
- 1红黑树【数据结构与算法Java】_数据结构红黑树java
- 2IOS证书申请流程
- 3皮尔逊、肯德尔和斯皮尔曼相关性分析的热力图python代码_python 皮尔逊相关图
- 4MySQL数据库查询重复数据办法_数据库查询三个字段数据相等的数据
- 5【单元测试】Junit 4(二)--eclipse配置Junit+Junit基础注解_eclipse junit4
- 6异常值检测(1)——箱线图四分位距和3σ
- 7C#中HttpWebRequest的用法_c# webrequest
- 8【算法系列篇】递归、搜索和回溯(二)
- 9打比赛?《CTF那些事儿》你不能错过。_base64相关的书籍
- 10偷偷曝光下国内这些软件外包公司!(2023 最新版)
Deberta:解耦+增强掩码的bert_deberta: decoding-enhanced bert with disentangled
赞
踩
论文地址
https://arxiv.org/pdf/2006.03654
论文架构
提出了一个名为DeBERTa(Decoding-enhanced BERT with disentangled attention)的模型架构,通过两种新颖技术改进了现有的BERT和RoBERTa模型。DeBERTa模型的原理和改进点如下:
1. Disentangled Attention Mechanism(解耦注意力机制):
- BERT预训练时注意力机制的计算,是将位置嵌入和词嵌入对应位置相加,得到单词的表示向量 X 作为attention的输入,具体计算如下:
Self-Attention 的输入用矩阵为 X,使用线性变阵矩阵WQ,WK,WV计算得到Q、K、V,X, Q(查询),K(键值),V(值) 的每一行都表示一个单词。
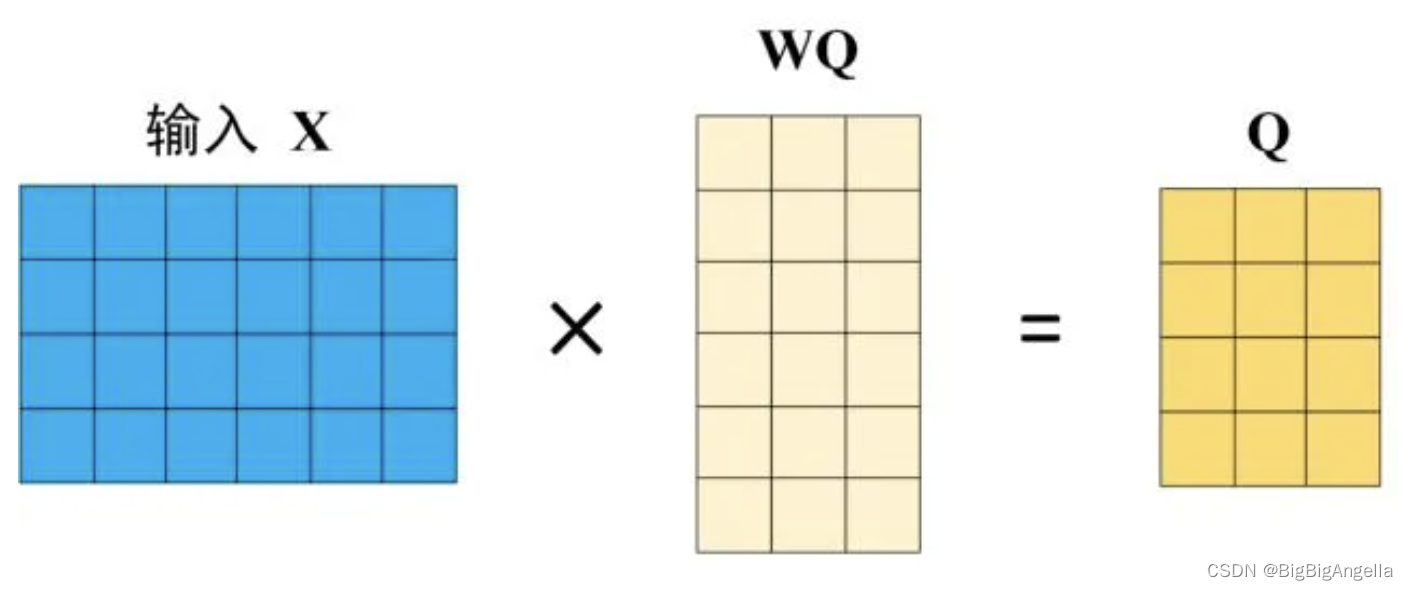
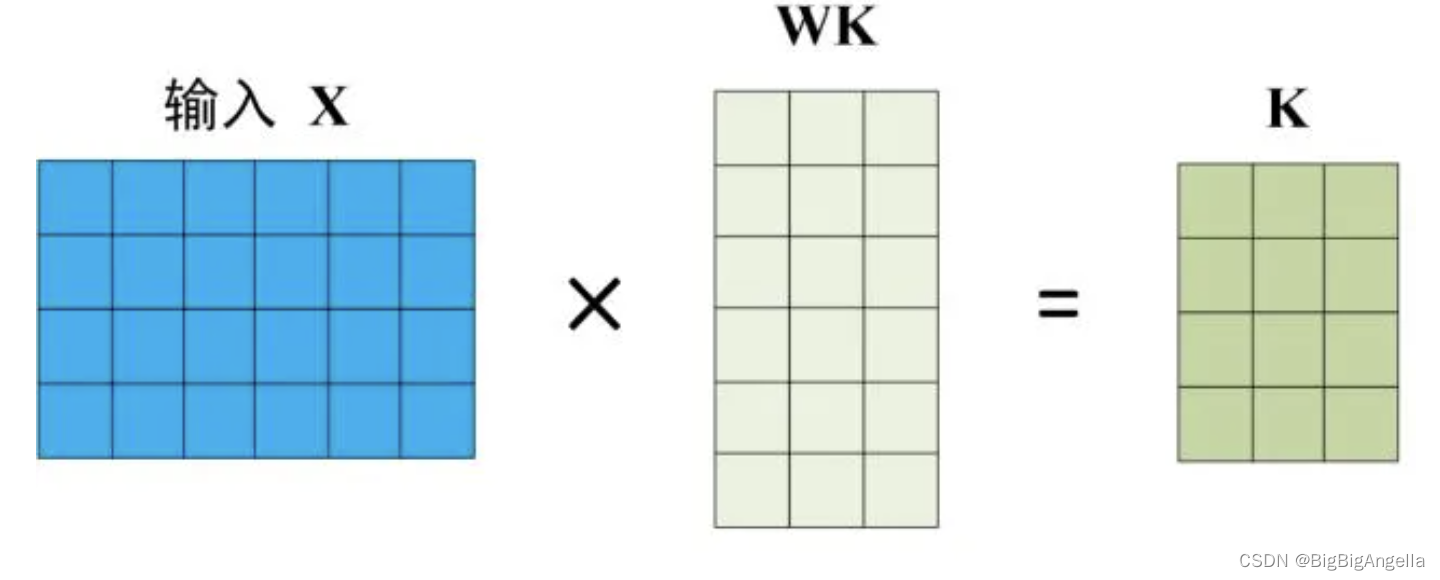
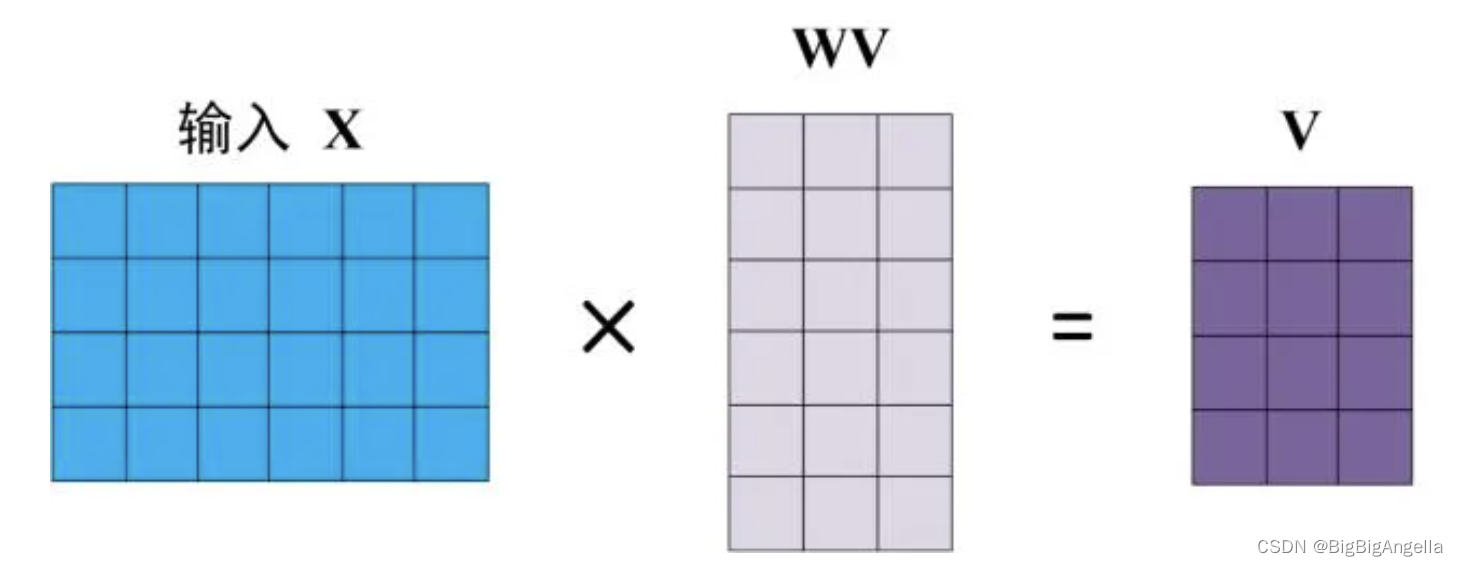
BERT中Self-Attention的输出为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
注:dk是Q、K矩阵的列数,即向量维度 - DeBERTa使用了解耦注意力机制,其中每个单词用两个向量表示:一个编码内容(content),另一个编码位置(position)。注意力权重是基于单词内容和相对位置分别使用不同的矩阵来计算的,这种设计考虑到了单词对之间的依赖性不仅取决于它们的内容,还取决于它们的相对位置,具体计算如下:
对于序列中的位置 i ,使用向量{Hi} 表示内容token,使用向量{Pi|j}表示位置 i 和 j 之间的相对位置token,token i 和 j 之间的交叉注意分数的计算可以分解为以下四个部分:
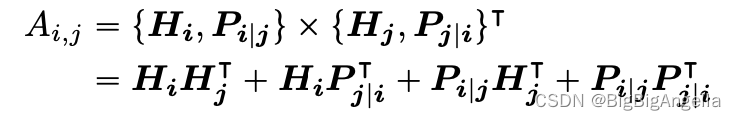
一个词对的注意力权重可以计算为四个注意力分数的总和:内容到内容、内容到位置、位置到内容和位置到位置。现有的相对位置编码方法在计算注意力权重时使用单独的嵌入矩阵来计算相对位置偏差,相当于只使用公式中的内容到内容和内容到位置项来计算注意力权重。
文中认为位置到内容也很重要,因为单词对的注意力权重不仅取决于它们的内容,还取决于它们的相对位置,这只能使用内容到位置和位置到内容来完全建模。由于使用了相对位置嵌入,位置到位置项不会提供太多额外的信息,所以在实现中删除。
记 k 为最大相对距离, δ ( i , j ) ∈ [ 0 , 2 k ) \delta(i,j) \in [0,2k) δ(i,j)∈[0,2k)为token i到 token j的相对距离,定义为:
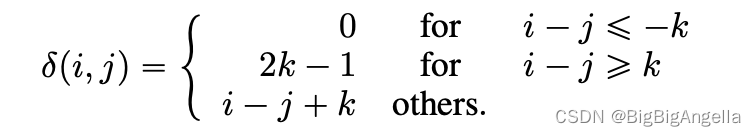
将具有相对位置偏差的解纠缠的自注意表示为如下公式,其中,其中Qc,Kc和Vc分别是使用投影矩阵 Wq,c, Wk,c, Wv,c ∈ R d × d \in R^{d\times d} ∈Rd×d 生成的投影内容向量, P ∈ R 2 k × d P \in R^{2k \times d} P∈R2k×d表示跨所有层共享的相对位置嵌入向量(即在正向传播期间保持固定),Qr和Kr分别是使用投影矩阵Wq,r,Wk,r ∈ R d × d \in R^{d\times d} ∈Rd×d 生成的投影相对位置向量。


2. Enhanced Mask Decoder(增强掩码解码器):
DeBERTa和BERT一样使用MLM进行预训练,使用掩码token周围的单词来预测掩码词,解耦注意机制已经考虑了语境词的内容和相对位置,但没有考虑这些词的绝对位置,绝对位置在很多情况下对预测至关重要。
BERT模型在输入层中包含绝对位置,在DeBERTa中,为了融合绝对位置信息,将它们合并在所有Transformer层之后,但在用于掩码token预测的softmax层之前,如下图所示:
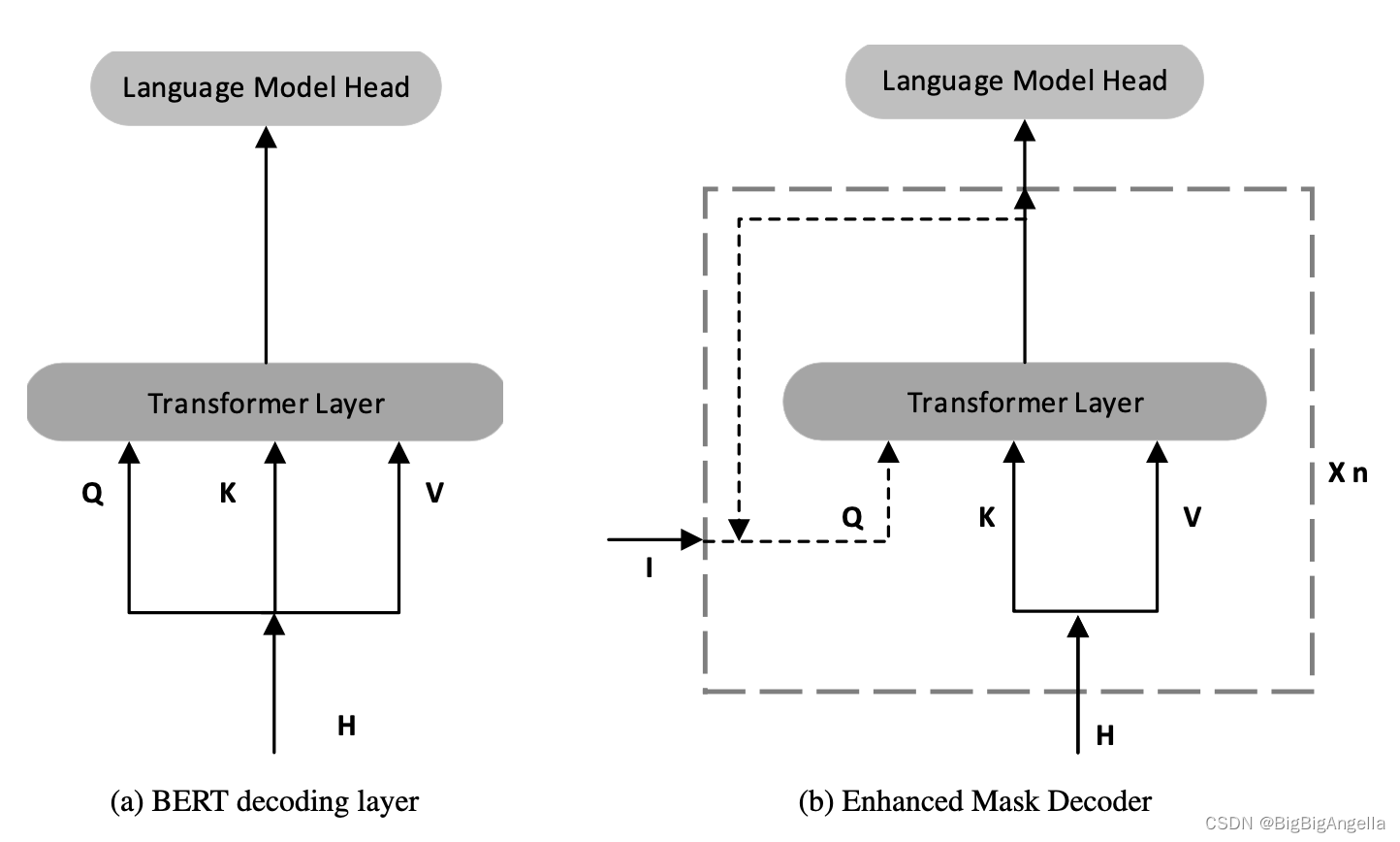
通过这种方式,DeBERTa捕获所有Transformer层中的相对位置,并且在解码被屏蔽的单词时仅使用绝对位置作为补充信息,并称DeBERTa的解码组件为增强型掩码解码器(EMD)。
3.Virtual Adversarial Training(虚拟对抗训练):
虚拟对抗训练(Scale-invariant-Fine-Tuning,参考[SiFT1,SiFT2])是一种提高模型泛化能力的正则化方法。它通过提高模型对对抗性样本的鲁棒性来实现这一点,对抗性样本是通过对输入进行小扰动而产生的。该模型是正则化的,因此当给定特定任务的示例时,该模型产生的输出分布与该示例的对抗性扰动产生的输出分布相同。
算法通过对归一化词嵌入应用扰动来提高训练稳定性。在文章实验中,当对DeBERTa进行下游NLP任务微调时,SiFT首先将单词嵌入向量归一化为随机向量,然后将扰动应用于归一化的嵌入向量。结果发现归一化极大地提高了微调模型的性能。对于较大的DeBERTa型号,改进更为突出。请注意,实验中只将SiFT应用于DeBERTa1.5B的SuperGLUE任务。
模型适用任务
DeBERTa模型适合的任务包括但不限于:
自然语言理解(NLU)任务,如文本分类、问答、自然语言推理等。
自然语言生成(NLG)任务,如文本生成、摘要等。
特别是那些需要理解文本中单词之间复杂关系的任务,DeBERTa的解耦注意力机制可以更好地捕捉这些关系。
论文改进点
与BERT相比,DeBERTa的改进点主要包括:
性能提升:在多种自然语言处理(NLP)任务上,DeBERTa显示出比RoBERTa更好的性能,即使在训练数据量减半的情况下也是如此。
效率:DeBERTa在预训练和下游任务的性能上都显示出显著的效率提升。
更好的泛化能力:通过虚拟对抗训练方法,DeBERTa在微调时展现出更好的泛化能力。
在论文中,DeBERTa在多个NLP基准测试中取得了优异的成绩,包括在SuperGLUE基准测试中首次超越人类表现,这表明DeBERTa在多项语言理解任务上具有强大的性能。

