上左、上右、中间、下左和下右。这五个特征图和全局特征图形成图的顶点,所有局部或全局顶点之间的空间接近性构成图的边。
此外,Y. Zhu等人[24]引入了SGAT7来考虑标志符(如徽标、窗户、灯和车牌)之间的内在结构关联以及车辆图像之间的外在结构关联。特别是,SGAT包含三个元素:外观、属性和外在SGAT(ESGAT)模块。首先,外观模块使用CNN网络提取全局特征,同时使用内在SGAT(ISGAT)发现局部特征。这些特征被 ConCat 在一起形成车辆的视觉外观特征。同时,将画廊图像输入到属性模块以计算属性相似度矩阵。最后,ESGAT网络采用相似度矩阵来改进车辆的视觉外观特征。
此外,F. Shen等人[25]提出了HPGN8,通过使用金字塔架构将多个SGN结合在一起来完全发现不同尺度特征图的空间重要性。首先,应用ResNet-50作为 Backbone 网络来发现输入车辆图像的全局特征图。接下来,通过应用五个池化层同时缩放全局特征图来生成多尺度特征图。然后,在每个尺度上构建SG9s,其中相应的尺度特征图的元素作为顶点,顶点之间的空间相似性作为边。在每个金字塔结构的 Level 中,通过堆叠三个SG来创建其SGN,以处理相应的尺度特征图。SGN的输出被 ConCat 在一起以产生独特的车辆视觉特征。在[64]中,作者采用了一个CNN模型,然后是一个Transformer[65],以挖掘全局特征并使用知识图谱传输网络,该网络由所有车辆类型作为节点来发现类内信息相关性。
尽管考虑部分区域之间关系的方法已经取得了有前途的结果,但它们仍然没有考虑局部特征和全局特征之间的相关性,以及其他描述性属性(如颜色、视点、品牌等),因此它们还没有达到足够的成熟度,其他方法已经通过涉及Transformer来填补这些缺陷。
Transformer-based Feature Learning
Transformer概念最初是在A. Vaswani等人[65]的研究中引入的,用于处理机器翻译问题。空间统计信息保留和全局处理是Transformer的两个基本机会。与CNN模型相比,由于下采样操作,Transformer可以保留空间统计信息,并通过采用多头自注意力机制提供远程信息。
后来,研究行人将Transformer应用于计算机视觉领域,并在各种视觉任务上获得了显著的性能,与CNN相比。例如,ViT10已在A. Dosovitskiy等人[66]的研究中提出,用于图像分类问题,其有效性已在多个知名基准测试上得到证实。最近,Transformer的能力被应用于解决车辆ReID问题。在本节中,作者讨论了Transformer的监督学习和特征学习应用,其余应用在其他节中进行了回顾。
在L. Du等人的研究中[70],ViT schema已被定制用于车辆ReID。车辆图像已被分割成 Patch ,线性投影为局部特征,并与视点信息合并,作为Transformer层输入。同样,Z. Yu等人[71]提出了VAT11,作为Transformer框架,将部分级局部特征和车辆属性集成,以实现更明显的特征图。车辆图像已被分割成几个部分,线性投影为视觉特征,并与属性特征(颜色、型号、视点等)相结合,输入到Transformer层,以生成车辆特征图。此外,多样本Triplet Loss已被采用来优化Transformer网络。
M. Li等人[28]关注于同一车辆从不同方向捕获的图像之间显著差异的学习挑战。他们提出了一种基于Transformer的schema来解决这个问题。他们的Transformer考虑了不同方向之间部分级交会的部分级对应关系,通过建模部分内和跨视点之间的对应关系。更具体地说,多个视图图像被分割成部分,通过卷积网络编码器进行约束,然后通过部分级交互在Transformer中提取车辆表示。
正如前文所述,GCN仅考虑部分区域之间的关系,并单独提取局部和全局特征。在F. Shen等人的研究中[26],GiT12将GCN和Transformer结合在一起,提取全局和局部特征,并学习它们之间的交互和合作。在微观视角下,车辆图像被划分为多个称为patch的具有多个意义的部分,然后线性投影为向量作为顶点,创建一个局部相关图(LCG)。最后,将LCG输入到Transformer层以构建GiT块。每个GiT块都与下一个块相连,模型化局部和全局特征之间的交互,并提供用于车辆ReID的最后判别特征图。
一些研究行人最近将Transformer模型扩展到使用语义和局部视觉特征,以达到更高效的车辆ReID模型。Z. Yu等人[72]开发了SOFCT13 schema,以探索更具有区分性的全局和局部特征。全局特征提取 Pipeline 首先将车辆图像划分为方块,然后通过线性投影层将其映射到高维数据。一个标记学习器被应用于学习这些数据,并在网络训练期间更新以学习整个图像的统计属性。这些特征与诸如颜色、位置、视点和模型等其他属性结合,并输入到Transformer层以挖掘最终的全局特征向量。此外,车辆图像被分为五个类别(前、后、顶、侧),因此图像块也被分为五个类别并使用Transformer层提取加权局部特征。同样,作者[73]开发了MART14框架,以高效地发现前centered全局特征,提取更具有区分性的局部特征,并证明被遮挡的局部特征。首先,为了消除全局特征上的背景效应,车辆图像Mask被估计采用U-Net与SEResNeXt50,预测每个像素的类别标签(Mask值),像素只能收到五个类别标签中的一个,分别是车辆的前、后、顶、侧,用自然数1到4表示。车辆Mask被划分为重叠的块,然后通过线性投影层将其映射到语义特征域。同时,原始车辆图像直接被划分为几个块,然后被flatten和通过线性投影层转换为标记特征域。
语义特征图、标记特征图及其位置信息被 ConCat 起来构建Transformer网络的输入,以产生前centered全局特征。在第二步中,为每个车辆图像构建一个有向GCN,通过将相应的语义特征图进行划分。然后,将GCN的邻接矩阵输入到Transformer层以发现局部特征。此外,GCN用于推理被其他物体遮挡的车辆的局部特征。此外,在Z. Li等人[64]的研究中,作者专注于在没有标注的车辆图像中去除背景效应。更具体地说,他们提出了SMNet,由两个独立的模块NPF和SFE组成,分别负责背景效应减少和细粒度特征发现。NPF将ViT扩展为一个噪声滤波器,在不需要标注的情况下检测背景并消除其影响。SFE使用自注意力机制提取车辆的最显著特征。尽管这个模型看起来是自动化的,并且具有非常低的计算复杂性,但与类似的研究相比,它缺乏足够的特征来实现高性能。
Iii-B3 Knowledge-based Methods
在车辆ReID的背景下,知识指的是除视觉外观特征和车辆属性之外的空间-时间或文本属性。空间-时间属性包括车辆轨迹、摄像头位置和周围摄像头、天气条件、白天状态等。知识-based方法旨在利用视觉特征和车辆属性的外部知识进行车辆ReID。通常,无法在这些方法和其他使用车辆属性和语义特征域的Transformer-based特征学习方法之间划清明确的界限。然而,使用空间-时间线索对于知识-based方法与其他类别区分开来是必要的。
知识-based方法利用空间-时间信息来增强视觉特征并改进检索结果。例如,Y. Shen等人[32]将视觉外观、时间戳和摄像头地理位置定义为视觉-空间-时间状态,并引入两阶段架构来考虑视觉-空间-时间状态并有效改进车辆ReID结果。它通过优化链式MRF15模型来在第一阶段生成 Query 和库图像的时空轨迹。LSTM网络然后验证轨迹,Siamese-CNN计算相似度分数以实现稳健的车辆ReID性能。同样,N. Jiang等人[12]提出了一个两部分的框架,包括CNN基础 Backbone 网络来增加车辆ReID模型的泛化能力。这些部分旨在提取颜色、型号和外观特征。还提出了一种重新排序技术,用于在不同摄像头的车辆图像之间建立空间-时间关系并重新排序相似的外观检索结果。此外,J. Peng等人[77]开发了一个两阶段的schema,第一阶段使用多任务深度网络来发现独特的特征,并在第二阶段采用空间-时间重新排序模块来改进深度网络的结果。在X. Liu等人[48]的研究中,提出了PROVID16 schema,用于考虑车辆ReID的视觉特征、车牌、摄像头位置、上下文信息和基于数据集统计的时空相似性。
此外,在[78]中,利用空间-时间信息来填充车辆ReID任务中的视觉特征的不足。DenseNet121是一个卷积神经网络,用于发现视觉特征并检索每个 Query 的一组图像。然后,结果集中的位置和时间戳被用于形成一个转移时间矩阵,并过滤出异常值和不相关的图像。同样,在研究X. Tan等人的工作中,提出了一种多摄像机车辆ReID方法,该方法在MCMT任务中利用多摄像机空间-时间信息对结果图像施加某些约束并重新排序。J. Tu等人[76]应用了一个两分支CNN基础的基于注意力的模块来发现全局和局部视觉特征以及一个空间-时间模块来建立一个距离函数以测量车辆图像之间的位置和时间戳相似性。而不是使用转移时间矩阵和空间-时间约束,距离函数使用随机变量分布来计算,可以更高效、更容易地扩展到大规模监控系统。
然而,在某些基于知识的方法中,收集空间-时间信息需要大量的手动标注工作,并使用MCMT任务,这损害了这些方法的 scalability 和 generalizability。因此,在最近的工作中,对采用所有空间-时间信息,尤其是相邻摄像机图像之间的关联以及车辆的运动路径,给予的关注较少。通常只使用其中的一些属性。例如,H. Li等人[5]提出了一种基于Transformer的schema,称为MsKAT17,该schema将视点和摄像机位置视为空间-时间信息,并将车辆颜色和类型作为知识向量。
Metric Learning
如图3所示,度量学习的关键目的是学习一个将物体图像映射到新视觉外观空间的表示函数,其中具有相同类别标签的目标尽可能地靠近彼此,而具有不同类别标签的目标则更远离彼此。对比损失和Triplet Loss是度量学习中使用的基本两种损失函数。此外,为了定制度量学习以用于车辆ReID任务,已经开发了各种损失函数。

首先,作者定义一些符号。训练集表示为和: 表示一个神经网络或任何参数函数作为嵌入函数,将输入样本映射到嵌入特征空间。在做出这些假设后,本节概述了损失函数及其在车辆ReID问题中的应用。
交叉熵损失
交叉熵损失,也称为soft-max损失,主要用于处理分类问题,并因此不包括在度量学习范围内。然而,由于在车辆RelD模型中,交叉熵损失与度量学习损失函数一起应用,因此在本小节中进行了介绍。
交叉熵损失计算每个训练样本的目标和预测类标签之间的差异。

Triplet Loss

此外,在R. Kumar等人[92]的研究中,对这些不同的采样方法在车辆ReID问题上的有效性进行了评估,证实了修改后的Triplet Loss与传统Triplet Loss的有效性相比。同样,为了区分正负样本之间的大和小绝对距离,在[93]中,通过向其函数中添加平衡项,对大采样Triplet Loss进行了改进。
J. Yu等人[94]提出了DTL23函数作为Triplet Loss的修改,用于自监督度量学习。具体来说,他们提出了一种无监督的车辆ReID模型,该模型从车辆图像中构建特征词典,并使用DTL对其进行处理,使用 未标注 的数据训练模型,并增强学习的特征的独特性。Y. Bai等人[95]提出了低收敛速度和特征判别力不足作为Triplet Loss的两个缺点,并引入了ICV24Triplet Loss来克服这些问题。他们采用了一种多任务学习策略,并共同优化了ICVTriplet Loss和交叉熵损失,以生成更多的有歧视性的车辆ReID特征。
此外,VAL和VARID提出了两种视角感知的Triplet Loss函数,以解决车辆ReID中类内相似性和类间相似性问题。特别是,内视角Triplet Loss函数已被定义为考虑同一视角不同车辆的歧视性,而外视角Triplet Loss函数已被部署为强加同一车辆样本在不同的视角下以彼此靠近。视角感知的损失函数是内视角和外视角损失函数的加权平均值。

-
群体群体学习损失
GGL27提出了一种方法,用于改进Triplet Loss中实例选择敏感性和低收敛速度的问题。首先,将训练数据集分成组,每组只包含同一车辆身份的所有图像。GGL然后更新模型权重,使具有相同身份的实例在嵌入特征空间中靠近彼此,并使不同组尽可能远离彼此。

-
其他损失函数
在前面各节中研究的损失函数之外,各种损失函数已在各种计算机视觉任务中采用,但作者所知,它们尚未应用于车辆ReID问题。
T. Lin等人[101]开发了focal损失,以解决密集目标检测中训练过程中经常出现的类不平衡问题。此外,范围损失函数和圆损失被引入,以降低类内离散度,同时增加类间相似度。同样,中心损失已在面部识别任务中使用,以提高特征的判别力。多粒度排名损失已在车辆ReID中引入,以实现最具有判别力的深度特征。多类N对损失作为传统三元的通用化,以克服慢收敛问题。此外,在研究X. Wang等人[104]中,提出了排名列表损失,以实现快速收敛和高性能的度量学习,并在研究E. Kamenou等人[34]中,已在车辆ReID任务中使用。
IV Unsupervised Vehicle Re-Identification
近年来,基于卷积神经网络(CNN)的深度学习技术的迅速发展导致了各种监督车辆重识别(ReID)方法的出现。监督方法的性能主要取决于大规模特定领域的标注训练集的可用性,这需要一项耗资和耗时的任务来准备。特别是,训练集不足会导致监督模型在转移到实际的大规模监控系统时,效率会以指数下降。从学者的角度来看,无监督学习是克服这些限制的有效方法,无需标注训练集即可从数据集中捕捉最具有意义模式。
基于深度学习的无监督方法通常基于迁移学习发展,其中在一个数据集上训练的模型被微调或适应以在不同的但相关的数据集上工作,作为目标域。根据源域和目标域是否已标记,迁移学习可以分为四类,如图4所示。由于这种分类,无监督车辆ReID技术可以分为两个主要组:无监督域自适应和完全无监督方法。本节提供对这些方法的全面概述。

Unsupervised domain adaption methods
无监督域自适应涉及在源域(一个领域)的数据上训练一个模型,并在没有标记的目标域(另一个领域)上适应以执行,在训练期间没有使用标记的目标域数据。目标是减少源域和目标域之间的差异,使模型在面对新且未见过的数据时能更好地泛化。在机器学习领域,已经提出了几种用于无监督域自适应的方法,包括域对抗训练、实例基础方法、自编码技术、特征对齐和基于GAN的方法。这些方法在模型训练期间使用各种策略来解决域间差异。例如,域对抗训练,如DANN ,利用域判别器在训练主任务时,同时对来自不同域的表示进行对齐。另一种方法是实例基础方法,它通过使用技术如MMD或CORAL 来匹配域分布来达到域分布的对齐。自编码技术,如Mean Teacher 、VAT 、PSUReID 和HyPASS ,通过伪标签化使用一致性正则化来稳定跨域偏移的预测。特征对齐技术,如Deep CORAL 和VAE ,通过修改模型架构或学习目标来显式地对齐域间特征,通常包括域特定的归一化或适应层。基于GAN的方法,例如CycleGAN 和DiscoGAN ,将GAN框架扩展到生成类似于源域的合成目标域数据,有效地减少了域间差异。据作者所知,关于无监督车辆ReID,特别是无监督域自适应的研究还很少,大部分研究集中在行人ReID任务上。
[115]和[116]的作者解决了由训练(源域)和测试(目标域)数据集之间的显著性能退化所引起的挑战。这个挑战源于不同领域的异质性,表现在各种图像特征上,包括不同的背景、光照、分辨率和摄像机视角的差异。为了克服这个挑战,J. Peng等人[115]提出了VTGAN,这是一个图像到图像的转换框架,旨在将源域的风格转移到目标域,同时保持它们的身份信息。此外,他们还提出了ATTNet,利用基于注意力的结构训练生成的图像,从而在车辆ReID的背景下发现更多的独特特征,同时抑制背景。
在C.-S. Hu等人[117]的研究中,车辆姿态的转换被表述为一个域适应任务。PTGAN被设计为接收表示车辆视点的关键点,然后生成一个对应于新视点的假图像来解决姿态变化问题。此外,在[118]中,探索了识别跨不同领域的相同车辆的任务,即包括白天和夜晚领域,作为一个域适应问题。介绍了一种基于GAN的框架,将两个输入图像转换为属于另一个领域的图像。然后,利用四分支Siamese网络学习两个不同领域图像之间的距离度量。
通过UDA学习的表示通常缺乏任务特定方向,这意味着它们通常不会同时具备分类判别和域可转移的特点。在UDA中的车辆ReID领域,已经致力于解决这一问题。值得注意的是,作者在[119]中引入了DTDN。这个框架将数据表示分为两个截然不同的部分:一个包含任务相关的元素,包括跨域任务相关的关键信息;另一个包含与任务无关的方面,包括无法转移或破坏性的数据。域间使用任务特定目标函数来调节这些部分。这种正则化明确地促进解耦,而不需要使用生成模型或解码器。R. Wei等人[116]在研究中首次引入了Transformer在UDA车辆ReID中的应用,以克服所提到的问题。这个基于Transformer的网络旨在增强图像中上下文信息的整合。具体来说,该网络适应地指导注意力在源域和目标域之间的判别性车辆组件。它包含一个域编码器模块来识别域不变的特征并减轻域相关因素的影响。此外,在每次训练周期开始之前,应用对比聚类损失对目标样本的特征表示进行聚类。这些聚类随后被分配标签,作为后续训练过程的伪身份来监督训练。
伪标记技术仍然是解决UDA车辆ReID任务的主要选择,因为它们的性能优越[29, 110]。然而,伪标记的有效性极大地取决于通过聚类方法直接影响伪标签生成的特定超参数的选择。为解决这个挑战,[111]中提出的方法HyPASS被引入为一种专门针对UDA聚类中伪标签超参数自动和循环调整的技术。
HyPASS包括伪标记方法框架中的两个基本组成部分:首先,超参数的选择取决于来自标记源数据的验证集;其次,通过特征判别性的条件对齐来优化超参数选择,这是一种通过分析源样本进行磨练的过程。同样,Z. Lu等人[29]介绍的MAPLD方法在UDA车辆ReID的背景下,同时增强了伪标记技术的精度,并有效地减少了伪标签噪声。
尽管基于UDA的方法在车辆ReID方面取得了成就,但它们通常需要来自不同领域的附加信息,这可能限制了它们在实际场景中的适用性。因此,有时完全无监督的方法由于与实际应用的兼容性而受到青睐,避免了从不同领域获取额外数据的需要。
Fully unsupervised methods
完全无监督方法可以直接从 未标注 的数据中提取有意义的信息,无需标注或标记数据。这种特性使得这些方法更适合和适应实际应用和场景。这些方法主要关注开发多种聚类技术和渐进训练策略作为其关键焦点。
渐进学习遵循逐步学习信息的方法,从简单的概念开始,逐步发展到更复杂的概念。这种方法已在不同的计算机视觉任务中广泛应用,如人脸识别,图像分类,行人ReID,等等。DUPL-VR 和VR-PROUD 专门针对车辆ReID的挑战,通过在无监督方式中实现渐进策略而设计。首先,将 未标注 的图像输入到基础CNN网络中,利用预先建立的权重来提取特征。这些特征经过聚类过程,获得作为“伪”标签的聚类ID。然后,应用特定的启发式约束来改进聚类结果,以增强聚类的准确性和稳定性。然后,使用聚类后的车辆作为额外CNN网络的校准,该网络的架构与基础CNN相同。这个迭代过程通过将不断增强的聚类纳入训练数据集,不断扩展训练数据集,实现无监督的自渐进学习,直到收敛。A. Zheng等人[123]提出了一种以渐进学习为中心的无监督车辆Re-ID的视角感知聚类方法。首先,使用视角预测网络提取视角细节,同时通过利用斥力损失函数学习每个样本的独特特征。然后,将特征空间根据预期的视角划分为不同的子空间。然后,应用渐进聚类算法来发现样本之间的精确关系,并增强网络的判别能力。
类似地,在[3]中提到的研究行人将渐进学习应用于解决无监督车辆ReID挑战。他们受到[124]的启发,主要关注区分可靠样本并实现网络的渐进算法训练。他们的方法有两个基本差异:首先,他们设计了一个多支路背部来捕捉全局和局部特征,利用这种双重信息来创建可靠聚类,从而减轻难以样本的影响。此外,他们的方法开始阶段分别利用全局和局部特征进行训练,然后逐渐过渡到这些特征的融合,因为网络的能力在后续阶段发展。
V Data Sets
不同的研究小组已经准备了许多标准数据集和基准来验证车辆ReID模型的优越性。本节将详细检查这些数据集,特别是它们的优点和局限性。
VehicleID
在中国一个小规模的白天,许多不重叠的监控摄像头收集了"车辆ID"数据集。平均每辆车有8.44张图像(总共221763张来自26267辆车)。
在这个数据集中,有90196张图像,其中10319辆车带有其模型信息(只有250个最流行的模型)。此外,考虑了车辆的两个方向,包括前或后,并且未标注视图信息。每辆车包含多于一个图像,因此该数据集适用于车辆检索任务。
这个数据集包括训练集和测试集。训练集中有110178张图像,涉及13134辆车,其中47,558辆带有车辆模型信息。测试集中有111585张图像,涉及13133辆车,其中42638张带有车辆模型信息。
这个数据集是在相对受限的情况下收集的,大约有20个摄像头在白天使用,包括两种方向视图,一些照明变化和简单的背景。因此,它不包含评估所有车辆ReID场景和挑战所需的基准。
这个数据集是在相对受限的情况下收集的,大约有20个摄像头在白天使用,包括两种方向视图,低照度变化,以及简单的背景。因此,它不包括所需的基准和数据来评估所有车辆ReID挑战。
VeRi-776
VeRi-776数据集是从VeRi数据集中构建的。大约20个交通监控摄像头在各种条件下收集了VeRi数据集,如方向、照度和遮挡。它包含619辆车的40000张图像,带有各种属性,包括车辆边界框、品牌、类型和颜色。
VeRi-776数据集是通过在三个方面扩展VeRi数据集而构建的:增加数据量、考虑车牌号码,并将车辆轨迹视为时空信息。它包含超过50000辆车辆图像,776辆车辆身份和约9000个轨迹。VeRi-776数据集包括训练集(576辆车辆和37781张图像)和测试集(200辆车辆和11579张图像)。
这个数据集是在一个单一的白天(下午4点到5点)在一个1平方公里的小区域内记录的,因此缺乏足够的测试床来评估所有车辆ReID的挑战。
VD1 and VD2
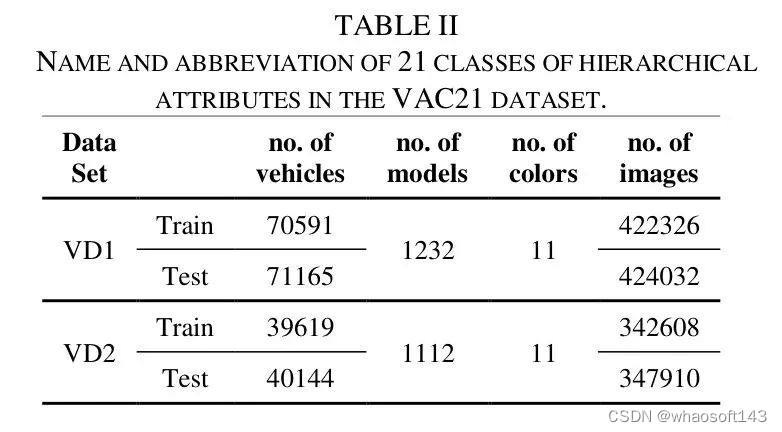
VD1和VD2数据集是从交通摄像头和监控视频中分别收集的车辆正面图像。在这两个数据集中,每辆车的颜色、型号和识别号码都被用作车辆图像的属性向量。
VD1数据集包含846358张图像,涉及141756辆车,有11种颜色和1232种型号,分为训练集和测试集。VD2数据集包含807260张图像,涉及79763辆车,有11种颜色和1112种型号。两个数据集的训练集和测试集的特性如表2所示。
 这些数据集在车辆ReID挑战中大大简化了问题,因为大多数图像是从单一视图捕获的。因此,在这些数据集上的性能已经饱和,最近一种方法在VD1和VD2上分别实现了97.8和95.5%的准确率。
这些数据集在车辆ReID挑战中大大简化了问题,因为大多数图像是从单一视图捕获的。因此,在这些数据集上的性能已经饱和,最近一种方法在VD1和VD2上分别实现了97.8和95.5%的准确率。
Vric
这个数据集包含由60个摄像头的复杂道路交通监控系统在白天和夜晚捕获的60,430张图像,涉及5622辆车辆的身份。VRIC包括24个监控位置,几乎覆盖了由分辨率、运动模糊、天气条件和遮挡差异引起的车辆几乎无限的外观。
这个数据集被分为训练集和测试集。训练集包括54,808张图像,涉及2811个身份,而测试集包括5622张图像,涉及2811个身份。所有图像都注明了汽车型号、颜色和类型。
尽管VRIC数据集考虑了车辆ReID在实际世界中的大多数挑战,但它仍然存在车辆类型和模型有限、缺乏详细车辆属性、图像面积较小以及训练集和测试集摄像机重叠等问题。
CityFlow
四十二个非重叠监控摄像头在美国一个中型城市十个交叉口之间收集了"CityFlow"数据集,两个摄像头之间的最大距离为2.5公里。该数据集包含229680辆车的图像,涉及666个不同的车辆身份,每个车辆至少通过两个摄像头。
这个数据集包含3.25小时的视频,包含如高速公路、公路和交叉口等地点。每个视频的起始时间偏移都进行了标注,大多数视频以每秒10帧的速度捕捉,分辨率至少为960p。
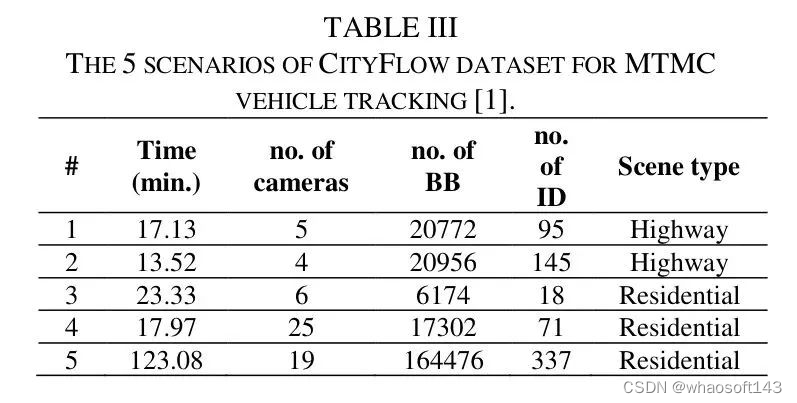
CityFlow是第一个支持多目标多摄像头(MTMC)车辆跟踪的公开基准。为此,表3中展示了五个场景。
此外,为了支持基于图像的车辆ReID,CityFlow的一部分被称为CityFlowReID已经开发出来。CityFlow-ReID包含总共56277辆车的图像和4.55个摄像头视图的平均666个不同的车辆身份。它包括一个训练集,包含333个车辆身份和36935张图像,以及一个测试集,包含333辆车和18290张图像。
VERI-Wild 2.0
VERI-Wild 2.0数据集是通过扩展VERI-Wild[128]来全面评估车辆ReID模型的判别和泛化能力而开发的。这个数据集是在一个超过200平方公里的都市区域的274个摄像头的巨大CCTV监控系统中,24小时收集了一个月的图像。
这个数据集包含许多同一型号的车辆,其样本包括非常复杂的背景、各种方向、严重的遮挡和不同的天气条件。它包含825042张图像,涉及42790个车辆身份,涵盖了各种场景,包括城市道路、街道交通灯区域、交叉口、高速公路收费站和匝道入口。有30%以上的身份是在白天和夜间录制的。此外,还标注了辅助属性、车辆颜色、车辆类型和车辆品牌,以提高车辆的视觉特征图。
这个数据集包含许多同一品牌或型号的车辆实例。平均而言,在雾天、雨天和晴天,每辆车的每个身份都被从不同的视点获取约59个样本。更具体地说,在雾天和雨天,分别有7.1%和3.48%的数据是在这两种天气条件下捕获的。
这个数据集被分为训练集和测试集,分别包含277797和398728张图像。此外,174个摄像头捕捉训练集,100个摄像头用于测试集。由于训练集和测试集中的摄像头不重叠,因此可以在不同的光线条件、视点和复杂背景下评估车辆ReID模型的判别和泛化能力。测试集被分为三个子集图像,以全面评估车辆ReID模型并研究方向、光线和天气变化的影响。
基于不同标准对所调查的数据集进行全面的车辆ReID比较,结果如表4所示。
VI Evaluation Strategies
现有文献中提出了许多评估策略,这些策略强调了数据集选择和性能指标是车辆ReID评估的关键方面。通过采用这些评估策略,研究行人和从业行人可以全面评估和比较不同车辆ReID方法的有效性,为该领域的进步铺平道路。
Dataset Selection
利用包含各种在不同场景、时间和环境条件下获得的车辆图像的标准数据集来评估研究挑战是至关重要的。在数据集中实现严格的训练和测试划分是确保公正评估和避免过拟合问题的关键。此外,可以通过在不同数据集上评估模型来衡量其通用性和鲁棒性。这验证了模型在训练数据之外的各种设置下的性能。此外,还需要考虑各种评估场景,如单张或多张重识别、相机内匹配或相机间匹配,以及在不同条件下的评估,如遮挡或光照变化。
前面部分提供了一个对已建立的用于评估车辆ReID模型数据集的全面回顾。
Performance Metrics
重新识别算法有效性的常用度量指标包括排名、mAP1、精确率-召回曲线和CMC2曲线。
排名比例
在车辆ReID中,对车辆进行排名的过程需要对 Query 车辆图像提取的特征与所有 gallery 中的图像进行彻底比较。这种比较使得图像按照相似度降序排列,最相似的图像排在较高的排名位置。对于选定的数据集的 ground truth,在有序列表中的第一个位置,其图像与 Query 图像对应的同一种车辆,表明了其排名并具有最重要的评估意义。
排名比例标准是通过将指定排名中准确重新识别的 Query 图像数量除以测试集中 Query 图像的总数来推导的。这个度量指标直接表明系统在预定义排名内精确重新识别车辆的有效性。例如,排名-k时的排名比例显示了算法在 Query 结果中正确识别的车辆图像数量,这些图像的排名不超过k。
mAP(平均精确率)
精度(Precision)和召回率(Recall)虽然作为单一值标准有价值,但它们基于 ReID 方案检索的所有图像。在车辆 ReID 的背景下,由于模型提供了图像的排名列表,因此考虑每个图像在列表中的位置是有益的。通过在列表中的每个位置计算精度和召回率,可以实现精度-召回曲线。平均精度(AP)的定义如下:

CMC (查准率-查全率曲线)

VII Discussion and Challenges
为了根据所提出的分类法评估基于深度学习的车辆 ReID 方法,表5 展示了使用 Veri-776 和 VehicleID 数据集的最先进方法在车辆 ReID 上的性能比较。显然,基于 Transformer 的特征学习和度量学习在与其他类别相比表现出了优越性能。
MsKAT 是一种基于知识的方法,其效率来源于使用了一个多尺度知识感知的 Transformer,其高性能可以归因于 Transformer 架构的战略性集成。此外,由于训练和测试域之间固有的差异,无监督方法的有效性,尤其是域适应技术,显著降低。这种域之间的适应性在实际车辆 ReID 任务中造成了巨大的挑战。
此外,为了衡量数据集的复杂性和模型在实际挑战中的适应性,作者在 VERI-Wild 和 VERI-Wild 2.0 数据集上呈现了一些最先进方法的表现评估。表5、VI 和 VII 的分析显示 VERI-Wild 2.0 数据集的高复杂性导致模型准确度的降低。因此,该数据集是评估车辆识别模型的合适基准。
智能视频监控系统的广泛应用导致了车辆 ReID 需求的急剧增长。尽管在一段时间内进行了大量和持续的努力,但该领域主要面临两个显著挑战。首先,在同一辆车的不同模式下捕获的图像中观察到的内插差异,包括摄像机视图、车辆视角和捕捉时间的差异。其次,在不同车辆之间遇到的实例相似性,特别是在共享相同特性(如颜色、类型和制造商)的情况下。此外,在将车辆 ReID 应用于交通监控场景时,不同摄像机之间的图像分辨率、不同的摄像机角度、天气条件和不同的照明条件会导致车辆外观的巨大差异,这给车辆 ReID 带来了巨大的挑战。下面解释了车辆 ReID 面临的问题的复杂性和挑战。 whaosoft aiot http://143ai.com
Viewpoint Variability
车辆在外观上可能会因摄像头角度、距离和方向的变化而出现显著差异。为了克服这些视点变化,确保识别的一致性,提取视点不变的特征仍然具有挑战性。
Appearance Variations
外部因素,如照明条件、天气、遮挡或修改(增加/减少配件),可能会改变车辆的外观,使一致的识别变得具有挑战性。
Scale and Resolution
车辆图像在不同的摄像机上可能具有不同的分辨率和缩放,这会影响特征提取和匹配的准确性。
Intra-Class Variability
同一品牌和型号的车辆由于修改、不同版本或磨损等原因可能表现出显著的视觉差异,这使得在相似车辆之间进行区分变得更加复杂。
Limited Annotated Data
尽管存在各种不同的数据集,但是覆盖所有可能情况的标注数据仍然不足,这仍然是一个重大的挑战,它对训练出强大的模型造成了困难,同时也阻碍了准确和泛化性算法的开发。
Real-time Processing
显然,深度学习模型面临指数级的时间复杂性,这是它们在实时应用中面临的一个持久且显著的障碍。因此,在实时交通监测或管理系统中准确重新识别车辆需要部署具有快速处理能力的算法。
Privacy and Ethical Concerns
平衡识别的有效性与尊重隐私权,尤其是在公共监视中,是一个关键的挑战。
VIII Conclusion
车辆 ReID 领域关注的是从分布在不同交通环境下的摄像机网络获取的车辆图像之间的关联。智能视频监控系统的广泛采用催生了车辆 ReID 技术的显著需求。这一任务在车辆为中心的技术领域中具有首要的重要性,作为实现智能交通系统(ITS)和开发智能城市的倡议的关键催化剂。深度学习的最新进展显著加速了车辆 ReID 技术的演变。本文对应用于车辆 ReID 的深度学习方法进行了全面的探索。
本文提出的方法可以分为两个主要类别:有监督方法和无监督方法。在有监督方法中,模型主要关注从车辆图像中获取独特的视觉特征,将其视为分类问题。相反,其他模型优先考虑通过应用特定的损失函数进行深度度量学习。无监督方法试图从数据中提取相关信息,而无需考虑类标签,分为两个截然不同的组:无监督域自适应和完全无监督方法。本文对已建立的标准化数据集和评估标准进行了详细的审查,并详细分析了来自最先进论文的实验结果。本文旨在提供一个指导框架和有价值的资源,以指导该领域的未来研究。

