
- 1从小红书app开启逆向之旅(1)_小红书app逆向
- 2微信小程序刷新页面数据_wx.getstorage获取的数据还在动态变化怎么办
- 3unity退出游戏_unity退出 游戏到初始界面
- 4python高校舆情分析系统+可视化+情感分析 舆情分析+Flask框架(源码+文档)✅_文本情感分析系统可视化
- 5教你如何提高双目立体视觉系统的精度
- 6vs code无法登陆git_git的相关操作
- 7【机器学习】机器学习:人工智能中实现自动化决策与精细优化的核心驱动力_集成优化目标的核心决策驱动力点?
- 8Unity3D性能优化 (五)——UI
- 9电话机器人 模拟人工打电话
- 10Rust TCP扫描器_rust 检查端口开启
算法时间复杂度分析(一)_算法的量级是什么意思
赞
踩
金庸武侠中描述一种武功招式的时候,经常会用到 “快、准、狠” 这3个字眼。同样,在计算机中我们衡量一种算法的执行效率的时候也会考量3个方面:“快、省、稳”。
具体点来讲就是我们在实现某一种算法的时候,最终目的就是要求计算机(CPU)在最短的时间内,用最少的内存稳定的输出正确的结果。这一章节主要来理解 “快”,至于“省” 和 “稳”,我会在后续章节进行讲解。
那如何来判断某一段代码运行的是否足够快呢??有没有一种标准让我们能迅速判断出某A算法比某B算法好呢??大O复杂度表示法 就是我们要寻找的答案,一般情况下,大O复杂度表示法是用来表示算法性能最常见的正式标记法,接下来就一起来看下这个大O复杂度表示法是个什么东东。
算法时间复杂度的由来
在理解什么是时间复杂度之前,我们需要先了解为什么需要复杂度分析。为了更形象的理解这个问题,我们用一段具体的代码来深入分析。这里有段非常简单的代码,实现了 1,2,3…n 的累加和。
案例1:
// 计算 1, 2, 3…n 的累加和
public class Test {
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果我们要测试以上面这段代码的执行效率,该如何去测试呢 ??
起初,我们能想到最简单最直接的方法就是把代码在机器上跑一遍,通过统计、监控,就能得到这段代码所执行的时间和占用的内存大小。既然是这样那为什么还要做时间、空间复杂度分析呢?复杂度分析会比我实实在在跑一遍得到的数据更准确吗?
首先,我可以肯定的说,这种评估算法的执行效率是正确的,并且在某些数据结构和算法的书籍中还专门给这种方法起了个名字—事后统计法。但是这种统计方法有非常大的局限性
1 测试结果极度依赖测试环境
测试环境中的硬件不同会对测试结果有很大的影响。比如案例1的代码分别跑在Intel Core i9 和 Intel Core i3的CPU上运行,很明显i9要比i3快很多。再比如我们在同一时刻在i9上执行运算1024/3,并在i3上运算10+10。正常来讲 10+10 操作比 1024/3 的操作简单很多,但是因为硬件性能的影响,导致i9处理器更快的得出结果。难道我们能说 1024/3 比 10+10 算法性能更高?显然不能!即使是一个初级工程师也应该知道除法运算比加法运算消耗更高!这样就造成我们很难用一个统一的标准去衡量执行时间。
2 测试结果受数据规模的影响很大
后续我们会讲到多种排序算法。对于同一种排序算法,比如快速排序或者插入排序,待排序数据的有序度不一样,排序的执行时间就会有很大差别。另外,对于不同的排序算法,测试数据规模不同也可能导致无法真实的反应排序的性能。比如,我们手上有一组小规模的数据需要做排序操作
int arr[] = {4, 10, 42, 1, 9};
如果分别使用插入排序和快速排序对 arr 进行排序,我们会发现插入排序比快速排序更快。但是这样不能说明插入排序的性能就比快速排序更高。因为随着arr规模的增长,它的性能会越来越低于快速排序。
综上所述,我们需要一个不用具体的测试数据来测试,用“肉眼”就可以粗略的估计算法的执行效率的方法。而这种方法就是我们今天要讲的 时间复杂度分析方法。
代码复杂度的分析过程
算法的执行时间等于它所有基本操作执行时间之和, 而一条基本操作的执行时间等于它执行的次数和每一次执行的时间的积,如下:
算法的执行时间 = 操作1 + 操作2 + ... + 操作n
操作的执行时间 = 操作执行次数 * 执行一次的时间
- 1
- 2
我们还是以案例1的代码为例。我们知道java代码经过编译之后,最终会被以字节码的方式由JVM来解释执行相应的指令,那我们可以通过如下命令,分别对Test.java进行编译并查看字节码
javac Test.java // 编译java代码,生成.class字节码文件
javap -c Test // 使用javap工具查看字节码指令
- 1
- 2
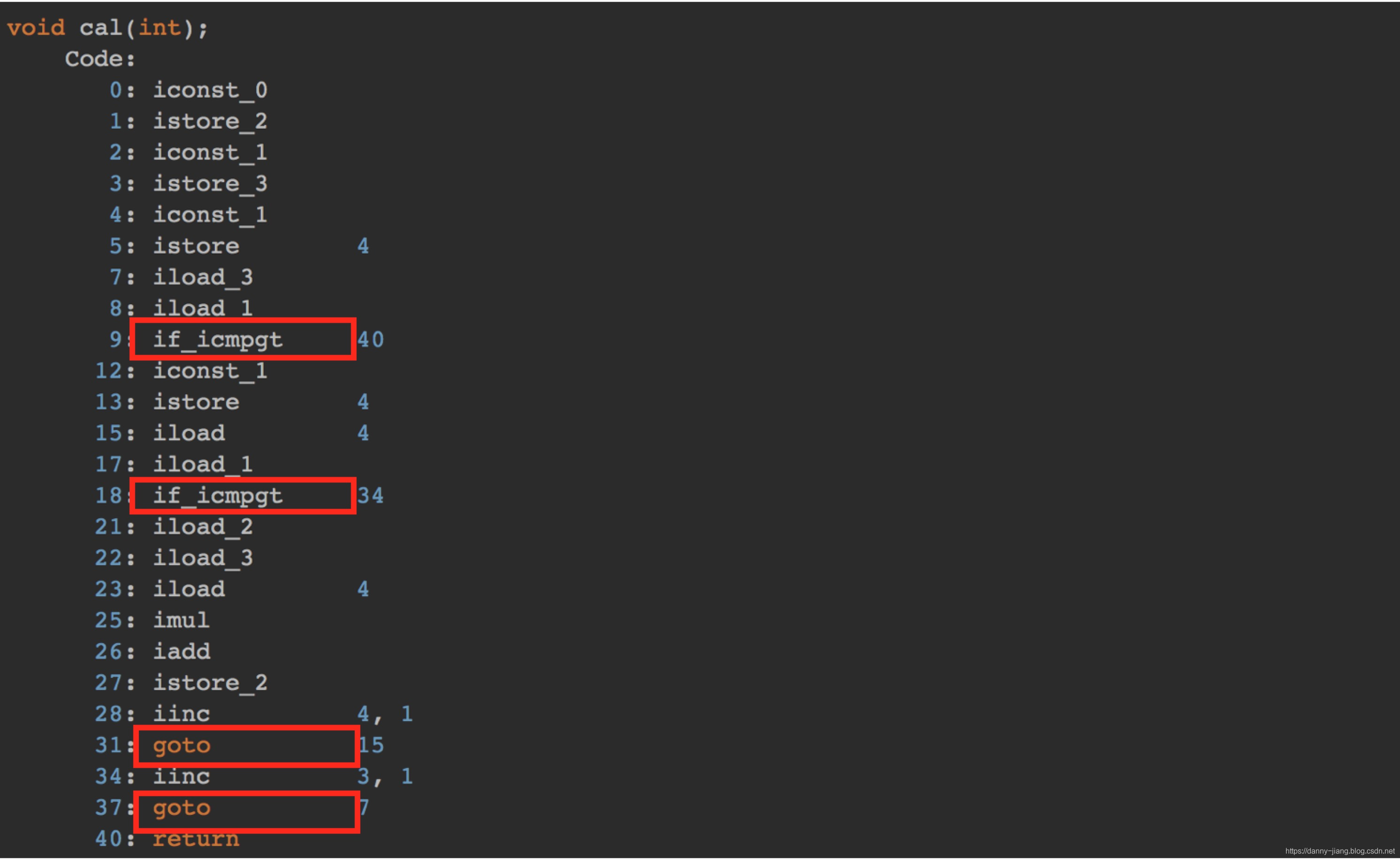
执行上述的javap命令之后,得到的字节码指令如下:

可以看出,案例1主要包含的字节码指令就是 iconst_ istore_ iload_ if_icmpgt iadd 等指令,具体每一条指令所代表的意义我已经添加注释(这块内容有点多,但建议耐心仔细阅研读一下,彻底理解每一条指令的意义,也有助于你理解Java代码的运行机制)
然而存在一个问题,不同的编程语言,不同的编译器,或不同的CPU等因素将导致执行一次指令操作的时间各不相同,这样的结果会使算法的比较产生歧义, 于是我们假定所有计算机执行相同的一次指令操作所需时间相同,统一定为 unit_time 。而把算法中基本操作所执行的 执行次数n 作为量度。就是说我们把算法的 运行时间 简单地用基本操作的 运行次数 来代替了, 进而将分析 运行时间 转移到某一行代码的 运行次数
其中unit_time在不同的CPU上可能不一样,比如在i9 Core上有可能是0.01ms,而在i3 Core上可能就是0.05ms。在这个假设的基础上,我们就可以计算出这段代码的总执行时间。
循环的依据就是if_icmpgt指令。
if_icmpgt 指令判断的是操作数栈顶的两个元素的大小,也就是 i 与 n 的大小,因为从指令 4 到指令 19 一共包含10条指令,所以4~19的指令执行次数为:10 * n * unit_time。
综上所述,这段代码总的执行时间就是:
4 * unit_time + 10 * n * unit_time
= (10n + 4) * unit_time
按照这个分析思路,我们再来看下面这段代码。
案例2
void cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
案例2的代码与案例1的唯一区别就是多了一层for循环。经过javac和javap之后的字节码指令如下:
分析过程同案例1的一样,具体就不再赘述了。最终分析案例2总的执行时间为:(45n² + 5n + 5) * unit_time
算法时间复杂度表示法
上面我们通过分析字节码指令,计算出案例1和案例2代码片段的具体运行时间,如下:
案例1运行时间 -> (10n + 4) * unit_time
案例2运行时间 -> (45n² + 5n + 5) * unit_time
尽管我们不知道 unit_time 的具体值,但是通过对案例1和案例2代码执行时间的推导过程,我们可以得到一个非常重要的规律,那就是 所有代码的执行时间 T(n) 与每行代码的执行次数 n 成正比。
我们可以把这个规律总结成一个公式,注意,大O要登场了
T(n) = O(f()n)
- 1
来解释一下这个公式:T(n)表示代码的执行时间;n表示数据规模的大小;f(n)是一个函数,表示每行代码执行的次数总和。函数f(n)外部的大O表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
注意:大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,
也叫作渐进时间复杂度(aymptotic time complexity),简称时间复杂度。或者说它表达的是随着数据规模n的增长,代码执行时间的增长趋势(类似于物理中的加速度)
案例1运行时间 -> (10n + 4) *unit_time
案例2运行时间 -> (45n² + 5n + 5) *unit_time
最终案例1中的 T(n) = O(10n + 4),案例2中的 T(n) = O(45n² + 5n + 5)。这就是大 O 时间复杂度表示法。
现在我们了解了大O表示法的演进过程,接下来我们再把视线重新放到案例2的复杂度表示上 T(n) = O(45n² + 5n + 5),细看之下,此表达式的函数f(n)部分由3部分组成 (45n² 高阶项) 、 (5n 低阶项) 、 (5 常数项)
现在我们假设 n = 3 时
45n² 高阶项 : 45 * 3 * 3 = 405 占总时间的 95.29%
5n 低阶项 : 5 * 3 = 15
5 常数项 : 5
我们已经看到,n²高阶项部分占据了运行时间的大部分比例。
现在,考虑当n = 100时的结果,如下
45n² 高阶项 : 45 * 100 * 100 = 4500 占总时间的 99.98%
5n 低阶项 : 5 * 10 = 50
5 常数项 : 5
可以看到,n²的部分已经占据了几乎整个运行时间,同时其它项的影响力变得更小,试想一下,如果n = 1000, 将占用多少时间!
由此我们可以看出,当我们以增长率的角度去观察 f(n) 函数的时,有几件事就变得很明显:
- 首先,我们可以忽略常数项,因为随着n的值变得越来越大,常数项最终变得可忽略不计
- 其次,我们可以忽略系数
- 最后,我们只需要考虑高阶项的因子即可,不需要考虑低阶项
综上所述:案例1和案例2的终极大O时间复杂度表达式可以简化为:
案例1: T(n) = O(10n + 4) = O(n) // 时间复杂度为线性级别
案例2: T(n) = O(45n² + 5n + 5) = O(n²) // 时间复杂度为指数级别
时间复杂度简单规则:
前面介绍了大 O 时间复杂度的由来和表示方法。现在我们来看下,当我们拿到一段代码时,如何去分析这一段代码的时间复杂度?
以下是几个比较实用的方法,你可以参考一下:
1 只关注循环执行次数最多的一段代码
我刚才说了,大O这种复杂度表示方法只是表示一种变化趋势。我们通常会忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了。
所以,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码即可。这段代码执行次数的n的量级,就是争端要分析代码的时间复杂度。
为了便于你理解,我还拿前面的例子来说明。
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中第 2、3 行代码都是常量级的执行时间,与 n 的大小无关,所以对于复杂度并没有影响。循环执行次数最多的是第 4、5行代码,
所以这块代码要重点分析。前面我们也讲过,这两行代码被执行了 n 次,所以总的时间复杂度就是 O(n)。
2 加法法则:总复杂度登记量级最大的那段代码的复杂度
我这里还有一段代码。你可以先试着分析一下,然后再往下看跟我的分析思路是否一样
int cal(int n) { int sum_1 = 0; int p = 1; for (; p < 100; ++p) { sum_1 = sum_1 + p; } int sum_2 = 0; int q = 1; for (; q < n; ++q) { sum_2 = sum_2 + q; } int sum_3 = 0; int i = 1; int j = 1; for (; i <= n; ++i) { j = 1; for (; j <= n; ++j) { sum_3 = sum_3 + i * j; } } return sum_1 + sum_2 + sum_3; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这个代码分为三部分,分别是求 sum_1、sum_2、sum_3。我们可以分别分析每一部分的时间复杂度,然后把它们放到一块儿,再取一个量级最大的作为整段代码的复杂度。
第一段的时间复杂度是多少呢?这段代码循环执行了 100 次,所以是一个常量的执行时间,跟 n 的规模无关。
这里我要再强调一下,即便这段代码循环 10000 次、100000 次,只要是一个已知的数,跟 n 无关,照样也是常量级的执行时间。当 n 无限大的时候,就可以忽略。尽管对代码的执行时间会有很大影响,但是回到时间复杂度的概念来说,它表示的是一个算法执行效率与数据规模增长的变化趋势,所以不管常量的执行时间多大,我们都可以忽略掉。因为它本身对增长趋势并没有影响。
那第二段代码和第三段代码的时间复杂度是多少呢?答案是 O(n) 和 O(n2),你应该能容易就分析出来,我就不啰嗦了。
综合这三段代码的时间复杂度,我们取其中最大的量级。所以,整段代码的时间复杂度就为 O(n2)。也就是说:总的时间复杂度就等于量级最大的那段代码的时间复杂度。那我们将这个规律抽象成公式就是:
如果 T1(n)=O(f(n)),T2(n)=O(g(n));
那么 T(n) = T1(n)+T2(n) = max(O(f(n)), O(g(n))) = O(max(f(n), g(n)))
3 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
我刚讲了一个复杂度分析中的加法法则,这儿还有一个乘法法则。当分析一个算法的运行时间时,如果一个任务的执行引起了另一个任务的执行,可以运用此规则。例如,在一个嵌套循环中,外层迭代为T1, 内层迭代为T2, 如果T1 = m, T2 = n, 那么运行结果表示为O(m * n)。
落实到具体的代码上,我们可以把乘法法则看成是嵌套循环,我举个例子给你解释一下
int cal(int n) {
int ret = 0;
int i = 1;
for (; i < n; ++i) {
ret = ret + f(i);
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) {
sum = sum + i;
}
return sum;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们单独看 cal() 函数。假设 f() 只是一个普通的操作,那第 4~6 行的时间复杂度就是,T1(n) = O(n)。但 f() 函数本身不是一个简单的操作,它的时间复杂度是 T2(n) = O(n),所以,整个 cal() 函数的时间复杂度就是,
T(n) = T1(n) * T2(n) = O(n*n) = O(n²)。
我刚刚讲了三种复杂度的分析技巧。不过,你并不用刻意去记忆。实际上,复杂度分析这个东西关键在于“熟练”。你只要多看案例,多分析,就能做到“无招胜有招”。
总结
这一节我们首先学习了为什么要使用算法复杂度分析,主要是因为外部硬件环境与数据规模不一样,会导致我们的计算结果出现偏差。因此需要一套不依赖具体测试数据的机制来衡量算法的性能。
接下里我们通过分析两个案例代码的粗略执行时间,进而引出了大O复杂度表示法,它是一种正式的表达算法时间复杂度的表示法。需要注意的是大O表达式并不表示某种算法具体的运行时间,而是表示代码执行时间随数据规模增长的变化趋势。
最后我总结了几点分析代码复杂度时的简单规则,或者说是技巧。通过这些技巧有助于我们更快的分析出某一段代码的时间复杂度时多少。
更多文章可以扫描二维码,关注算法公众号


