
- 1vivado SRIO 学习
- 2Ubuntu20.04中复现FoundationPose
- 3【等保小知识】等保分几级?每个级别怎么区分?_等保类型
- 4低代码:美味膳食或垃圾食品?
- 5秋读|10本热门图书(人工智能、编程开发、架构、区块链等)免费送!_李运华 电子科技大学
- 6步进电机基础(2.3)-电机按相分类及其结构_步进电机按相位分类
- 7k8s 1.23.1部署gitlab、 gitlab-runn配置k8s集群编写.gitlab-ci.yml实现根据tag,分支发布CICD流程_gitlab-ci.yml怎么根据分支处理
- 8Windows下Python调用海康SDK实时显示网络摄像头_python 海康sdk显示图像
- 9基于华为云 设备接入IoTDA的数据实时查看_华为云物联获取设备属性
- 10Flink面试题与详解_flink 面试题
【NLP】用MLP、CNN、RNN解决文本情感分类问题_cnn和mlp能否用于文本处理
赞
踩
这是一个练手MLP、CNN、RNN的demo,pytorch实现。包含预处理,数据加载,模型构建,训练,测试,性能展示训练模型全套。细致讲解整个代码实现过程的每一步。
训练环境:
Ubuntu 18.04
python 3.7
Conda
CUDA 10.2
GPU RTX2080Ti
任务目标
- 利用PyTorch深度学习框架,实现多层感知机(MLP)、卷积神经网络(CNN)和递归神经网络(RNN)。
- 利用已实现好的深度网络模型,实现文本数据预处理、载入、训练和测试等功能,并根据预测的结果计算分类指标。
- 需要提交实现代码一份以及作业报告一份。作业报告的具体要求见下面的任务详情。
- 附加目标:
a) 在模型中载入预训练好的词向量(word embedding),如Word2vec 或 Glove, 可使用网络上开源的训练好的词向量,也可自行训练;
b) 不使用PyTorch提供的RNN层,自行实现RNN层;
任务详情
- 利用PyTorch框架,分别实现MLP、CNN和RNN模型,具体要求如下:
MLP模型:需要包含至少一层隐层(hidden layer),每个全连接层的神经元数量需自行设置;
CNN模型:需要包含卷积层(convolution layer)与池化层(pooling layer),但不同于图像,文本的分类对卷积层的设置不同,设置方式见文章https://arxiv.org/abs/1408.5882,其余的参数需自行设置;
RNN模型:需要包含LSTM或GRU层,对应的参数需自行设置。
注:CNN模型的结构可以参考第四讲ppt的page 60。MLP的输入可以采用词袋模型(Bag-of-words),也采用嵌入表征(embedding),具体做法是将词表示为embedding,然后取一条文本中所有词的average embedding作为文本的嵌入表征。 - 对于给定的数据集,需要完成预处理、载入、训练和测试四个步骤,具体要求如下:
- 预处理:需要对原始的数据集进行预处理,使其符合神经网络需要的输入格式,详见数据集说明;
- 载入:对于预处理之后的文本数据,需要使用PyTorch的数据加载模块(Dataloader)进行数据载入,以进行批次训练,batch size需自行设置;
- 训练:使用实现好的神经网络模型对数据进行迭代的批次训练,使结果收敛,以得到效果较好的模型,迭代轮数(epoch)需自行设置;训练过程中,可以同时进行验证操作,以进更好的进行参数调节;在报告中,需要呈现出“训练集precision”,“训练集recall”,“训练集F1”和“训练集平均loss”随epoch的变化折线图,对应的指标计算方法在Python的sklearn包中均有相应接口;
- 测试:将测试数据经过同样的预处理与数据载入,输入进训练好的模型进行测试,得到测试结果,在报告中,需要呈现出“测试集precision”,“测试集recall”,“测试集F1”随epoch的变化折线图;还需要给出最好的epoch和最后一个epoch的precision、recall、F1的具体数值。
- 神经网络模型的参数较多,且调参效果与多个因素相关,故需要同学们了解各个参数所代表的意义,从而更好的调节参数,以到达更好的模型效果,在报告上只需呈现最终的模型参数即可;
- 附加目标为选做内容,同学们可根据自身情况选做以下内容,完成的同学会得到额外加分,具体情况如下:
a) 使用预训练好的词向量或模型有利于训练更好的文本分析模型。最著名的两个词向量工具Word2vec和Glove都提供了在大规模文本语料中预训练好的词向量或模型。同学们可从开放互联网上下载使用。一个可供下载的参考地址为:
https://blog.csdn.net/LeYOUNGER/article/details/79343404。
b) PyTorch已实现常用的RNN层,如LSTM和GRU,有能力的同学可自行实现LSTM层或GRU层,理解其中的数学原理。
c) 如完成了选做内容,请在报告中简述对应内容的做法及代码中的位置。
数据集说明
- 本数据集为Kaggle上开源的推特情感分类数据,为二分类数据集。原始数据集总文本量为1600000,为了减少作业训练压力,从中随机选择部分样本作为本次作业的数据集,原始数据集已进行简单的文本处理,使得文本更易于情感分类,且已过滤掉长度小于5的文本。项目原始地址为:https://www.kaggle.com/kazanova/sentiment140
- 处理后的数据集包含100000个训练样本和20000个测试样本,其中,正类和负类各占一半。训练样本文本为train_X.txt,标签为train_Y.txt;测试样本文本为test_X.txt,标签为test_Y.txt,文本与标签每行相对应。请以“latin-1”编码打开数据文件。
- 文件中的每一行均为一条评论的文本。载入数据集后需对文本进行如下的预处理操作:
a) 分词:英文以空格分割单词,删除句首句尾的换行符等无关字符,并进行大小写转换等其他需要的操作;
b) 构建词典:本数据集词典已在vocab.txt中给出,无需构建。如果觉得词典过大,也可以自己再删掉部分低频词。改文件请以“latin-1”编码打开,每一行为对应的单词和对训练集统计的词频,以‘\t’(tab键)分割;
c) 词索引转换:PyTorch的嵌入层需要输入词的索引进行词嵌入,故需要将文本序列根据词典转换为索引的序列;不在词典中的词课统一替换为标识符,标识符也需要对应一个索引;
d) 确定输入长度:每句话的长度不同,需要统计文本长度以选择合适的序列长度,不要过长也不要过短;确定长度后需要对过长的文本进行裁剪,对过短的文本进行补齐,可自行实现,也可借助PyTorch的padding工具。
实现过程
0 引言
本次作业利用Pytorch实现了MLP、CNN、RNN三种神经网络,并且实现了一个简单的RNN网络。分别在老师给定的vocab上对数据集进行训练,并载入预训练好的词向量Glove作为对照试验。
1 代码结构说明
本次实现的网络结构较多、数据集处理较复杂、设计对照试验因此代码结构较为复杂,代码结构包含3个文件夹和5个python文件,如下:

Data文件夹中存放数据集,包括train_X.txt、train_Y.txt、test_X.txt、test_Y.txt、vocab.txt五个文件,分别是训练集文本数据、训练集标签、测试集文本数据、测试集标签和词典。
GloVe文件夹中存放下载的预训练好的词向量glove.6B.300d.txt。
runs文件夹中存放tensorboard文件,用于实时查看训练效果。
main.py是代码的主干,包括可选参数、加载数据集到GPU、模型选择、模型训练、模型测试、结果展示几个部分。
config.py是配置文件,保存着文件路径、模型超参数等静态信息。
dataset.py中构建了一个Dataset class,用于加载数据集。
models.py保存MLP、CNN、RNN、myRNN四个网络模型。
utils.py是数据预处理部分,包括训练集、测试集、vocab、glove的处理。
2 前期配置
代码中用到了需要额外下载配置的库和文件。
2.1 tensorboard
tensorboard在模型训练过程中经常用于实时查看模型训练效果,能很好的反应出训练效果。
####2.1.1 install
pip install tensorboard
- 1
####2.1.2 run
在terminal中输入
tensorboard --logdir=runs --port=3389
- 1
在浏览器中输入网址http://localhost:3389/即可查看训练效果
####2.1.3 files introduce
在runs文件目录中已经保存了12个训练好的模型效果共查看
MLP_with_glove_vocab:代表采用MLP模型,使用预训练词向量glove与老师提供的vocab求交集作为词典,不在词典内的词均用表示。
MLP_with_vocab:代表采用MLP模型,仅使用老师提供的vocab作为词典,不在词典内的词均用表示。
MLP_with_glove:代表采用MLP模型,仅使用预训练词向量glove作为词典,不在词典内的词均用表示。
RNN、CNN、myRNN开头的文件以此类推
2.2 GLove
预训练词向量glove从官网下载,选用Wikipedia 2014,822MB压缩文件,选择其中将一个词表示为300维的词典glove.6B.300d.txt,若使用其他的词典,可以自行下载,并对代码相关部分进行修改。
3 可选参数&超参数
###3.1 可选参数
在运行时设置了模型选择、词典选择、是否进行预训练三个可选参数,代码在main.py的主函数中,如下:
parser = argparse.ArgumentParser(description='manual to this model')
parser.add_argument('--model', type=str, default='myRNN')
parser.add_argument('--choose_vocab', type=str, default='vocab')
parser.add_argument('--pretrain', type=bool, default=False)
args = parser.parse_args()
- 1
- 2
- 3
- 4
- 5
运行代码示例如下:
python main.py
- 1
会调用默认参数训练,即:采用RNN模型、使用vocab作为词典、不进行预训练。需要注意的是,选择字典仅在进行预训练的情况下才会生效。--pretrain=False时,字典为老师给定的字典。
当然,也可以根据需要调整可选参数,比如采用CNN模型,使用glove作为字典,进行预训练。运行示例代码如下:
python main.py --model=CNN --pretrain=True --choose_vocab=glove
- 1
###3.2 超参数
针对不同的网络模型,learning_rate、dropout、epoch、batch_size等超参数的设置也有不同。因此在选择对应模型后,会加载不同的超参数用于训练。代码在config.py的Config类中。如下:
class Config(object): def __init__(self, args): assert args.model in ['MLP', 'RNN', 'CNN', 'myRNN'] assert args.choose_vocab in ['vocab', 'glove'] self.model = args.model self.choose_vocab = args.choose_vocab self.pretrain = args.pretrain self.path = { 'train_X': './Data/train_X.txt', 'train_Y': './Data/train_Y.txt', 'test_X': './Data/test_X.txt', 'test_Y': './Data/test_Y.txt', 'vocab': './Data/vocab.txt', 'glove': './GloVe/glove.6B.300d.txt' } self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') self.max_len = 31 self.vocab_size = 25467 self.embedding_dim = 300 if self.model == 'MLP': self.epoch = 1000 self.batch_size = 100000 self.learn_rate = 1e-4 self.hidden_size = 500 elif self.model == 'RNN' or self.model == 'myRNN': self.epoch = 20 self.batch_size = 4096 self.learn_rate = 1e-3 self.hidden_size = 200 self.num_layers = 2 self.dropout = 0.5 elif self.model == 'CNN': self.epoch = 100 self.batch_size = 32768 self.learn_rate = 1e-3 self.dropout = 0.25 self.n_kernel = 128 self.filter_sizes = [3, 4, 5]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
超参数命名遵信常规命名,不在赘述具体含义。调用代码在main.py中,代码如下:
from config import Config
cfg = Config(args)
- 1
- 2
4 数据预处理
数据预处理较为复杂。包括对训练数据、标签、字典的预处理。实现代码在utils.py中。
4.1 字典
4.1.1 vocab
老师给的字典共两列,第一列是单词,第二列是该词出现的次数,为了能更好的学到参数,我在处理时将出现次数少于2次的单词全部用代替。并将数据整理为{‘word’: index}的格式。代码如下:
def load_vocab(path):
with open(path) as f:
data = f.read().splitlines()
data = [line.split() for line in data]
words = [word for word, count in data if int(count) > 1]
vocab = {word: index for index, word in enumerate(words, start=2)}
vocab.update({'<pad>': 0, '<unk>': 1})
return vocab
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.1.2 glove
glove每一行共301个项,第一项是单词,后面300项为表示该次的词向量。需要将数据整理成{‘word’: [tensor]}的形式。在load_glove()函数中除了转换glove格式外,还要生成同4.1.1中格式相同的vocab,因此还包含选择用老师给的词典,还是用glove作为词典。
def load_glove(path, choose_vocab): with open(path['glove']) as f: datas = f.read().splitlines() datas = [line.split() for line in datas] if choose_vocab == 'vocab': vocab = load_vocab(path['vocab']) else: words = [data[0] for data in datas] vocab = {word: index for index, word in enumerate(words, start=2)} vocab.update({'<pad>': 0, '<unk>': 1}) glove = {data[0]: np.array([float(i) for i in data[1:]]) for data in datas} glove.update({'<pad>': np.zeros(300), '<unk>': np.ones(300)}) return vocab, glove
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.2 数据
4.2.1 数据加载
train_X.txt、test_X.txt中每一行是一个完整的句子,因此要将句子切分成单词保存,实际训练中,单词不能作为输入,要改成索引输入,因此要对照4.1中生成的vocab,生成句子的索引序列。代码如下:
def load_sents(path, max_len, vocab): sens = [] with open(path) as f: for line in f: sen = [] sentence = line.strip().split() for word in sentence: if word in vocab.keys(): sen.append(vocab[word]) else: sen.append(vocab['<unk>']) if len(sen) in count_len.keys(): count_len[len(sen)] += 1 else: count_len[len(sen)] = 1 sens.append(sen) sens = normalize(sens, max_len) # count every sentence len, found the longest sentence # print(count_len) return sens
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其中count_len是用来统计文本长度的一个dict,通过观察发现,绝大多数句子的长度在31个单词以内,因此将31作为合适的序列长度。
####4.2.2 输入长度整理
上述代码中count_len是用来统计文本长度的一个dict,通过观察发现,绝大多数句子的长度在31个单词以内,因此将31作为合适的序列长度对过长的文本进行裁剪,对过短的文本进行补齐 。补齐代码如下:
def normalize(sens, max_len):
temp = []
for sen in sens:
if len(sen) > max_len:
sen = sen[:max_len]
elif len(sen) < max_len:
sen = [0] * (max_len - len(sen)) + sen
temp.append(sen)
return temp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.3 标签
train_Y.txt、test_Y.txt中每一行只有一个元素,为对应的情感标签,因此按行读入,转换成浮点数即可,代码如下:
def load_label(path):
with open(path) as f:
label = [int(line) for line in f]
return label
- 1
- 2
- 3
- 4
- 5
4.4 配对
为了在接下来的方便调用pytorch的DataLoader,需要对数据和标签进行一对一捆绑,形成train_set和test_set,数据格式为[x, y],代码如下:
def make_pair(x, y):
pairs = []
for i in range(len(x)):
tempx = np.asarray(x[i])
tempy = np.asarray(y[i])
pairs.append([tempx, tempy])
pairs = np.array(pairs)
return pairs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.5 封装
将上述部件封装起来,方便调用,其中在选择字典时需要判断,代码如下:
def load_data(cfg): glove = None if cfg.pretrain: vocab, glove = load_glove(cfg.path, cfg.choose_vocab) cfg.vocab_size = len(vocab) else: vocab = load_vocab(cfg.path['vocab']) train_X = load_sents(cfg.path['train_X'], cfg.max_len, vocab) test_X = load_sents(cfg.path['test_X'], cfg.max_len, vocab) train_Y = load_label(cfg.path['train_Y']) test_Y = load_label(cfg.path['test_Y']) train_set = make_pair(train_X, train_Y) test_set = make_pair(test_X, test_Y) return train_set, test_set, vocab, glove
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
main.py调用方式如下:
from utils import load_data
train_set, test_set, vocab, glove = load_data(cfg)
- 1
- 2
5 模型构建
模型均保存在models.py文件中,共四个模型。
5.1 MLP
多层感知机由一个embeding层和三个线性层构成。每层的大小维度见注释,代码如下:
class MLP(nn.Module): def __init__(self, cfg, vocab, glove): super(MLP, self).__init__() self.glove = glove self.vocab = vocab self.embed = nn.Embedding(cfg.vocab_size, cfg.embedding_dim) if glove is not None: self.weight_matrix = create_weight_matrix(self.vocab, self.glove) self.embed.load_state_dict({'weight': self.weight_matrix}) self.fc1 = nn.Linear(cfg.embedding_dim, cfg.hidden_size) self.fc2 = nn.Linear(cfg.hidden_size, cfg.hidden_size) self.fc3 = nn.Linear(cfg.hidden_size, 1) def forward(self, x): # x: batch_size * seq_len e = self.embed(x) # batch_size * seq_len * hidden_size h = e.mean(dim=1) # batch_size * hidden_size h = F.relu(self.fc1(h)) h = F.relu(self.fc2(h)) h = self.fc3(h) return h.squeeze(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5.2 RNN
我选用的pytorch自带的LSTM作为RNN层,双层RNN,隐层维度为200,双向结构,代码如下:
self.rnn = nn.LSTM(
input_size=cfg.embedding_dim,
hidden_size=cfg.hidden_size,
num_layers=cfg.num_layers,
dropout=cfg.dropout,
bidirectional=True,
batch_first=True,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以及全连接层双隐层,神经元数分别为500、300,代码如下:
self.fc1 = nn.Linear(cfg.hidden_size * 2, 500)
self.fc2 = nn.Linear(500, 300)
self.out = nn.Linear(300, 1)
- 1
- 2
- 3
5.3 myRNN
自己实现的RNN较为简单,每次输入一句话,将一句话的每个单词放入RNN中更新参数,核心代码如下:
for t in range(self.seq_len):
tmp = torch.cat((e[:, t, :], pre_state), 1)
a[:, t, :] = self.in2hidden(tmp)
h = self.tanh(a[:, t, :])
pre_state = h
pre_y[:, t, :] = h
- 1
- 2
- 3
- 4
- 5
- 6
后面紧跟一个MLP,结构代码如下:
self.mlp = nn.Sequential(
nn.Linear(cfg.hidden_size, cfg.hidden_size * 2),
nn.Dropout(cfg.dropout),
nn.ReLU(),
nn.Linear(cfg.hidden_size * 2, 1),
)
- 1
- 2
- 3
- 4
- 5
- 6
5.4 CNN
CNN较为特殊,我采用的是pytorch中的nn.Conv2d函数,这样会从单词方向和embeding两个方向进行卷积,但其实embeding方向的卷积是没有意义的,后来得知pytorch中竟然已经提供了nn.Conv1d函数,但是效果对比并没有明显差别,因此没有进行修改。
CNN模型包括三个卷积层,每层包含128个卷积核,高度分别为3,4,5,全连接层单层隐层,神经元个数为500,采用max_pool1d即可。代码较长,不做展示,详见models.py中的CNN类。
5.5 加载Glove
为了在embeding是加入GLove,需要自己写load_glove函数,然后再调用embeding层时作为weight调用,生成weight矩阵代码如下:
def create_weight_matrix(vocab, glove):
weights_matrix = np.zeros((len(vocab), 300))
for key in vocab.keys():
if key in glove.keys():
weights_matrix[vocab[key]] = glove[key]
else:
# weights_matrix[vocab[key]] = np.random.normal(scale=0.6, size=300)
weights_matrix[vocab[key]] = np.ones(300)
weights_matrix = torch.from_numpy(weights_matrix)
return weights_matrix
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
对于vocab中不存在的单词,统一用300维的全1矩阵代替。(注释掉的代码是用随机生成300维矩阵代替,实际效果没有差别)
在embeding时调用该矩阵方式如下:
self.embed = nn.Embedding(cfg.vocab_size, cfg.embedding_dim)
if glove is not None:
self.weight_matrix = create_weight_matrix(self.vocab, self.glove)
self.embed.load_state_dict({'weight': self.weight_matrix})
- 1
- 2
- 3
- 4
6 模型训练
###6.1 数据加载
我采用pytorch自带的Dataloader进行数据加载,首先需要自己构建一个继承torch.utils.data.Dataset的类
class MotionDataset(torch.utils.data.Dataset):
- 1
需要写明每个数据的大小
def __len__(self):
return len(self.sentence)
- 1
- 2
并写清如何提取数据
def __getitem__(self, index):
return self.sentence[index][0], self.sentence[index][1]
- 1
- 2
完整代码在dataset.py中,封装好后在main.py中调用,得到train_loader和test_loader,代码如下:
from dataset import MotionDataset
train_loader = torch.utils.data.DataLoader(
MotionDataset(train_set),
batch_size=cfg.batch_size,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
MotionDataset(test_set),
batch_size=cfg.batch_size,
shuffle=False,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.2 选择模型
在load数据后要加载模型,并将模型放到GPU上,代码如下:
if cfg.model == 'MLP':
model = MLP(cfg, vocab, glove).train().to(cfg.device)
elif cfg.model == 'RNN':
model = RNN(cfg, vocab, glove).train().to(cfg.device)
elif cfg.model == 'myRNN':
model = myRNN(cfg, vocab, glove).train().to(cfg.device)
elif cfg.model == 'CNN':
model = CNN(cfg, vocab, glove).train().to(cfg.device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.3 激活函数
选用Adam作为激活函数,代码如下:
optimizer = optim.Adam(model.parameters(), lr=cfg.learn_rate)
- 1
6.4 训练
首先将数据放到GPU上,再将数据送入模型,进一步计算loss,采用binary_cross_entropy_with_logits作为loss函数,该函数在二分类中表现优秀,且内置了sigmoid函数,因此在模型中不需要额外添加sigmoid层,剩下的就是神经网络的八股文,代码如下:
data, label = data.to(cfg.device), label.to(cfg.device)
logits = model(data)
loss = F.binary_cross_entropy_with_logits(
input=logits,
target=label.double(),
reduction='mean',
)
model.zero_grad()
loss.backward()
optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
该部分还有很多额外的代码并没有解释,均为计算准确率,查看模型效果的辅助代码,详情可查看tqdm、tensorboard、sklearn.metrics文档查看详细的使用方法。
6.5 测试
测试部分代码与训练代码大同小异,不再赘述。
7 试验结果
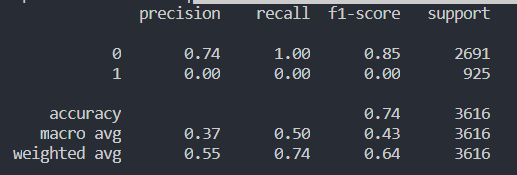
实验结果并不好,MLP训练1000轮,CNN训练100轮,RNN训练20轮,总体准确率在73%~75%之间
###7.1 precision、recall、F1
MLP的各项数据如下;


CNN各项数据如下:


RNN各项数据如下:


myRNN各项数据如下:
7.2 对比试验
所有的结果均保存在runs文件夹里,运行tensorboard即可查看

