
- 1SQL基础语句大全,建库建表及增删改查(一)_sql语句创建
- 2Unity 动态创建Mesh 基础方法与高级方法_unity 动态生成mesh
- 3Stable Diffusion——文生图界面参数讲解与提示词使用技巧_文生图关键词
- 4计算机系统常见故障及处理,电脑常见故障以及解决方案都在这里!
- 5尚硅谷《MySQL高级特性篇》教程发布_尚硅谷mysql md课件
- 6PowerDesigner中用JDBC连接MySQL_powerdesigner 通过jdbc 链接mysql
- 7〔003〕Stable Diffusion 之 界面参数和基础使用 篇_stable diffusion 参数设置_stable diffusion prompt 参数详解
- 8pycharm 安装“通义灵码“并测试_2019版本的pycharm支持通义灵码吗
- 9万字长文精解目标检测中的TP、FP、FN、TN、Precision、Recall 、 F1 Score、AP、mAP与AR 。附代码实现。_计算yolov5tp, fp, fn, recall和precision
- 10git使用总结_git查看全局配置
Kafka介绍_kafka有主节点吗
赞
踩
Kafka介绍
一、Kafka是什么?
Kafka是Linkedin于2010年12月份开源的消息系统,一个高吞吐量分布式消息系统。
提供了类似JMS的特性,但是在设计实现上完全不同,不是JMS规范的实现。
主要应用场景:Messaging、Website Activity Tracking、Metrice、Log Aggregation、Stream Processing
Kafka发送消息性能远高于ActiveMQ的任何存储方式。
Kafka消费少量消息的时候,性能优势不明显,甚至可能会低于文件存储系统的ActiveMQ,但是发送大量消息的时候,性能优势非常明显。
Kafka的集群算法做的很先进,大大强于ActiveMQ。ActiveMQ只有主从互备的HA,负载均衡做的不好,没有消息分片。而Kafka在HA,负载均衡和消息分片上做的很完美。
二、Kafka的设计目标
1、消息数据保存在磁盘,存取代价为O(1)。一般数据在磁盘上是使用BTree存储的,存取代价为O(lgn)。
2、高吞吐率。在普通的节点上,单机每秒10W消息读写。
3、支持分布式,所有的producer、broker和consumer都会有多个,均为分布式的。
4、支持数据并行加载到Hadoop中。
三、Kafka的设计理念
Kafka是一个高性能,高可用,可持久化的,为分布式设计的消息中间件。与标准的,如ActiveMQ这样的消息中间件不同,Kafka对消息的“仅仅发送一次”并不关注。
Kafka的设计初衷是提供一个统一的处理实时数据的平台。和普通的消息中间件一样,Kafka也分为消息生产者,消息消费者和消息中介。
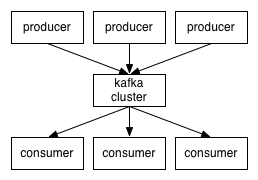
kafka对消息保持时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群由多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
每一种消息的分类,叫主题(Topic)。一个消息中介可以包含多个不同的主题。为了分布式设计,每个主题又可以分成多个分区(Partition)。每个分区都是一个顺序写入,且不可变的文件。每个新的消息总是追加到文件尾部。每个消息都有一个编号(Offset偏移量),消费者可以通过这个编号选择消费消息。如下图:

1、分区
由于主题都可以分成不同的分区,而每个分区可以分布在不同的机器上,所以实现了分布式功能。Kafka通过Zookeeper实现注册中心,会将消息生产者,消费者,消息中介的元数据存储到Zookeeper上。Kafka会自动将分区分配到不同的机器上。
对于将哪些消息发送到哪些分区,Kafka默认使用轮询调度的方式分配。但是也可以根据自己的业务场景,定制化实现消息分区逻辑。每个分区的消费都是按照顺序的,但是跨分区的消息不保证顺序性。
2、消费
Kafka为消费者提供了GroupID的功能,同时只能有一个拥有同样GroupID的消费者,消费一个分区。这个有点像ActiveMQ里面的Exclusive Consumer功能。我们都知道,消息中间件分为Queue和Topic两种模式。如果每个消费者拥有同样的GroupID,那么这个主题就是被当做Queue方式消费,因为不会有消费者消费同样的消息;如果每个消费者拥有不同的GroupID,那么这个主题就是被当做Topic方式消费,因为每个消费者都会消费一遍这个消息。
3、Push/Pull
消息生产者使用标准的推送(push)模型,将消息推送到消息中介。但是消息消费者不同,它使用拉取(pull)模型,主动的将消息从消息中介拉取到客户端。这样消息中介不需要维护消息的使用状态。
消息推送的优势是,消息的实时性高,一旦消息中介接收到消息,可以马上推送给消费者。并且方便维护消息的消费状态。但是缺点也比较明显,不能得知消费者的状态,如果碰到消费者比发送者慢的情况,很容易造成消费者的消息堆积,最终压垮消费者。
使用拉取模型,消费者可以根据自己的状态选择什么时间拉取多少消息,不会造成消费者的拥堵。并且为了提升吞吐量,可以一次批量拉取多条消息。
4、消息传递保障方式
Kafka的消息中介不会存储消息消费的状态,而是把消息消费到哪里的偏移量存到客户端,并且同步到Zookeeper。可以选择批量同步,这样做的优势是提升吞吐量,风险是如果消费者崩溃,未同步的偏移量会导致消息重新消费。
这个就引出了消息传递的语意。系统可以提供3种可能的消息传递保障方式:至多一次,至少一次和仅仅一次。
至多一次是消息发送以后,无论消费者是否成功消费,消息都不会再重新发送。这个风险比较大,会丢消息。
至少一次是,消息即使被消费,如果由于网络等原因造成消费状态没有同步,那么下次还是会消费同样的消息。这样虽然不会丢失消息,但是会导致重复消费,这就需要业务程序实现幂等性,即无论消费多少次都是同样的结果,这个对业务端的程序要求比较苛刻。
最理想的方式当然是仅仅一次。这样如果消费消息之后,再存储消息已经被消费的状态时出现异常,那么被消费的数据会回滚,就当做消息没有消费。这是消息系统最完美的保障,但是是以牺牲性能为前提,所以使用仅仅一次的消费模型时需要确认,是不是真的有必要。
ActiveMQ等JMS实现的消息中间件支持仅仅一次的消费模型,Kafka由于设计理念不同,只支持至少一次,牺牲一致性换取性能。
5、存储方式
Kafka直接使用磁盘进行存储,没有使用缓存。由于操作系统本身是有缓存功能的,会先将数据放入缓存,经过一定时间刷盘存入硬盘。如果再使用JVM缓存,就会造成有两份缓存。Kafka最大限度的利用操作系统的缓存,所以如果想提升Kafka的性能,使用固态硬盘是个很好的手段。
因为Kafka只是追加数据和顺序读,不会随机读写,所以即使直接使用磁盘 效率也很高。
如果想不丢消息,可以修改Kafka的配置参数,每发送一条消息就同步一下磁盘,用降低性能的方式提高安全性。
传统的消息中间件一般是使用Btree的方式存储消息,但是由于Kafka不会有随机读,所以使用BTree并无意义。而且BTree只有在内存中查找数据才比较快,是Log(n)。如果在硬盘中查找,每一次寻道都需要一定时间,大约(10ms),多次寻道会大幅降低效率。
Kafka会自动清理过期消息。无论消息是否被消费,创建时间2天(可设置)的消息将会被删除。
6、消息高可用实现
最后再说一下Kafka的消息高可用实现。Kafka使用复制备份机制存储消息。Kafka收到消息之后会向主节点和从节点发送消息。主节点用于接收和被消费消息,从节点只用于同步消息。Kafka的主从节点不是以服务器为粒度,而是以主题的分区为粒度。这样每台服务器都可能有主分区和从分区。最大限度的利用机器资源,而不是只有一台服务器接收请求,其他服务器等待。
总结一下,Kafka的优势是高性能,高可用。不足是消息可能会被消费多次。
四、Kafka相关概念
1、Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一的标记一条消息。kafka没有提供索引机制来存储offset,因为kafka中不对消息进行“随机读写”。
kafka和ActiveMQ不同的是:即使消息被消费,消息仍然不会被立即删除,日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,之后不管消息是否被消费,文件都会被删除。可以达到减少磁盘IO开支的效果。
consumer需要保持消费消息的offset。
kafka集群不需要维护任何consumer和producer状态信息,这些信息由zookeeper保存。
2、Partitions
一个topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性。
基于replicated方案,就需要对多个备份进行调度;每个partition都有一个server为“leader”;leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是简单的跟进与leader,同步消息即可。leader server承载了全部的请求压力,因此从集群整体考虑,有多少个partitions就有多少个leader,kafka将leader均衡分散在每个实例上,确保整体的性能稳定。
3、Producers
Producers将消息发布到指定的Topic中,同时Producer也能决定将消息归属到哪个partitions,比如基于“round-robin”方式,或者通过其他的一些算法等。
4、Consumers
每个consumer属于一个consumer group。发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
如果所有的consumer都具有相同的group(属于queue模式),消息将会在consumer之间负载均衡。
如果所有的consumer都具有不同的group(属于“发布-订阅”模式),消息将会广播给所有的消费者。
一个partition中的消息只会被group中的一个consumer消费,一个consumer可以消费多个partitions中的消息。kafka只能保证一个partitions中的消息被某个consumer消费是顺序的。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则某些consumer将无法得到消息。
五、Kafka部署结构
kafka是显式分布式架构,producer、broker(Kafka)和consumer都可以有多个。Kafka的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。几个基本概念:
1、message(消息)是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给这些consumer。
2、Kafka是显式分布式的,多个producer、consumer和broker可以运行在一个大的集群上,作为一个逻辑整体对外提供服 务。对于consumer,多个consumer可以组成一个group,这个message只能传输给某个group中的某一个consumer.
六、Kafka集群部署
Kafka的集群算法做的很先进,大大强于ActiveMQ。ActiveMQ只有主从互备的HA,负载均衡做的不好,没有消息分片。而Kafka在HA,负载均衡和消息分片上做的很完美。
Kafka的消息存储在Broker上,每种类型的消息,存在一个Topic里。每个Topic分成多个分区。这些分区可以分布在同一个物理机,也可以分布在不同的物理机。
高可用
Kafka提供一个复制因子的概念,可以把分区复制n份,放在不同的节点上。这就实现了数据的高可用。而服务的高可用,和ActiveMQ类似。是在客户端注册多个Broker地址,其中一个失效,客户端会自动进行失效转移。
消息分片
消息通过轮询,或者自定义的算法写入不同的分区,则实现了消息分片。消息生产者不需要关注消息最终存入Topic的哪个分区,也不需要关注这个分区在哪台物理机上。分片算法会自动把消息路由到正确的分区。这个算法,非常像一致性哈希。其中每个物理机有n个分区,这n个分区是这个物理机的虚拟节点,将这些虚拟节点放入Hash环。
负载均衡
每个Topic分区有n分拷贝,但是只有一个节点负责处理消息的发送和接收,称为主节点。其他节点称为从节点,只是被动的同步消息。一旦主节点不能提供服务,从节点会变为主节点。而主从节点的单位是分区。也就是一台物理机,可以是Topic A的主节点,Topic B的从节点。通过此方式实现负载均衡和最大限度的利用系统资源,不会有专门负责备份的从节点物理机。
Kafka集群的结构图如下:


