
- 1华为鸿蒙HarmonyOS应用开发者高级认证答案_华为认证答案’
- 2阿维塔在车辆安全中的以攻促防实例 | 附PPT下载
- 3下载代码的一些命令-小记_quicinc
- 4Logistic模型
- 5正确解决can‘t connect to MySQL server on ip(10060)的解决办法异常的有效解决方法_can't connect to mysql server on 10060
- 6GIT远程仓库(随笔)
- 7win10下 docker 配置python pytorch深度学习环境_win10创建docker python
- 8Hive实战案例_hive多维统计分析案例实战
- 9软件架构模式之分层架构
- 10【博客89】考虑为你的inline函数加上static_inline 函数都加了static
Kubernetes容器平台下的 GPU 集群算力管控_gpu mps调度
赞
踩
引言
随着最近一两年生成式大模型的迭代出新,尤其是以 ChartGPT 为代表的大语言模型,几乎一夜间让所有人都看到了人工智能改变世界的潜力。而作为持续发力 GPU 通用计算(CUDA)的 AI 专业显卡提供商,Nvidia 公司成为了当之无愧的技术赢家,从其屡创新高的市值中就可见一瞥。
Kubernetes(简称K8S)作为一种容器编排平台,具有许多独特的优势,尤其是其弹性伸缩的能力,可以实现底层资源的超高利用率。纵观当下的科技产业界,到处是大模型推理、微调训练的需求与 Nvidia 专业显卡一卡难求的矛盾局面。在这种矛盾背景下,将 NVIDIA 显卡与 K8S 容器平台结合起来,组成一个高效的 GPU 算力调度平台,无疑是解决这一难题的最佳技术方案。这种结合将充分发挥每块显卡的算力,并通过 Kubernetes 的弹性伸缩特性,实现对 GPU 算力的灵活调度和管理,为大规模 AI 模型的训练和推理提供了可靠的基础支持。
本文将重点介绍 Nvidia GPU 在 K8S 容器平台上的包括虚拟化、调度和安全性在内的算力管控相关技术。
名词解释
| CUDA | CUDA(Compute Unified Device Architecture)是 NVIDIA 公司推出的并行计算平台和编程模型。它允许开发人员利用 NVIDIA GPU 的并行计算能力来加速应用程序的执行。CUDA 包含了一系列的编程接口和工具,使得开发者可以通过使用标准的 C/C++ 编程语言来编写 GPU 加速的程序。 |
| RootFS | 根文件系统(Root Filesystem),是 Linux 系统启动后所加载的文件系统,也是文件系统的最顶层。它包含了操作系统中的核心文件和目录结构,包括 /bin、/sbin、/etc、/lib、/dev、/proc、/sys 等 |
| Volta、Pascal、Kepler 等 | 不同的 nvidia GPU 架构名称。完整定义如下:
|

基于 K8S 的 GPU 虚拟化框架
GPU 虚拟化,除了 GPU 厂商能够在硬件和驱动层面对各种资源进行划分进而形成隔离的虚拟化方案之外,其他主流方案本质上都是对 CUDA 调用的劫持与管控,这里包括阿里的 cGPU、百度的 qGPU、火山引擎的 mGPU 和灵雀云的 vGPU 方案等。考虑到厂商对于硬件的把控和深入理解,即使出自厂商的 “软” 虚拟化方案,也可以通过硬件配合从而获得更好的效果。下文会重点介绍 Nvidia 公司的虚拟化方案以及基于 Nvidia 方案增强的灵雀云 vGPU 方案。
容器侧:CUDA 工具集
在 K8S 容器平台下,一个典型的 GPU 应用软件栈如下图所示。其中,最上层的是多个包含了业务应用在内的容器。每个容器都分别包含了业务应用、CUDA 工具集(CUDA Toolkit)和容器 RootFS;中间层是容器引擎(docker)和安装了 CUDA 驱动程序的宿主机操作系统;最底层是部署了多个 GPU 硬件显卡的服务器硬件。
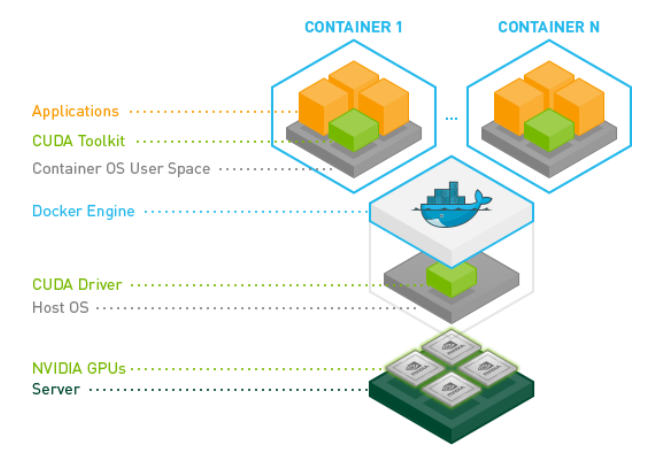
图示:基于 Nvidia 的 GPU 应用软件栈
主要组件
CUDA 工具集包含了 nvidia-container-runtime(shim)、nvidia-container-runtime-hook 和 nvidia-container library、CLI 工具。对比 CUDA 工具集嵌入前后架构图的差异,我们可以很清楚地看到 CUDA 工具集中的组件嵌入位置,甚至推断出其作用。
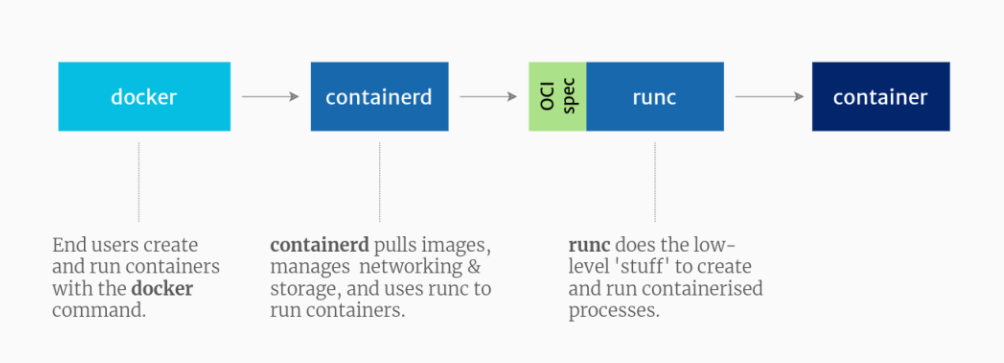
图示:CUDA toolset 嵌入前的容器软件栈
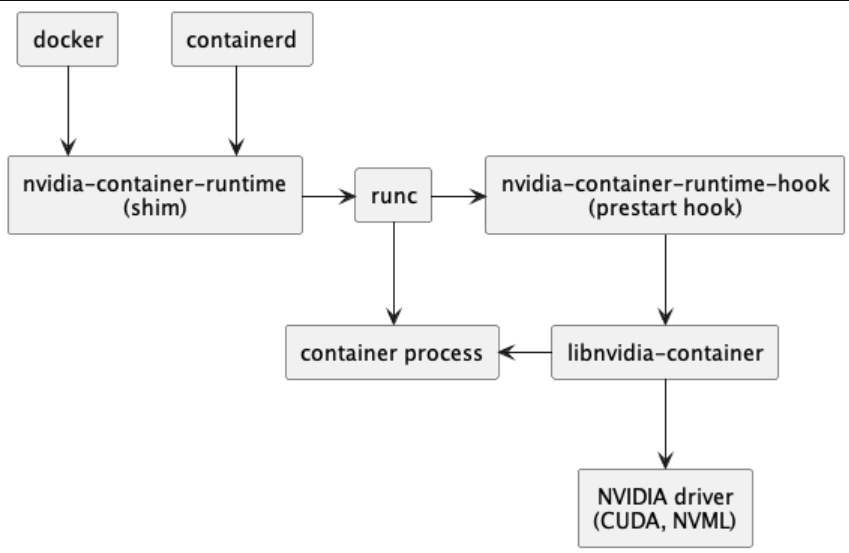
图示:CUDA toolkit 嵌入后的容器软件栈
-
nvidia-container-runtime(shim):
该组件曾经是 runc 的一个完整分支,其中注入了特定于 NVIDIA 的代码。自2019年以来,它已经成为安装在主机系统上的本机 runC 的一个轻量级包装器。nvidia-container-runtime 接受 runc spec作为输入,将 NVIDIA 容器运行时钩子(nvidia-container-runtime-hook)作为预启动钩子注入其中,然后调用本机 runc,并传递修改后的具有该钩子设置的 runc spec。对于 NVIDIA 容器运行时 v1.12.0 版本及更高版本,这个运行时(runtime)还对 OCI 运行时规范进行了额外修改,以注入特定的设备和挂载点,这些设备和挂载点不受 NVIDIA 容器 CLI 控制。
-
nvidia-container-runtime-hook:
该组件包含一个可执行文件,实现了 runC 预启动钩子所需的接口。此脚本由 runC 在容器创建后启动前调用,并且被授予对容器关联的 config.json(例如,该 config.json )的访问权限。然后,它会提取 config.json 中包含的信息,并使用这些信息调用 nvidia-container-cli CLI,并附带适当的一组标志。其中最重要的标志之一是应该注入到该容器中的特定 GPU 设备。
-
nvidia-container library 和 CLI:
这些组件提供了一个库和一个简单的 CLI 实用程序,用于自动配置 GNU/Linux 容器使用 NVIDIA GPU。该实现依赖于内核原语,并设计为与容器运行时无关。
K8S 侧:Device Plugin
在 Kubernetes(K8S)中,Device Plugin 是一种扩展机制,用于将节点上的设备资源(例如 GPU、FPGA、TPU 等)纳入到 Kubernetes 资源管理的范围内。Device Plugin 允许集群管理员将节点上的设备资源暴露给 Kubernetes API 服务器,使得集群中的 Pod 可以通过资源调度机制使用这些设备。
实现步骤
得益于可扩展性的架构设计,Volcano 支持用户自定义 plugin 和 action 以支持更多调度算法。更多关于 Volcano 的介绍,请查阅参考资料。
灵雀云一站式解决方案
在前文中,我们深入探讨了不同的GPU虚拟化技术以及调度框架和策略。然而,要在标准的Kubernetes容器平台上实施这些方案,并借助监控机制对GPU资源进行实时管理和运维,无疑是一项复杂又耗时的任务。那么,是否存在一种全面且高效的解决方案,答案是肯定的。灵雀云全新研发的AI 开发运维一体化平台中深度集成vGPU方案,以高效集成和灵活调度为核心优势,实现GPU资源的全面优化和快速响应。
AML
在生成式 AI 如火如荼、大行其道的今天,灵雀云始终致力于拥抱生成式 AI 的发展趋势,近期将发布面向大模型的 AI 开发运维一体化平台:AML。AML 为企业用户提供了丰富的开箱即用大模型选择、一站式的模型推理、优化与应用开发能力,助力企业轻松开启 AI 赋能之旅,释放无限业务潜力。
AML针对大模型的全生命周期做了深入优化,从模型选择、模型发布、AI 应用开发、模型线上运维监控到模型微调和优化,每个环节都集成了业界最前沿的研究成果和最佳实践,使企业节省大量的时间和成本,提高生产效率。
AML支持一键发布多种类型的模型,包括但不限于文本生成、图像生成和音视频生成等,使用户能够轻松训练和部署各种 AI 应用。全流程管理功能使 AML 成为一站式 AI 工作台,简化了工作流程管理,提高了用户的操作便捷性。
与传统的 SaaS 服务相比,AML 使用私有化的数据存储提供了更高级别的数据安全性,让企业可以放心地存储和管理其敏感数据,满足内部数据安全的合规性要求。
AML 允许企业根据自身的安全规范自定义模型发布过程,确保模型发布符合企业安全规范。
AML 基于标准开源产品,具有高度的社区兼容性。AML 不仅全面兼容 HuggingFace 的模型库和接口定义,还支持常见主流深度学习框架,如 PyTorch 和 TensorFlow。
AML 支持各种常见模型格式,使企业能够基于已有框架灵活选择模型进行开发。
通过支持 pGPU/vGPU 解决方案、RDMA 网卡和高性能存储等系列方案,AML 实现了卓越的计算性能,能够更好的支持大规模分布式训练和推理。
-
初始化。在这个阶段,设备插件将执行特定于供应商的初始化和设置,以确保设备处于就绪状态。
-
插件使用主机路径 /var/lib/kubelet/device-plugins/ 下的 UNIX 套接字启动一个 gRPC 服务,该服务实现以下接口:
- service DevicePlugin {
- // GetDevicePluginOptions 返回与设备管理器沟通的选项。
- rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
- // ListAndWatch 返回 Device 列表构成的数据流。
- // 当 Device 状态发生变化或者 Device 消失时,ListAndWatch
- // 会返回新的列表。
- rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
- // Allocate 在容器创建期间调用,这样设备插件可以运行一些特定于设备的操作,
- // 并告诉 kubelet 如何令 Device 可在容器中访问的所需执行的具体步骤
- rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
- // GetPreferredAllocation 从一组可用的设备中返回一些优选的设备用来分配,
- // 所返回的优选分配结果不一定会是设备管理器的最终分配方案。
- // 此接口的设计仅是为了让设备管理器能够在可能的情况下做出更有意义的决定。
- rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
- // PreStartContainer 在设备插件注册阶段根据需要被调用,调用发生在容器启动之前。
- // 在将设备提供给容器使用之前,设备插件可以运行一些诸如重置设备之类的特定于
- // 具体设备的操作,
- rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
- }
- 说明:
- 插件并非必须为 GetPreferredAllocation() 或 PreStartContainer() 提供有用的实现逻辑, 调用 GetDevicePluginOptions() 时所返回的 DevicePluginOptions 消息中应该设置一些标志,表明这些调用(如果有)是否可用。kubelet 在直接调用这些函数之前,总会调用 GetDevicePluginOptions() 来查看哪些可选的函数可用。

-
插件通过位于主机路径/var/lib/kubelet/device-plugins/kubelet.sock 下的 UNIX 套接字向 kubelet 注册自身。(说明:工作流程的顺序很重要。插件必须在向 kubelet 注册自己之前开始提供 gRPC 服务,才能保证注册成功。)
-
成功注册自身后,设备插件将以提供服务的模式运行,在此期间,它将持续监控设备运行状况, 并在设备状态发生任何变化时向 kubelet 报告。它还负责响应 Allocate gRPC 请求。在 Allocate 期间,设备插件可能还会做一些特定于设备的准备;例如 GPU 清理或 QRNG 初始化。如果操作成功,则设备插件将返回 AllocateResponse,其中包含用于访问被分配的设备容器运行时的配置。kubelet 将此信息传递到容器运行时。
AllocateResponse 包含零个或多个 ContainerAllocateResponse 对象。设备插件在这些对象中给出为了访问设备而必须对容器定义所进行的修改。这些修改包括:注解、设备节点、环境变量、挂载点、完全限定的 CDI 设备名称。
小结
至此,GPU 在容器中使用和虚拟化所需要的所有技术框架就都齐备了。Nvidia 公司利用这两个组件,结合不同的硬件特性,分别实现了 Time-slicing、MPS 和 MIG 等不同的 GPU 虚拟化技术。
Nvidia 虚拟化方案
在容器中,GPU 虚拟化就是将一个物理 GPU 切分为多个虚拟CPU以供不同容器应用使用。
Time-slicing
时间片调度机制,可以使用简单的超额订阅策略来调用GPU的时间片调度器,从而实现多个 CUDA 应用程序通过 GPU 时间的共享达到并发执行的效果。时间片调度得益于自 Pascal 架构开始支持的 GPU 计算抢占机制。计算抢占允许在指令级粒度上中断 GPU 上运行的任务。当时间片被激活时,GPU 通过以固定时间间隔(可配置)在进程上下文之间切换,以公平共享的方式在不同进程之间共享其计算资源。此方式是在 Kubernetes 集群中共享 GPU 的最简单解决方案。
虽然是最简单的解决方案,这个方案也是有明显缺陷的。CUDA 应用程序频繁的上下文切换会带来额外的时间开销,进一步转化为性能抖动和更高的计算延迟。同时,时间片调度不会在共享 GPU 的进程之间提供任何级别的内存隔离,也不会提供任何内存分配限制,这可能导致频繁的内存不足 (OOM) 错误;同时,由于没有内存隔离,任何一个进程的内存不足,都会导致所有在同一个设备上执行的 CUDA 程序退出。
MPS
多进程服务(Multi-Process Service)是CUDA应用程序编程接口(API)的替代二进制兼容实现。从Kepler的GP10架构开始,NVIDIA就引入了MPS(基于软件的多进程服务,当时称为Hyper-Q技术),它允许多个流(stream)或者 CPU 的进程同时向 GPU 发射 CUDA Kernel 函数调用,并结合为一个单一应用程序上下文在 GPU 上运行,从而实现更好的GPU利用率。在单个进程的任务处理,对GPU利用率不高的情况下是非常有用的。
在 nvidia 不同架构的 GPU 卡中,MPS的实现是在持续改进的。例如,Volta 架构的 MPS 相比 Pascal MPS 有以下改进点,如下图所示:
-
Volta MPS client提交GPU任务不需要经过MPS服务器
-
每个client有属于自己的显存地址
-
Volta提供了为QoS提供有限的执行资源
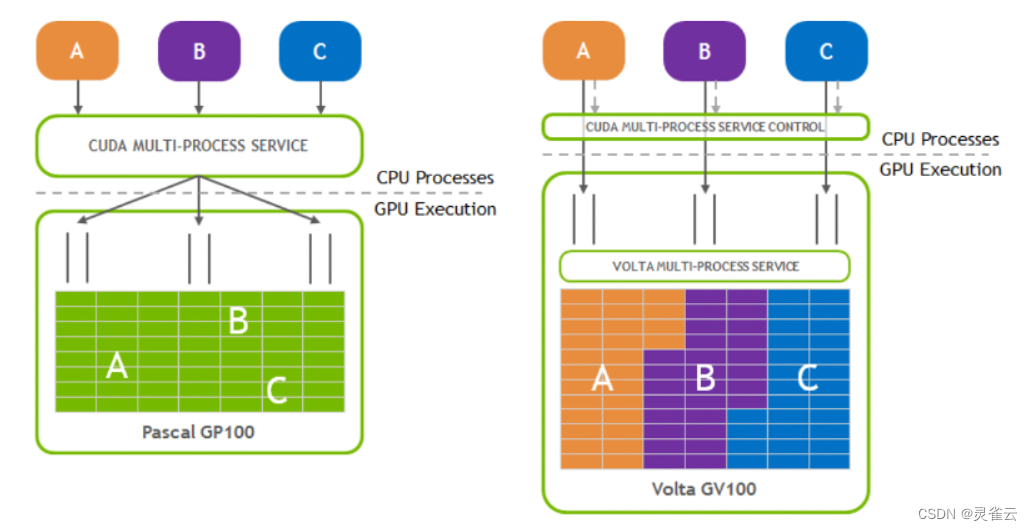
图示:Volta 架构的 MPS 相比 Pascal MPS 的改进点
优势
-
增加GPU的利用率
-
单个进程大部分情况下不能充分利用GPU上可用的资源(算力、内存和内存带宽)。MPS允许不同进程的内核和内存请求操作在GPU上堆叠执行,从而实现更高的利用率和更短的运行时间。
-
减少GPU上下文存储空间
-
如果没有 MPS,使用 GPU 的每个 CUDA 进程会在 GPU 上单独分配存储和调度资源。而 MPS server 只分配一份GPU存储和调度资源,并由所有客户端共享。Volta 架构的MPS在MPS client 之间的隔离有所加强,因此资源占用相比 pre-Volta MPS 会多一点。
-
减少GPU上下文切换
-
如果没有 MPS,当进程共享GPU时,这些进程的调度资源必须在 GPU 上交换。MPS服务器在所有客户端之间共享一组调度资源,消除了 GPU 在这些客户端之间调度时交换的开销。
同时,MPS实际上也是有一些使用限制的,比方它现在仅支持 Linux 操作系统,还要求 GPU 的运算能力必须大于3.5。
MIG
多实例GPU (Multi-Instance GPU) 功能 (从NVIDIA Ampere架构开始) 允许把 GPU 安全地划分为多达七个独立的 GPU 实例,为多用户提供独立的 GPU 资源以最大化提高GPU的利用率。
使用MIG技术,每个实例在系统中都具有独立且隔离的各项 GPU 资源(显存、缓存与计算核心)。由于每个实例具有可控的计算资源,因此单个用户的工作负载便能够在可预测的性能下运行且不受其他用户工作负载情况的影响。MIG对系统可用的 GPU 计算资源 (包括流多处理器、SMs、 GPU引擎等) 进行分区,可以为不同的客户端 (如虚拟机、容器或进程) 提供具有故障隔离的质量保证。MIG 使多个 GPU 实例能够在单个物理 Ampere 架构上并行。
使用 MIG,用户能够在新的虚拟 GPU 实例上查看和调度作业,就如同使用物理 GPU 一样。MIG 与 Linux 操作系统配合使用,支持使用 Docker 引擎的容器,并支持使用 Red Hat Virtualization 和 VMware vSphere 等管理程序的 Kubernetes 和虚拟机。
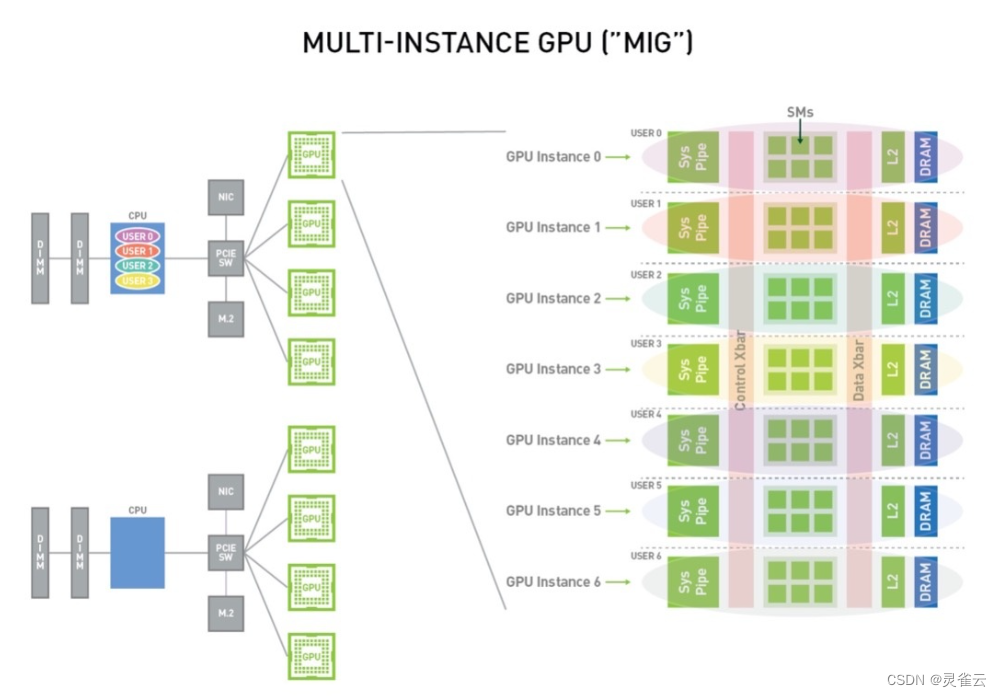 MIG分配遵循一定的规则,如下图所示(以A100 40GB显存GPU为例):
MIG分配遵循一定的规则,如下图所示(以A100 40GB显存GPU为例):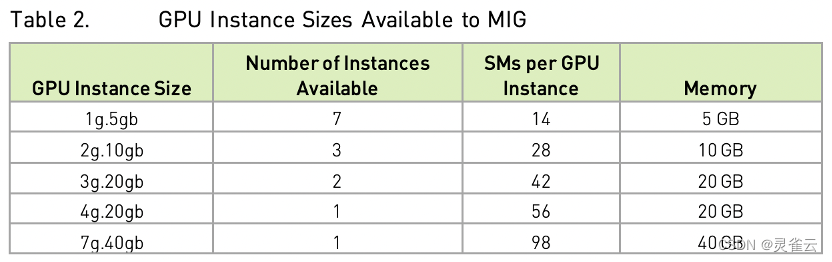
A100 的 SM 单元 (streaming multiprocessor) 数量 (类似CPU的核心数) 为108,每个 GPU 运算实例的最小粒度是 14 个 SM 单元,也就是说在分配 GPU 的 SM 单元数量时必须是 14 的整数倍。比如:申请规模为 28 SM 单元数、10GB 显存的运算实例,设在单张 A100 上这样的实例个数最多为 X 个,那么必须满足28 * X <= 108 (SM单元总数限制) 且 10 *X <= 40 (GPU显存限制),所以 X 最大为3。
MIG 共享 GPU 需要手动预先配置,这种方式缺乏灵活性、支持的实例少且只有较新的芯片架构上支持。
优势
-
扩展 GPU 的应用范围
-
借助 MIG 技术,您可以在单个 GPU 上获得多达原来 7 倍的 GPU 资源。MIG 为研发人员提供了更多的资源和更大的灵活性。
-
优化 GPU 利用率
-
MIG 允许您灵活选择许多不同的实例大小,从而为每项工作负载提供适当规模的 GPU 实例,最终优化利用率并使数据中心投资充分发挥成效。
-
同时运行工作负载
-
凭借 MIG,能以确定性延迟和吞吐量,在单个 GPU 上同时运行推理、训练和高性能计算 (HPC) 工作负载。与时间分片不同,各工作负载并行运行,能够实现高性能。
-
方案对比
特性 MPS MIG Time-Slicing 类型(Partition Type) Logical Physical Temporal (Single process) 最大分区数量(Max Partitions) 48 7 Unlimited SM 性能隔离(SM Performance Isolation) Yes (by percentage, not partitioning) Yes Yes 内存保护(Memory Protection) Yes Yes No 内存带宽质量保证(Memory Bandwidth QoS) No Yes No 错误隔离(Error Isolation) Yes Yes No 跨区互操作(Cross-Partition Interop) IPC Limited IPC Limited IPC 更新配置(Reconfigure) 仅在 mps server 进程启动/重启时 当显卡空闲时 N/A GPU 调度和增强
通过在前面章节介绍的组件和机制,GPU 的各种计算资源已经实现了资源上报、量化、分配、隔离和使用监控等;所以基于原生的 K8S Scheduler,也可以实现基础的 GPU 容器应用的调度(默认调度策略)。如果用户不满足于默认的调度策略,还可以通过扩展、新增调度策略来实现诸如优先调度到同一张显卡实现更高的利用率和更低的碎片化、同一个业务的不同 pod 分布到不同显卡实现更好的鲁棒性等。如果用户不满足于默认的调度策略,又没有时间去执行扩展调度器,那么也可以直接使用后面介绍的 Volcano 调度器。
K8S scheduler framework
调度框架是面向 Kubernetes 调度器的一种插件架构, 它由一组直接编译到调度程序中的“插件” API 组成。这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。一个典型的 Pod 调度流程如下图所示。更多关于 K8S scheduler framework 的介绍,请查阅参考材料。
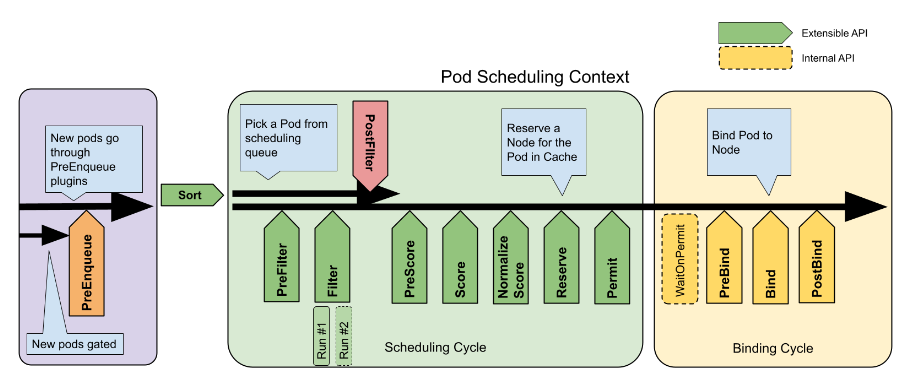
图示:Pod 调度流程
Volcano 调度器
Volcano是 CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。它提供了Kubernetes目前缺 少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种高性能工作负载所需的。作为一个通用批处理平台,Volcano 与几乎所有的主流计算框 架无缝对接,如 Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle 等。它还提供了包括基于各种主流架构的 CPU、GPU 在内的异构设备混合调度能力。Volcano 的设计 理念建立在15年来多种系统和平台大规模运行各种高性能工作负载的使用经验之上,并结合来自开源社区的最佳思想和实践。
Volcano支持各种调度策略,包括:
-
Gang-scheduling
Gang调度策略是 volcano-scheduler 的核心调度算法之一,它满足了调度过程中的 “All or nothing” 的调度需求,避免 Pod 的任意调度导致集群资源的浪费。
-
Fair-share scheduling
-
Queue scheduling
-
Preemption scheduling
-
Topology-based scheduling
-
Reclaims
-
Backfill
-
Resource Reservation
-
大模型时代的生产力工具
-
出色的易用性
-
企业级安全性
-
广泛的兼容扩展性
-
卓越的性能表现
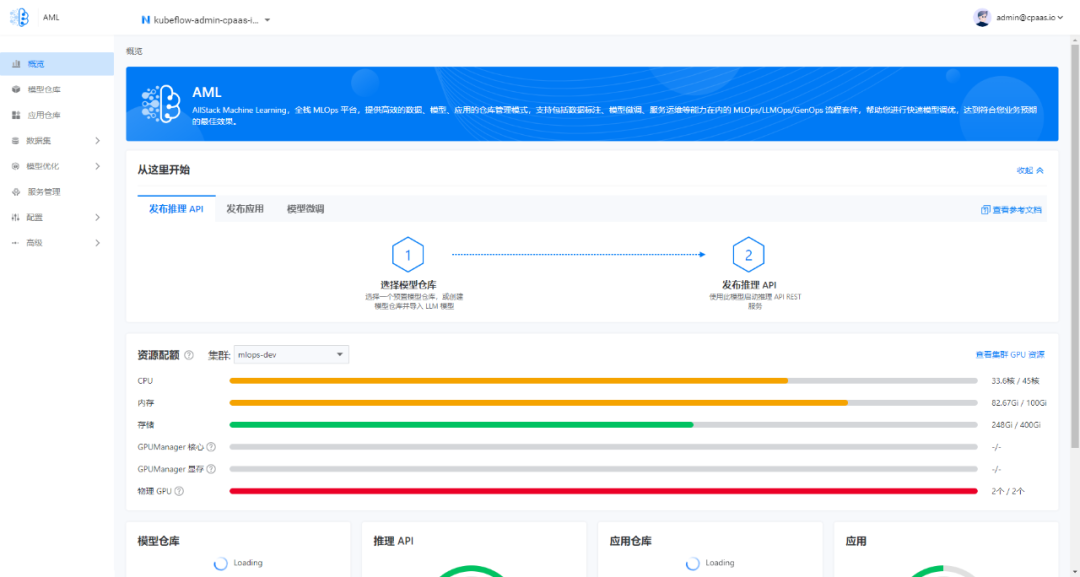
图示:AML 的概览页
AML 的 vGPU 方案
AML 中支持的 GPU 能力是成熟且完备的,不仅全面支持 Nvidia 官方的 GPU 虚拟化方案,还强化了产品层面的易用性,提升了稳定性。
AML 的 vGPU 方案主要特性包括:
-
支持包括 Nvidia、昇腾、天数在内的所有市面上主流品牌
-
支持 GPU 物理卡(pGPU)和虚拟卡(vGPU)
-
支持市面上主流 CUDA 版本(v11.4 到 v12.2)
-
开箱即用的GPU 能力
-
全面支持计算隔离、显存隔离和故障隔离,用户可以放心使用虚拟化 GPU,无惧扰动
-
提供针对 GPU 资源的多种增强调度能力,完美支持微调训练等高性能运算场景
用户典型 GPU 使用场景,如图所示:
-
创建/初始化集群:用户在部署集群时,可以标定 GPU 节点并部署对应的驱动包,也可以在集群使用过程中更新、新增 GPU 节点。GPU 资源使用情况会以图表形式直观的展示给用户。
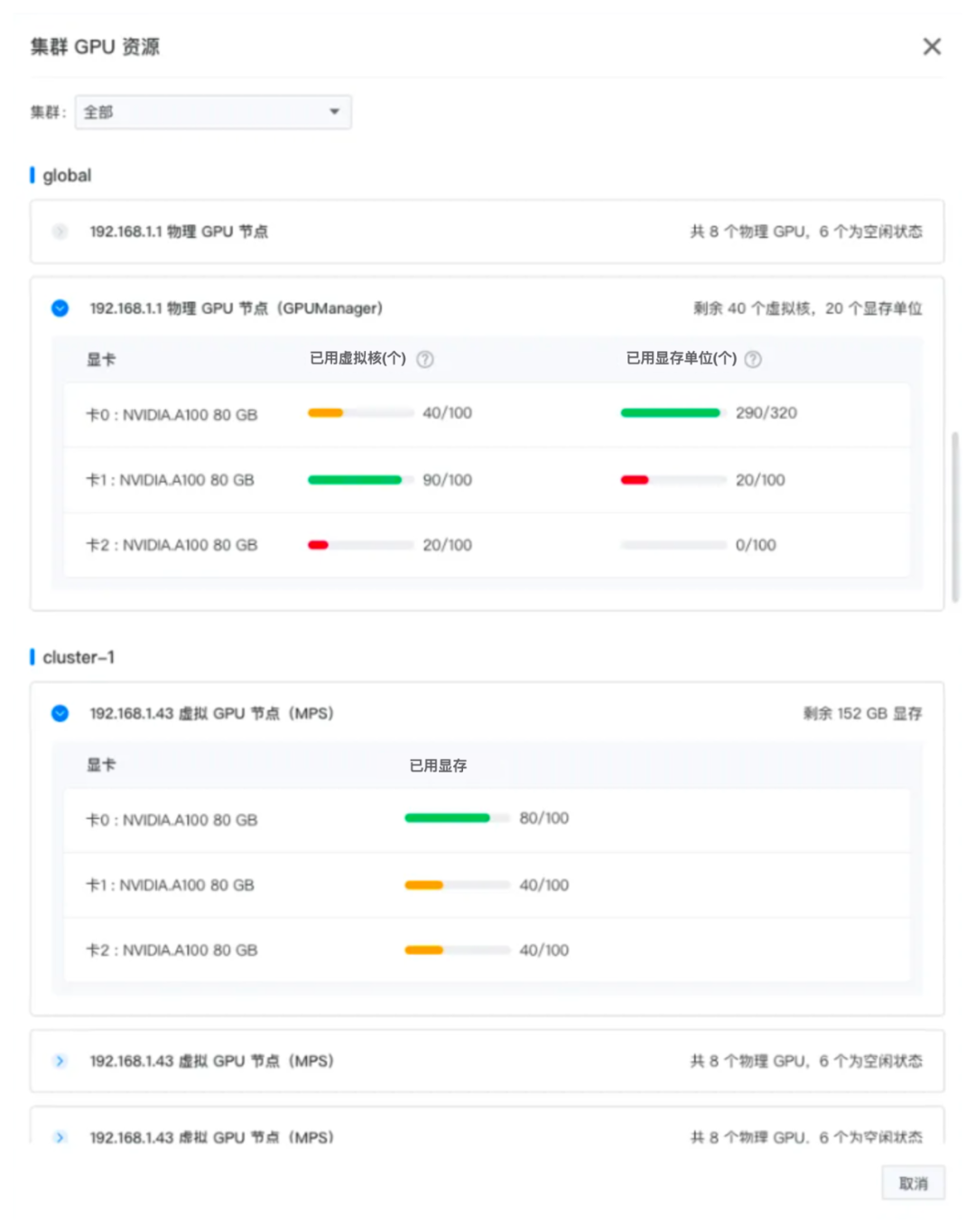
-
绑定和使用:用户只需在容器应用中声明特定的 GPU 资源,调度器即可自动完成绑定和调度工作。声明示例如下:
- apiVersion: v1
- kind: Pod
- metadata:
- name: mps-gpu-pod
- spec:
- restartPolicy: Never
- hostIPC: true
- securityContext:
- runAsUser: 1000
- containers:
- - name: cuda-container
- image: <test-image>
- resources:
- limits:
- nvidia.com/mps-core: 50
- nvidia.com/mps-memory: 8
-
监控面板:监控面板将提供详细的GPU监控图表,使用户对GPU的使用情况一目了然,实现直观可视化的管理。
-
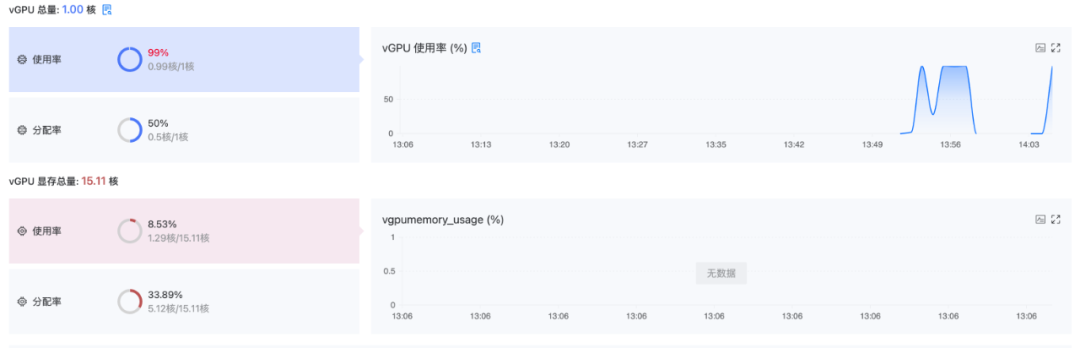
图示:vGPU 资源使用监控面板
更多关于 AML 产品的信息,敬请期待后续内容

