
- 1【python】调整图像大小_自定义调整、等高宽调整
- 2Python中函数的详解_def func( ): print('hello') 问:type(func),type(func
- 3队列的顺序存储结构_队列的顺序存储结构源代码
- 4linux-----------串口设置缓冲器的大小_xmit_fifo_size
- 5让模型畅所欲言不再Say No丨专访Dolphin开源模型作者Eric Hartford
- 6散列表(哈希表)
- 7Flink Task、Sub-Task、task slot和parallelism_flink subtask
- 8Spark MLlib快速入门(1)逻辑回归、Kmeans、决策树、Pipeline、交叉验证_sparkmlib入门
- 9OpenCV如何模板匹配(59)
- 10大语言模型与知识图谱的融合在心理学领域的应用_语言模型与知识图谱在心理学领域的应用
【论文阅读】Fuzz4All: Universal Fuzzing with Large Language Models
赞
踩
摘要
Fuzzing在发现各种软件系统中的错误和漏洞方面取得了巨大成功。以编程或形式语言为输入的被测系统(SUT),例如编译器、运行时引擎、约束求解器和具有可访问API的软件库,尤其重要,因为它们是软件开发的基本构建块。然而,用于此类系统的现有模糊器通常针对特定语言,因此不能容易地应用于其他语言甚至同一语言的其他版本。此外,现有模糊器生成的输入通常仅限于输入语言的特定特征,因此很难揭示与其他或新特征相关的错误。
本文介绍了Fuzz4All,这是第一个通用的模糊器,它可以针对许多不同的输入语言和这些语言的许多不同特征。Fuzz4All背后的关键思想是利用大型语言模型(LLM)作为输入生成和变异引擎,这使得该方法能够为任何实际相关的语言生成多样化和现实的输入。为了实现这一潜力,我们提出了一种新的自动提示技术,该技术创建了非常适合模糊处理的LLM提示,以及一种新颖的LLM驱动的模糊循环,该循环迭代更新提示以创建新的模糊输入。
我们在九个测试系统上评估Fuzz4All,这些系统采用六种不同的语言(C、C++、Go、SMT2、Java和Python)作为输入。评估表明,在所有六种语言中,通用模糊比现有的特定语言模糊实现了更高的覆盖率。此外,Fuzz4All已经在广泛使用的系统中发现了98个漏洞,如GCC、Clang、Z3、CVC5、OpenJDK和Qiskit量子计算平台,其中64个漏洞已经被开发人员确认为以前未知的。
一、介绍
传统的模糊器分为基于生成的模糊器和基于突变的模糊器:
- 基于生成的模糊器:直接合成完整的代码片段
- 基于突变的模糊器:将突变算子或转换规则应用于高质量模糊种子集
但是这两种模糊器都面临着两种挑战:
- C1:现有模糊器与特点的语言和待测系统紧密耦合,将对于一种语言有效的模糊器应用于另一种语言可能就会完全无效,并且需要花费大量精力去针对特定语言设计模糊器。
- C2:缺乏对于更新后软件或语言的支持,例如,Csmith仅支持C++11之前的一些有限功能,但是对于后面更新的功能则无法支持。
- C3:生成能力受限,即使在特定语言的目标范围内,这两种模糊器都无法覆盖大部分的输入空间。基于生成的模糊器严重依赖输入语法来生成有效代码,且依赖语义规则来保证API的调用依赖,基于突变的模糊器受到算子的限制,并且难以获得高质量的种子。
本文基于以上挑战,设计了第一个通用的模糊器Fuzz4All,Fuzz4All不同于AFL和Libfuzzer,Fuzz4All关键思想是利用大模型作为输入生成和突变引擎,由于大模型接受了各种编程语言的预训练,因此它可以有效的为多种语言进行突变和输入生成。从而解决上述的挑战。
- 针对C1,通过使用LLM作为生成引擎,应用于广泛的被测系统以及语言
- 针对C2,Fuzz4All可以跟随被测目标一起更新
- 针对C3,大模型在数十亿的代码片段上进行训练,使得它能够具有广泛的生成能力
二、Fuzz4All的方法

Fuzz4All主要由两部分组成,自动提示以及fuzzing循环。
2.1、自动提示
该步骤通过自动提示将给定的用户输入提取为适合模糊处理的提示。用户输入可以描述一般的被测系统,或者被测系统的特定特征。用户输入可以包括技术文档、示例代码、规范,或者甚至不同模态的组合。与传统的模糊器要求输入遵循特定格式不同(例如,用作种子的代码片段或格式良好的规范),Fuzz4All可以直接理解用户输入中的自然语言描述或代码示例。然而,用户输入中的一些信息可能是多余的或不相关的,因此,自动提示的目标是生成一个提取的输入提示,从而实现有效的基于LLM的模糊处理。
2.1.1、自动提示算法

在这个算法中,userInput表示用户输入,numSamples表示生成的候选提示数量,输出的inputPrompt表示用于输入模糊循环的输入提示。第二行伪代码中,
M
D
M_D
MD表示蒸馏大模型,APInstruction表示自动提示命令,文中使用的是Please summarize the above information in a concise manner to describe the usage and functionality of the target。
在生成了一定数量的提示词之后,在第七行伪代码里把生成的所有提示词放到评分函数中评分并排序,并从中选出最好的提示词作为输入放到下面的fuzzing循环阶段。
2.1.2、自动提示的例子
使用了C++23下的std::expected来举例子,展示自动生成的提示
2.1.3、与现有自动提示技术的比较
本文是第一个使用黑匣子自动提示从软件工程任务的任意用户输入中自动提取知识的文章。与之前在NLP和软件工程中关于自动提示的工作相比(通过访问模型梯度来优化提示),我们的自动提示只需要访问蒸馏LLM的黑盒采样。虽然使用评分函数来评估每个提示与NLP[87]中最近的工作类似,但我们的评分函数直接评估生成有效代码片段的确切下游任务的提示,而不是使用近似的代理评分函数
2.2、fuzzing循环
给定在Fuzz4All的第一步中创建的输入提示,模糊循环的目标是使用生成LLM生成不同的模糊输入。然而,由于LLM的概率性,使用相同的输入进行多次采样会产生相同或相似的代码片段。对于模糊化,我们的目标是避免这种重复输入,而是希望生成一组不同的模糊化输入,覆盖新代码并发现新错误。为了实现这一目标,我们利用LLM的能力,利用示例和自然语言指令来指导生成。
模糊循环的高级思想是通过从以前的迭代中选择一个模糊输入示例并指定一个生成策略来不断增加原始输入提示。使用示例的目的是演示我们希望生成LLM生成的代码片段的类型。生成策略被设计为关于如何处理所提供的代码示例的指令。这些策略受到传统模糊器的启发,模仿它们合成新的模糊输入(如基于生成的模糊器)和产生先前生成的输入的变体(如基于突变的模糊器中)的能力。在模糊循环的每次新迭代之前,Fuzz4All都会在输入提示中添加一个示例和一个生成策略,使生成LLM能够连续创建新的模糊输入。
2.2.1、模糊循环算法

模糊循环算法的大致流程如图所示,它接受从上一流程传来的提示词,并通过生成式大模型完成三种变异,分别是
- 1、通过提示词生成新的模糊输入
- 2、通过提示词变异已经存在的代码
- 3、通过提示词创建与给定示例相同语义的输入

输入是初始输入提示和模糊预算。最终输出是由用户定义的预言机(Oracle)识别的一组错误。
首先,该算法初始化生成策略(生成新的、变异现有的和语义等价),这些策略将用于在模糊循环期间修改输入提示(第2行)。
M
G
M_G
MG表示的生成LLM的第一次调用,该算法还没有任何模糊输入的例子。因此,它在输入提示中添加生成新一代指令,该指令引导模型生成第一批模糊输入(第3行)。
接下来,算法进入主模糊循环(第5-9行),该循环不断更新提示以创建新的模糊输入。为此,该算法从前一批生成的模糊输入中选择一个示例,从所有对SUT有效的模糊输入随机选取(第6行)。除了示例之外,该算法还随机选择三种生成策略中的一种(第7行)。生成策略要么指示模型对所选示例进行变异(变异现有示例),要么生成与该示例在语义上等效的模糊输入(语义等效),要么提出新的模糊输入。
该算法将初始输入提示、所选示例和所选生成策略连接到一个新提示中,然后用该提示查询生成LLM,以生成另一批模糊输入(第8行)。重复主模糊循环,直到算法耗尽模糊预算为止。对于每个创建的模糊输入,Fuzz4All将输入传递给SUT。如果用户定义的预言机识别出意外行为,例如崩溃,则算法会向检测到的错误集添加一个报告(第4行和第9行)。
2.2.2、Oracle
Fuzz4All在模糊化循环期间产生的模糊化输入可用于对照oracle检查SUT的行为,以检测错误。oracle是为每个SUT定制的,它可以由用户完全定义和定制。例如,当模糊C编译器时,用户可以定义一个差分测试预言机,用于比较不同优化级别下的编译器行为,在本文中,我们将重点讨论简单易定义的预言机,例如由于分段故障和内部断言故障导致的崩溃。
三、实验设计
本文根据以下四个问题进行评估:
- Fuzz4Aall与现有模糊器相比如何?
- Fuzz4All在执行有针对性的模糊处理方面的有效性如何?
- 不同的组件如何影响Fuzz4All的有效性?
- Fuzz4All在现实世界中发现了哪些bug?
3.1、实现
Fuzz4All主要是用Python实现的。Fuzz4All使用GPT4作为蒸馏LLM来执行自动提示,主要是使用通过OpenAI API提供的最大token为500的gpt-4-0613检查点。max_token强制提示始终适合生成LLM的上下文窗口。对于自动提示,我们对四个候选提示进行采样,每个提示生成30个模糊输入,并使用基于有效率的评分函数进行评估(如第3.1.1节所述)。对于模糊循环,我们使用HuggingFace上的StarCoder[41]模型作为生成LLM,该LLM在80多种语言的一万亿个代码令牌上进行训练。当生成模糊输入时,我们的默认设置使用温度为1,批大小为30,最大输出长度为1024,使用核采样,top-p为1。
3.2、被测系统和baseline
针对六种语言的九个被测系统进行测试,如下:

3.3、实验设置以及评估指标
对于RQ1,自动提示和模糊循环每个任务用时24小时
对于其他RQ,使用10000个生成的模糊输入的模糊预算,并重复四次进行消融研究。
环境
Ubuntu 20.04.5 LTS、256 GB内存、RTX A6000 GPU
评估指标
我们使用广泛采用的代码覆盖率度量来评估模糊工具[7,36,76]。为了统一,我们报告了评估中研究的每个目标的line coverage。根据先前的工作[36],我们使用Mann-Whitney U型检验来计算统计显著性。我们还将输入的有效率(%valid)测量为生成的有效且唯一的模糊输入的百分比。由于Fuzz4All同时支持通用模糊和目标模糊,为了评估目标模糊的有效性,我们报告了命中率,即使用特定目标特征的模糊输入的百分比(用简单的正则表达式检查)。最后,我们还报告了模糊化最重要的指标和目标:Fuzz4All在九个SUT中检测到的错误数量。
四、结果分析
4.1、RQ1:Fuzz4Aall与现有模糊器相比如何?
随时间变化的覆盖率

图中的实线表示平均覆盖率,范围表示五次测试下来的最大值和最小值,每一幅小图中,都是Fuzz4All与其语言对应的模糊器的比较。
生成测试的有效性、数量和覆盖率
 这张表中展示了对于不同的被测目标,Fuzz4All与相对应应用于该目标的模糊器进行比较,分别是在生成测试的有效性、数量和覆盖率这三个方面进行比较。
这张表中展示了对于不同的被测目标,Fuzz4All与相对应应用于该目标的模糊器进行比较,分别是在生成测试的有效性、数量和覆盖率这三个方面进行比较。
4.2、RQ2:Fuzz4All在执行有针对性的模糊处理方面的有效性如何?
这里主要是评估Fuzz4All执行有针对性的模糊处理的能力,即生成聚焦于特定特征的模糊输入。对于每个目标SUT和语言,我们针对三个不同的示例特征,并将它们与RQ1中使用的具有一般用户输入的设置进行比较(如第4.3节所述)。这些功能是内置的库或函数/API(Go、C++和Qiskit)、语言关键字(C和Java)和理论(SMT)。目标模糊运行的用户输入是我们关注的特定功能的文档。表3显示了目标模糊的结果以及RQ1中使用的默认通用模糊。每一列都代表一个有针对性的模糊化运行,我们将重点放在一个特性上。每个单元格中的值显示了特定模糊运行的特征(第4.3节)的命中率。我们还包括获得的覆盖结果。
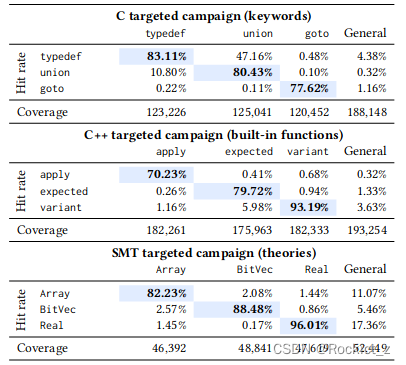
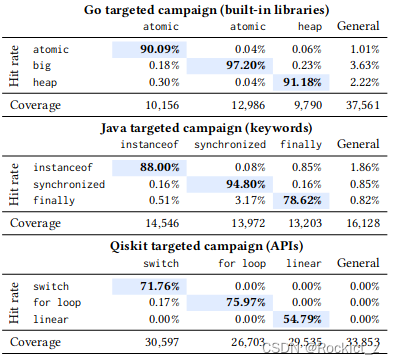
4.3、RQ3:不同的组件如何影响Fuzz4All的有效性?
这里主要是基于Fuzz4All的两个关键组件进行了消融研究:(a)自动提示,即提供给生成LLM的初始输入提示的类型;(b) 模糊循环,使用选定的例子和生成策略。我们研究了两个关键组成部分中每一个的三种变体。

首先,我们研究了提供给生成LLM的不同初始输入的影响。为了减少额外因素的影响,我们将生成策略固定为仅使用生成新的并研究三个变动条件下的覆盖率和有效性
- 1)无输入不使用任何初始提示
- 2)原始提示直接使用原始用户输入作为初始输入
- 3)autoprompt应用autoprompt生成初始提示
接下来,我们通过保持初始提示相同(通过使用默认的自动提示)来检查模糊循环设置的不同变体:
- 1)
w/o example表示在模糊循环期间不选择示例(即,它从相同的初始提示连续采样) - 2)
w/ example选择示例但仅使用生成新指令2 - 3)Fuzz4All是使用所有生成策略的完整方法。
4.4、RQ4:Fuzz4All在现实世界中发现了哪些bug?

五、结论
我们介绍了Fuzz4All,这是一种通用模糊器,利用LLM来支持任意SUT的通用模糊和有针对性的模糊,这些SUT采用多种编程语言。Fuzz4All使用一个新颖的自动提示阶段来生成输入提示,简要总结用户提供的输入。在模糊循环中,Fuzz4All使用代码示例和生成策略迭代更新初始输入提示,以产生不同的模糊输入。对六种不同语言的九种不同SUT的评估结果表明,与最先进的工具相比,Fuzz4All能够显著提高覆盖率。此外,Fuzz4All能够检测到98个bug,其中64个已经被开发人员确认为以前未知的。

