
- 1影院CMS源码。全自动采集,影视源码-上传即可使用_影视cms采集
- 2好书推荐 《Node-RED物联网应用开发技术详解》_node-red 软件著作权
- 3HBase数据结构_hbase的数据结构
- 4centos7 通过端口转发实现代理中转_端口 中转
- 5K8S集群搭建教程
- 6项目模版汇总_项目排期 语雀
- 7google浏览器安装vuejs-devtools插件2024年安装记录_google has flagged vue_devtools插件安装
- 8高级python程序设计,给大家推荐几本最优秀的编程书,阿里P7亲自讲解_python高级编程书籍
- 9git常用回滚命令_git 回滚提交是什么意思
- 10Vivado_IDE(1)熟悉环境_vivado recent projects
对大模型和AI的认识与思考_人工智能大模型相关思考
赞
踩
自从OpenAI在2022年11月30日发布了引领新一轮AI革命浪潮的产品ChatGPT以来,大模型和生成式AI这把大火在2023年越烧越旺,各种技术和应用层出不穷;而2023年11月,同样是OpenAI CEO山姆·奥特曼(Sam Altman)被开除后有回归,这100小时的宫斗赚足了媒体和世界网名的关注,引出了大家对AI安全的遐想和担忧。
以OpenAI开始,以OpenAI收尾,至此已经一年有余了。这一年AI做出了令人瞩目的成绩,确似乎才刚刚开始。我、我的朋友、我的同事以及网络上的网友,都切实可行的从AI技术上获得了效率和便捷性大幅度提升的好处。
做为一名技术人,在2023年,笔者也参与了各种学习和实践,从大语言模型、多模态算法,文生图(Stable Diffusion)技术,到prompt工程实践和搭建文生图(Stable Diffusion)webui实操环境。在此对谈谈对大模型和AI的认识与思考,是为总结。
2. 生成式AI元年
2023无疑是生成式AI的元年,英伟达的CEO黄仁勋曾说过:人工智能已经到了iPhone时刻;或许离真正的AGI还有一定的距离,但AI确实展现出人类基本常识和推理的能力,特别是模型越来越大的加持虾出现的涌现能力。就在最近Google发布最新人工智能模型Gemini,声称性能超越GPT-4和人类专家,从宣传视频上看,Gemini已经具备人类的视觉(图像识别),听觉(语音识别)和自然语言理解的基本技能。
我们一起来回顾下生成式AI的发展。
2.1 GPT的发展
如果说大语言模型存在一个分水岭的话,我觉得是2017年Google提出了一种全新的模型Transformer,Transformer是典型的encoder-decoder结构,最早是用来做机器翻译的。Transformer中最重要的结构是Multi-Head的Self-Attention机制。在Transformer之前,自然语言处理(NLP)一般采用循环神经网络RNN,以及变种如双向的RNN、LSTM和GRU等,但都存在一定的问题,如长文本序列上下文遗忘,难以并行等,而Transformer较好的解决了这些问题。

Transformer推出之后,被循序了应用到自然语言处理的各个领域,同样也在机器视觉领域和传统的CNN一较高下,并拔得头筹。Transformer的火爆可见一斑,值得一提的当前Transformer的几个作者都开始加入大模型创业浪潮,虏获资本的厉害,如Adept、Essential AI、Cohere。
说回到Transformer的生态树,Transformer之后,出现了三个较大的分支:
-
一个是以BERT为代表的以decoder-only的模型,还有百度的ERNIE
-
另一个是以GPT为代表的encoder模型,还有谷歌的Bard,claude,cohere,百度的ERNIE 3.0(当前的文心一言)
-
第三个分支则是encoder+decoder的模型(就是整个Transformer),这里有清华系的GLM和chatGLM,还有谷歌的T5,Meta的LLAMa

BERT以完形填空的方式开启的大语言的预训练模型之路,一个pre-trained Model可以快速的迁移后下游的任务。而GPT走的是另外一条更艰难的道路,生成式模型,预测下一个词,一开始GPT1性能不如BERT,于是GPT开始了大,更大,最大的模式,从GPT1的1.17亿参数量到GPT3的1750亿参数量,开始了大力出奇迹的真正大模型之路。

在GPT3中,使得提示(Prompt)的重要性越来越被重视,逐步变成当前的Prompt Engineering。Prompt engineering是创建提示或询问或指导像ChatGPT这样的语言模型的输出的指令。它允许用户控制模型的输出并生成文本根据他们的具体需求量身定制。如何有效清晰明确的表达你的意愿,对于使用大模型是至关重要的。

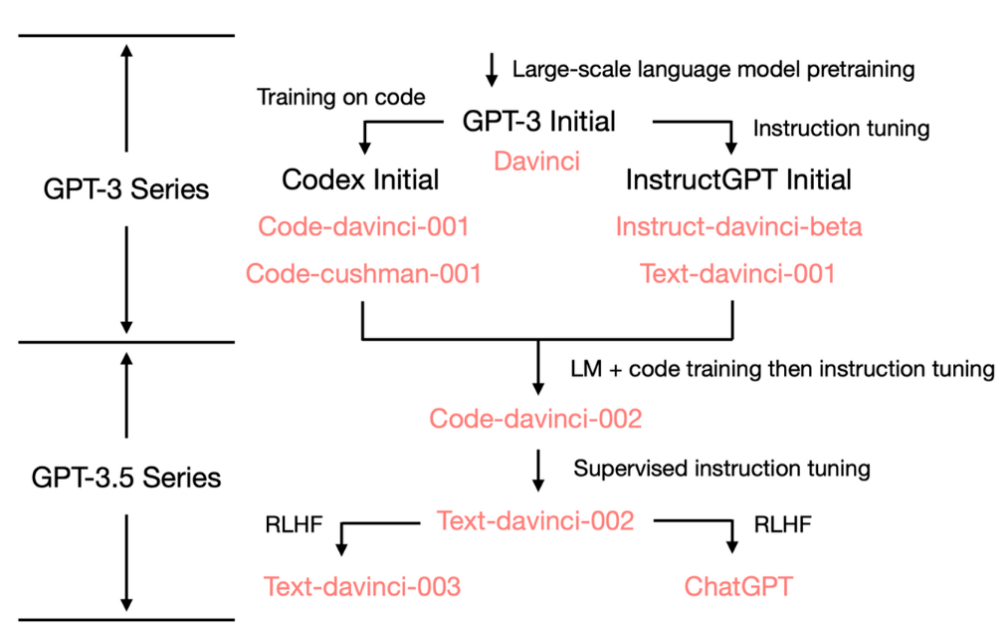
在GPT3之后,OpenAI做了不同的调优,如针对代码的Codex,特别是InstructGPT引入了强化学习的机制来使得大语言模型的生成结果和人类进行对齐,而ChatGPT是在此基础上加入了有监督的学习指导,可以说是更强的对齐(OpenAI最近成立SuperAlign超级对齐部门专门解决AI和人类的对齐问题)。至此ChatGPT问世,GPT4则加入多模态使得GPT可以有处理图像的能力。
2.2 开源GPT
我们知道,OpenAI在GPT3之后就采用封闭的方式不公开代码和模型,只提供API来供使用。谷歌的Bard和PaLM也是封闭的。国外大厂里只有Meta提供了大模型的开源,如OPT、BLOOM、LLaMa。
开源社区也针对公开的模型,训练更小的模型,并希望和GPT性能对齐。比较早期的有斯坦福大学的Alpaca(羊驼),清华系的ChatGLM-6B,复旦MOSS,Vicuna-13B 和mini-GPT4。
当然后续国内外也有公司开源了较小的模型,如百川2-13B,通义千问-72B(Qwen-72B)等,这些模型都可以在modelscope上下载获得。
感谢开源!
2.3 国内的GPT们
在ChatGPT爆红之后,国内的大厂们也开启GPT模式,进入百模大战模式。百度的文心一言先开始拉开序幕,还有阿里云的通义千问,华为盘古,商汤日日新,360的360智脑,京东的言犀大模型,腾讯的HunYuan大模型,科大讯飞的讯飞星火,还有chatGLM的智谱清言。
大家都在追赶GPT,目前看百度的文心一言4.0是比较接近ChatGPT,当然如何有效的评测大模型的性能也是一门学问,可以参考Holistic Evaluation of Language Models。
2.4 文生图赛道
今年除了ChatGPT这个语言生成模型比较火之外,另一个比较火的生成式AI就是Text-to-Image文生图。就是通过文字描述来生成一个和文字描述相关的图片。
Text-to-Image的代表应用是Midjourney,还有OpenAI的DALE-2和DALE-3,以及开源的Stable diffusion。

文生图可以通过文字描述来生成逼真的图画,这让许多没有绘画基础的人们带来了福音,只要你有想象力就可以。同时,文生图还开始席卷了需要图片的行业,比如游戏原画设计,logo设计,电商模特,海报设计,视频剪辑等等。
AI生成图片可以追溯到VAE,GAN,而当前最流行都是Diffusion扩散模型,这些事图生图的范式。
而文生图,就是在图生图之前加入文本的encoder,并加入图生图的过程,来影响图片的生成,借用李宏毅老师的一个框架,著名的DALE-2和Stable diffusion以及谷歌的Imagen都是套用此方法。

3. 大模型和AI应用和思考
如果说以大模型为代表的AI模型是人工智能的iphone时刻的话,那么iphone的APP有哪些?这或许是作为开发者的一个新的机会,在最近的OpenAI开发者大会上,OpenAI发布了GPTs和GPT store,通过GPTs人们可以构建自己的应用,而GPT store是针对垂直领域的大模型微调版本。另外一种形象的说法是大模型是底座操作系统,而运行上在这平台上的软件和app才刚刚开始,是为机会。毕竟大模型的训练是需要很大成本的,而开发一个APP是有可能的。
那我们如何利用这个大模型呢?
3.1 效率提升,解决业务痛点
通过分析下当前业务中的痛点和效率低下的环节,评估下是否接入成熟AI工具如ChatGPT或者文生图,当然也要考虑成本因素。这是当前比较主流的应用方式。比如游戏设计中的原画设计,可以接入Midjourney来做初稿和创意设计,来大大加快效率;视频或者文字内容创造者,可以用ChatGPT来文案设计,用Midjourney来插画或者视频素材;培训工作者如教师可以用ChatGPT来做备课工具,提升效率。
这个阶段注重和自身业务的契合点,直接使用工具解决问题。
3.2 提升易用性,做垂直应用
当前大模型的一个重要的环节是prompt(提示),不同的prompt可以有截然不同的结果,这个也是当前大模型使用的一个门槛。如何提升工具的易用性,是一个值得关注的方向。
-
prompt分享平台:分享不同的prompt展示平台,甚至拿prompt做为产品来销售,以及prompt培训
-
能不能只写简单的prompt就能有很好的结果,比较典型的就是做垂直领域的应用,总结垂直领域特别的prompt作为潜在的prompt添加到使用者的prompt之后进行简化使用
-
垂直领域应用:用产品思维的方式,分析垂直领域的特点,综合大模型和其他领域知识,打造更加智能化的垂直应用
这个阶段注重易用性的提升, 封装工具成特定领域的工具解决问题。
3.3 AI Agents
AI Agents无疑是未来新的发展方向,AI Agents在大模型的基础上,结合其工具和知识来扩展大模型的能力,使得大模型能够拆分任务,联网分析,使用工具等。以AugoGPT以开始,如何将大模型功能扩展到更大的领域,如何做任务规划,存储记忆,以及使用工具;以及制作AI Agent的平台工具,这也是提升便利性的方向。

除了autoGPT,langchain也是一个AI-agents的开发框架,同时也可以开发定制的知识库,同时也带动了向量数据库的发展,如Milvus,faiss等。
3.4 产品性思维
如何依托大模型来开发APP,最重要的是产品性思维;有哪些痛点,要解决什么问题。充分分析和挖掘需求,并结合大模型的能力,开发MVP最小可行产品,快速验证试错。比如chatMind是结合chatGPT+思维导图,GPTcache是节省chatGPT开销。大模型App的开发还在早期,要抓住机会。
4. AI安全
据传OpenAI这次100小时的宫斗,是因为OpenAI的首席科学家Ilya Sutskever对AI发展过于激进和AI安全的担忧。
说到AI的安全性,狭义上看AI或者生成式AI是否生成对人类有害的内容,比如是否包含种族歧视,性别歧视,暴力色情内容等,这也是当前评测大模型性能的一个方面。从广义上说,AI的安全性就广大到AI是否威胁人类的生存,AI会不会像影视剧中一样出现意识,毁灭人类。
到底会不会发生AI毁灭人类呢?不知道。不过可以讲一个实例,我们知道训练AI是通过拟合一个优化目标来完成的,这个目标是人类设定;比如我们训练AI和人类下棋对弈,而目标就是赢棋,AI可以通过多种手段来达到这个目标,我们希望AI通过学习大量棋谱和自我对弈来达到赢棋的目标,而AI可能另辟蹊径:那就是直接杀死和它下棋的人类来达到赢棋的目标,这就是激励扭曲。
我们如何能够更好的让AI和人类价值观做更好的对齐,使得AI的方式和人类相同,这也许是AI安全的一个解决方案。
以上是为总结,2023马上就要过去,我很想你它,我更期望崭新的2024和新的机遇。
5. 参考
-
attention is all you need
-
Language Models are Few-Shot Learners
-
Harnessing the Power of LLMs in Practice A Survey on ChatGPT and Beyond
-
符尧:拆解追溯 GPT-3.5 各项能力的起源
-
LLM Powered Autonomous Agents
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

