
- 1c++ stringstream_c++ stringstream清空
- 2【小程序】发布商品(上传图片、数据校验)_10rpx
- 3GPT磁盘及ID号介绍_gpt分区id
- 4实验4《算符优先分析法设计与实现》(java版)_实验4《算符优先分析法设计与实现》(java版)
- 5Linux ln命令 软链接和硬链接_linux lvm创建分区
- 6实验三、SPARK RDD基础编程方法二_ubuntu的spark实验rdd
- 7代码逻辑分析_借助Elaborated Design优化RTL代码
- 8如何解决mfc100u.dll丢失问题,关于mfc100u.dll丢失的多种解决方法
- 9数据挖掘十大经典算法_数据挖掘十大经典算法及各自优势
- 10数据结构(用 JS 实现栈和队列【三种方式】)
保姆级零基础微调大模型(LLaMa-Factory,多卡版)_llamafactory多卡训练
赞
踩
此处非常感谢https://github.com/hiyouga/LLaMA-Factory这个项目。
看到网上的教程很多都是教如何用webui来微调的,这里出一期命令行多卡微调教程~
1. 模型准备
模型下载比较方便的方法:
1. modelscope社区(首选,速度很高,并且很多需要申请的模型都有)注意要选择代码下载,直接用命令行下载模型文件下不下来。注意默认的话是虾到系统盘里,加上cache_dir这个参数
2. huggingface镜像网站(不用梯子,但是该申请的还是需要申请)
3.自行下载网上云盘资源等(上传比较慢,若采取此方法,推荐使用XShell等工具)
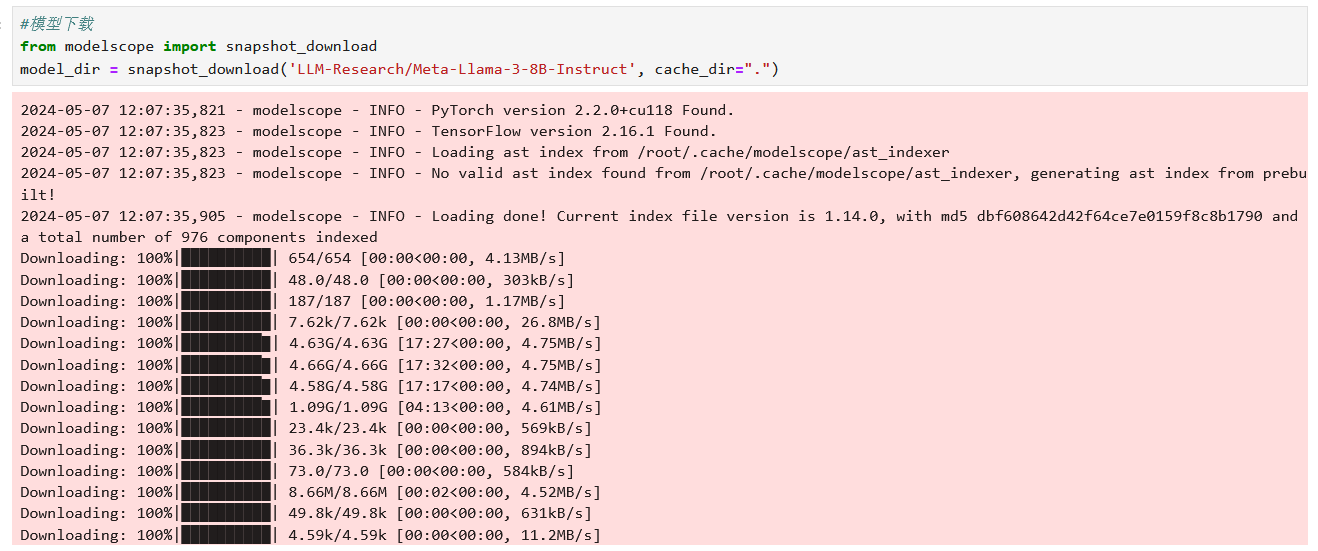
2. 数据集准备
数据集主要有两种格式,这里直接参考仓库里面给出的示例数据即可(非常简单)
有以下几点注意:
1. 对于自己的数据集,首先去测试一下instruction+input的长度,方便后面设定cutoff_len
2. 记得去data_info.json里面加上自己的数据集信息,参考其他即可。此处有个坑,本来是需要有哈希码来对应文件的,但是这个哈希码很神奇,乱写的哈希码会报哈希不对应,对应的哈希码还是会报错。所以,最后干脆没写,就能跑了,而且自己新加了2个数据集都没写,都没有问题。
3. 修改命令
下面主要是介绍在单台服务器(single node),多个GPU(multi gpu)的参数设置
要注意的主要是以下几点:
1. eval看是否需要,eval时间对于参数量比较大+数据量比较大而言有点长,可以直接把per_device_eval_batch_size、eval_steps、evaluation_strategy、load_best_model_at_end、val_size删掉,注意是删掉。
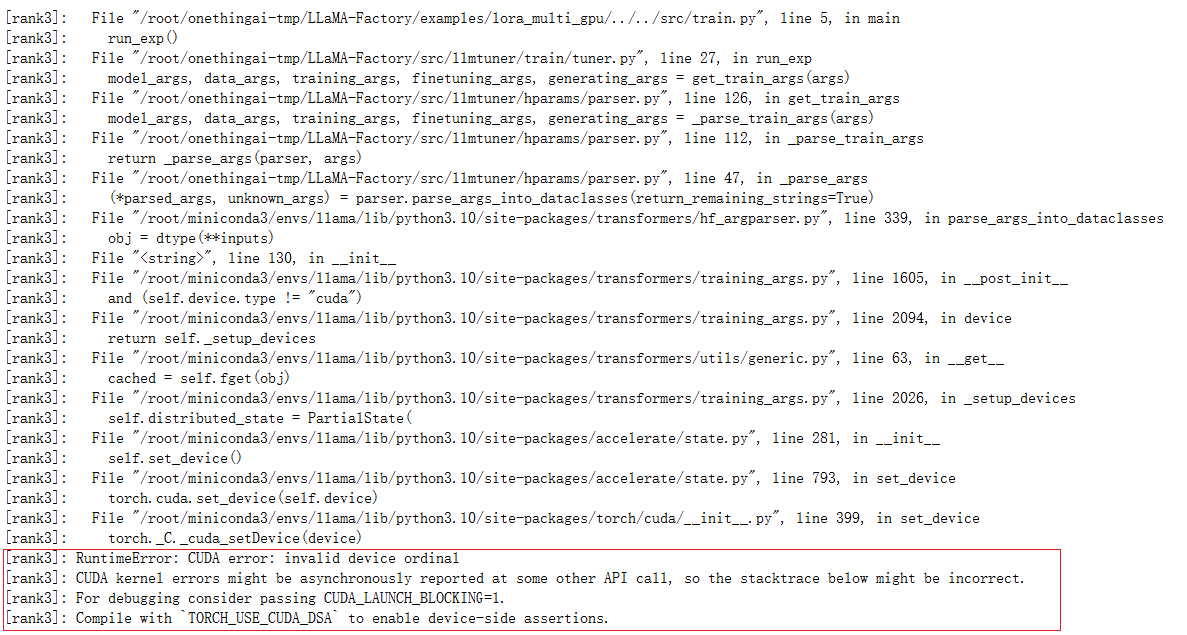
2. 多卡并行时,记得去对应的.yaml改gpu的个数!(建议卡数为2的次方,和操作系统有关)最新一版貌似已经很明显了,大家应该会记得去改的~ 忘记改的话就会像我下面这样报错
3. template记得改成你的模型名称,不能直接default,lora_target也是去找README进行修改
4. batch设置自己的显存能够跑起来的,我的是40G显存,只能设最大为4,最后的batch_size实际上是卡数 * 每张卡的batch * 累计步数,所以想要大一点的batch_size,可以对应地把gradient_accumulation_steps调高一点。理论上来说,batchsize大一些训练得会稳定一些,但是相应的学习率也应该稍微调大一些,具体可以参考这篇blog,写得很清楚。
4. 开训

训练的时候注意以下几点:
1. 可先用小数据集训一版,直接在sh文件中修改max_samples参数,跑一轮确定一下batch_size大小为多少比较合适
2. 还要注意系统盘是否够大,否则数据加载不完就满了也无法进行训练
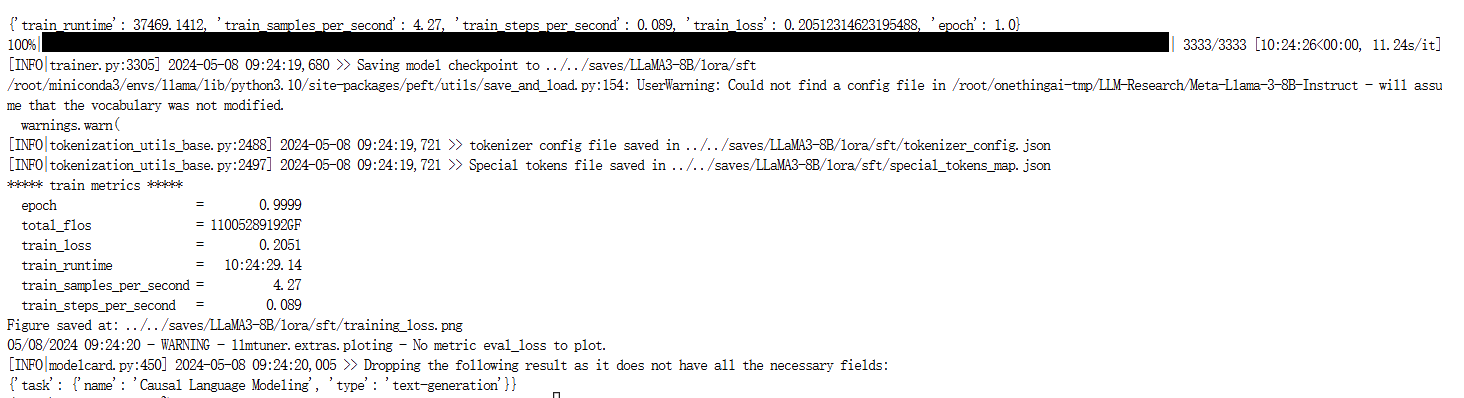
训练成功后:
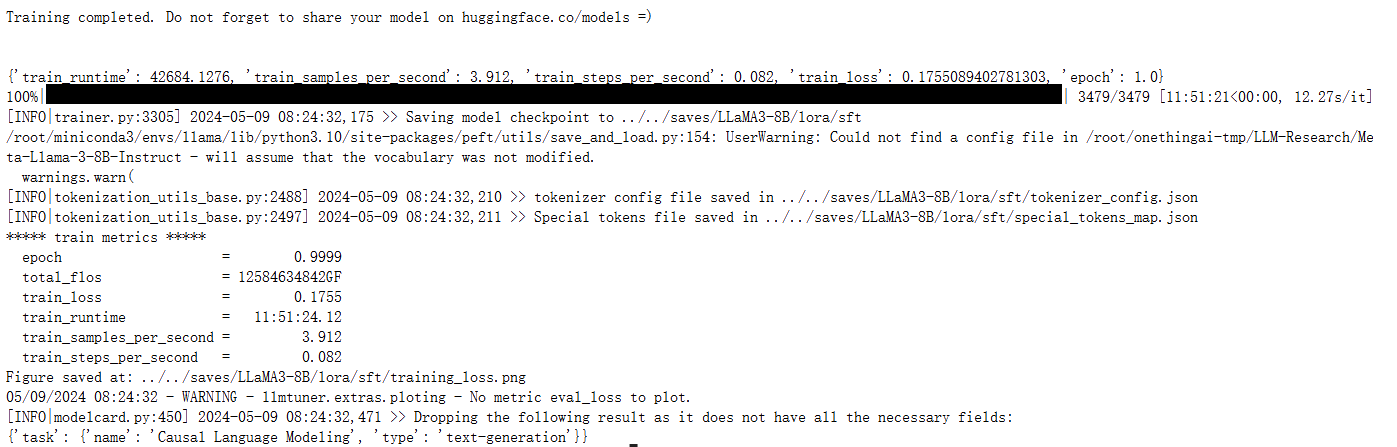
loss图像:
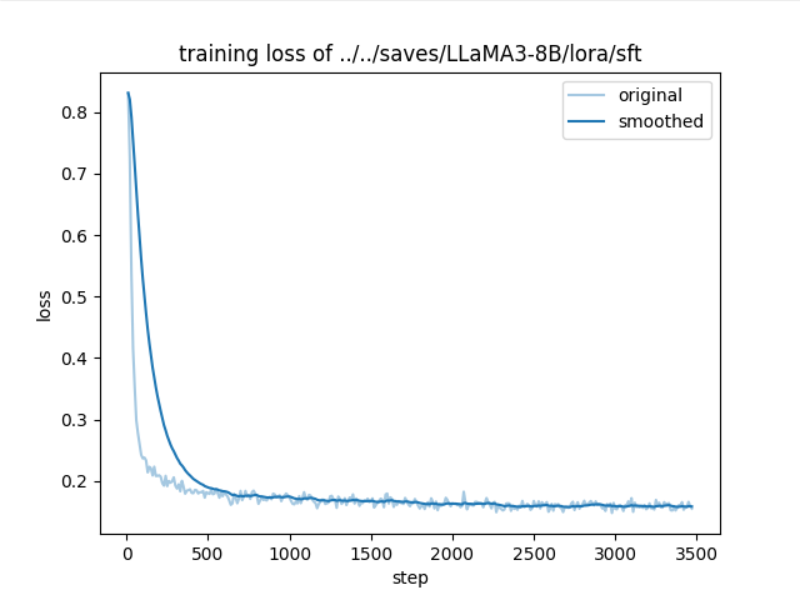
5. 结果评测
先要进行merge 基础模型以及LoRA,再进行推理。推理建议使用vllm,速度会快很多。
merge_model在example里面有基本命令,需要注意的如下:
1. template记得改成对应的模型,其他参数基本不需要修改
6. 总结反思
第一次尝试多卡微调大模型中途遇到了挺多坑,并且感觉有一些思维上的误区,要及时记录下来:
1. 使用unsloth训练只能用单卡
2. 配置文件一定要好好看,每个都看懂,比如说yaml文件,有一些配置默认的要改成合适的,在微调的时候就要多点去了解每个参数的含义
3. 报错第一时间去看issue,而不是在网上乱搜
4. 要尽量使用2的次方的卡数,比方说2,4,8,用其他的不符合操作系统的规律,可能会有一些问题,比如说算力分配不均衡,2**n的张量无法拆分进行运算
5. 系统盘如果不够的话可以直接清空.cache文件(都是缓存文件),一般在根目录下 cd ~
6. 训练的时候一定要明晰训练集和测试集的分布。比方说如果测试集原来的分布就和训练集一样,那就不要乱搞训练集增强,不要说训得不好的那些数据集再让他学习更多次,这样分布会变,让模型倾向于生成这些hard样本模式的。有一种情况可以调整数据分布不平衡的情况,训练集明显有偏,比如说99%正样本,1%负样本这些。
7. 在跑代码之前都要记得用小数据集进行试试,说不定跑完才报错呢!
8. 验证集,按自己需求,想快点就不要经常valid,或者调小一点比例
9. 推理的时候,可能有时候贪心就是最好的,直接设temperature=0,topk=1
10. 注意maxlen,一定要看清楚训练的数据集的长度,实现统计一下,重要的信息不要放后面,实验证明大模型还是会更加关注前面的信息,所以rerank是个很好的提分trick! 至于如何rerank也是很有技巧的,一定要注意分布要相同,最好就是选Top-K确定的,不要一个是2个一个是10个,这样分布很不好看!
11. 比LoRA稳定好的还有LoRA+,PLoRA,稳定涨1-2%左右,微调之前先调研清楚呀!!
12. 迭代LoRA的效果不好!!不要幻想着训完一个LoRA之后再来一个LoRA,真的没有重训好

