
- 1如何做好单元测试_简述如何做好单元测试的各个阶段的管理工作。
- 2C4.5算法详解(非常仔细)_c4.5决策树流程
- 3JAVA?:使用_? java
- 4【BUG日记】【Maven】【SpringBoot】启动项目的时候,报错:If you want an embedded database (H2, HSQL or Derby)
- 5Baidu Comate智能代码助手-高效代码编程体验_智能代码助手comate
- 6遇到软件测试职业瓶颈,如何突破_测试部门想突破的事
- 7XCode 开发证书配置(更换电脑后)_xcode accounts user manger
- 8Vue 使用 Video.js_vue使用video.js
- 9Redis - 高并发场景下的Redis最佳实践_翻过6座大山_redis 并发
- 10扫雷游戏(C语言实现,快三万字超详细教程+源码)_扫雷算法的流程图
为什么GPU比CPU更适合人工智能计算?_ai算法为什么和gpu有关
赞
踩
人工智能模型,也称为神经网络,本质上是一个数学千层面,由一层又一层的线性代数方程组成。每个方程都表示一段数据与另一段数据相关的可能性。
就其本身而言,GPU 包含数千个内核,微型计算器并行工作,以切开构成 AI 模型的数学。从高层次上讲,这就是人工智能计算的工作原理。
作为加速机器学习工作负载的主要计算平台,GPU在过去的五年里基本成为大模型训练的标配。它能够协助处理训练和部署人工智能算法所涉及的众多计算任务,极大地推动了AI领域的发展。
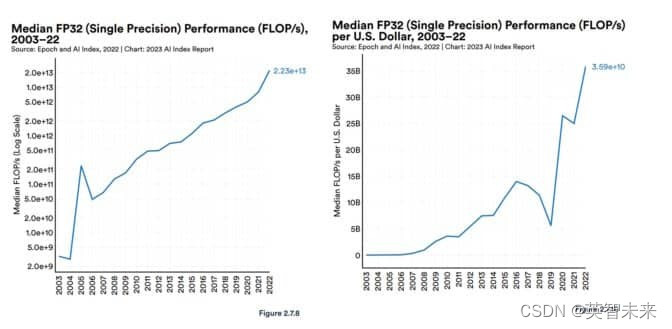
斯坦福人工智能小组报告中称,自2003年以来,GPU性能“增长了大约7000倍”,性能价格比“增长了5600倍”。
当下主流的AI处理器毫无疑问是NVIDIA的GPU,大型语言模型 (LLM) 在数千个 NVIDIA GPU 上训练和运行,运行超过 1 亿人使用的生成式 AI 服务。并且,英伟达针对不同的场景推出了不同的系列和型号。例如:L4用于AI视频,L40用于图像生成,H100系列则是大模型,GH200是图形推荐模型、矢量数据库和图神经网络。
点击查看不同型号的价格:https://www.baystone.ai/airesource
为了满足AI模型不断变化的需求,NVIDIA 的工程师已经优化了 GPU 内核,最新的 GPU 包括 Tensor Core,其功能比第一代设计强大 60 倍,用于处理矩阵数学神经网络。
此外,NVIDIA Hopper Tensor Core GPU 包括一个 Transformer 引擎,该引擎可以自动调整到处理 Transformer 模型所需的最佳精度,Transformer 模型是催生生成式 AI 的一类神经网络。
目前最先进的 LLM GPT4 包含超过一万亿个参数,这是其数学密度的指标。这比 2018 年流行的 LLM 的不到 1 亿个参数有所增加。
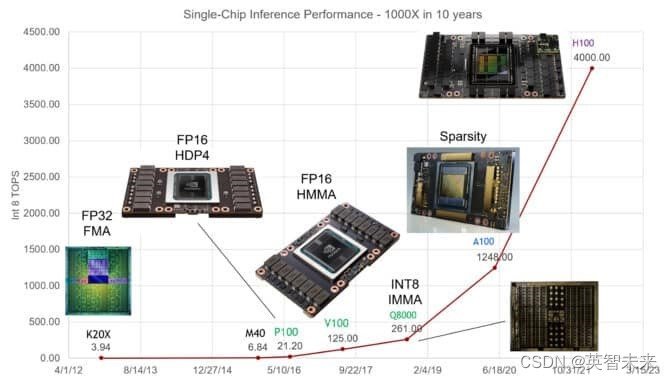
在最近的Hot Chips演讲中,NVIDIA首席科学家Bill Dally详细描述了过去十年中单个GPU在AI推理方面性能的惊人增长,达到了1000倍的扩展,为了跟上这个优化进度,GPU系统通过协同应对各种挑战。利用快速的NVLink互连技术和NVIDIA Quantum InfiniBand网络,它们能够扩展到超级计算机的规模。
例如,DGX GH200 是一款大内存 AI 超级计算机,可将多达 256 个 NVIDIA GH200 Grace Hopper 超级芯片组合到一个数据中心大小的 GPU 中,具有 144 TB 的共享内存。
每个 GH200 超级芯片都是一台服务器,具有 72 个 Arm Neoverse CPU 内核和 4 petaflops 的 AI 性能。新的四路 Grace Hopper 系统配置在单个计算节点中提供了高达 288 个 Arm 内核和 16 petaflops 的 AI 性能以及高达 2.3 TB 的高速内存。
11 月发布的 NVIDIA H200 Tensor Core GPU 采用高达 288 GB 的最新 HBM3e 内存技术。
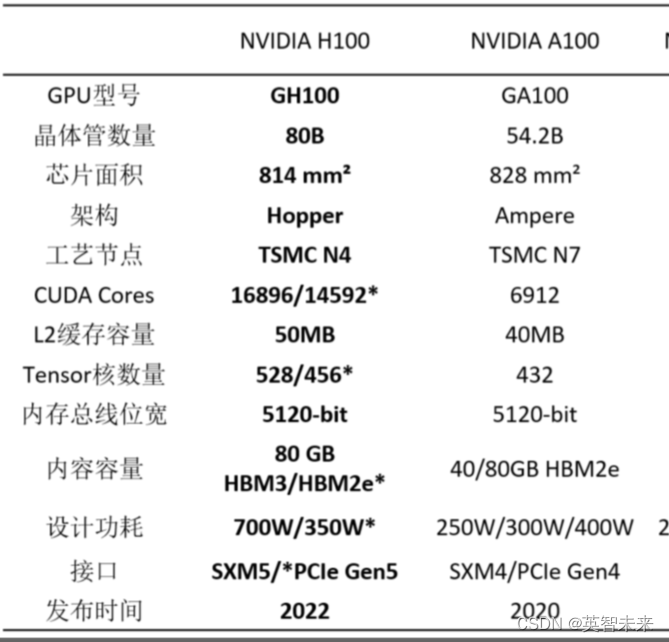
英伟达GPU常见型号参数
Baystone算力聚合平台,聚合全球智算算力运营商算力资源(GPU 服务器),算力运营商分布在美国、日本、中国、新加坡、德国等国家和地区,就近为您提供所需规格的智算算力,算力聚合服务为您提供统一的SLA。

