
- 1数据结构:插入排序和希尔排序
- 2GaussDB T 手动建库方法_gaussdb创建数据库
- 3大数据 DataX-Web 详细安装教程_datax web
- 4BroadcastReceiver(二)手动注册注销receiver_crtix receiver注销
- 5阿里云ECS上搭建Hadoop分布式环境(会更新)_云服务器ecs安装hadoop
- 6DB-GPT 初体验chat data
- 7vscode不支持旧版本os vscode无法提示_您即将连接到vs code不支持的系统版本
- 8拿到字节跳动offer后,简历被阿里捞了起来,二面竟迎来了P9的“盘问“_如果我是来字节面试的员工,通了2次面试了,第三次和你说不想来了,已经有阿里,
- 9CSDN博客&论坛——“我的2013”年度征文活动火爆进行中!【已结束】
- 10AList 网盘挂载,在线浏览各种网盘资源,部署并挂载到本地——教程(Linux+Windows)_alist挂载小雅网盘最新方法
你能讲出Spark sql和Hive sql两者间的区别吗?_sparksql和hive on spark性能对比
赞
踩
在大数据处理领域,Spark SQL 和 Hive SQL 都是非常流行的分布式 SQL 查询引擎。它们都能够在分布式环境中处理大量数据,提供快速、高效的数据分析和计算能力。然而,尽管它们都属于大数据处理工具,但它们之间仍然存在一些重要的区别。
在本文中,我们将详细比较 Spark SQL 和 Hive SQL 的区别,包括它们的执行引擎、性能、优缺点和应用场景。希望本文能够帮助您更好地理解 Spark SQL 和 Hive SQL 的区别。
区别
执行引擎
Spark SQL 使用 Spark 作为执行引擎。支持实时计算和机器学习。
相比之下,Hive 使用 MapReduce作为执行引擎。MapReduce 是 Hadoop 的原生计算模型,它能够在分布式环境中处理大量数据,但它的计算效率不如 Spark。
性能比较
Spark SQL 使用 Spark 作为执行引擎,能够在内存中快速处理大数据集,支持实时计算和机器学习。这使得 Spark SQL 在大规模数据处理时具有更高的处理速度。此外,Spark SQL 还支持多种格式的数据(如 CSV、JSON、Parquet 等),可以处理实时数据和离线数据。
相比之下,Hive SQL 使用 MapReduce 作为执行引擎。MapReduce 是 Hadoop 的原生计算模型,它能够在分布式环境中处理大量数据,但它的计算效率不如 Spark。
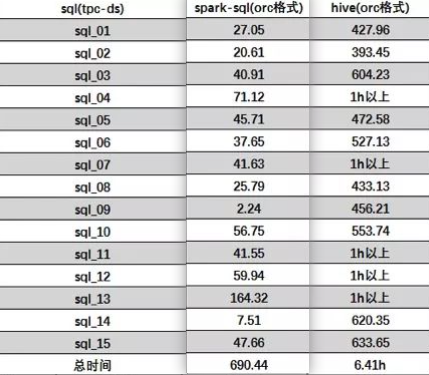
用相同的查询和数据量进行测试可以看到如下图
多表查询:
单表查询:
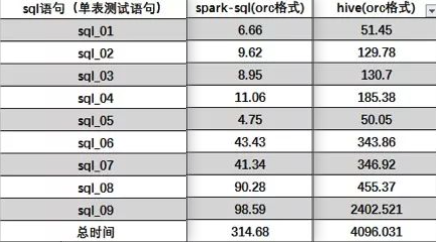
可以看到性能差距还是很大的。
优缺点
Spark SQL 和 Hive SQL 都是大数据处理的分布式 SQL 查询引擎,它们都能够在分布式环境中处理大量数据,但它们各自都有一些优缺点。
Spark SQL 的优点包括:
-
它使用 Spark 作为执行引擎,可以在内存中快速处理大数据集,支持实时计算和机器学习。
-
它支持多种格式的数据(如 CSV、JSON、Parquet 等),可以处理实时数据和离线数据。
-
它比 Hive SQL 更为强大和灵活,支持复杂的数据处理功能,例如机器学习、图像处理、流处理等,可以满足更多的数据分析和计算需求。
Spark SQL 的缺点包括:
-
它需要较多的内存来支持快速计算,这可能会增加硬件成本。
-
它对于小规模数据的处理可能不如传统的关系数据库高效。
Hive SQL 的优点包括:
-
它是基于 Hadoop 的数据仓库系统,用于处理大数据的存储和分析。
-
它支持 HiveQL 语言,是在 Hadoop 生态系统上的 SQL 分析工具。
-
它面向 OLAP(联机分析处理),即对大批量的数据进行分析和计算。
-
它可以将结构化的数据文件映射成一张表,并使用 SQL 进行查询和分析。
-
它通常用于数据分析、数据挖掘等场景。
-
它支持多种格式的数据(如 CSV、JSON、AVRO 等)。
Hive SQL 的缺点包括:
-
它使用 MapReduce 作为执行引擎,其计算效率不如 Spark。
-
它不支持实时计算和机器学习等高级功能。
应用场景
Spark SQL 更适用于大规模数据的复杂分析和计算。它可以在内存中快速处理大数据集,支持实时计算和机器学习。它通常用于机器学习、大数据分析、数据科学等场景。
Hive SQL 适用于大规模数据仓库的数据处理。它是基于 Hadoop 的数据仓库系统,用于处理大数据的存储和分析。它面向 OLAP(联机分析处理),即对大批量的数据进行分析和计算。它通常用于数据分析、数据挖掘等场景。
总结
首先,它们的执行引擎不同。Spark SQL 使用 Spark 作为执行引擎。而 Hive SQL 使用 MapReduce作为执行引擎。
其次,在性能方面,Spark SQL 在大规模数据处理时具有更高的处理速度,可以在内存中快速处理大数据集。但是 Hive SQL 也有其独特的优势,它更适用于大规模数据仓库的数据处理。
此外。Spark SQL 更适用于大规模数据的复杂分析和计算,而 Hive SQL 更适用于大规模数据仓库的数据处理。
如果采用5分为满分的话,简单打个分,如下图:

最后,在应用场景方面,Spark SQL 更适用于机器学习、大数据分析、数据科学等场景,而 Hive SQL 更适用于数据分析、数据挖掘等场景。

