
热门标签
热门文章
- 1深入浅出Python日志打印_python 打印日志
- 2永恒之蓝 (EternalBlue) 漏洞利用原理详解_永恒之蓝漏洞
- 3直播系统开发之对接微信支付sdk流程_微信支付sdk干嘛的
- 4【IEEE出版】第六届电子与通信,网络与计算机技术国际学术会议(ECNCT 2024,7月19-21)_2024 ecnct
- 5Seata 中XA,AT模式浅析_xa at
- 6这是一份简单到没朋友的上手图数据库的图文教程_图数据库怎么访问
- 7性能巅峰对决:Rust vs C++ —— 速度、安全与权衡的艺术_rust语言和c++性能
- 8Mybatis 标签大全及标签中各属性详解_写出10个mybatis中mapper配置文件的标签
- 9git远程分支与本地分支合并_git合并本地分支 与远程分支
- 10网络安全工程师入门教程,从零基础入门到精通,看完这一篇就够了~_网络工程师教学csdn
当前位置: article > 正文
Python(8):文件的IO读写操作(操作普通文件/csv/excel)_csv文件操作
作者:从前慢现在也慢 | 2024-07-13 16:23:34
赞
踩
csv文件操作
一、文件的IO读写操作
1.常用的文件读取标志符
| 标识 | 含义 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| b | 可以在上述标识后边加b,表示字节层面,例如‘wb’,可以借助requests模块下载请求图片到本地 |
举个例子:
假设现在有个1.txt的文件

我们简单的读取一下
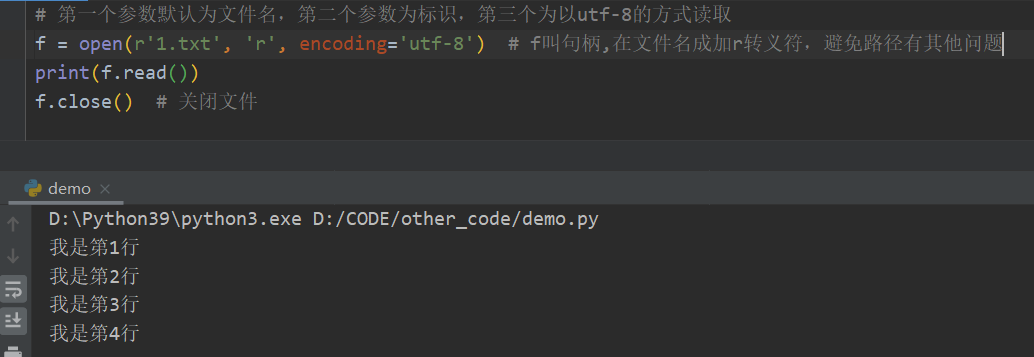
通常操作文件,我们会使用这种方式,可以不用关闭文件,是Python的一种简洁方式
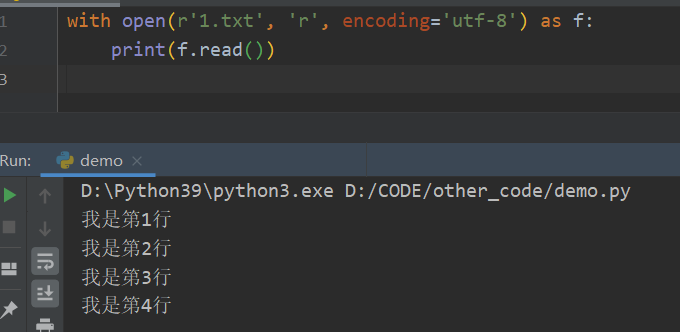
2.普通文件的读操作
关于读文件有3种方式,这里说一下区别
| 方法 | 作用 |
|---|---|
| read | 1.读取整个文件,将文件内容放到一个字符串变量中。2.如果文件非常大,尤其是大于内存时,无法使用read()方法。3.read()直接读取字节到字符串中,包括了换行符 |
| readline | 1.readline()方法每次读取一行;返回的是一个字符串对象,保持当前行的内存 2.比readlines慢得多 3.readline() 读取整行,包括行结束符,并作为字符串返回 |
| readlines | 一次性读取整个文件;自动将文件内容分析成一个行的列表。 |
二、csv文件的读写操作
1.读取操作
有一个示例文件,内容如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tLqWLmO4-1603958602468)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\1603957345164.png)]](https://img-blog.csdnimg.cn/2020102916034014.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70#pic_center)
读取文件
import csv # 使用csv模块
file_path = 'result.csv'
# 读取csv文件
with open(file_path, 'r') as f:
reader = csv.reader(f, delimiter=',') # 默认的情况下, 读和写使用逗号做分隔符(delimiter)
for row in reader:
print(row)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-51uPXwkV-1603958602469)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\1603957731518.png)]](https://img-blog.csdnimg.cn/20201029160352688.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70#pic_center)
2.读取时候跳过某一行
import csv
from itertools import islice
with open('2.csv', 'r') as f:
reader = csv.reader(f)
for row in islice(reader, 1, None): # 跳过表头的第一行
print(row)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.列表方式写入csv文件
这个是通过列表的方式进行写入,如果有标题,需要自己一一对应
import csv
with open('some.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['1', '1', '1', '1'])
writer.writerow(['2', '2', '2', '2' ])
- 1
- 2
- 3
- 4
- 5
- 6
运行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gvopptqw-1603958602470)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\1603958444732.png)]](https://img-blog.csdnimg.cn/2020102916040296.png#pic_center)
问题: 发现每写完一行会加入一个空行
解决办法: Python3因此需要加入在open( )中增加一个参数newline=’’
import csv
with open('some.csv', 'w',newline='') as f:
writer = csv.writer(f)
writer.writerow(['1', '1', '1', '1'])
writer.writerow(['2', '2', '2', '2' ])
- 1
- 2
- 3
- 4
- 5
- 6
运行

Python2可以把w或者a改成字节存储,可以避免这个问题,这里我封装了一下python2的写入
def write_to_csv(file_path, row, fileheaders):
with open(file_path, 'ab+') as f:
f.write(codecs.BOM_UTF8)
writer = csv.writer(f)
if not os.path.getsize(file_path):
writer.writerow(fileheaders)
writer.writerow(row)
print(row)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
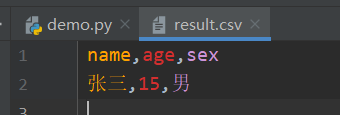
4.字典方式写入csv文件
import csv data = [ {'name': '张三', 'age': 15, 'sex': '男'}, {'name': '李四', 'age': 12, 'sex': '男'}, {'name': '彪子', 'age': 1, 'sex': '女'}, ] keys = data[0].keys() # 这里每行key相同,我随便取一行做表头 with open('result.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.DictWriter(f, fieldnames=keys) writer.writeheader() # writer.writerows(data) # 按顺序写全部 writer.writerow(data[0]) # 只写一条

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三、excel的数据操作(非pandas模块)
原文件
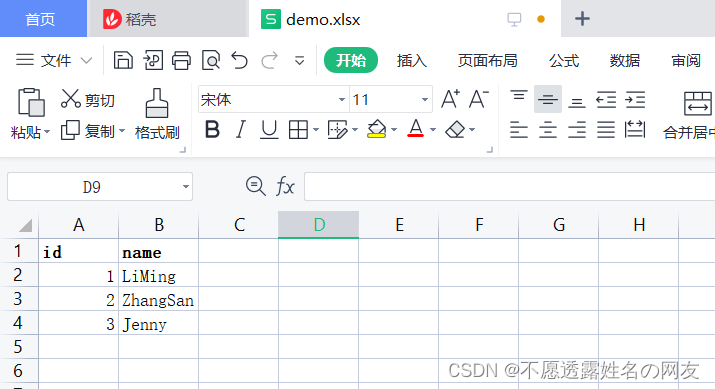
1.读取excel的某个sheet的某一行的某一列
import xlrd
file = 'demo.xlsx'
sheet_name='Sheet1'
work = xlrd.open_workbook(file)
work_sheet = work.sheet_by_name(sheet_name)
print(work_sheet.cell_value(2, 0)) # 读取第3行的第1列
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
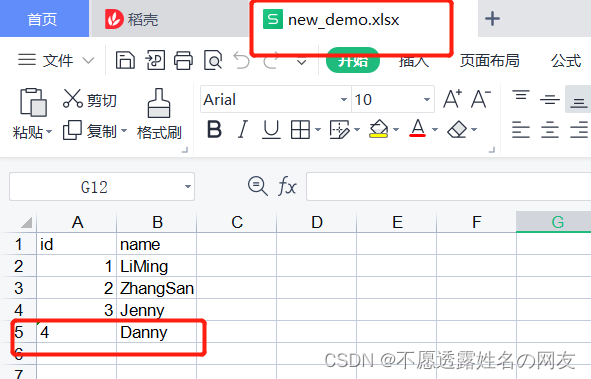
2.追加数据到新文件
# coding: utf-8 import xlrd from xlutils.copy import copy file = 'demo.xlsx' sheet_name = 'Sheet1' work = xlrd.open_workbook(file) work_sheet = work.sheet_by_name(sheet_name) # 对数据表格进行复制 new_file = copy(work) ws = new_file.get_sheet(0) # 往新表格写数据 ws.write(4, 0, '4') ws.write(4, 1, 'Danny') # 保存 new_file_name = 'new_demo.xlsx' new_file.save(new_file_name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/820418
推荐阅读

相关标签

