
- 1Neo4j【环境部署 01】图形数据库(简介+下载地址+安装_neo4j-community-3.4.5
- 2[Java·算法·简单] LeetCode 14. 最长公共前缀 详细解读_java求公共前缀
- 3MySQL批量多条件的IN查询_mysql多条件批量查询
- 4【AI绘画发展史】AI绘画从历史到技术突破,何以突飞猛进?_人工智能绘画的发展
- 5AI绘画Stable Diffusion【真人模型】:美得令人心动亚洲女性大模型迎来SDXL版XXMix_9realisticSDXL_xxmix 大模型
- 6Python数据分析环境和工具
- 7二本4年测龄年仅25岁,五面阿里(定薪25K)....._阿里巴巴测试开发工程师工资
- 8对话杨元庆:AI PC,个人大模型最佳载体
- 9RabbitMQ在Ubuntu 16.04下的安装与配置_ubunto17.10 安装rabbitmq
- 10同样是程序员,本科学历凭什么就比专科学历更吃香?_本科学历从事开发比实施工程好吗
计算机_数据库_考研复试_简答题_全(2)_试述信息安全标准的发展历史,试述cc评估保证级划分的基本内容。
赞
踩
前言
题目
-
试述数据、数据库、数据库管理系统、数据库系统的概念。
(1)数据是数据库中存储的基本对象,是描述事物的符号记录。
(2)数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。
(3)数据库管理系统是位于用户与操作系统之间的一层数据管理软件
(4)数据库系统是指在计算机系统中引入数据库后的系统,一般由数据库、数据库管理系统、计算机硬软件、数据库管理员构成。 -
使用数据库系统有什么好处?
(1) 可以大大提高应用开发的效率
(2) 共享性高,冗余度低,独立性高,由DBMS统一管理 -
举出适合用文件系统而不是数据库系统的应用例子,以及适合用数据库系统的应用例子。
前者:数据备份,临时数据文件
后者:学生管理系统,图书管理系统 -
定义并解释概念模型中以下术语:实体,实体型,实体集,实体之间的联系。
(1)实体:客观存在并可以相互区分的事物。
(2)实体型:抽象、刻画同类实体。【学生是一个实体型】
(3)实体集:同型实体的集合。【全体学生是实体集】
(4)实体联系图(E-R图):提供了表示实体型、属性和联系的方法。 -
试述数据模型的概念、数据模型的作用和数据模型的三个要素。
概念:是对现实世界数据特征的抽象
作用:用来描述数据、组织数据和对数据进行操作
三要素:数据结构【静态特性的描述】、数据操作【动态特性的描述】、完整性约束【保证数据的正确、有效、相容】 -
试述层次模型的概念,举出三个层次模型的实例。【行政区域层次数据库模型】
层次模型:树形结构;
满足两个条件:只有一个根节点;除根节点外其他节点有且只有一个双亲结点 -
试述网状模型的概念,举出三个网状模型的实例【人和树】
①允许一个以上的结点无双亲;
②一个结点可以有多于一个的双亲。 -
试述网状、层次数据库的优缺点。
层次:
优点
①模型简单,直观,容易理解。
②用层次模型的应用系统性能好
缺点
①现实世界中很多联系是非层次性的
②查询子女结点必须通过双亲结点。
网状:
优点
①能够更为直接地描述现实世界
②具有良好的性能,存取效率较高。
缺点
①结构比较复杂 ②DDL、DML语言复杂,用户不容易使用。 -
试述关系模型的概念,定义并解释以下术语:关系,属性,域,元组,码,分量,关系模式
①关系:一个关系对应通常所说的一张表。
②属性:表中的一列即为一个属性。
③域:属性的取值范围。
④元组:表中的一行即为一个元组。
⑤主码:它可以惟一确定一个元组。
⑥分量:元组中的一个属性值。
⑦关系模式:对关系的描述,一般表示为关系名(属性1,属性2,…,属性n)。 -
试述关系数据库的特点。
关系模型的概念单一,无论实体还是实体之间的联系都用关系来表示
关系模型的存取路径对用户透明,有更高的数据独立性、更好的安全保密性 -
试述数据库管理员、系统分析员、数据库设计人员、应用程序员的职责。
(1)系统分析员:系统分析员负责应用系统的需求分析和规范说明,要和用户及DBA相结合,确定系统的硬件软件配置,并参与数据库系统的概要设计。
(2)数据库设计人员:数据库设计人员负责数据库中数据的确定、数据库各级模式的设计。
(3)应用程序员:应用程序员负责设计和编写应用系统的程序模块,并进行调试和安装。 -
简述关系数据语言的特点和分类。
(1)共同特点是:都是非过程化的集合操作语言,能够嵌入高级语言中使用。
(2)关系数据语言分为三类:
①关系代数语言
②关系演算语言
③SQL。具有丰富的查询功能 -
解释术语
①候选码:唯一标识的属性【在关系中能唯一标识元组的最小属性集】
②主码:选择一个唯一标识的属性
③外部码:老师编号在教师表中是主键,在学生表中它就是外键。
④笛卡儿积:两个分别为n目和m目的关系R和S的笛卡尔积是一个n+m列的元组的集合。 -
8关系代数的基本运算有哪些?如何用这些基本运算来表示其他运算?
关系代数的基本运算包括并、差、笛卡尔积、投影和选择5种运算。
其他3种运算,即交、连接和除,均可以用这5种基本运算来表达。
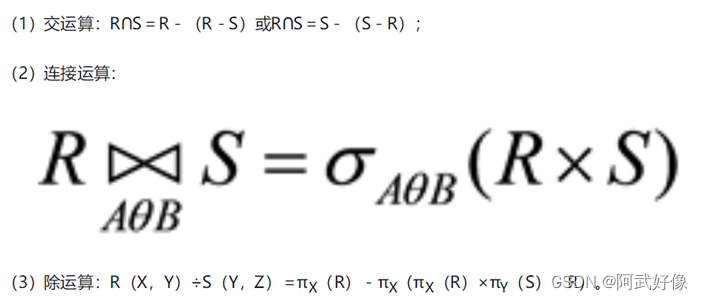
-
说明在DROP TABLE时,RESTRICT和CASCADE的区别。
若选择RESTRICT,则该表的删除是有限制条件的【默认】
若选择CASCADE,则该表的删除没有限制条件。 -
什么是基本表?什么是视图?两者的区别和联系是什么?
(1)基本表是本身独立存在的表,在SQL中一个关系就对应一个表。
(2)视图是从一个或几个基本表导出的表。它本身不独立存储在数据库中,即数据库中只存放视图的定义而不存放视图对应的数据。这些数据仍存放在导出视图的基本表中,因此视图是一个虚表。
(3)基本表与视图的区别和联系:
①区别:视图本身不独立存储在数据库中,是一个虚表。即数据库中只存放视图的定义而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中。
②联系:视图在概念上与基本表等同,用户可以如同基本表那样使用视图,可以在视图上再定义视图。
所以基本表中的数据发生变化,从视图中查询出的数据也就随之发生改变。 -
哪类视图是可以更新的?哪类视图是不可更新的?
(1)基本表的行列子集视图一般是可更新的
(2)若视图的属性来自集函数、表达式,则该视图是不可以更新的 -
举例说明对数据库安全性产生威胁的因素。
滥用过高权限:超过被授予的权限,然后进行恶意操作
滥用合法权限:利用职务之便,利用合法但进行恶意的操作
权限提升:坏人利用漏洞把自己设置成管理员 -
试述信息安全标准的发展历史,试述CC评估保证级划分的基本内容。
(1)信息安全标准的发展历史如下:
①TCSEC是指1985年美国国防部正式颁布的《可信计算机系统评估准则》(简称TCSEC)。在TCSEC推出后的十年里,不同国家都开始开发建立在TCSEC概念上的评估准则,如欧洲的信息技术安全评估准则(ITSEC)、加拿大的可信计算机产品评估准则(CTCPEC)、美国的信息技术安全联邦标准(FC)草案等。
②CTCPEC、FC、TCSEC和ITSEC的发起组织于l993年起开始联合行动,这一行动被称为CC项目。CC V2.1版于1999年被ISO采用为国际标准,2001年被我国采用为国家标准。
③1991年4月美国NCSC颁布了《可信计算机系统评估准则关于可信数据库系统的解释》(简称TDI),将TCSEC扩展到数据库管理系统。
④TDI/TCSEC将系统划分为四组七个等级,依次是D、C(C1,C2)、B(B1,B2,B3)、A(A1),按系统可靠或可信程度逐渐增高。
⑤CC提出了目前国际上公认的表述信息技术安全性的结构,即把对信息产品的安全要求分为安全功能要求和安全保证要求。
(2)评估保证级是在CC第三部分中预先定义的由保证组件组成的保证包,每一保证包描述了一组特定的保证要求,对应着一种评估保证级别。从EAL1至EAL7共分为七级,按保证程度逐渐增高 -
解释强制存取控制机制中主体、客体、敏感度标记的含义。
(1)主体是系统中的活动实体,既包括DBMS所管理的实际用户,也包括代表用户的各进程。
(2)客体是系统中的被动实体,受主体操纵,包括文件、基表、索引、视图等。
对于主体和客体,DBMS为它们每个实例(值)指派一个敏感度标记(Label)。
(3)敏感度标记被分成若干级别,例如绝密、机密、可信、公开等。主体的敏感度标记称为许可证级别,客体的敏感度标记称为密级。 -
举例说明强制存取控制机制是如何确定主体能否存取客体的。
假设用户U1和U2的许可证级别分别为3和2,
则根据规则[假设的]U1能查得元组S1和S2,可修改元组S2;
而U2只能查得元组S1,只能修改元组S1。 -
数据库的完整性概念与数据库的安全性概念有什么区别和联系?
数据的完整性和安全性是两个不同的概念,但是有一定的联系。
数据的完整性是为了防止数据库中存在不符合语义的数据,也就是防止数据库中存在不正确的数据。数据的安全性是保护数据库防止恶意的破坏和非法的存取。
完整性检查和控制的防范对象是不合语义的、不正确的数据,防止它们进入数据库。
安全性控制的防范对象是非法用户和非法操作,防止他们对数据库数据的非法存取。 -
什么是数据库的完整性约束条件?
完整性约束条件是指数据库中的数据应该满足的语义约束条件。
完整性约束条件分为六类:静态列级约束、静态元组约束、静态关系约束、动态列级约束、动态元组约束、动态关系约束。
(1)静态列级约束是对一个列的取值域的说明
(2)静态元组约束就是规定组成一个元组的各个列之间的约束关系
(3)静态关系约束是在一个关系的各个元组之间或者若干关系之间常常存在各种联系或约束,常见的静态关系约束有:实体完整性约束,参照完整性约束,函数依赖约束。
(4)动态列级约束是修改列定义或列值时应满足的约束条件,包括下面两方面:修改列定义时的约束,修改列值时的约束。
(5)动态元组约束是指修改某个元组的值时需要参照其旧值,并且新旧值之间需要满足某种约束条件。
(6)动态关系约束是加在关系变化前后状态上的限制条件,例如事务一致性、原子性等约束条件。 -
关系数据库管理系统的完整性控制机制应具有哪三方面的功能?
(1)提供定义完整性约束条件的机制。包括关系模型的实体完整性、参照完整性和用户定义完整性。
(2)提供完整性检查的方法。
(3)违约处理。DBMS若发现用户的操作违背了完整性约束条件,就采取一定的动作,如拒绝(NO ACTION)执行该操作,或级连(CASCADE)执行其他操作,进行违约处理以保证数据的完整性。 -
关系数据库管理系统在实现参照完整性时需要考虑哪些方面?
(1)外码是否可以接受空值。
(2)删除被参照关系元组时的问题,系统可能采取的作法有三种:级联删除、受限删除和置空值删除。
(3)在参照关系中插入元组时的问题,系统可能采取的做法有:受限插入和递归插入。
(4)修改关系中主码的问题。如果需要修改主码值,只能先删除该元组,然后再把具有新主码值的元组插入到关系中。如果允许修改主码,首先要保证主码的惟一性和非空,否则拒绝修改,然后要区分是参照关系还是被参照关系 -
在关系系统中,当操作违反实体完整性、参照完整性和用户定义的完整性约束条件时,一般是如何分别进行处理的?
(1)当违反实体完整性约束条件时,一般采用的方式是拒绝执行,比如拒绝插入或拒绝修改等。
(2)当违反参照完整性约束条件时,并不都是简单地拒绝执行,有时要根据应用语义执行一些附加的操作,以保证数据库的正确性。比如拒绝执行,级连操作,设置为空值等。
(3)当违反用户定义的完整性约束条件时,一般采用的方式是拒绝执行。 -
理解并给出术语的定义
(1)函数依赖:
(2)部分函数依赖:
(3)完全函数依赖:
(4)传递依赖:
(5)候选码:
(6)全码:
(7)多值依赖:
(8)4NF: -
举例多值依赖的实例
(1)关系模式ISA(I,S,A)中,I表示学生兴趣小组,S表示学生,A表示某兴趣小组的活动项目。假设每个兴趣小组有多个学生,有若干活动项目。每个学生必须参加所在兴趣小组的所有活动项目,每个活动项目要求该兴趣小组的所有学生参加。
按照语义有I→→S,I→→A成立。
(2)上课(学号,教师工号,教室),一个学生可由多个教师来教,一个学生可在多教室上课,而且一个教师可在多个教室上课,一个教室可由多个教师上课。
所以存在如下多值依赖:学号→→教师工号和学号→→教室。 -
试述数据库设计过程中形成的数据库模式。
(1)在概念设计阶段形成独立于机器特点,独立于各个DBMS产品的概念模式,在本篇中就是E-R图;(2)在逻辑设计阶段将E-R图转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式,然后在基本表的基础上再建立必要的视图,形成数据的外模式;
(3)在物理设计阶段,根据DBMS特点和处理的需要,进行物理存储安排,建立索引,形成数据库内模式。 -
数据字典的内容和作用是什么?
(1)数据字典是系统中各类数据描述的集合。
数据字典的内容通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分。
(2)数据字典的作用:数据字典是关于数据库中数据的描述,在需求分析阶段建立,是下一步进行概念设计的基础,并在数据库设计过程中不断修改、充实、完善。 -
什么是数据库的概念结构?试述其特点和设计策略。
(1)概念模型用于信息世界的建模,是现实世界到信息世界的第一层抽象,是数据库设计人员进行数据库设计的有力工具
(2)其主要特点是:
①能真实、充分地反映现实世界
②用户易于理解
③易于更改
④易于向关系、网状、层次等各种数据模型转换。
(3)概念结构的设计策略通常有四种:
①自顶向下,即首先定义全局概念结构的框架,然后逐步细化;
②自底向上,即首先定义各局部应用的概念结构,然后将它们集成起来,得到全局概念结构;
③逐步扩张,首先定义最重要的核心概念结构,然后向外扩充,以滚雪球的方式逐步生成其他概念结构,直至总体概念结构;
④混合策略,即将自顶向下和自底向上相结合,用自顶向下策略设计一个全局概念结构的框架,以它为骨架集成由自底向上策略中设计的各局部概念结构。 -
什么是数据库的逻辑结构设计?试述其设计步骤。
(1)E-R图转换为与选用的DBMS产品所支持的数据模型相符合的逻辑结构。
(2)数据库的逻辑结构设计步骤为:
①将概念结构转换为一般的关系、网状、层次模型;
②将转换来的关系、网状、层次模型向特定DBMS支持下的数据模型转换;
③对数据模型进行优化。 -
试述数据库物理设计的内容和步骤。
数据库在物理设备上的存储结构与存取方法称为数据库的物理结构
数据库物理设计的主要内容是选取一个最适合的物理结构
数据库的物理设计步骤通常分为两步:
(1)确定数据库的物理结构,在关系数据库中主要指存取方法和存储结构;
(2)对物理结构进行评价,评价的重点是时间效率和空间效率。 -
规范化理论对数据库设计有什么指导意义?
规范化理论为数据库设计人员判断关系模式的优劣提供了理论标准,
可用以指导关系数据模型的优化,
用来预测模式可能出现的问题,
为设计人员提供了自动产生各种模式的算法工具,使数据库设计工作有了严格的理论基础。 -
数据输入在实施阶段的重要性是什么?如何保证输入数据的正确性?
(1)实施阶段必须将原有系统中的历史数据输入到数据库。
(2)保证输入数据正确性的方法:为提高数据输入工作的效率和质量
设计一个数据录入子系统,由计算机来完成数据入库的任务。
在源数据入库之前要采用多种方法对其进行检验,以防止不正确的数据入库 -
什么是数据库的再组织和重构造?为什么要进行数据库的再组织和重构造?
(1)数据库的再组织是指按原设计要求重新安排存储位置,以提高系统性能。
数据库的重构造则是指部分修改数据库的模式和内模式
【数据库的再组织是不修改数据库的模式和内模式的】
(2)数据库运行一段时间后,数据库性能下降,这时DBA就要对数据库进行重组织。
原有的数据库设计不能满足新的需求,需要调整数据库的模式和内模式,这就要进行数据库重构造。 -
试述查询优化在关系数据库系统中的重要性和可能性。
(1)它减轻了用户选择存取路径的负担。用户只要提出“干什么”,不必考虑如何最好地表达查询以获取较好的效率,而且系统可以比用户程序的“优化”做得更好。
(2)查询优化在关系数据库系统中的可能性:
①优化器可以从数据字典中获取许多统计信息,例如关系中的元组数、关系中每个属性的分布情况、这些属性上是否有索引(B+树索引、HASH索引、唯一索引或组合索引)等。优化器可以根据这些信息选择有效的执行计划,而用户程序则难以获得这些信息。
②如果数据库的物理统计信息改变了,系统可以自动对查询进行重新优化以选择相适应的执行计划。在非关系系统中必须重写程序,而重写程序在实际应用中往往是不太可能的。
③优化器可以考虑数十甚至数百种不同的执行计划,从中选出较优的一个,而程序员一般只能考虑有限的几种可能性。
④优化器中包括了很多复杂的技术,这些优化技术往往只有最好的程序员才能掌握。系统的自动优化相当于使得所有人都拥有这些优化技术。 -
试述关系数据库管理系统查询优化的一般准则。
(1)选择运算应尽可能先做。
(2)投影运算和选择运算同时进行。
(3)投影同其前或其后的双目运算结合起来。
(4)某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算。
(5)找出公共子表达式。
(6)选取合适的连接算法。 -
试述关系数据库管理系统查询优化的一般步骤。
(1)把查询转换成某种内部表示,通常用的内部表示是语法树。
(2)把语法树转换成标准(优化)形式,即利用优化算法,把原始的语法树转换成优化的形式。
(3)选择低层的存取路径。
(4)生成查询计划,选择代价最小的。 -
什么是检查点记录?检查点记录包括哪些内容?
(1)检查点记录是一类新的日志记录。
(2)检查点记录的内容包括:
①建立检查点时刻所有正在执行的事务清单;
②这些事务的最近一个日志记录的地址。 -
具有检查点的恢复技术有什么优点?试举一个具体例子加以说明。
(1)在采用检查点技术之前,利用日志技术进行数据库的恢复时需要从头扫描日志文件,而利用检查点技术只需要从检查点所处时间点起开始扫描日志,这就缩短了扫描日志的时间,改善恢复效率。(2)例如当事务T在一个检查点之前提交,T对数据库所做的修改已经写入数据库,那么在进行恢复处理时,没有必要对事务T执行REDO操作。 -
试述使用检查点方法进行恢复的步骤。
(1)从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录。
(2)由该检查点记录得到检查点建立时刻所有正在执行的事务清单ACTIVE-LIST。这里需要建立以下两个事务队列:UNDO-LIST队列,REDO队列
把ACTIVE-LIST暂时放入UNDO-LIST队列,REDO队列暂时为空。
(3)从检查点开始正向扫描日志文件
①如果有新开始的事务,则将其暂时放入UNDO-LIST队列。
②如果有已提交的事务,则将其从UNDO-LIST队列移至REDO-LIST队列,直到日志文件结束。
(3) 对UNDO-LIST中的每个事务执行UNDO操作,对REDO-LIST中的每个事务执行REDO操作。 -
什么是数据库镜像?它有什么用途?
(1)数据库镜像即根据DBA的要求,自动把整个数据库或者其中的部分关键数据复制到另一个磁盘上。每当主数据库更新时,DBMS自动把更新后的数据复制过去,即DBMS自动保证镜像数据与主数据的一致性。
(2)数据库镜像的用途有两点:
①用于数据库恢复
②提高数据库的可用性,在没有出现故障时,当一个用户对某个数据加排它锁进行修改时,其他用户可以读镜像数据库上的数据,而不必等待该用户释放排它锁。 -
什么是封锁?
封锁是指事务T在对某个数据对象(例如表、记录等)进行操作之前,先向系统发出请求,对其加锁。加锁后,事务T就对该数据对象有控制权,在事务T释放锁之前,其他事务不能更新此数据对象。 -
如何用封锁机制保证数据的一致性?
DBMS在对数据进行读、写操作之前首先对该数据执行封锁操作
DBMS按照一定的封锁协议,对并发操作进行控制,使得多个并发操作有序地执行,避免了丢失修改、不可重复读和读“脏”数据等数据不一致性。 -
什么是活锁?试述活锁的产生原因和解决方法。
(1)如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁之后系统首先批准了T3的请求,T2仍然等待。然后T4请求封锁R,当T3释放了R上的封锁之后系统批准了T4的请求……T2有可能永远等待,这就是活锁
(2)活锁产生的原因:当一系列封锁不能按照其先后顺序执行时,可能导致一些事务无限期地等待某个封锁,从而导致活锁。
(3)避免活锁的解决方法是采用先来先服务的策略。 -
什么是死锁?请给出预防死锁的若干方法。
(1)如果事务T1封锁了数据R1,T2封锁了数据R2,T1又请求封锁R2,因T2已封锁了R2,于是T1等待T2释放R2上的锁。T2又申请封锁R1,因T1已封锁了R1,T2也只能等待T1释放R1上的锁。这样就出现了T1在等待T2,而T2又在等待T1的局面,T1和T2两个事务永远不能结束,形成死锁。(2)防止死锁发生其实是要破坏产生死锁的条件。
①一次封锁法要求每个事务必须一次将所用的所有数据全部加锁,否则就不能执行。
②顺序封锁法预先对数据对象规定一个封锁顺序,所有事务都按照这个顺序实行封锁。但是,预防死锁的策略不大适合数据库系统的特点。 -
请给出检测死锁发生的一种方法,当发生死锁后如何解除死锁?
①超时法是如果一个事务的等待时间超过了规定的时限,就认为发生了死锁。超时法实现简单,但有可能误判死锁,事务因其他原因长时间等待超过时限时,系统会误认为发生了死锁。若时限设置得太长,又不能及时发现死锁。
②事务等待图动态地反映了所有事务的等待情况。并发控制子系统周期性地生成事务等待图,并进行检测。如果发现图中存在回路,则表示系统中出现了死锁。
(2)DBMS并发控制子系统检测到死锁后,就要设法解除。通常采用的方法是选择一个处理死锁代价最小的事务,将其撤消,释放此事务持有的所有锁,使其他事务得以继续运行。对撤销的事务所执行的数据修改操作必须加以恢复。 -
什么样的并发调度是正确的调度?
可串行化的调度是正确的调度。
可串行化的调度是指多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行执行它们时的结果相同的调度策略 -
为什么要引进意向锁?意向锁的含义是什么?
(1)引进意向锁是为了提高封锁子系统的效率,封锁子系统支持多种封锁粒度。原因是在多粒度封锁方法中一个数据对象可能以两种方式加锁——显式封锁和隐式封锁。因此系统在对某一数据对象加锁时不仅要检查该数据对象上有无(显式和隐式)封锁与之冲突,还要检查其所有上级结点和所有下级结点,看申请的封锁是否与这些结点上的(显式和隐式)封锁冲突,这样的检查方法效率很低,为此引进了意向锁。
(2)意向锁的含义是:对任一结点加锁时,必须先对它的上层结点加意向锁。
引进意向锁后,系统对某一数据对象加锁时,不必逐个检查与下一级结点的封锁冲突。 -
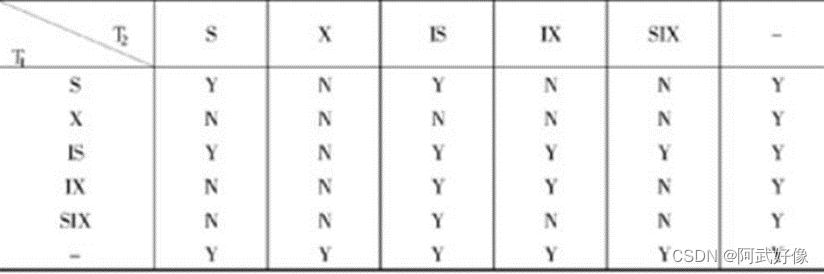
试述常用的意向锁:IS锁、IX锁、SIX锁,给出这些锁的相容矩阵。
(1)如果对一个数据对象加IS锁,表示它的后裔结点拟加S锁。
例如,要对某个元组加S锁,则要首先对关系和数据库加IS锁。
(2)如果对一个数据对象加IX锁,表示它的后裔结点拟加X锁。
例如,要对某个元组加X锁,则要首先对关系和数据库加IX锁。
(3)如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX=S+IX。
并发控制可以保证事务的一致性和隔离性,保证数据库的一致性。
恢复技术保证了事务的原子性、一致性和持续性。
总结
来源在第一篇上已贴链接

