
热门标签
热门文章
- 1【微信小程序】零基础快速入门_小程序开发学习路线
- 2如何用Python编写俄罗斯方块Tetris游戏?_pygame tetris
- 3Druid数据库密码加密_druid开启数据库加密
- 4已解决java.util.concurrent.ExecutionException异常的正确解决方法,亲测有效!!!
- 5Neural Data-to-Text Generation with Dynamic Content Planning_neural pipeline for zero-shot data-to-text generat
- 6MySQL 出现 ERROR 1396 (HY000): Operation CREATE USER failed for ‘xxx’ 问题的解决方法_error 1396 (hy000): operation drop user failed for
- 7解决MacOS打开网下下载的Txt乱码_mac打开txt文件乱码
- 8谷粒商城学习笔记-18-快速开发-配置&测试微服务基本CRUD功能
- 9SQLserver链接MySQL服务器_链接服务器"sm"的 ole db 访问接口 "msdasql" 返回了消息 "[mysql][od
- 10YOLOv8改进 | 主干篇 | 低照度增强网络PE-YOLO改进主干(改进暗光条件下的物体检测模型)_yolov8低光照
当前位置: article > 正文
决策树分类预测(matlab代码)_matlab决策树
作者:从前慢现在也慢 | 2024-07-16 10:04:08
赞
踩
matlab决策树
决策树分类预测matlab代码
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的,期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树
数据为Excel分类数据集数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构:代码按照功能模块进行划分,清晰地分为数据准备、算法处理块和结果展示等部分,提高了代码的可读性和可维护性。
数据处理流程清晰:对数据进行了标准化处理,包括Zscore标准化,将数据分为训练集、验证集和测试集,有助于保证模型训练的准确性和可靠性。
模型评估: 代码中通过十折交叉验证等方法评估了模型的性能,计算了训练集、验证集和测试集的准确率,并输出了十折验证准确率和运行时长。此外,还通过绘制分类情况图和混淆矩阵对模型的分类效果进行了可视化展示,帮助更直观地了解模型的性能和分类结果。
结果可视化: 通过绘制通过绘制树形图,分类情况图和混淆矩阵,直观展示了模型的分类效果,有助于对模型性能进行直观分析和比较。
输出定量结果如下:
十折验证准确率
训练集ACU
验证集ACU
测试集ACU
运行时长
代码有中文介绍。
代码能正常运行时不负责答疑!
代码运行结果如下:
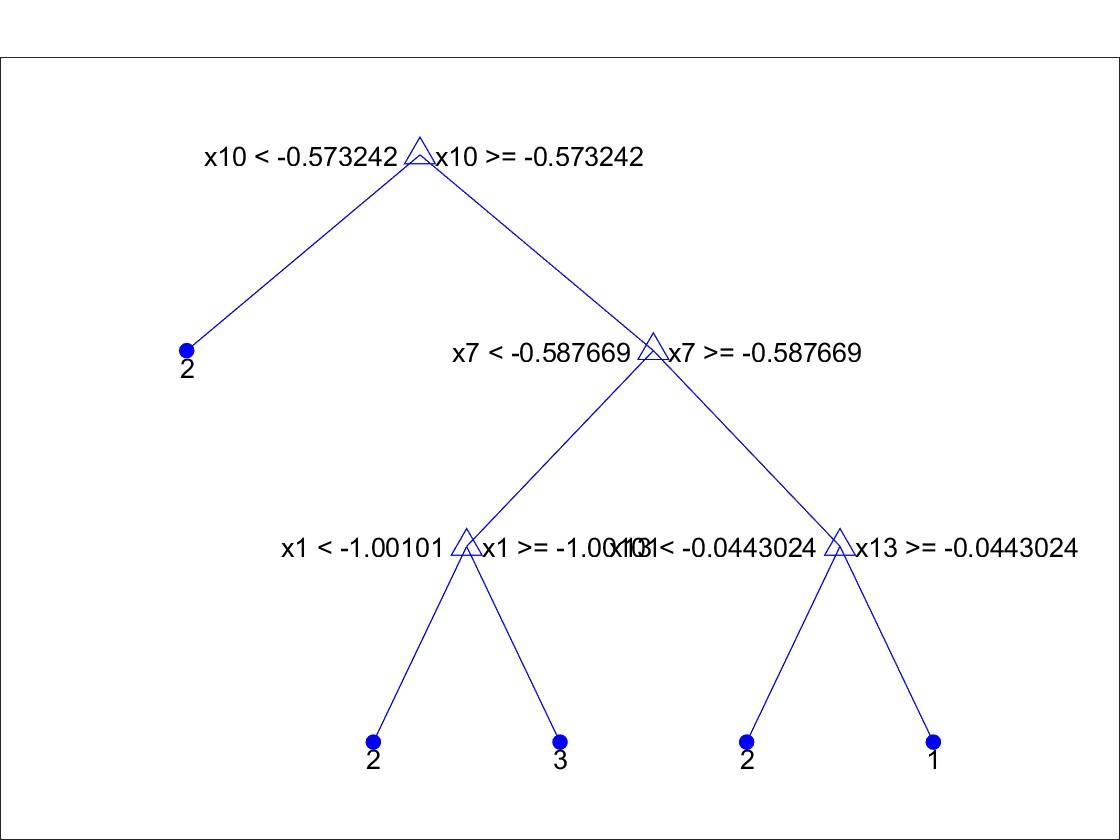
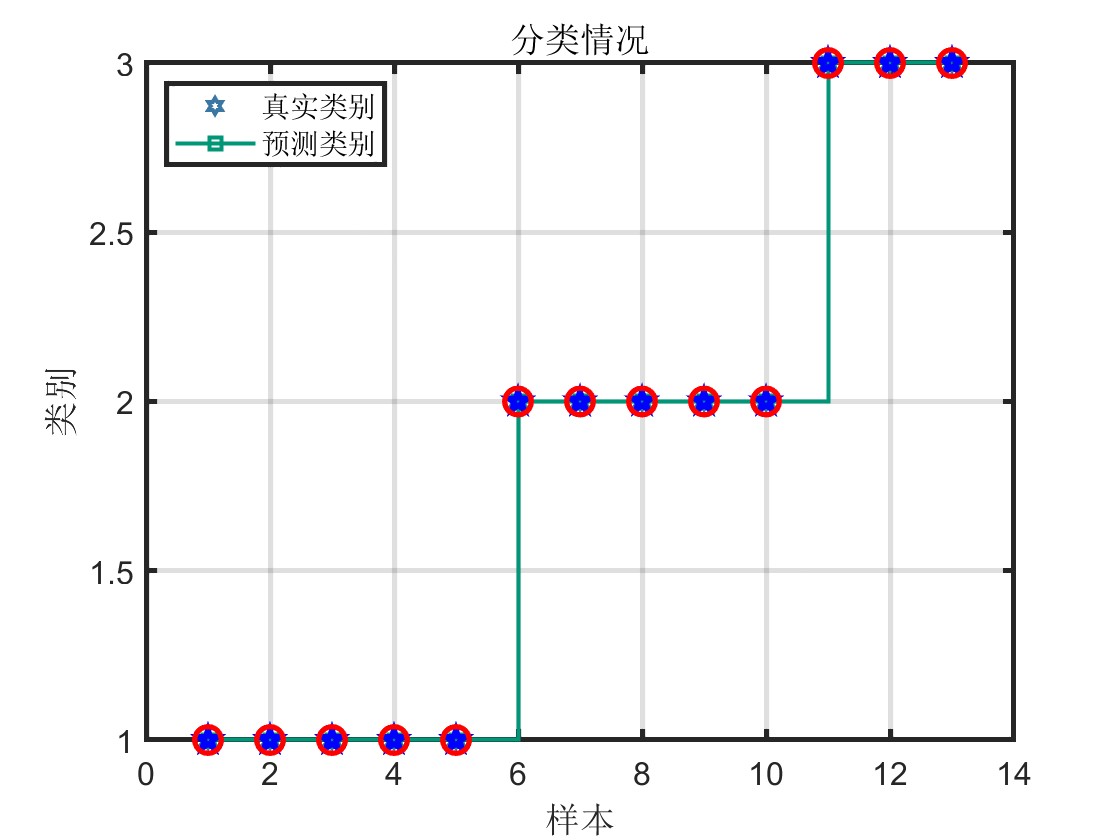
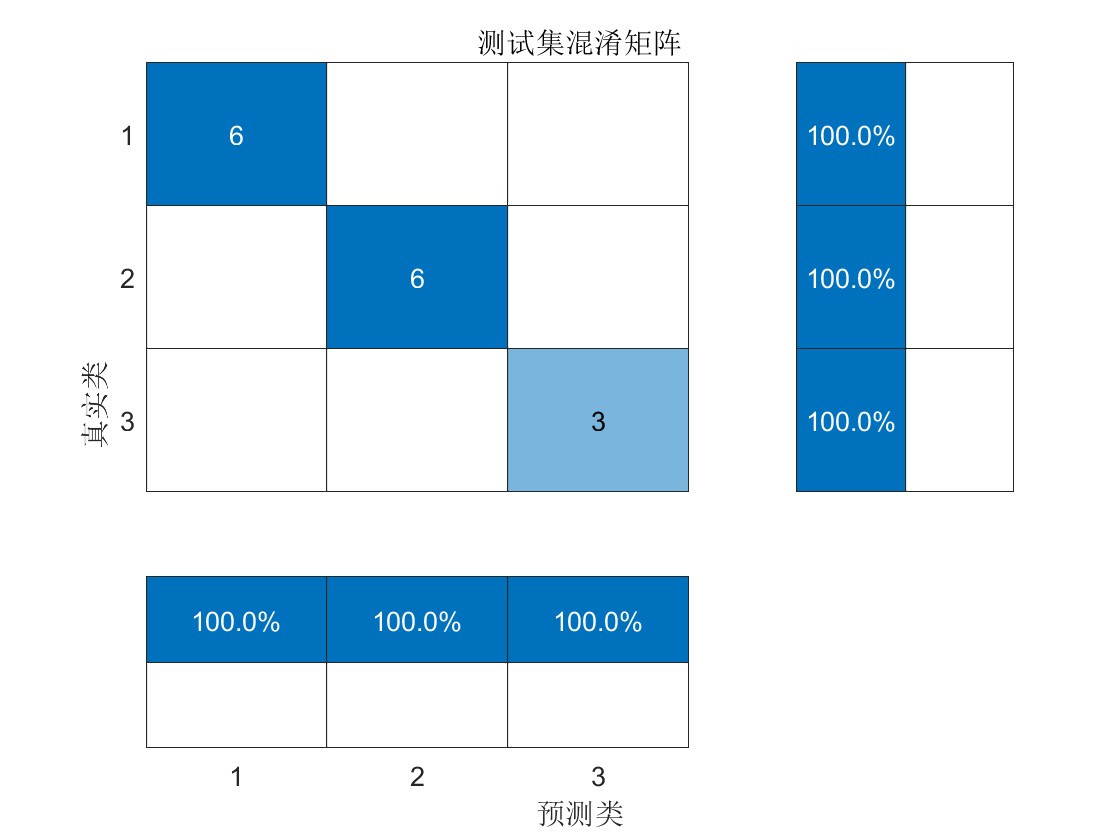
- 部分代码如下:
- % 清除命令窗口、工作区数据、图形窗口、警告
- clc;
- clear;
- close all;
- warning off;
- load('data.mat')
-
- data1=readtable('分类数据集.xlsx'); %读取数据
- data2=data1(:,2:end);
- data=table2array(data1(:,2:end));
- data_biao=data2.Properties.VariableNames; %数据特征的名称
- A_data1=data;
- data_select=A_data1;
-
- x_feature_label=data_select(:,1:end-1); %x特征
- y_feature_label=data_select(:,end); %y标签
- index_label1=randperm(size(x_feature_label,1));
- index_label=G_out_data.spilt_label_data; % 数据索引
- if isempty(index_label)
- index_label=index_label1;
- end
- spilt_ri=G_out_data.spilt_rio; %划分比例 训练集:验证集:测试集
- train_num=round(spilt_ri(1)/(sum(spilt_ri))*size(x_feature_label,1)); %训练集个数
- vaild_num=round((spilt_ri(1)+spilt_ri(2))/(sum(spilt_ri))*size(x_feature_label,1)); %验证集个数
- %训练集,验证集,测试集
- train_x_feature_label=x_feature_label(index_label(1:train_num),:);
- train_y_feature_label=y_feature_label(index_label(1:train_num),:);
- vaild_x_feature_label=x_feature_label(index_label(train_num+1:vaild_num),:);
- vaild_y_feature_label=y_feature_label(index_label(train_num+1:vaild_num),:);
- test_x_feature_label=x_feature_label(index_label(vaild_num+1:end),:);
- test_y_feature_label=y_feature_label(index_label(vaild_num+1:end),:);

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/833519
推荐阅读
相关标签

