
- 1如何备考PMP考试?
- 2[Go语言]我的性能我做主(1)_b.reportallocs()
- 3安装运行streamlit 过程中出现的2个问题_no module named 'streamlit
- 4【JavaWeb】网上蛋糕商城-项目搭建_网上蛋糕商城web项目
- 528岁程序猿,劝告那些想去学车载测试的人
- 6华为OD机试-字符串变换最小字符串(Java&Python&Js)100%通过率_给定一个字符串 最多只能交换一次 返回变换后能得到的最小字符串
- 7强力推荐!史上最强logo设计Midjourney提示词合集_midjourney logo设计关键词
- 8pythonexcel汇总_Python汇总excel到总表格
- 9如何使用Python读写多个sheet文件_python sheets 选择读取多行sheet
- 10喜报丨上海容大中标某股份制大行信用卡中心PDA移动办卡终端项目
ICLR 2023 | DM-NeRF:从2D图像中实现3D场景的几何分解与编辑(已开源)
赞
踩
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

编辑丨Cver
点击进入—>3D视觉工坊学习交流群

DM-NeRF: 3D Scene Geometry Decomposition and Manipulation from 2D Images
论文链接:https://arxiv.org/abs/2208.07227
PyTorch代码(已开源):
https://github.com/vLAR-group/DM-NeRF

1. Introduction
高效准确地分解三维场景的几何结构并对其进行任意编辑是三维场景理解与交互的关键问题,也是虚拟现实、智能机器等应用的基础。经典的几何方法如SfM/SLAM只能重建稀疏、离散的点云,无法包含几何细节,且不能对场景进行理解和操作。近年来,大多数基于深度神经网络的方法仅关注场景的光照和材质组成,无法实现对场景几何结构的分解与编辑,尤其是面临复杂三维场景时。
2. Motivation
近期,以NeRF [1] 为代表的神经网络隐式场方法在表征三维模型的几何细节、新视角合成和语义分割等任务上取得了很好的效果。本文旨在同时还原连续的3D场景几何结构、分解3D空间中所有独立的物体,并支持灵活的场景编辑。此外,编辑后的3D场景还可以从新视角进行渲染。目前所有已知的方法无法完成上述任务,因为需要满足以下两个条件:
三维场景分解。其依赖空间中连续的3D标签提供监督信号,但是这不仅需要大量的人工标注,而且由于物体间遮挡关系的存在,完整的标注是不现实的;
三维场景编辑。其需要对指定的隐式物体场进行编辑,然而场景编辑会不可避免地导致视觉遮挡问题,因此编辑算法应具备解决该遮挡问题的能力。
针对上述问题,本文设计了一种可以在单个框架中同时重建、分解、编辑和渲染复杂3D场景的方法。该方法可以在不依赖任何3D标签的前提下,实现对三维场景连续且隐式的分解,并在此基础上对其几何结构进行任意编辑。具体来讲,在神经辐射场的渲染框架内,首先,通过本文设计的Object Field模块,仅利用2D监督信号完成对3D空间的准确分解;其次,基于我们提出的Object Manipulator算法,对场景几何结构进行任意的编辑,如平移、旋转、放缩和形变等;最后,在新视角下对编辑后的场景完成渲染。本文包括以下三点贡献:
提出了一个全新的场景分解框架,仅通过2D物体标签为每个空间中的三维物体直接学习其唯一的Object Code。相比现有的基于单张图像的分割方法,该框架表现出了更加显著的鲁棒性和准确性;
提出了一个新颖的Inverse Query编辑算法,该算法可以高效地对指定物体的形状进行任意编辑,同时在新视角下对编辑后的场景进行渲染并生成逼真的二维图像;
通过大量实验验证了本文方法在3D场景分解和编辑方面的卓越性能,并为3D场景编辑任务的定量评估贡献了第一个合成数据集。
3. Method
3.1 Overview
本文方法将三维空间点的位置信息 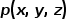 和观察方向
和观察方向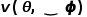 作为输入。首先,利用NeRF Component 和 Object Field Component对每个三维空间点的体积密度(Volume Density)、RGB及物体编码(Object Code)进行预测;其次,使用Volume Rendering方法,将同一条光线上所有三维空间点的预测值积分到二维平面下,得到每个像素对应的RGB和Object Code;最后,Object Manipulation Component根据Object Field Component的3D标签预测结果完成场景编辑。
作为输入。首先,利用NeRF Component 和 Object Field Component对每个三维空间点的体积密度(Volume Density)、RGB及物体编码(Object Code)进行预测;其次,使用Volume Rendering方法,将同一条光线上所有三维空间点的预测值积分到二维平面下,得到每个像素对应的RGB和Object Code;最后,Object Manipulation Component根据Object Field Component的3D标签预测结果完成场景编辑。
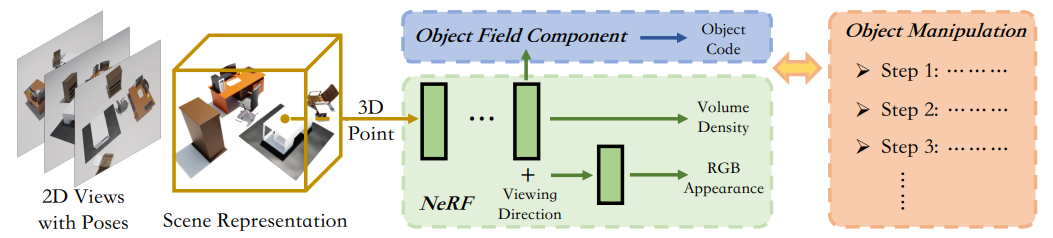
图1: DM-NeRF流程图
如图1所示,DM-NeRF框架包括以下三个核心部分:
1) NeRF Component:完成三维场景重建及渲染工作。学习每个三维空间点的体积密度和RGB;
2) Object Field Component:完成三维场景分解工作。表征每个三维空间点的物体编码;
3) Object Manipulator:完成三维场景编辑工作。任意编辑场景的几何结构,并解决视觉遮挡问题。
3.2 NeRF Component
该模块使用经典NeRF框架, 如图1所示。首先,输入L张图像及其对应的相机位姿 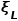 和相机内参
和相机内参 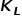 ,利用重投影方法可以将整个场景以点云的形式表示;其次,以每个三维空间点的位置
,利用重投影方法可以将整个场景以点云的形式表示;其次,以每个三维空间点的位置 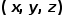 和观察方向
和观察方向  作为框架的输入,通过多层MLP对每个三维空间点的 RGB和体积密度进行预测;最后,使用Volume Rendering方法将同一条光线上所有三维空间点的预测值积分到二维平面下, 得其对应像素点的RGB。因为本文的核心工作是对三维空间中每一个物体进行准确分解及任意编辑,所以这里对NeRF只做简单介绍,具体细节请参考 [1] 。
作为框架的输入,通过多层MLP对每个三维空间点的 RGB和体积密度进行预测;最后,使用Volume Rendering方法将同一条光线上所有三维空间点的预测值积分到二维平面下, 得其对应像素点的RGB。因为本文的核心工作是对三维空间中每一个物体进行准确分解及任意编辑,所以这里对NeRF只做简单介绍,具体细节请参考 [1] 。
3.3 Object Field Component
该模块是DM-NeRF框架的关键。其可实现在不依赖任何3D标签的前提下,生成每一个三维空间点对应的Object Code。该模块包含Object Field Representation、Object Code Projection及Object Code Supervision三部分关键内容。
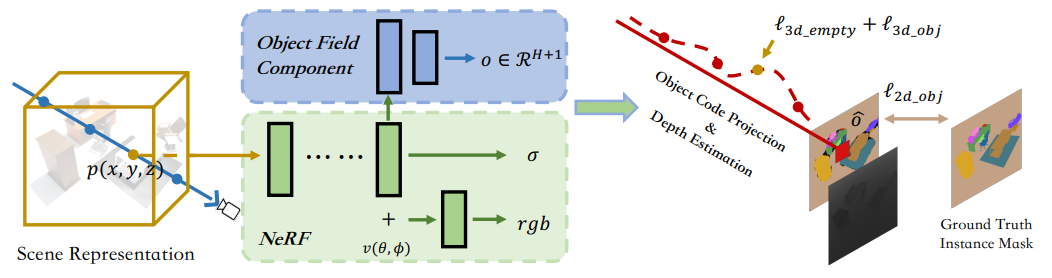
图2: DM-NeRF 结构图
1) Object Field Representation
这一部分是对Object Field的定义。因为Object Code来表征Object Field,所以其是DM-NeRF对三维场景进行分解的关键,需要对其进行巧妙设计。如图2所示,给定一个三维空间点 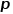 ,Object Field Component针对这个点生成相应的Object Code,这里所有的Object Code用One-Hot 向量
,Object Field Component针对这个点生成相应的Object Code,这里所有的Object Code用One-Hot 向量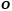 表示,每一个
表示,每一个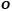 都有H+1维,其中H被描述为场景中存在的物体数量,
都有H+1维,其中H被描述为场景中存在的物体数量,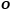 的最后一维被表述为Non-Occupied空间。Object Field 公式定义如下:
的最后一维被表述为Non-Occupied空间。Object Field 公式定义如下:
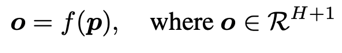
2) Object Code Projection
这一部分是对2D物体监督信号的投影过程。虽然直接获取空间中连续的3D标签是不现实的,但是获取2D物体标签却相对容易,本文旨在仅通过2D物体标签为每个空间中的三维物体直接学习其唯一的Object Code。具体来讲,Object Field对三维空间中每一个点的Object Code进行预测,然后使用Volume Rendering方法将同一条光线上所有查询点的Object Code进行权重累加,得到其对应像素点的 Object Code。积分公式如下:
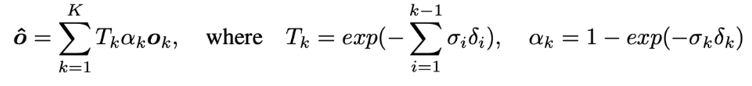
3) Object Code Supervision
这一部分是对2D物体标签的监督。通过上述方法可得到预测的2D物体标签。在实际应用中,由于存在视觉遮挡问题,不同视角下物体的数量和Object Code顺序是变化的,导致同一个三维空间点对应多个Object Code真值。为了解决这个问题,本文参考3D-BoNet [2] 的Optimal Association and Supervision策略,设计了以Soft Intersection-over-Union(sIoU)和Cross-Entropy Score(CES)为影响因素的Cost Matrix。具体的计算公式如下:
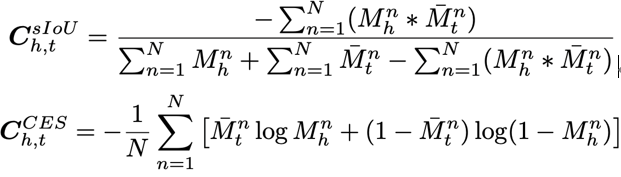
3.4 Object Manipulator
该模块是三维场景编辑的关键。基于Object Field对场景的准确分解,用户可以定位到场景内所有物体。为了高效地对指定物体的形状进行任意编辑,同时在新视角下对编辑后的场景进行渲染并生成逼真的二维图像,本文在给定目标物体Object Code和相应编辑操作的前提下,设计了新颖的Inverse Query算法。该方法如图3所示。
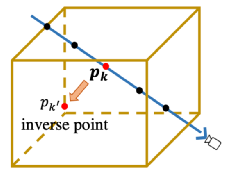
图3: Inverse Query示例
具体来讲,首先,空间中任意一束光线上的查询点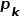 可以通过一个变化矩阵,如平移矩阵
可以通过一个变化矩阵,如平移矩阵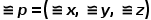 ,旋转矩阵
,旋转矩阵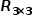 或形变矩阵等,在该空间下找到另一束光线上的查询点
或形变矩阵等,在该空间下找到另一束光线上的查询点 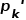 ;其次,把这两个查询点对应的五维位置信息送入DM-NeRF中,可以生成对相应的Object Codes。Manipulator接着会判断预测点的Object Code是否等于目标点的Object Code,来决定是否定交换他们的预测值;最后,再次沿着光线进行渲染,得到编辑后场景的二维图像。
;其次,把这两个查询点对应的五维位置信息送入DM-NeRF中,可以生成对相应的Object Codes。Manipulator接着会判断预测点的Object Code是否等于目标点的Object Code,来决定是否定交换他们的预测值;最后,再次沿着光线进行渲染,得到编辑后场景的二维图像。
4. Experiments
为了验证算法可行性,本文针对重建、分解、编辑和渲染,分别在Replica [3] 、ScanNet [4] 和DM-SR上进行了定量和定性评估。最终验证,DM-NeRF在复杂3D场景下具有近乎完美的场景重建、渲染及场景分解能力,并可以对场景进行任意编辑。
4.1 Training with 100% Accurate 2D Labels
首先,本文以NeRF作为重建和渲染的Baseline,以当前SOTA的SwinT [5] 作为场景分解的Baseline,在100%正确的2D物体真值标签下进行训练。从表1可以看出,本文方法都要优于上述Baseline。定性结果对比如图4、5。

表1: 重建及场景分解定量结果对比

图4: Replica重建及分解定性结果对比

图5: ScanNet重建及分解定性结果对比
4.2 Robustness to Noisy 2D Labels
其次,本文在有噪声的2D物体标签上进行训练评估。因为本文是基于多视角的重建方法,相比2D分割方法更具一致性,所以DM-NeRF的场景分解结果应更为鲁棒。为了验证这一想法,如图6所示,本文先是对训练的每张图像随机分配了整张图像不同比率(10%/50%/70%/80%/90%)的噪声, 然后分别让DM-NeRF和SwinT进行训练。从表2可以看出,本文方法在80% 噪声标签下训练,最终在测试数据上依然有平均74.08% 的准确率。
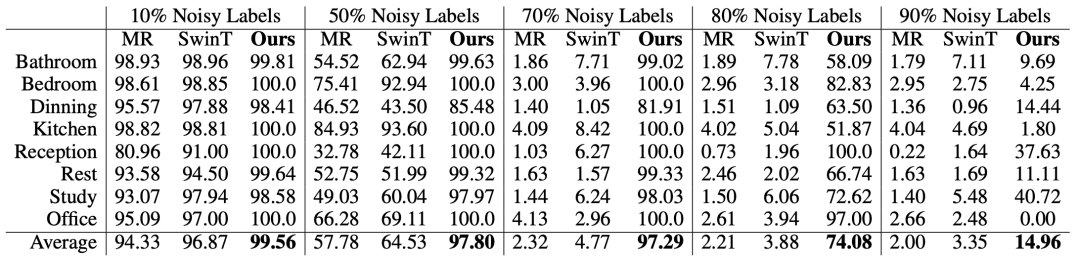
表2: 有噪声的场景分解定量结果(AP0.75)
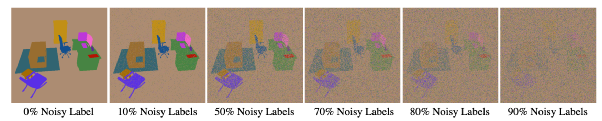
图6: 不同噪声比率的真值标签示例
4.3 3D Object Manipulation
最后,由于目前缺乏一个可以对三维场景编辑进行定量评估的数据集,而为了展现DM-NeRF在场景编辑方面的卓越性能,本文使用Blender制作了一个包含8个多样且复杂的室内场景的合成数据集(DM-SR),并在该数据集提供的对指定物体的平移(Translation)、旋转(Rotation)、放缩(Scale)及平移+旋转+放缩(Joint)等真值数据上进行了定量评估。同时,本文还在Point-NeRF [6] 上也完成了相同的评估。可以从表3看出,DM-NeRF的场景编辑结果要远优于Point-NeRF。Manipulator对场景编辑任务的定性结果对比,如图7、8所示。
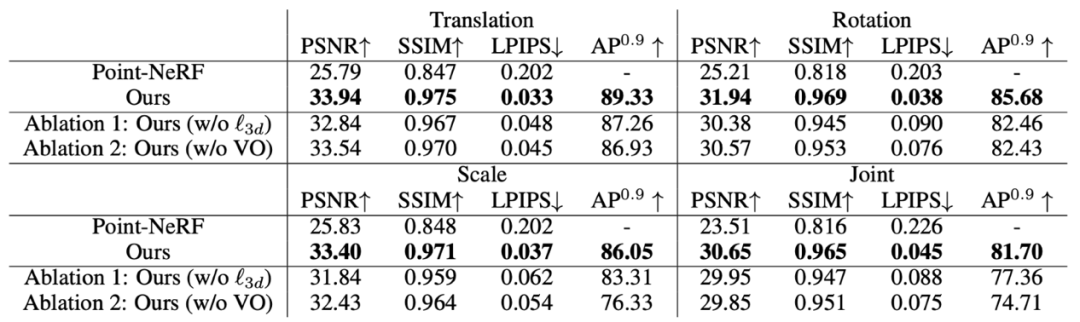
表3: DM-SR数据集上场景重建和编辑的定量结果对比
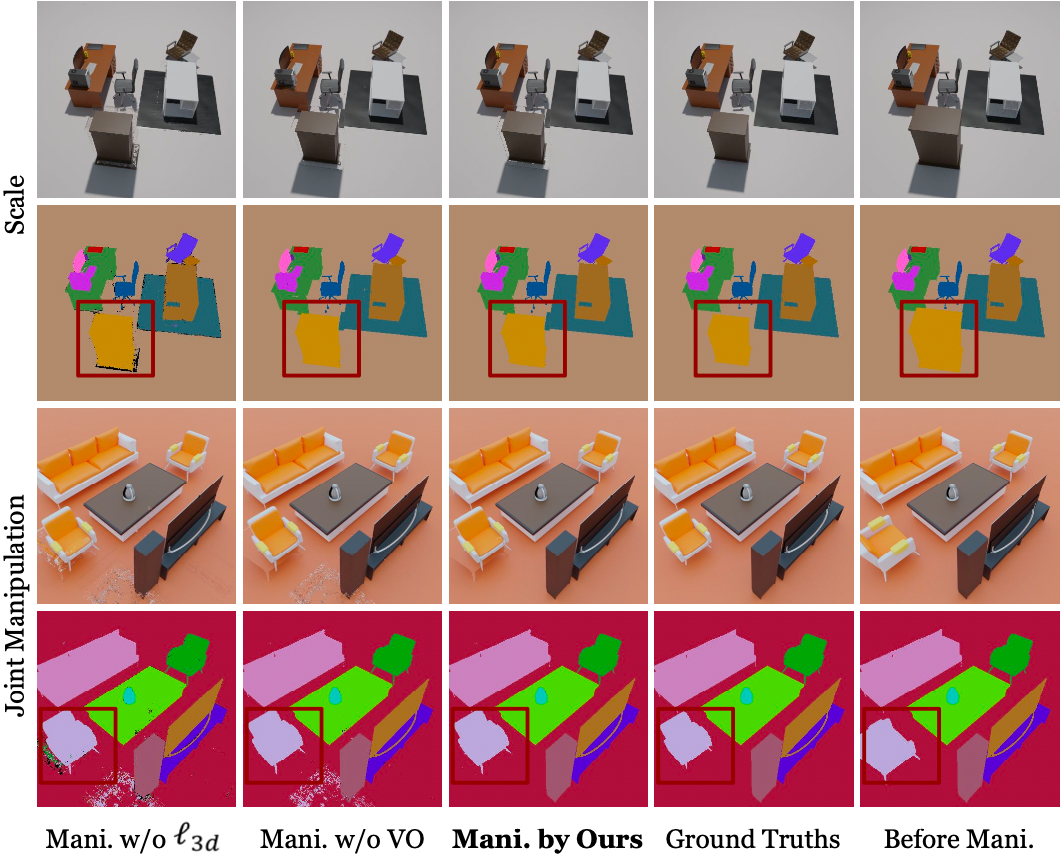
图7: Rigid Manipulation定性结果对比
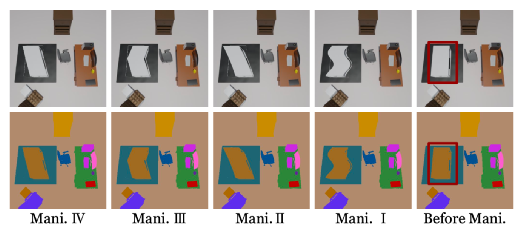
图8: Deformable Manipulation定性结果对比
5. Conclusion
最后总结一下,本文提出的DM-NeRF灵活地将复杂场景的重建、分解、编辑和渲染集成在同一框架中。首先,通过设计隐式Object Field,将三维场景进行分解;其次,提出Visual-Occlusion-Aware编辑器,对场景几何结构进行任意编辑;最后,在新视角下对编辑后的场景完成渲染。然而,本文仍存在一些不足之处,未来可从以下两方面开展研究:1)场景光照解耦,允许同时对场景几何结构和环境光照进行编辑,让场景的渲染更加真实。2)Artifacts修复,可利用物体表面的几何连续性或设计更强大的神经网络编辑方法对其进行修复。
欢迎大家关注我们更多的新工作:
https://www.polyu.edu.hk/aae/people/academic-staff/dr-wang-bing/
https://yang7879.github.io/
Reference
[1] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, 967 Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: 968 Representing Scenes as Neural Radiance Fields for View 969 Synthesis. European Conference on Computer Vision. pages 970 405–421, 2020.
[2] Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds. NeurIPS, 2019.
[3] Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, and Hauke M Strasdat. The Replica Dataset : A Digital Replica of Indoor Spaces. arXiv:1906.05797, 2019.
[4] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. CVPR, 2017.
[5] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10012-10022.
[6] Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, and Ulrich Neu- mann. Point-NeRF: Point-based Neural Radiance Fields. arXiv, 2022.
本文仅做学术分享,如有侵权,请联系删文。
点击进入—>3D视觉工坊学习交流群
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
2.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
3.国内首个面向工业级实战的点云处理课程
4.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
5.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
6.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
7.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
16.透彻理解视觉ORB-SLAM3:理论基础+代码解析+算法改进
重磅!粉丝学习交流群已成立
交流群主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、ORB-SLAM系列源码交流、深度估计、TOF、求职交流等方向。
扫描以下二维码,添加小助理微信(dddvisiona),一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿,微信号:dddvisiona
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看,3天内无条件退款

高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

