
- 1ShardingSphere-Proxy分表分库、读写分离基本使用(v5.4.1版本)_shardingsphereproxy5.4.1数据加密
- 2doccano 标注工具 全网最全安装部署采坑_doccano部署
- 3人工智能与能源约束的矛盾能否化解
- 4深度解析:AI Prompt 提示词工程的兴起、争议与未来发展_提升词工程
- 5【高项】第1章 信息化与信息系统(1)_面向对象面向服务结构化是高项那章
- 6Spring boot集成通义千问大模型实现智能问答_springboot 整合阿里千问实现ai
- 7基于堆叠长短期记忆网络 Stacked LSTM 预测A股股票价格走势
- 8S-Clustr(影子集群)V3 高并发,去中心化,多节点控制
- 9LeetCode -面试题02.02. 返回到数第k个节点 -简单_leetcode返回第k个节点
- 10@Transactional+@Autowired出现的lateinit property xx has not been initialized错误_lateinit propertyxx has not been initialized
智谱AI 发布最新开源模型GLM-4-9B,通用能力超Llama-3-8B,多模态版本比肩GPT-4V_智谱ai大模型 github
赞
踩

自 2023 年 3 月 14 日开源 ChatGLM-6B 以来,GLM 系列模型受到广泛关注和认可。特别是 ChatGLM3-6B 开源以后,开发者对智谱AI 第四代模型的开源充满期待。
为了使小模型(10B 以下)具备更加强大的能力,GLM 技术团队进行了大量探索工作。经过近半年的探索,我们推出了第四代 GLM 系列开源模型:GLM-4-9B。
在预训练方面,我们引入了大语言模型进入数据筛选流程,最终获得了 10T 高质量多语言数据,数据量是 ChatGLM3-6B 模型的 3 倍以上。同时,我们采用了 FP8 技术进行高效的预训练,相较于第三代模型,训练效率提高了 3.5 倍。在有限显存的情况下,我们探索了性能的极限,并发现 6B 模型性能有限。因此,在考虑到大多数用户的显存大小后,我们将模型规模提升至 9B,并将预训练计算量增加了 5 倍。
综合以上技术升级和其他经验,GLM-4-9B 模型具备了更强大的推理性能、更长的上下文处理能力、多语言、多模态和 All Tools 等突出能力。GLM-4-9B 系列模型包括:基础版本 GLM-4-9B(8K)、对话版本 GLM-4-9B-Chat(128K)、超长上下文版本 GLM-4-9B-Chat-1M(1M)和多模态版本 GLM-4V-9B-Chat(8K)。
以下是 GLM-4-9B 的能力掠影:

具体性能如下:
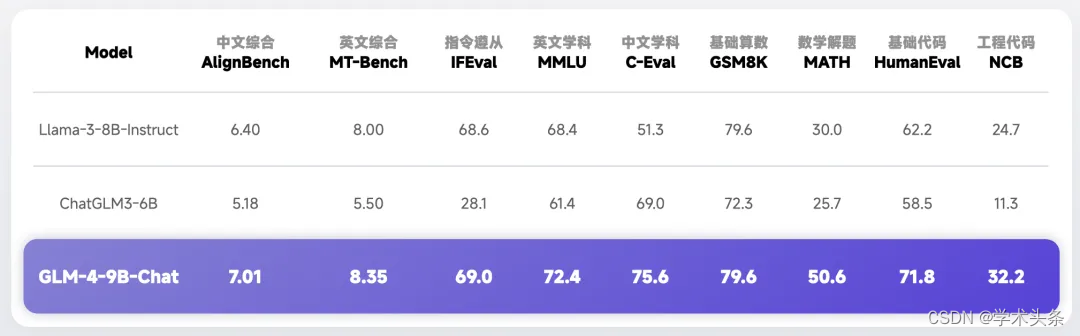
基础能力
基于强大的预训练基座,GLM-4-9B 的模型中英文综合性能相比 ChatGLM3-6B 提升了 40%,尤其是在中文对齐能力 AlignBench、指令遵从 IFeval、工程代码 Natural Code Bench 方面都取得了非常显著的提升。对比训练量更多的 Llama 3 8B 模型也没有逊色,英文方面有小幅领先,中文学科方面更是有着高达 50% 的提升。
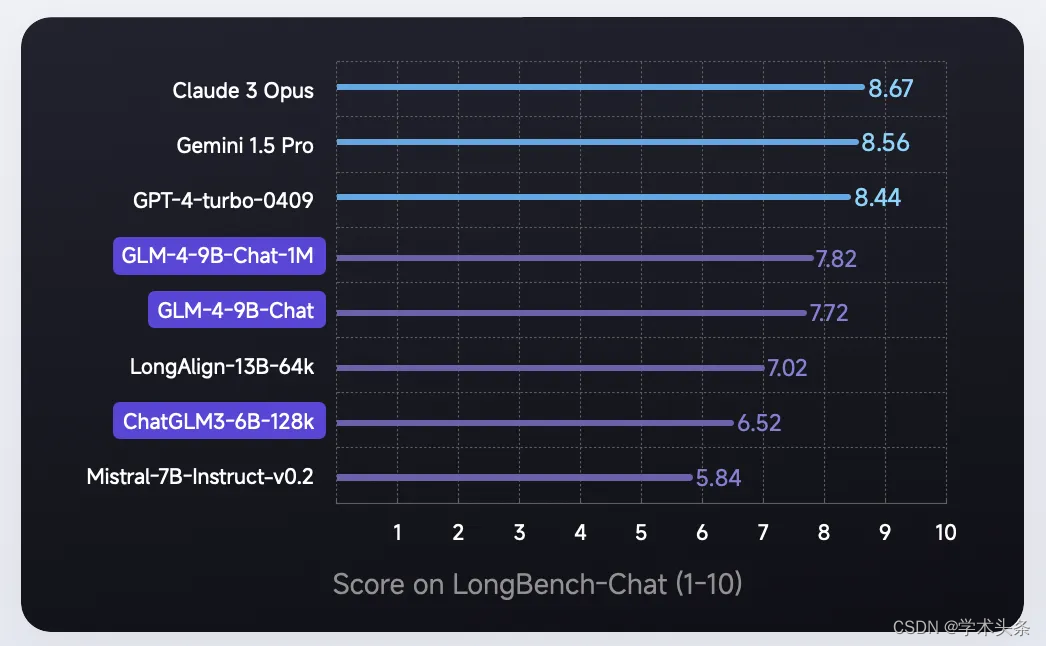
长文本能力
GLM-4-9B 模型的上下文从 128K 扩展到了 1M tokens,这意味着模型能同时处理 200 万字的输入,大概相当于 2 本红楼梦或者 125 篇论文的长度。
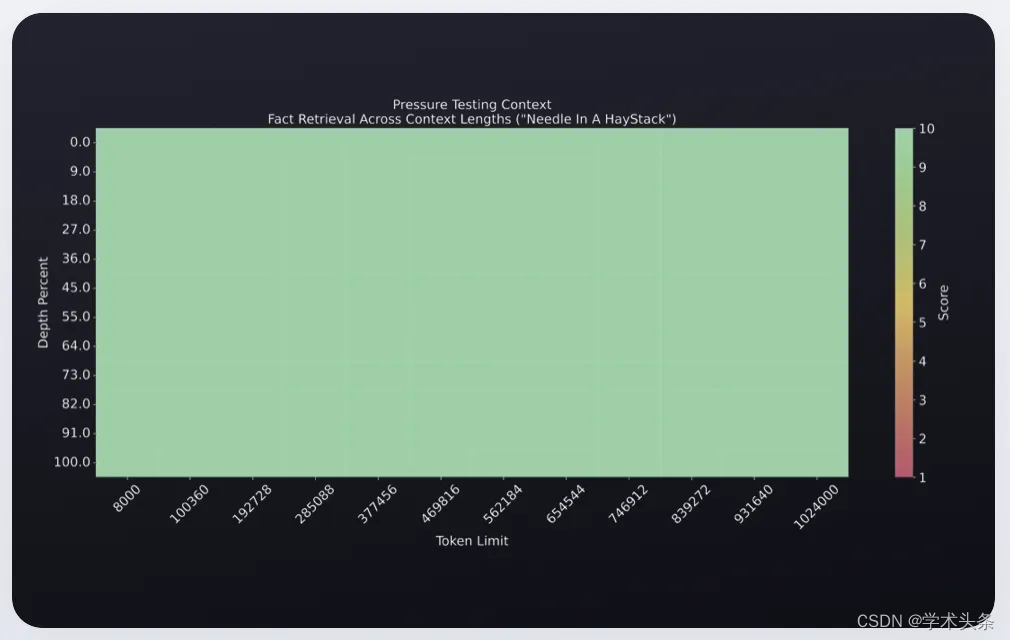
GLM-4-9B-Chat-1M 模型在 1M 的上下文长度下进行了“大海捞针”实验,展现出了出色的无损处理能力。
多语言能力
GLM-4-9B 支持包括汉语、英语、俄语、西班牙语、德语、法语、意大利语、葡萄牙语、波兰语、日语、荷兰语、阿拉伯语、土耳其语、捷克语、越南语、波斯语、匈牙利语、希腊语、罗马尼亚语、瑞典语、乌克兰语、芬兰语、韩语、丹麦语、保加利亚语和挪威语在内的 26 种语言。
为了提升性能,我们将 tokenizer 的词表大小从 65k 扩充到了 150k,这一改进使得编码效率提高了 30%。在多语言能力方面,我们在六个不同的多语言理解和生成数据集上进行了测试,结果显示 GLM-4-9B-Chat 显著超越 Llama-3-8B-Instruct。具体评测结果如下:

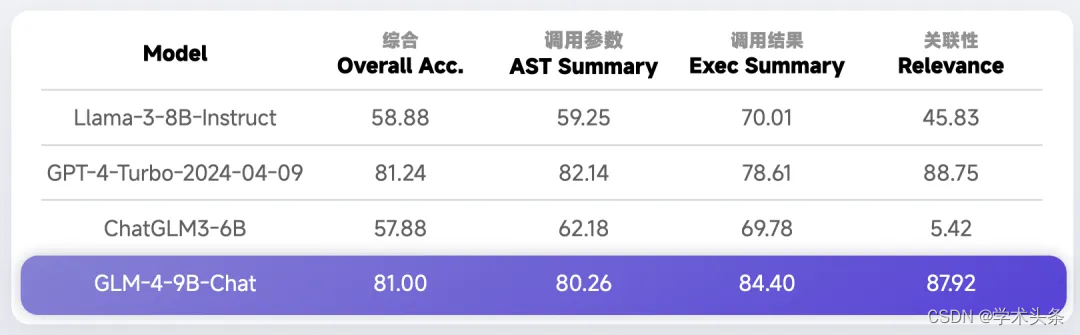
Function Call 能力
ChatGLM3-6B 模型的函数调用一直广受各大开发者喜爱。GLM-4-9B 模型的函数调用能力更是迎来了巨大的升级,相比上一代提升了 40%,在 Berkeley Function-Calling Leaderboard 上,GLM-4-9B 模型的 Function Call 能力与 GPT-4 不相上下。
All Tools 能力
“All Tools”即模型能够理解和使用一系列外部工具(比如代码执行、联网浏览、画图、文件操作、数据库查询、API 调用等)来辅助回答问题或完成任务。
在 1 月 16 日的 Zhipu DevDay 上,GLM-4 模型全线升级了 All Tools 能力,模型可以智能调用网页浏览器、代码解释器、CogView 来完成用户的复杂请求。
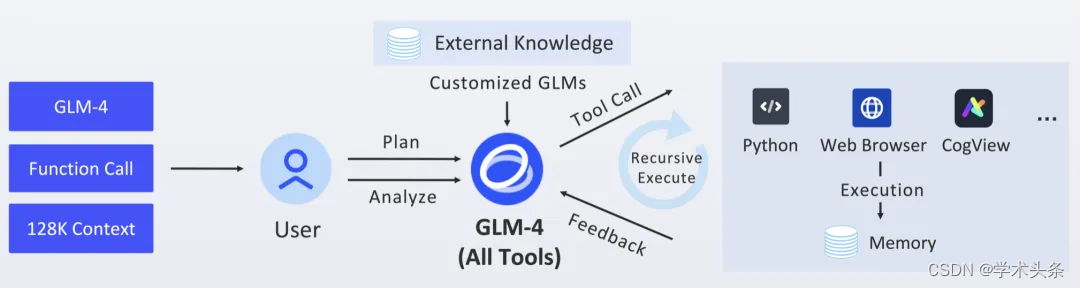
我们将这一功能带到了 GLM-4-9B 模型中,我们在开源仓库中提供了一个完整的 All Tools Demo,用户可以在本地拥有一个轻量级的清言平替。
多模态能力
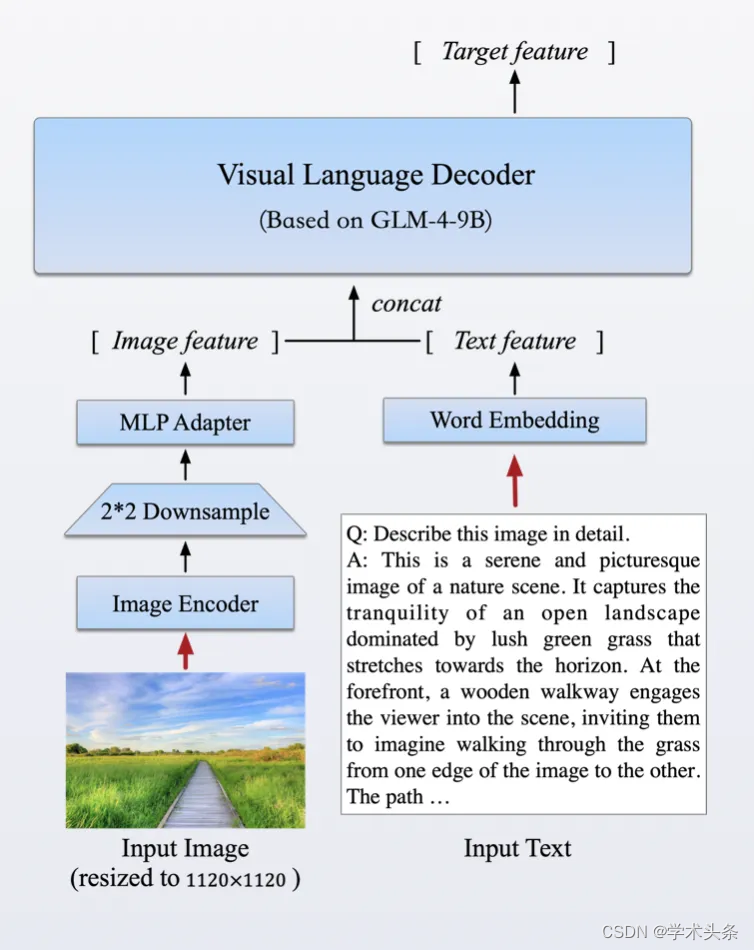
在强化文本能力的同时,我们首次推出了基于 GLM 基座的开源多模态模型 GLM-4V-9B。这一模型采用了与 CogVLM2 相似的架构设计,能够处理高达 1120 x 1120 分辨率的输入,并通过降采样技术有效减少了 token 的开销。为了减小部署与计算开销,GLM-4V-9B 没有引入额外的视觉专家模块,采用了直接混合文本和图片数据的方式进行训练,在保持文本性能的同时提升多模态能力。
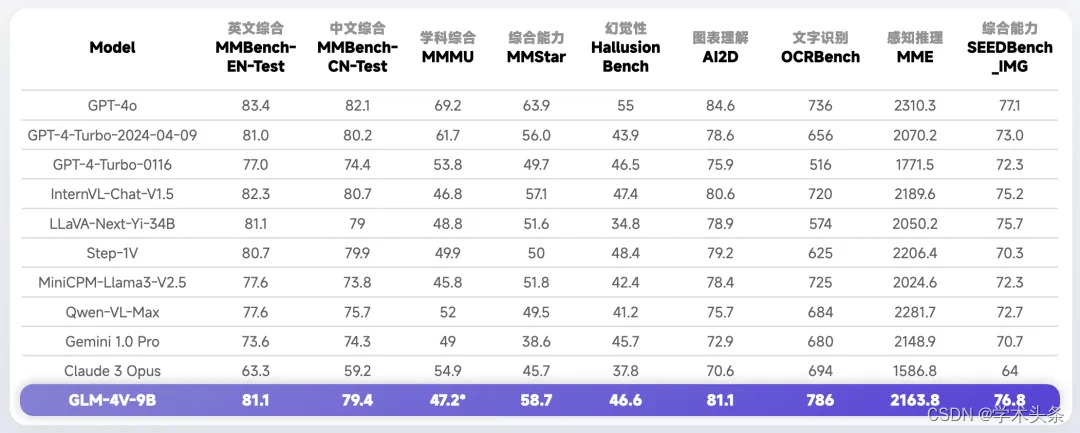
在性能方面,GLM-4V-9B 模型展现了显著的优势。尽管其参数量仅为 13B,但它成功地超越了许多参数量更大的开源模型。在众多任务中,GLM-4V-9B 的性能与 GPT-4V 不相上下。
以下两个 demo 展示了 GLM-4-9B 多模态能力。

在第一个示例中,我们要求模型识别一件 T 恤上的公式印花。模型准确地识别出这是麦克斯韦方程组,并且当我们进一步追问关于麦克斯韦方程组的细节时,模型能够依靠其文本处理能力给出回答。这一过程证明了我们在引入多模态功能的同时,并未牺牲模型的文本处理能力。
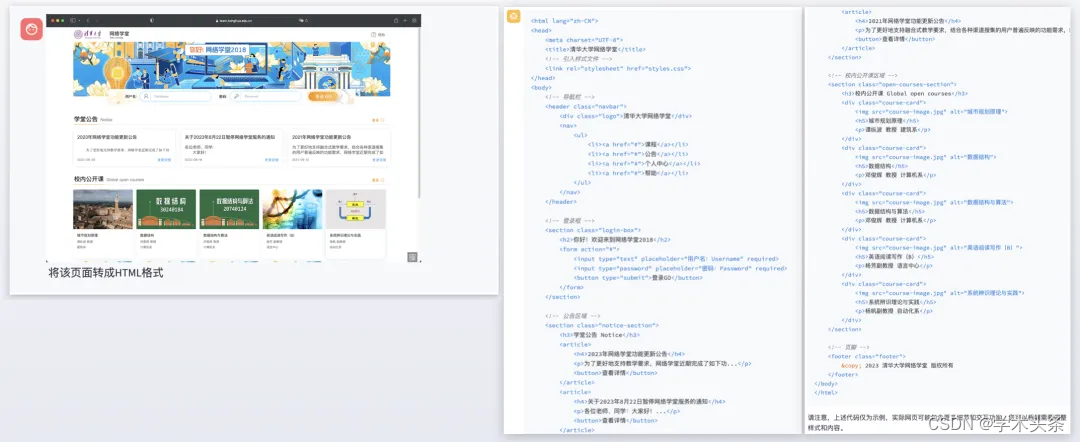
在第二个示例中,我们输入了一个网页截图,并要求模型将其翻译成 HTML 代码。模型能够直接识别截图中的元素,并输出相应的代码,展现了其在多模态任务中的实用性。
相关链接:
代码:
https://github.com/THUDM/GLM-4
模型:
Hugging Face:
https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7
魔搭社区:
https://modelscope.cn/organization/ZhipuAI

