
- 1GitHub上只下载部分文件的操作教程_github如何下载部分代码
- 2目标检测实战(五): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))_yolov5.7介绍
- 3Android动态权限详解
- 4【DevOps】Kibana:数据可视化与探索的强大工具
- 5MySQL索引下推(Index Condition Pushdown, ICP)优化深入解析_mysql 索引下推
- 6spss安装后 python_python从入门到入土教程(7)——用python实现SPSS的各种功能
- 7软件测试学习职业生涯必读的书籍【附电子版】_探索式软件测试电子书
- 8python爬虫及数据可视化分析_python爬虫与可视化项目简介怎么写
- 9【AI学习指南】七、PaddlePaddle自然语言处理-PaddleNLP的基础使用/中文分词/词性标注/实体识别/依存句法分析_paddlenlp 分词
- 10strongswan交叉编译与安装
AIGC专题:Sora技术深度解析_aigc sora讲解
赞
踩
今天分享的是AIGC系列深度研究报告:《AIGC专题:Sora技术深度解析》。
(报告出品方:华福证券)
报告共计:21页
精选报告来源:人工智能学派
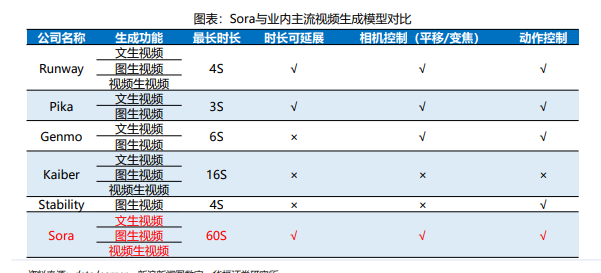
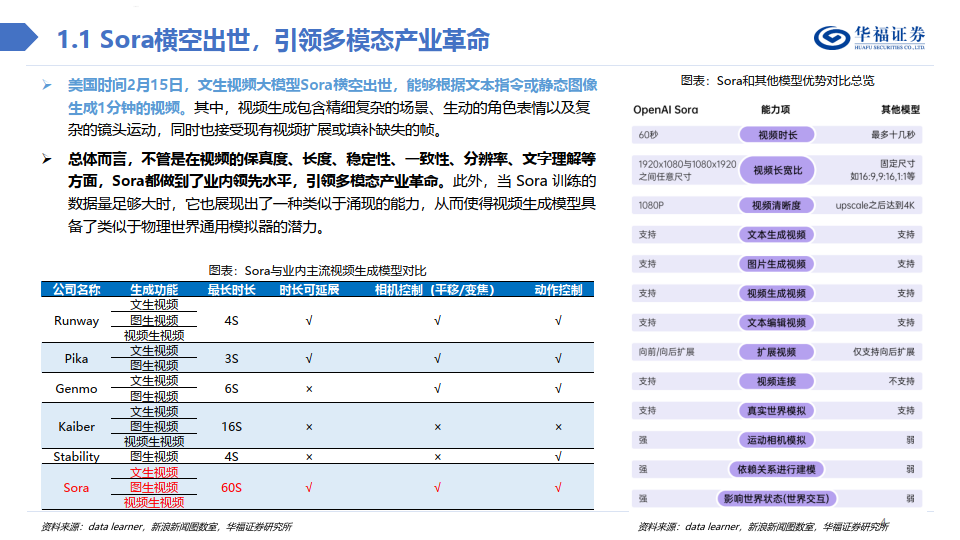
Sora横空出世,引领多模态产业革命
美国时间2月15日,文生视频大模型Sora横空出世,能够根据文本指令或静态图像 生成1分钟的视频。其中,视频生成包含精细复杂的场景、生动的角色表情以及复 杂的镜头运动,同时也接受现有视频扩展或填补缺失的帧。
总体而言,不管是在视频的保真度、长度、稳定性、一致性、分辨率、文字理解等 方面,Sora都做到了业内领先水平,引领多模态产业革命。此外,当 Sora 训练的 数据量足够大时,它也展现出了一种类似于涌现的能力,从而使得视频生成模型具 备了类似于物理世界通用模拟器的潜力。
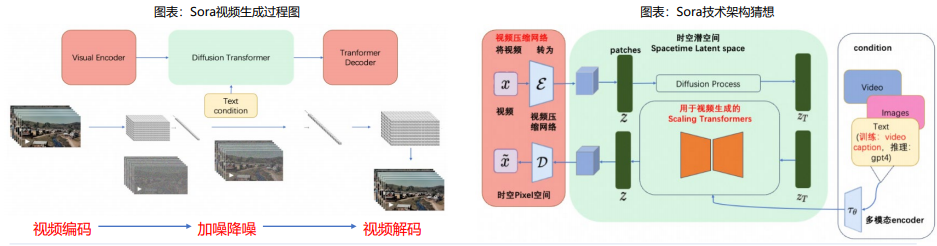
Sora视频生成过程:视频编码+加噪降噪+视频解码
从技术报告中,Sora视频生成过程大致由以下三个步骤组成:
视频编码:Visual Encoder将原始视频压缩为低维潜在空间,再将视频分解为时空patches后拉平为系列视频token以供 transformer处理。
加噪降噪:在transfomer架构下的扩散模型中,时空patches融合文本条件化,先后经过加噪和去噪,以达到可解码状态。
视频解码:将去噪后的低维潜在表示映射回像素空间。
总体而言,我们认为Sora技术报告虽未能详尽阐述视频生成技术细节,但从参考技术文献中,可初步窥探出时空patches、视频压 缩网络、 Transformer技术架构、独特文本标注视频数据集等技术与资源优势,这些或为Sora占据业内领先地位的原因。
视频压缩网络实现降维,或为长视频生成基础
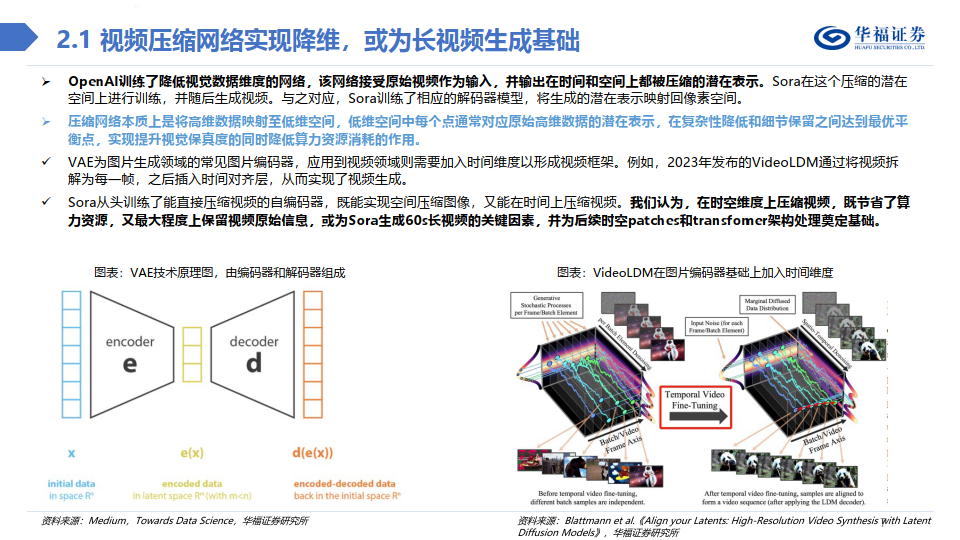
OpenAI训练了降低视觉数据维度的网络,该网络接受原始视频作为输入,并输出在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在 空间上进行训练,并随后生成视频。与之对应,Sora训练了相应的解码器模型,将生成的潜在表示映射回像素空间。
压缩网络本质上是将高维数据映射至低维空间,低维空间中每个点通常对应原始高维数据的潜在表示,在复杂性降低和细节保留之间达到最优平 衡点,实现提升视觉保真度的同时降低算力资源消耗的作用。
VAE为图片生成领域的常见图片编码器,应用到视频领域则需要加入时间维度以形成视频框架。例如,2023年发布的VideoLDM通过将视频拆 解为每一帧,之后插入时间对齐层,从而实现了视频生成。
Sora从头训练了能直接压缩视频的自编码器,既能实现空间压缩图像,又能在时间上压缩视频。我们认为,在时空维度上压缩视频,既节省了算 力资源,又最大程度上保留视频原始信息,或为Sora生成60s长视频的关键因素,并为后续时空patches和transfomer架构处理奠定基础。

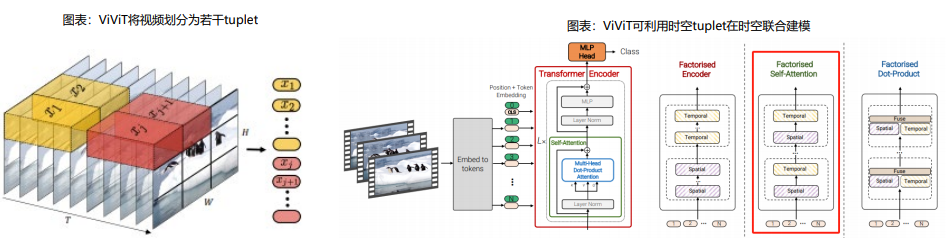
时空patches统一视频分割,奠定处理和理解复杂视觉内容的基石
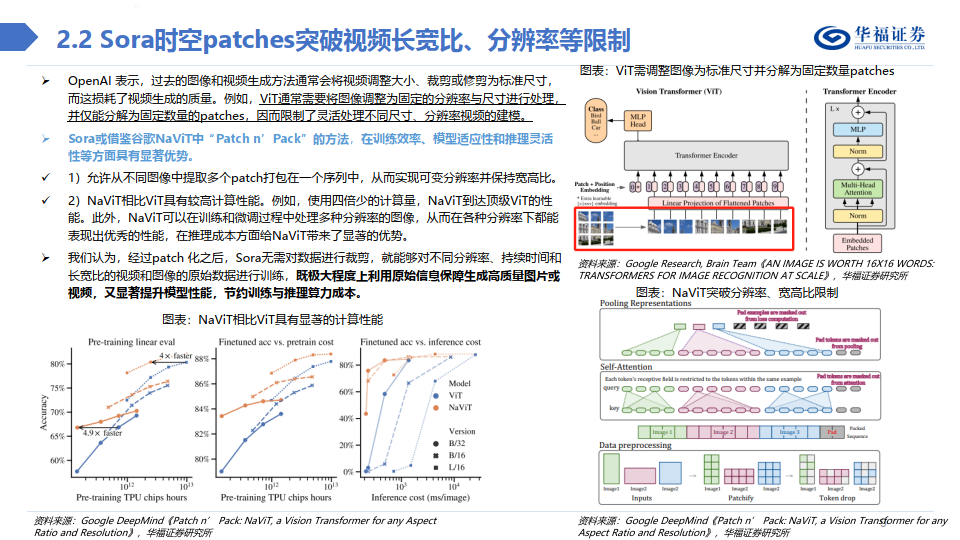
Sora借鉴LLM中将文本信息转化为token的思路,针对视频训练视觉patch,实现视觉数据模型的统一表达,实现对多样化视频和图像内容的有 效处理和生成,之后通过视频压缩网络分解为时空patches,允许模型在时间和空间范围内进行信息交换和操作。
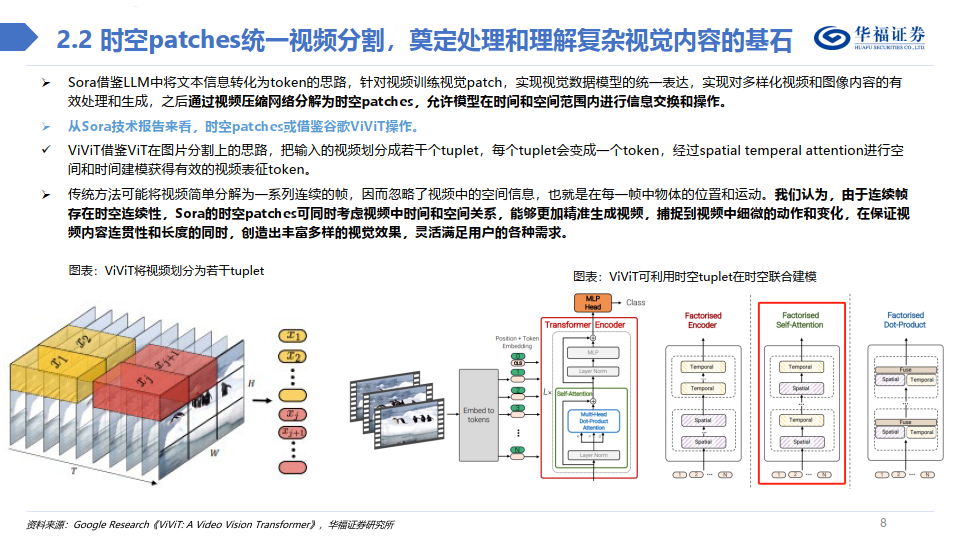
从Sora技术报告来看,时空patches或借鉴谷歌ViViT操作。
ViViT借鉴ViT在图片分割上的思路,把输入的视频划分成若干个tuplet,每个tuplet会变成一个token,经过spatial temperal attention进行空 间和时间建模获得有效的视频表征token。
传统方法可能将视频简单分解为一系列连续的帧,因而忽略了视频中的空间信息,也就是在每一帧中物体的位置和运动。我们认为,由于连续帧 存在时空连续性,Sora的时空patches可同时考虑视频中时间和空间关系,能够更加精准生成视频,捕捉到视频中细微的动作和变化,在保证视 频内容连贯性和长度的同时,创造出丰富多样的视觉效果,灵活满足用户的各种需求。








报告共计:21页
精选报告来源:人工智能学派

