- 1[图解]SysML和EA建模住宅安全系统-04_sysml案例 ea
- 2idea 换maven项目jdk版本_idea maven 更换项目的jdk
- 3fpga快速入门书籍推荐_fpga入门书推进
- 4实验 5 Spark SQL 编程初级实践
- 5Git忽略已经上传的文件和文件夹_git 忽略文件以及忽略已上传文件
- 6解决哈希碰撞:选择合适的方法优化哈希表性能
- 7idea java 插件开发_IDEA插件开发之环境搭建过程图文详解
- 8《五》Word文件编辑软件调试及测试
- 9ubuntu下faster-whisper安装、基于faster-whisper的语音识别示例、同步生成srt字幕文件_装faster whisper需要卸载whisper吗
- 10大疆 植保无人机T60 评测_大疆t60无人机参数
DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for WSI_论文笔记
赞
踩
文章链接:https://arxiv.org/pdf/2203.12081.pdf
一.摘要:
多实例学习(MIL)在组织病理学全切片图像分类中的应用越来越广泛。然而,用于这一特定分类问题的MIL方法仍然面临着独特的挑战,特别是那些与小样本队列相关的挑战。其中,WSI幻灯片(包)的数量有限,而单个WSI的分辨率很大,这导致从该幻灯片中裁剪大量补丁(实例)。为了解决这个问题,我们提出通过引入伪包的概念来增加包的数量,并在伪包的基础上构建双层MIL框架,以有效地利用内在特征。此外,我们还推导了基于注意的MIL框架下的实例概率,并利用该推导帮助构建和分析所提出的框架。所提出的方法在CAMELYON-16上的性能优于其他最新方法,而且在TCGA肺癌数据集上的性能也更好。
二.介绍:
WSI具有巨大的尺寸,从100M像素到10G像素不等,这一独特的特性使得直接将现有的机器学习技术转移到WSI几乎不可行,因为这些现有的技术最初是用于自然图像或小得多的医学图像。对于基于深度学习的模型,大规模的数据集和高质量的注释是训练高容量模型的主要但至关重要的条件。然而,wsi的巨大尺寸给像素级注释带来了巨大的负担。这个问题反过来又鼓励研究人员开发基于深度学习的模型,用有限的注释训练,称为“弱监督”或“半监督”。现有的弱监督WSI分类工作中有很大一部分被描述为“多实例学习”(MIL)。在MIL框架下,一个切片(或WSI)充当一个包,其中有多个实例,是从切片中裁剪的数百或数千个patch。如果至少有一个实例为疾病阳性,切片被标记为阳性。
问题:WSI分类最臭名昭著的后果是过拟合问题,机器学习模型在优化过程中容易陷入局部极小值,而学习到的特征与目标疾病的相关性较低,因此,训练的模型泛化能力较差。MIL为WSIs解决过拟合问题的最新工作是建立在利用更多信息来学习的基本思想之上的,而不是在于相对较少的幻灯片上的标签。
解决过拟合的方法:mutual-instance relation互实例关系:实例间的相互关系可以指定为空间或特征距离,也可以由神经模块不可知地学习,如循环神经网络(RNN),transformer和图卷积网络。上述许多方法都属于基于注意的MIL (AB-MIL),尽管它们在注意分数的公式上有所不同。然而,在AB-MIL框架下显式推断实例概率被认为是不可行的,作为一种替代方法,注意力得分通常被用作阳性激活的指标。
仍然存在的问题:用于WSI分类的MIL模型本质上旨在识别与切片标签相对应的最具特色的补丁。然而,切片数量有限,而一张切片中有数百甚至数千个补丁(实例),用于学习的信息只是切片级别的标签。此外,在许多组织病理学切片中,阳性疾病对应的阳性区域仅占组织的一小部分,导致切片阳性实例的比例很小。因此,在MIL条件下指导模型识别正实例具有挑战性,因为这些因素共同加剧了过拟合问题。
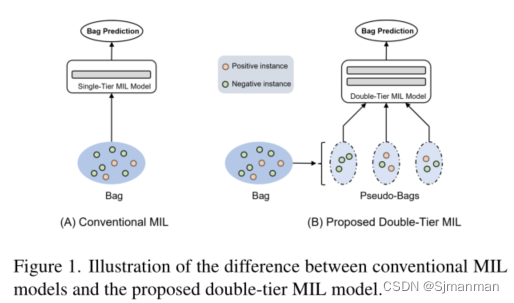
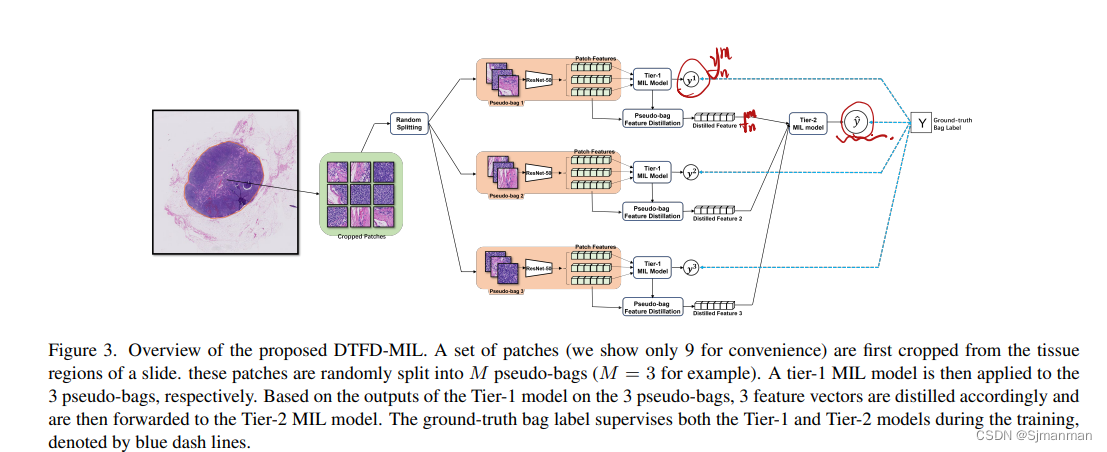
本文的解决方法:为了减轻这些问题的负面影响,我们在建议的框架中引入了“伪袋”的概念。也就是说,我们将一个包(切片)的实例(补丁)随机分割为几个更小的包(伪包),并为每个伪包分配原始包的标签,称为父包。这种策略实际上增加了包的数量,而每个伪包内部的实例更少;实现了双层特征蒸馏MIL模型(图1)。更具体地说,所有幻灯片的伪包都应用了Tier-1 AB-MIL模型。然而,随之而来的风险是,来自阳性父包的伪包可能没有分配到至少一个阳性实例,在这种情况下,引入了一个错误标记的伪包。为了解决这个问题,我们从每个伪袋中提取一个特征向量,并根据从一张切片的所有伪袋中提取的特征建立Tier2 AB-MIL模型(如图3)。通过蒸馏过程,Tier-1模型为Tier-2模型提供了不同特征的初始候选,从而为相应的父包生成更好的表示。此外,为了进行特征蒸馏,我们利用为可视化深度学习特征而提出的grad -cam的基本思想,在AB-MIL框架下推导出实例概率。
三.相关工作:
1.MIL
MIL模型一般可以分为两组,基于最终的包预测是直接来自实例预测,还是来自实例特征的聚合。对于前者,包预测通常通过平均池化(实例概率的平均值)或最大池化(实例概率的最大值)获得。后者学习包的高级表示,并在此基础上建立分类器进行包级预测,通常称为袋嵌入法。尽管实例级概率池简单明了,但经验证明在性能上不如包嵌入。
许多基于袋嵌入的模型采用了AB-MIL的基本思想,即袋嵌入(或袋表示)是通过对单个实例的特征进行加权得到的,而最新的这类研究在权重值的生成方式上存在差异,这些权重值通常被称为注意力得分。例如,在原始论文中,注意力分数是由侧分支side-branch network网络学习的,在DS-MIL中,注意力分数是基于实例的特征与关键实例之间的余弦距离,而在Trans-MIL中,它们是编码实例之间相互相关性的transformer架构的输出。
2.Grad-based Class Activation Map类激活图
类激活图(CAM)最初是作为一个空间可视化工具,用于揭示图像中与深度学习模型分类对应的位置。作为其广义版本,Grad-CAM (Grad based Class Activation Map)]能够从多层感知(MLP)的更高复杂架构中生成CAM。将其作为设计的深度学习模型中的嵌入式组件用于各种应用。例如,CAM的一个显著功能是仅使用图像标签训练的模型的目标定位。
四.方法:
1.Attention-Based Multiple Instance Learning
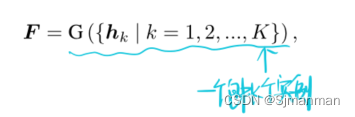
其中G是一个聚合函数。hk是实例k提取的特征。
通常,采用注意力策略来获得包的表现:
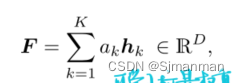

ak由注意力得到的分数。

2. Derivation of Instance Probability in AB-MIL推导实例概率
实例k的信号强度为c类(c = 0为负,c = 1为正),则可导出为:
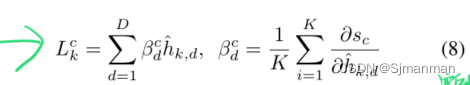
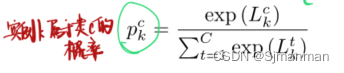

3.Double-Tier Feature Distillation Multiple Instance Learning
一个幻灯片(包)中的实例被随机分成M个伪包,实例数量大致相等。
![]()
伪包的标签被分配给它的父包的标签:![]()
Tier-1模型输入为伪包,网络模型H,模型输出为估计的伪袋概率为:
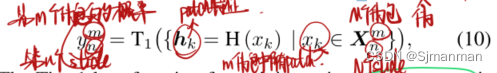
Tier-1损失函数:交叉熵
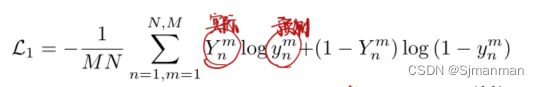
每个伪袋中实例的概率可由式(8)和式(9)导出。基于派生的实例概率,从每个伪包中提取一个特征,对于第n个父包的第m个伪包,表示为fmn。所有提取出来的特征被转发到第二层AB-MIL,记为T2,用于父包的推断。

T2损失函数:
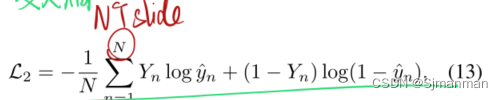
整体优化过程为:
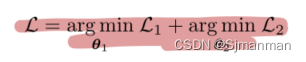
4.考虑四种特征蒸馏策略:
1.最大选择:选择正概率(阳性概率)最大的实例特征(一个伪包中的)送入T2网络。
2.正概率最大和最小的实例特征
3.选择具有最大注意力分数的实力特征
4.选择聚合伪包中的所有实例特征。
五.实验结果:

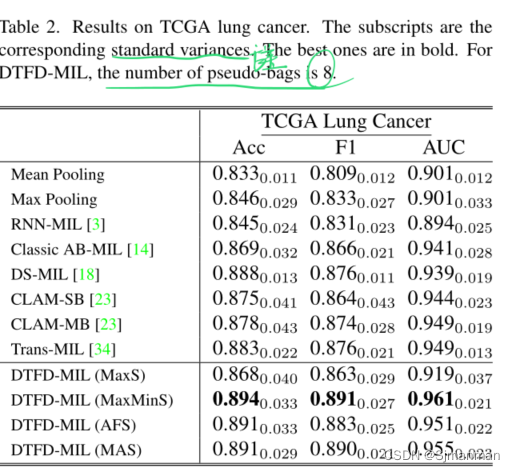
预处理:应用OTSU的阈值方法来定位每个WSI中的组织区域。然后从组织区域中提取大小为256x256像素的不重叠斑块,在20X放大倍率下。CAMELYON-16数据集总共有370万个补丁,TCGA肺癌数据集总共有830万个补丁。
指标:对于所有的实验,曲线下面积(AUC)是报告的主要性能指标,因为它更全面,对类别不平衡不那么敏感
通常情况下,实例级方法(Mean Pooling, Max Pooling)在性能上不如基于包嵌入的方法。
可视化:为了进一步探索所提出的实例概率推导,我们训练了一个经典的AB-MIL模型,并从CAMELYON16中生成了5张幻灯片的5个子字段的热图。这些热图来自(1)标准化注意力得分(基于注意力);(2)分别用式(8)和式(9)求补丁概率(基于导数)。
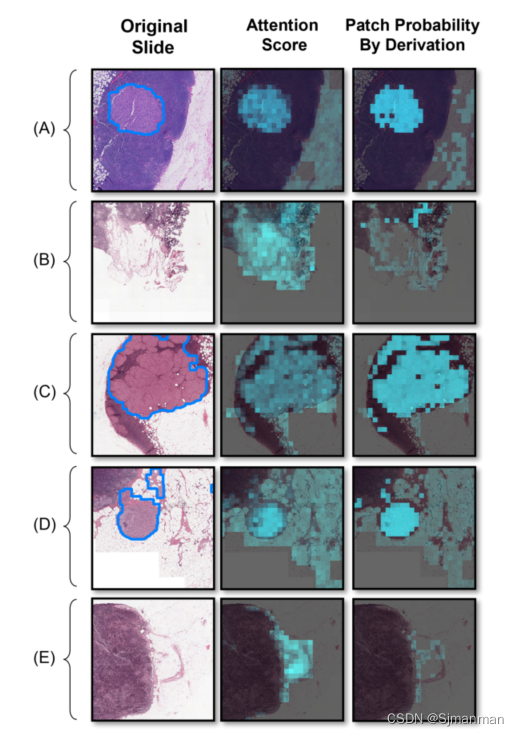
热图表明,与注意力得分相比,实例概率推导在定位积极激活方面具有更好的能力。具体而言,通过实例概率推导得到的热图中的正激活更加一致和准确,与注意力得分相比呈现出更好的对比。此外,在ground-truth阴性幻灯片中,注意力得分热图中总是存在较强的假阳性区域,而在实例概率推导的热图中,这些区域大多可以被正确识别为阴性。
伪包的数量的消融实验:
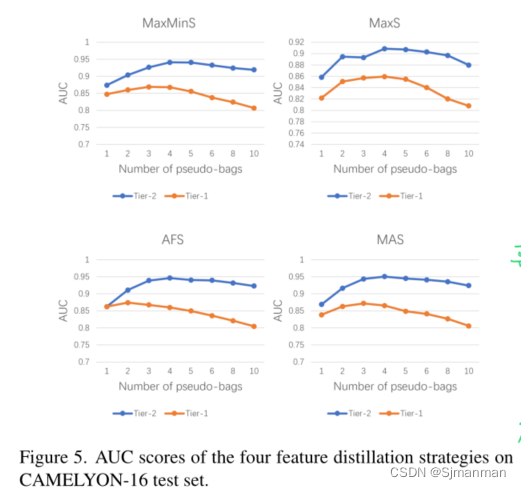
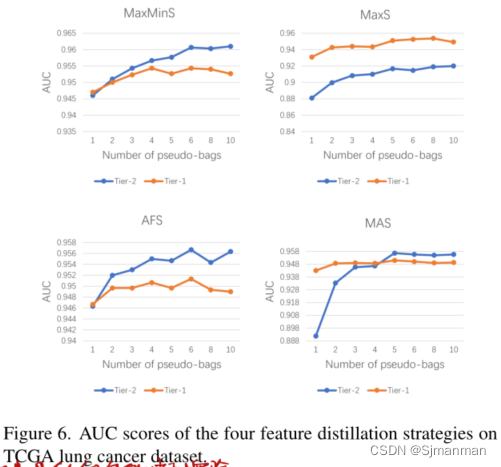
(1)伪袋思想对Tier-1和Tier-2 MIL模型都有利。然而,Tier-1模型对CAMELYON16的伪袋数更为敏感:当伪袋数从3开始增加时,对应的AUC分数急剧下降。相比之下,在TCGA肺癌数据集中,Tier1模型对伪袋数的敏感性较低,即使在伪袋数适当的情况下,Tier1模型也能达到较高的性能。这种现象主要是由于CAMELYON-16阳性切片中肿瘤多为小区域,而TCGA肺癌则相反;因此,在CAMELYON-16中,伪包很有可能没有分配至少一个来自阳性父包的阳性实例。这很好地证明了我们最初的动机,即通过从相应的伪包中提取特征来建立第二级MIL模型,总体而言,Tier-2模型的性能确实优于Tier-1模型,特别是CAMELYON-16。
(2)在四种特征蒸馏策略中,DTFD-MIL (MaxS)的性能无法与其他三种相比较,在TCGA肺癌数据集上,使用MaxS特征蒸馏时,Tier-2 MIL模型甚至不如Tier-1 MIL模型。这意味着采用具有最高正概率的实例来形成袋子的表示并不总是最佳选择。这一现象也与图4的观察相吻合,在阴性切片中,最强的激活来自中性甚至空白区域(对应于肿瘤的概率近似为零),而不是非肿瘤组织区域。
六.句子摘抄:
The increasing use of WSIs in histopathology results in digital pathology providing huge improvements in workflow and diagnosis decision-making by pathologists, but it also stimulates the need for intelligent or automatic analytical tools of WSIs.
When it comes to deep learning based models, large scale datasets and high quality annotations are the primary yet crucial conditions to train a high capacity model.
However, the enormous sizes of WSIs bring along substantial burden for pixel-level annotation. This problem in turn encourages researchers to develop deep learning based models trained with limited annotations, termed as “Weakly Supervised” or “Semi-Supervised”. A large proportion of existing weakly supervised works for WSI classification are characterized as “multiple instance learning” (MIL).
Most recent works of MIL for WSIs to tackle the overfitting issue are built on the essential idea of exploiting more information to learn in addition to the labels of the relatively small number of slides in a cohort.
MIL models for WSI classification essentially aim to recognize the most distinctive patches that correspond mostly to the slide label.
In essence, we deal with the MIL problem for WSI classification from another perspective with the proposed double-tier MIL framework.
Providing the importance of weakly supervised learning, there is a trend to develop MIL algorithms for WSI analysis where, instead of elaborated pixel-level annotation, only the slide labels are available for training.
However, deep neural networks are resilient to noise labels to some extent.
The results of all the other methods are from the experiments conducted using their official codes under the same settings.
七.代码(待补充)
1.命令行参数
- parser = argparse.ArgumentParser(description='abc')
- #使用了argparse.ArgumentParser()函数来创建一个ArgumentParser对象,然后使用add_argument()方法来添加命令行参数。
- parser.add_argument('--data_dir', default='', type=str) #### ####
- parser.add_argument('--device', default='cuda', type=str)
- parser.add_argument('--num_worker', default=4, type=int) #子线程个数
- parser.add_argument('--crop', default=224, type=int)
- parser.add_argument('--batch_size_v', default=64, type=int)
- parser.add_argument('--log_dir', default='', type=str) #### #### 存储pkl的路径
- parser.add_argument('--img_resize', default=256, type=int)
使用:
- def main():
- args = parser.parse_args() #解析器解析出的数据放在argparse.Namespace对象中,然后将其赋值给变量args
- #使用:args.data_dir;args.batch_size_v等等

2.图像归一化
- normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #将图像进行归一化处理,其中mean和std是在ImageNet数据集上计算得出的。
- test_transform = T.Compose([
- T.CenterCrop(args.crop), #RandomCrop(224), #对图像进行中心裁剪
- T.ToTensor(), #将图像转换为张量
- normalize, #图像进行归一化处理
- ]) #应该是对测试数据集进行的操作


3.glob()函数
- for tslideName in SlideNames: #tslideName是指定目录slide_dir下的子目录名称
- #读取指定目录下的图像文件,并将其存储在列表tpatch_paths中
- tpatch_paths = glob.glob( os.path.join(slide_dir, tslideName, '*.'+surfix)) #获取patch路径加名称加后缀的整个路径
- #glob.glob()函数是Python标准库中的一个函数,它可以根据指定的规则搜索文件路径,并返回符合规则的文件路径列表。
- #其中,规则可以使用通配符来表示,例如*表示匹配任意字符,?表示匹配单个字符等。这个函数返回的是一个列表,其中每个元素都是一个字符串类型的文件路径。
- self.patch_dirs.extend(tpatch_paths)
- #这段代码的作用是将列表tpatch_paths中的元素添加到列表self.patch_dirs中。
- # 其中,self.patch_dirs是一个类的成员变量,它是一个列表类型的变量。这段代码的作用是将列表tpatch_paths中的元素添加到列表self.patch_dirs中,以便于后续读取图像文件

4.os.path.basename()函数

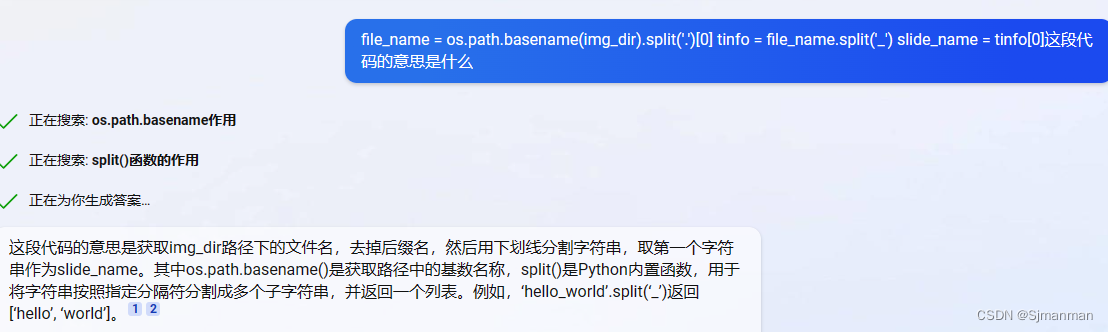
- file_name = os.path.basename(img_dir).split('.')[0] #img_dir路径下的文件名,去掉后缀名
- tinfo = file_name.split('_')