- 12024年Java最新Java算法基础 - 单链表详解(文末有配套视频)(2),2024Java面试题知识点总结_链表 java
- 2Git 安全警告修复手册:解决 `fatal- detected dubious ownership in repository at ` 问题 ️_fatal: detected dubious ownership in repository at
- 3常用机器学习算法训练预测模型的常规流程
- 4计算机必背单词——术语和缩写
- 5美团校招机试 - 小美的MT(20240309-T3)
- 6Github 上最大的开源算法库,还能学机器学习_在github中怎么搜算法题
- 7FastAPI vs Flask: 选择最适合您的 Python Web 框架_fastapi和flask
- 8mysql的information_schema浅析
- 9vue权限管理解决方案
- 10【Struts2漏洞】Struts2全版本漏洞检测工具 v19.23 官方版_struts2漏洞利用工具
景芯SoC A72 12nm TOP的时钟树分析(二)
赞
踩
innovus的ctslog中的Clock DAG信息可以报出来CTS主要运行步骤的关键信息,比如clustering,balancing做完后的clock tree的长度,clock tree上所用的buffer、inverter,icg cell数量,clock skew等信息。我们以景芯SoC A72 TOP项目的maia_cpu core为例:

从clustering到balancing,clock ID(insertion delay)和buffer数量大幅增加,这是由于比如一些sinks存在于不同的skew groups,为了平衡skew group之间的skew,就会插入buffer并做大了clock ID,因此我们需要确认skew group的存在是否合理。
抓取cts.log中的Clock DAG
grep -E -A2 "Clock DAG" cts.log >> SoC_cts_Clock DAG.rpt
可以看到cell、sink的counts,也可以看到BUF、ICG的数量,接下来我们来看看景芯SoC A72 TOP的CLOCK ID和BUF个数的变化吧。
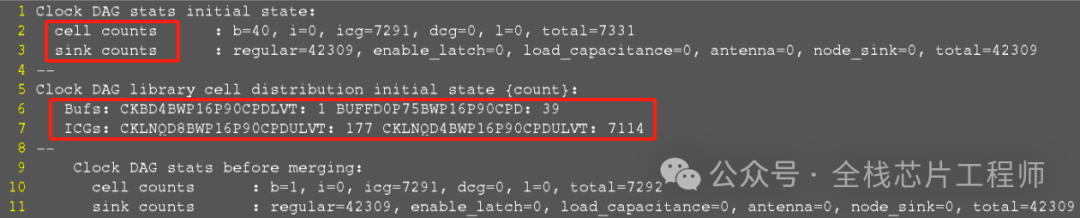
先看下景芯SoC A72项目的cts latency变化过程。将Clock DAG和Primary reporting一起抓出来:
grep -E -A2 "Clock DAG|Primary reporting" cts.log >> SoC_cts_latency_debug.rpt
打开报告SoC_cts_latency_debug.rpt,Clustering之后,IDmin=0.431 IDmax=0.690

Reducing insertion delay后:IDmax从0.690降低到了0.652

Balancing后:IDmin从0.431升到了0.569,而IDmax从0.652略微降低到了0.648

请思考,为何Balancing后:IDmin从0.431升到了0.569?
如果您和小编一样渴求进步,想掌握芯片设计全流程,欢迎加入小编知识星球,疯狂成长,一起进步!早日成为芯片大佬!

通过下面的命令报出所有skewgroup的最长和最短clock path。
report_ccopt_skew_groups-summary
景芯SoC A72项目maia_cpu这个harden的时钟为ck_gclkt,其Min ID为0.560,Max ID为0.661。

通过下面的命令来报出maxclock path的ID。
get_ccopt_skew_group_path -skew_group ck_gclkt/func_fast -longest

那么怎么抓取ID最长的路径呢?方法参见知识星球。
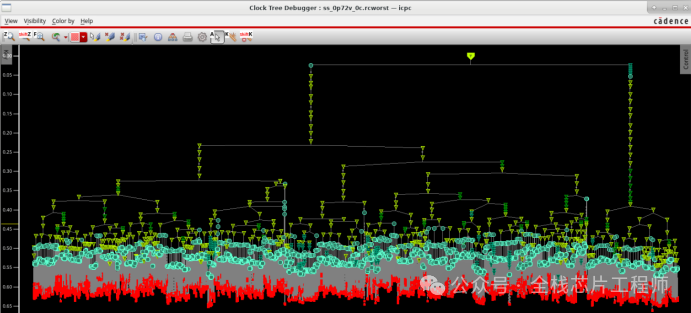
抓取最长路径后,高亮为红色,路径如下:
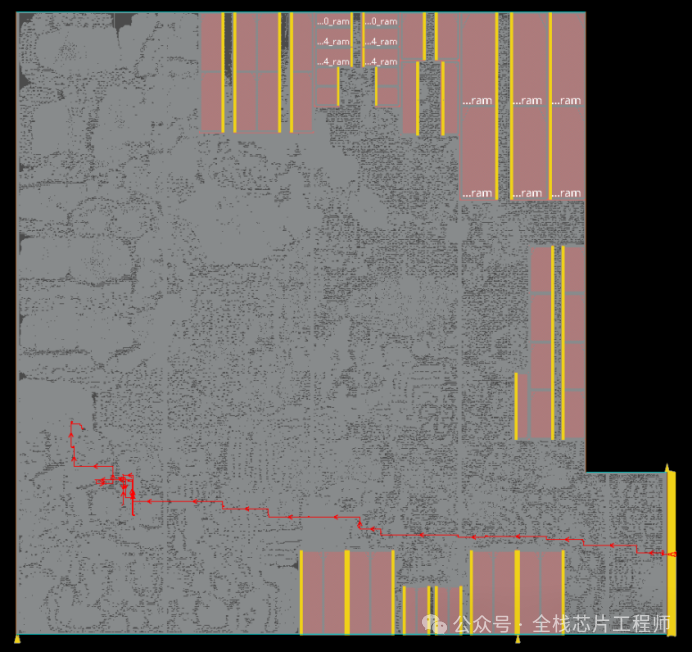
找到最长路径的clock path后,我们需要关注什么?
首先,看下时钟路径上存在fixed的clock cell,看摆放位置是否合理,比如执行命令:
get_dbclock_trees .insts -if { .place_status == fixed }
发现如下cts cell是fixed的,请问为何?景芯SoC A72实战训练营是特别讲过这两个ICG是干啥的,非常高阶。大家思考下这两ICG干啥的?
inst:maia_cpu/uck_cpu/ucpu_main/uck_gclkcx/uIcg inst:maia_cpu/uck_cpu/ucpu_main/uck_gclkcr/uIcg
更多内容参见景芯SoC A72训练营。
“12nm 2.5GHz频率 hierarchy UPF DVFS低功耗A72后端培训”

2.5GHz 12nm 景芯SoC A72 upf DVFS 后端实战训练营!
项目手把手一对一辅导!随到随学!
2.5GHz 12nm A72 maia_cpu实战价格6999!
2.5GHz 12nm A72 MAIA TOP实战价格8999!(含2个maia_cpu)
课程采用hierarchy/partition flow,先完成单核A72实战,然后完成A72 TOP实战!训练营简介:
-
Instance:315万
-
Gate count:2600万
-
Frequency: 2.5GHz
-
Power domain:7个,hierarchy UPF设计
-
EDA工具有VCS/Fusion Compiler/VCLP
-
EDA工具有innovus/Starrc/PT/Voltus/formality/LEC/Calibre
-
EDA工具有Redhawk-sc全网首发python版
-
授课形式:视频+文档+上机实践,真实项目flow,一对一答疑!
-
ICer加班太多,项目采用视频模式,随到随学!
景芯A72训练营您将掌握以下知识:
-
掌握hierarchy UPF文件编写,掌握Flatten UPF文件编写、UPF验证。本项目采用hierarchy UPF方式划分了7个power domain、voltage domain。
-
掌握power switch cell,包括SWITCH TRICKLE、SWITCH HAMMER。掌握低功耗cell的用法,选择合适的isolation cell、level shifter等低功耗cell。
-
掌握Power gating,Clock gating设计技术。
-
掌握Multi-VT设计技术,本项目时钟树都是ULVT,动态功耗小,skew小。
-
掌握DVFS技术,ss0p9 2.5GHz、ss0p72 2.0GHz,,其中sram不支持ss0p63。要做ss0p63的话,给sram vddm单独一个0p7v的电源即可。
-
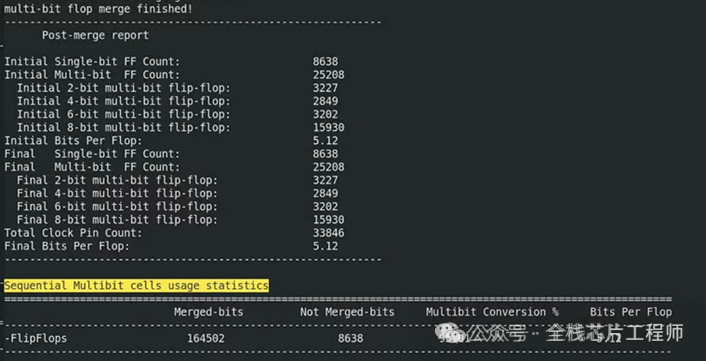
掌握multibit cell的用法,本项目CPU里面的mb高达95%,选择合适的multibit cell得到超高的CPU利用率。INNOVUS里面一般不做mb的merge和split。所以前后一样的,一般综合做multibit的merge split。
-
根据TOP Floorplan DEF进行CPU子系统的partition以及pin assignment。
-
Top的Power stripe的规划及其push down。
-
SpecifyBlackBox,将CPU core镜像partition。
-
手动manual cut the BlackBox的方法,掌握复杂的floorplan设计方法经验。
-
VerifyPowerDomain,检查低功耗划分以及UPF的正确性。
-
Pin assignment,根据timing的需求进行合理的pin脚排布,并解决congestion问题。
-
掌握Timing budget。
-
掌握利用Mixplace实战CPU的自动floorplan,掌握AI的floorplan方法学。

-
掌握Fusion compiler DCG,利用fusion compiler来完成DCG综合,进一步优化timing与congestion。
-
掌握hierarchy ICG的设计方法学,实战关键ICG的设置与否对timing的重大影响。
-
掌握Stapling技术,实战power switch cell的布局和特殊走线的方法学,掌握CPU子系统的powerplan规划及实现,保证CPU子系统和顶层PG的alignment。
-
掌握CPU子系统和TOP的时序接口优化。掌握TOP isolation cell的placement以及isolation cell input电学特性检查。
-
掌握TOP和CPU子系统的clock tree Balance优化处理,common clock path处理。时钟树结构trace和时钟树评价。
-
CPU子系统的DRC/LVS检查
-
TOP系统的DRC/LVS检查
-
Hierarchy & Flatten LVS检查原理及实现方法
-
静态时序分析&IR-Drop
-
DMSA flow
-
根据Foundry的SOD(signoff doc)的Timing signoff标准建立PT环境。
-
Star RC寄生抽取及相关项检查
-
Timing exception分析,包括set_false_path、set_multicyle_path解析。
-
PT timing signoff的Hierarchical和Flatten Timing检查
-
PT和PR timing的差异分析、Dummy insertion和with dummy的Timing分析
-
IR-Drop分析
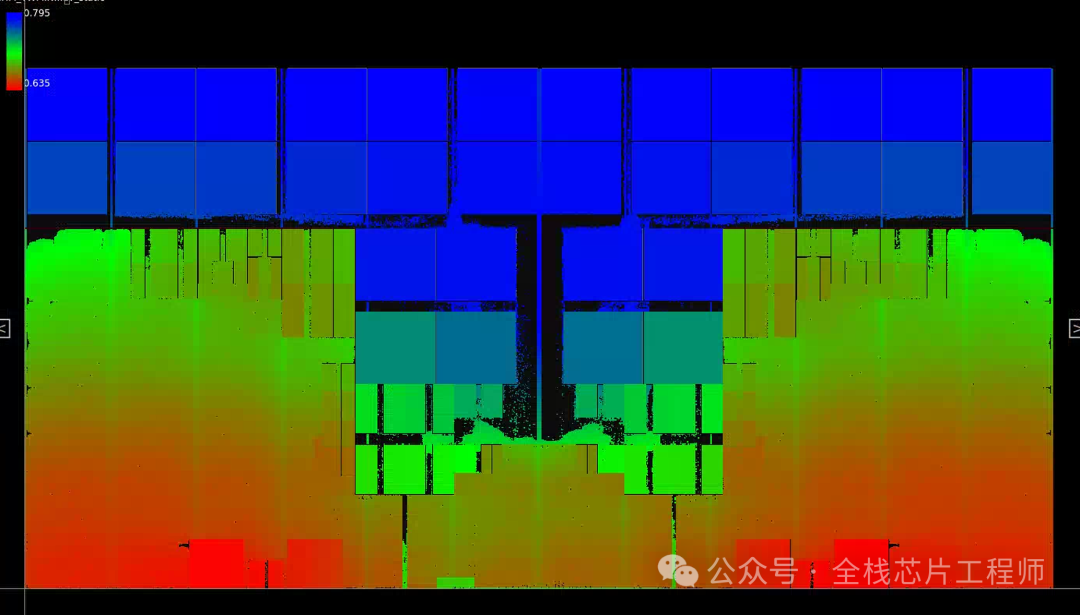
训练营部分文档:
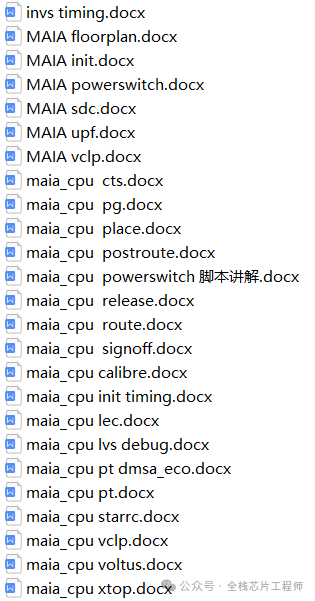
Flow:Partition Flow
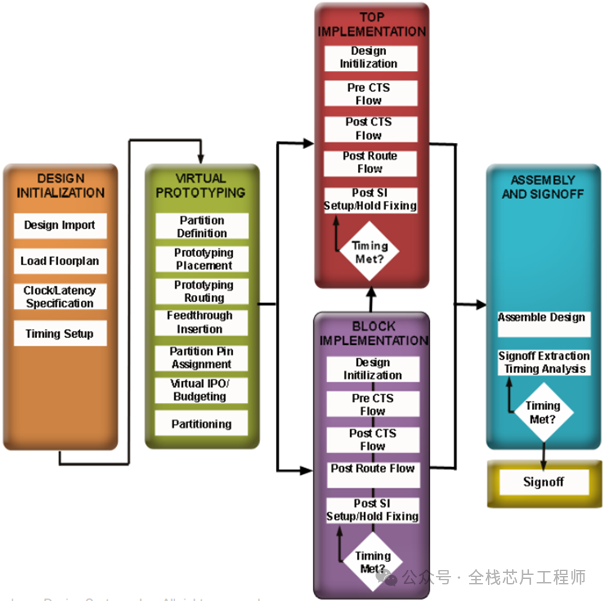
时钟结构分析:
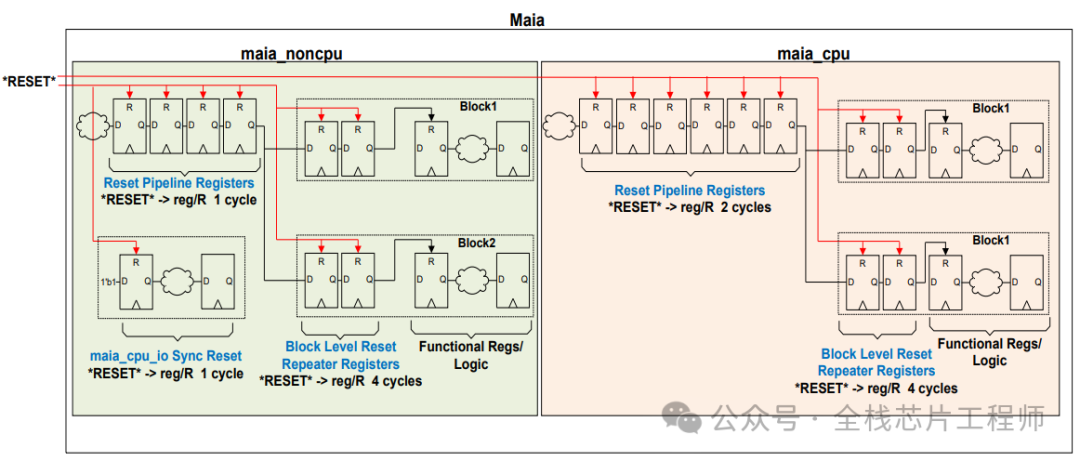
复位结构分析:
12nm 2.5GHz的A72实战训练营需要特别设置Latency,TOP结构如下,参加过景芯SoC全流程训练营的同学都知道CRG部分我们会手动例化ICG来控制时钟,具体实现参见40nm景芯SoC全流程训练项目,本文介绍下12nm 2.5GHz的A72实战训练营的Latency背景,欢迎加入实战。
时钟传播延迟Latency,通常也被称为插入延迟(insertion delay)。它可以分为两个部分,时钟源插入延迟(source latency)和时钟网络延迟(Network latency)。
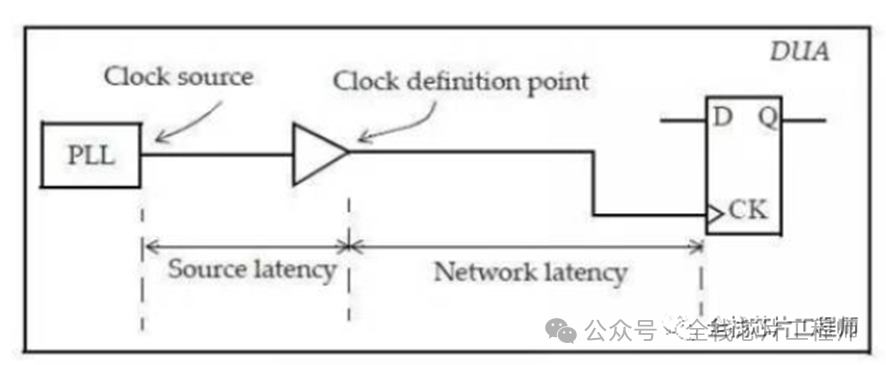
大部分训练营同学表示平时都直接将Latency设置为0了,那latency值有什么用呢?其实这相当于一个target值,CTS的engine会根据你设置的latency值来插入buffer来实现你的latency target值。
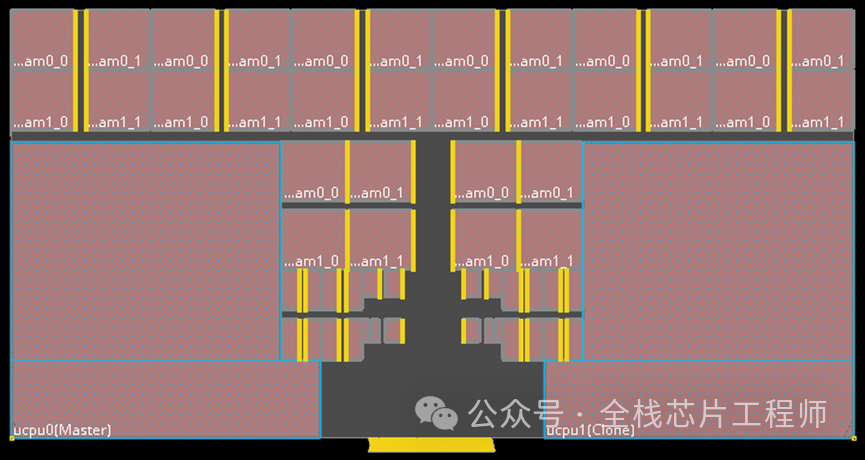
下图分为1st Level ICG和2nd Level ICG,请问这些ICG为什么要分为两层?
请问,为什么不全部把Latency设置为0?2nd Level ICG的latency应该设置为多少呢?
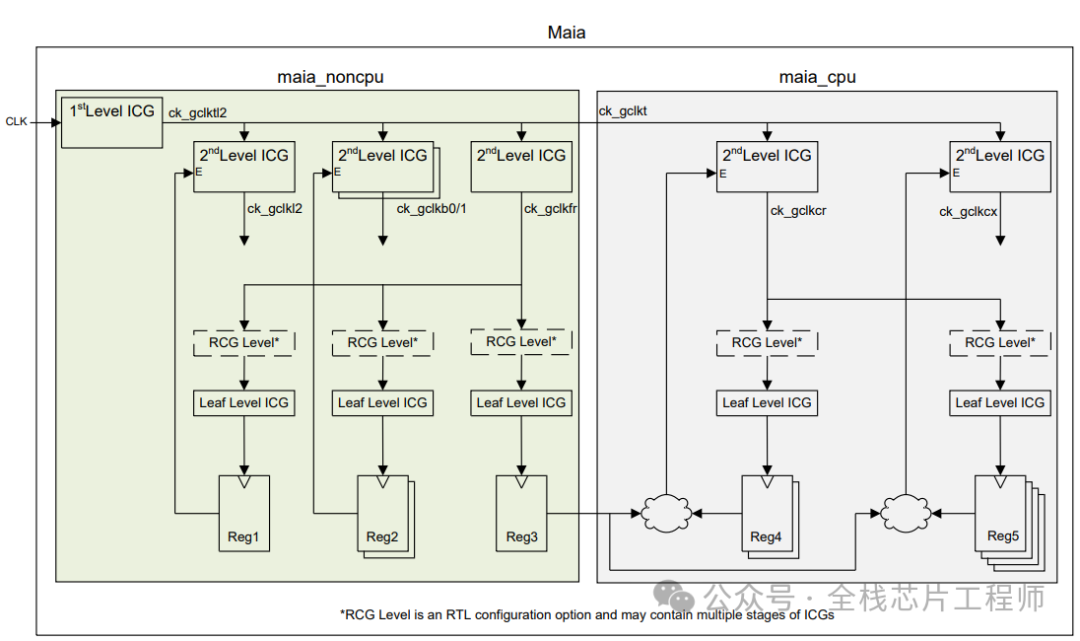
latency大小直接影响clock skew的计算。时钟树是以平衡为目的,假设对一个root和sink设置了400ps的latency值,那么对另外的sink而言,就算没有给定latency值,CTS为了得到较小的skew,也会将另外的sink做成400ps的latency。请问,为何要做短时钟树?因为过大的latency值会受到OCV和PVT等因素的影响较大,并有time derate的存在。
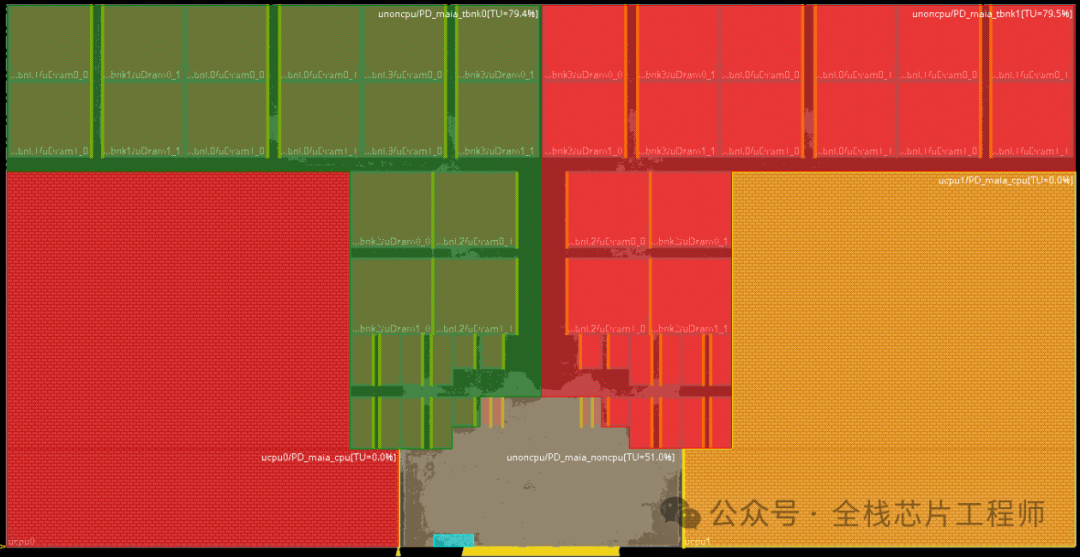
分享个例子,比如,Cortex-A72低功耗设计,DBG domain的isolation为何用VDDS_maia_noncpu供电而不是TOP的VDD?
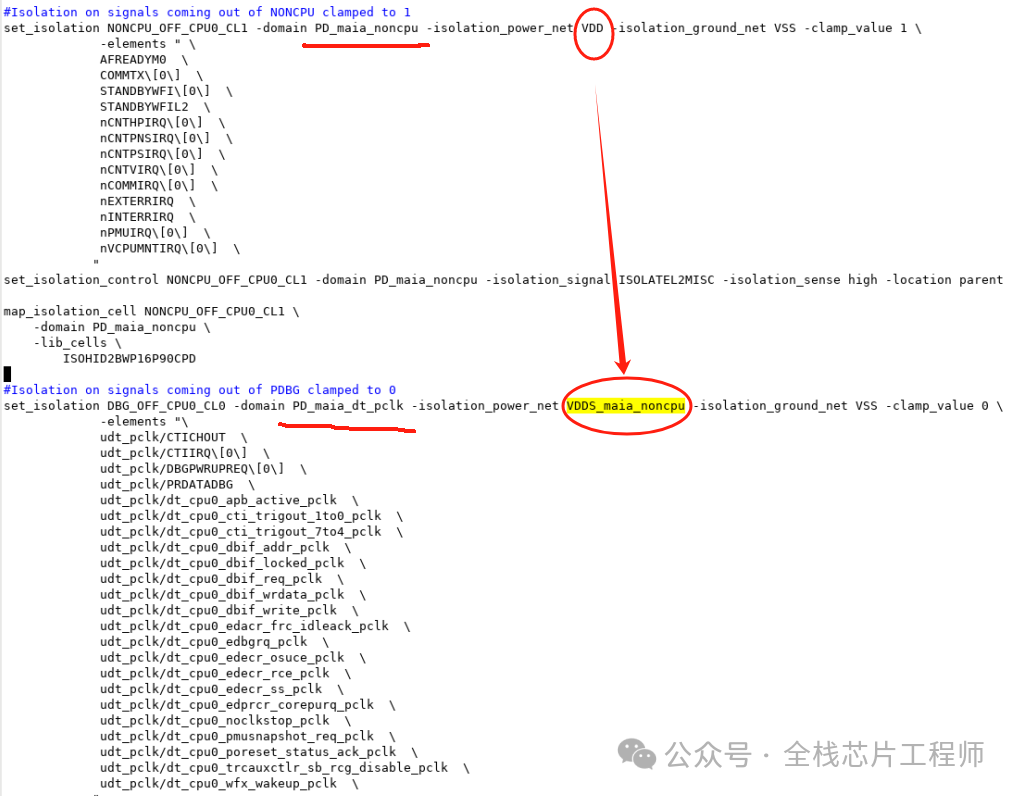
答:因为dbg的上一级是noncpu,noncpu下面分成dbg和两个tbnk。
再分享个例子,比如,Cortex-A72低功耗设计,这个switch cell是双开关吗?答:不是,之所以分trickle和hammer,是为了解决hash current大电流,先开trickle,然后再开hammer。

再分享个例子,比如,Cortex-A72课程的低功耗例子:请问,如果iso cell输出都要放parent,输入放self,那么下面-applies_to_outputs对应的-location为何是self?

答:这个需要了解CPU的内部设计架构,tbnk掉电 VDDS_maia_noncpu也必然掉电,pst如下,所以-applies_to_outputs对应的-location是可以的,那么注意下debug domain呢?

实际上,没有tbnk到debug domain的信号,因此脚本如下:

再分享个例子,比如,Cortex-A72课程的低功耗例子:为何non_cpu的SRAM的VDD VDDM都接的可关闭电源?SRAM的VDD VDDM分别是常开和retention电源吧?

答:本来是VDDM作为retention电源设计的,VDD关掉后 VDDM可以供电作为retention使用,但是此处没有去做memory的双电源,sram当成单电源使用,不然sram无法彻底断电。
再分享个例子,比如,Cortex-A72课程有学员的Cortex-A72 maia_cpu LVS通过, 但是MAIA顶层LVS比对不过,我们来定位一下。
以FE_OFN4326_cfgend_cpu1_o为例,点击下图FE_OFN4326_cfgend_cpu1_o:
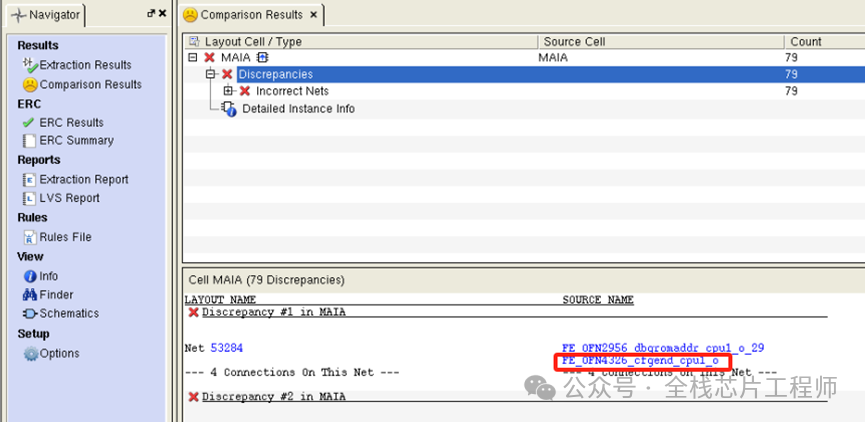
找到calibredrv错误坐标:(1949,139)
对应到innovus去看坐标:(1949,139)
看到maia_cpu的pin脚过于密集,造成顶层连接pin脚时候会无法绕线,从而导致innovus从maia_cpu上面走线,形成short。尽管maia_cpu带了blockage,但是invs没有足够的连接pin的routing resource,也就只能在maia_cpu上面去try了。
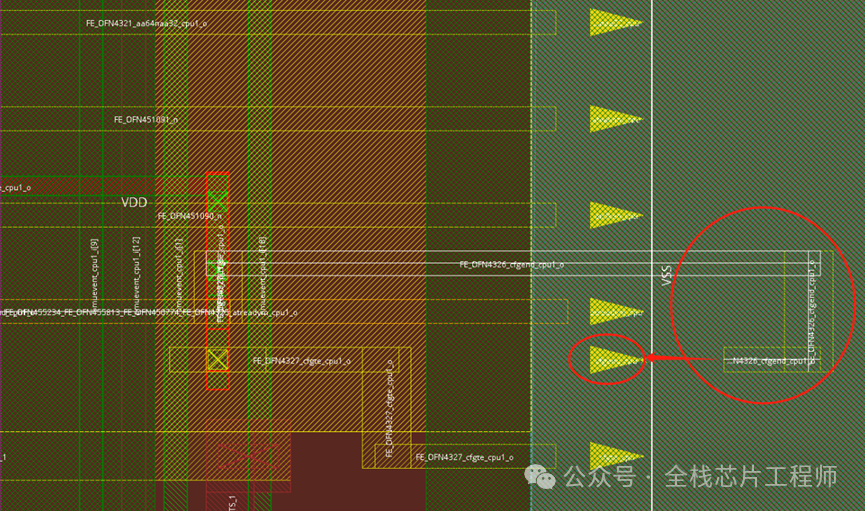
修改办法很简单,具体操作option参见知识星球。
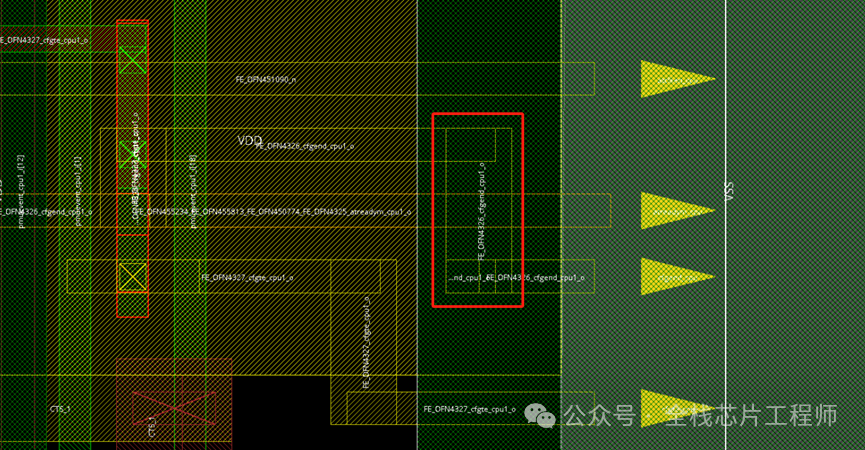
保存db,重新LVS,比对通过。

我们来对比下A72项目与A7项目的资源。A72 Gate数目是A7的13倍!如果都采用28nm制程,A72的面积应该是1180790um^2,实际A72采用12nm制程面积是486100um^2,1180790/486100=2.4,符合摩尔定律。
Cortex-A7单核:
Gates=240291 Cells=118421
Cortex-A72单核:
Gates=3125649 Cells=1207766
28nm Cortex-A7单核:
Area=90830.1 um^2
12nm Cortex-A72单核:
Area=486100.9 um^2
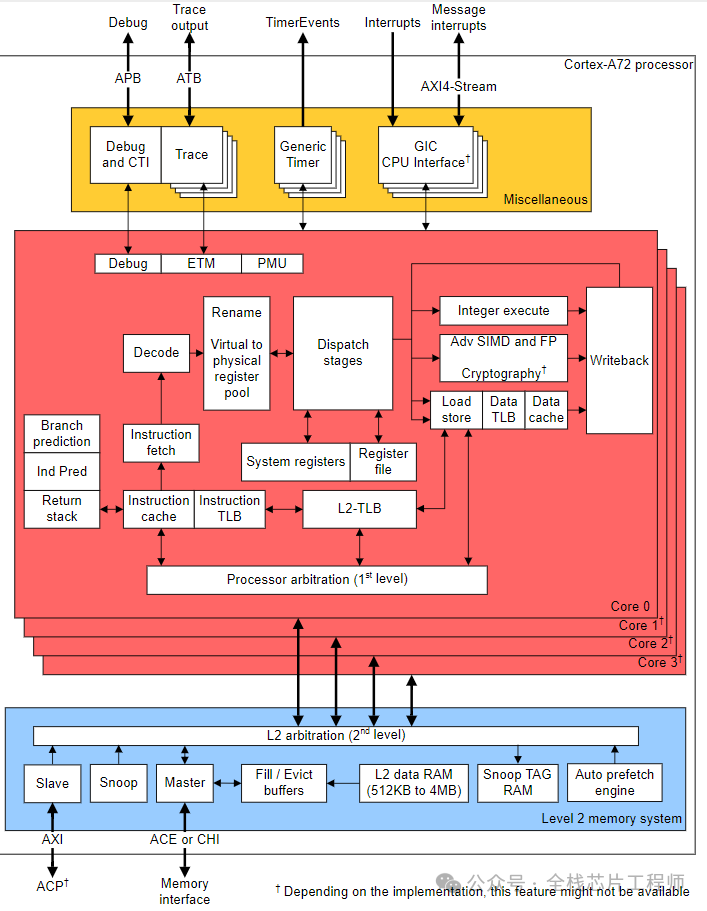
Cortex-A72处理器Partition Flow:
Cortex-A7处理器: