
- 1AWS RDS启用自动备份_aws rds备份
- 2项目管理模板_2021年会策划,用项目管理思维搞定!(附28个配套模板)
- 3Python 使用 WeChatFerry 搭建部署微信机器人详细教程(更新中)
- 4JDBC——详解注册驱动_在哪里修改jdbc的注册驱动
- 5PHP实现SM2算法(附完整源码)_php sm2
- 6c语言编程实现rm调度算法,浅析rm与edf实时调度算法.docx
- 7GIT常用操作整理(从本地创建仓库到提交到GitHub全流程)学习笔记_git新建一个仓库
- 8亚马逊云与生成式 AI 的融合:未来展望与综述_亚马逊生成式ai
- 9基于第三方开源框架xxl-sso单点登录的实现
- 10使用Spring Retry实现重试机制
Hadoop集群中各节点的连接与HDFS的作用介绍_hadoop集群节点
赞
踩
摘要:本文将介绍Hadoop集群中各节点之间的连接方式,并重点探讨Hadoop分布式文件系统(HDFS)在数据处理中的重要作用。我们将深入了解Hadoop集群的架构,并详细介绍HDFS的特性和功能
引言
Hadoop已成为处理大规模数据的首选框架,其分布式计算能力和可靠性使其在大数据处理领域广泛应用。Hadoop集群由多个节点组成,每个节点负责承担不同的任务,并通过HDFS共享和存储数据。

Hadoop集群架构
Hadoop集群主要由以下几个组件组成:
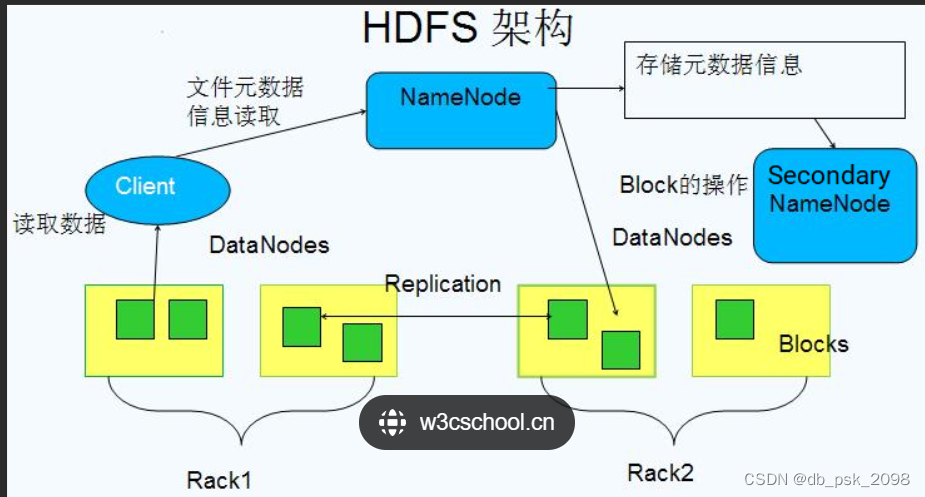
- NameNode: NameNode是HDFS的关键组件之一。它负责管理整个HDFS文件系统的命名空间和元数据信息。命名空间包括文件和目录的结构,以及与它们相关联的权限、时间戳和数据块的位置信息。元数据信息则包括文件的大小、副本数量和数据块的位置等。
-
NameNode还负责处理客户端的读写请求,将这些请求转化为适当的数据块位置,并向客户端提供数据块所在的DataNode地址。它还负责监控DataNode的状态和健康状况,并在需要时重新复制数据块以确保数据的可靠性。
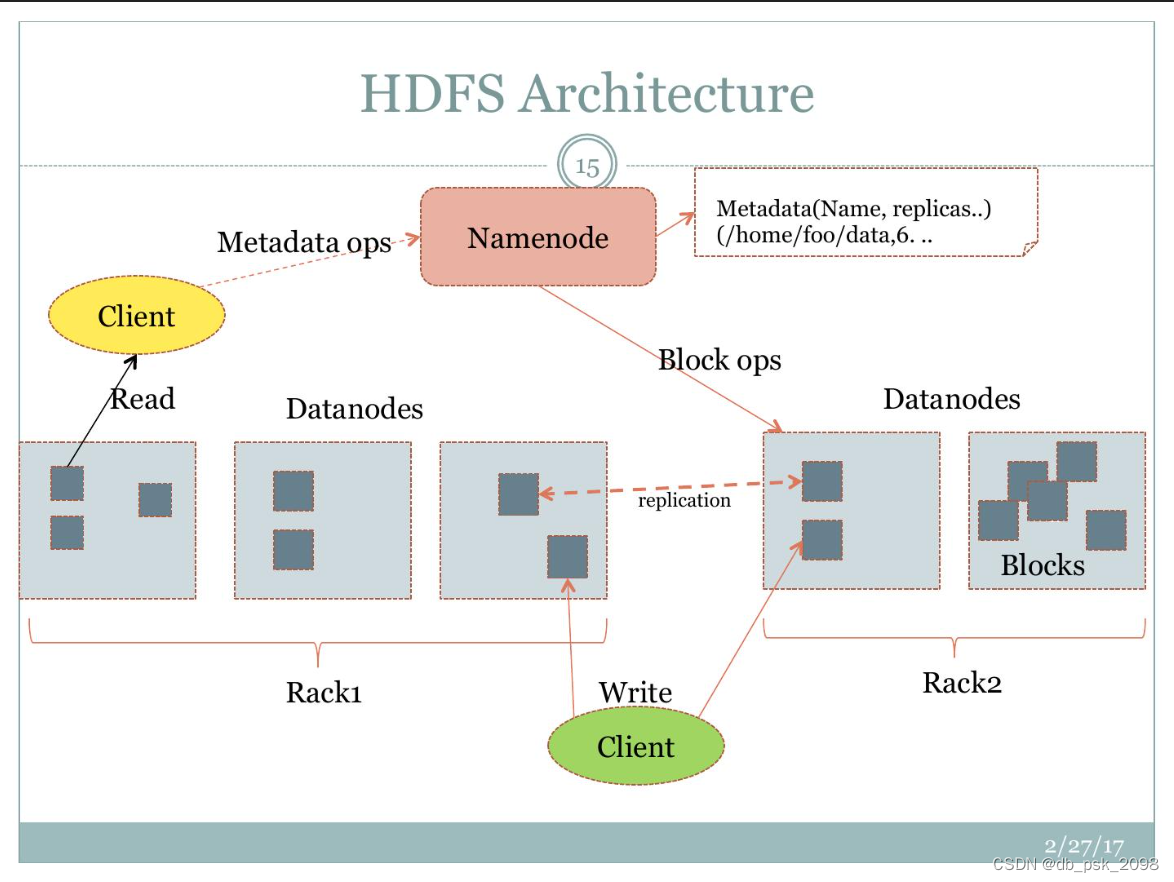
- DataNode: DataNode是实际存储数据块的节点。每个DataNode都存储了一部分数据块,并向NameNode报告它们存储的状态。DataNode通过与客户端和其他DataNode的交互来执行读取和写入操作。
-
当客户端请求访问特定数据块时,DataNode会提供该数据块的副本。它还负责处理数据块的复制、删除和传输等操作,以及定期向NameNode报告其健康状况。
- ResourceManager: ResourceManager是Hadoop集群中的资源管理器。它负责整个集群的资源分配和任务调度。ResourceManager维护着集群中可用资源的信息,并根据应用程序的需求分配适当的资源。
-
ResourceManager还负责监控各个NodeManager的状态,并根据需要重新分配任务。它使用调度器来决定哪些任务在哪些节点上运行,并确保集群的资源被充分利用。
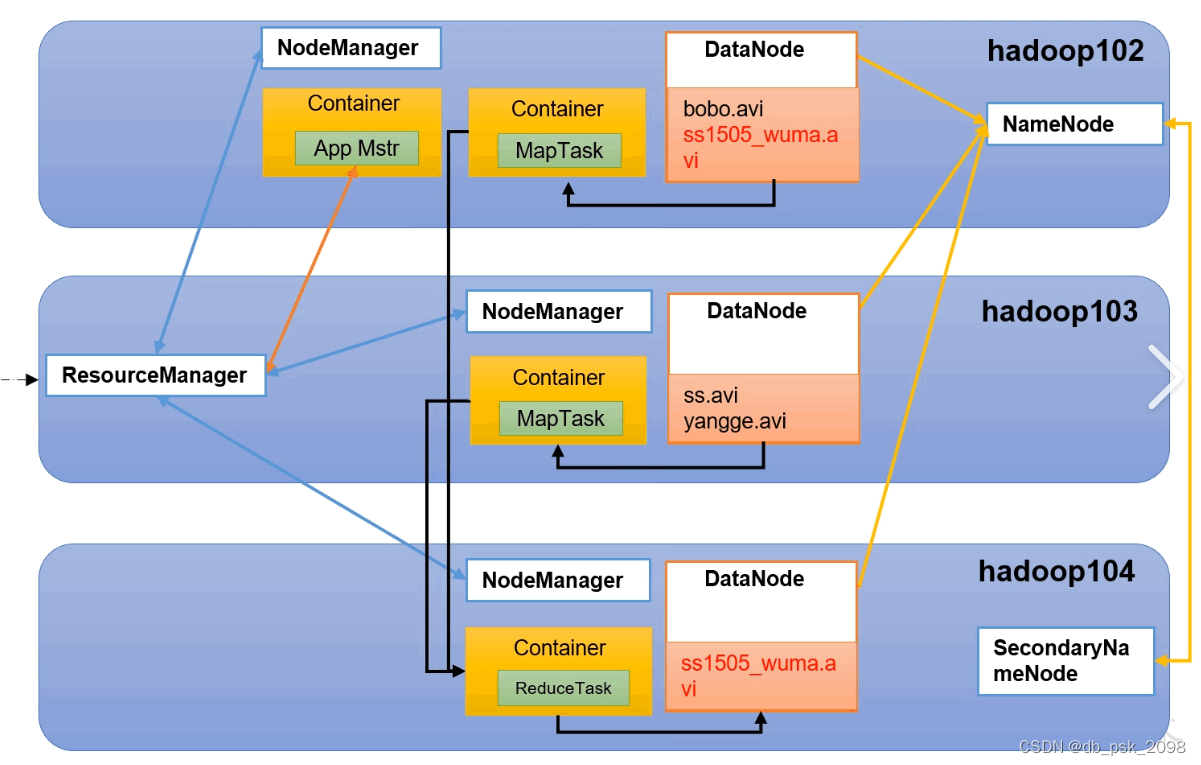
- NodeManager: NodeManager是位于每个节点上的代理。它负责监控节点的使用情况,并与ResourceManager通信以获取任务分配和资源分配。NodeManager还负责启动、监控和报告运行在该节点上的容器(Container)。
-
NodeManager还负责管理本地节点上的资源,如内存和CPU,并根据ResourceManager的要求动态调整资源分配。
- Secondary NameNode: Secondary NameNode并不是NameNode的备份或热备节点。它定期从NameNode复制编辑日志并合并它们,以减少NameNode日志的大小和恢复时间。
-
Secondary NameNode帮助确保在NameNode发生故障时能够更快地进行恢复。尽管它的名称可能会导致误解,但Secondary NameNode并不直接承担NameNode的功能。
Hadoop集群节点之间的连接方式
Hadoop集群中的各节点通过网络连接进行通信和数据传输。以下是几种常见的节点连接方式:
- 局域网(LAN)连接: 局域网连接是指通过一个局域网(如公司内部网络)连接各个节点。这种连接方式适用于小型集群或本地开发环境,因为它简单直接,不需要额外的网络设备或服务。
-
局域网连接通常使用以太网技术,数据传输速度可以达到千兆每秒,足以满足大多数应用的需求。不过,由于局域网的范围有限,这种连接方式不适用于跨越不同地理位置的集群。
- 广域网(WAN)连接: 广域网连接是指通过互联网连接各节点。这种连接方式适用于跨越不同地理位置的集群,但需要考虑网络带宽和延迟等因素,确保数据传输效率和稳定性。
-
广域网连接通常使用VPN或专线技术,以提高数据传输的安全性和稳定性。不过,由于互联网的不确定性和不稳定性,广域网连接可能会遇到一些问题,如延迟、丢包和带宽瓶颈等。
- 云服务提供商: 许多云服务提供商(如AWS、Azure)提供Hadoop集群的托管服务,节点之间的连接通过云服务提供商的网络进行。这种连接方式可以帮助企业快速构建和管理Hadoop集群,同时减少了对硬件和网络设备的投资。
-
云服务提供商通常提供高速网络连接,并根据用户需求灵活调整带宽和存储空间。不过,使用云服务提供商也需要考虑成本和安全性等问题。
总的来说,在选择节点连接方式时,需要根据实际需求和预算情况综合考虑各种因素,如数据传输速度、稳定性、安全性、成本等。
HDFS的作用及特性
Hadoop分布式文件系统(HDFS)是Hadoop生态系统中的核心组件之一,它提供了一种可靠、高吞吐量的分布式存储和处理大规模数据的方法。以下是对HDFS几个关键特性的深入讲解:
- 可靠性和容错性: 为保证数据的可靠性和容错性,HDFS采用了多副本机制,即将数据划分成多个块并在集群中复制多份。默认情况下,每个数据块会被复制到3个不同的节点上,这样即使某个节点发生故障,数据仍然可以从其他节点中获取。 ( 此外,HDFS还具有自我修复机制,即当某个节点上的数据块丢失或损坏时,HDFS会自动将其复制到其他节点上,以保证数据的完整性和可靠性。)
-
高吞吐量: HDFS旨在处理大量数据,通过并行读取和写入数据块,实现高吞吐量的数据访问。HDFS支持批量数据处理和流式数据处理,同时还提供了分布式计算框架MapReduce来实现数据处理。
-
分布式存储: HDFS将大规模数据集划分成多个块并存储在不同的节点上,实现了数据的分布式存储和管理。每个数据块的大小可以根据需要进行配置,默认情况下为128MB。HDFS还提供了命名空间管理、权限控制、数据快照等功能,以便于用户对数据进行管理和维护。
-
数据本地性: 为减少数据传输的开销,提高计算效率,HDFS倾向于将计算任务分配给存储数据的节点。这样可以避免数据在网络中传输的开销,提高计算效率,同时也可以减少网络带宽的消耗。
-
扩展性: 为应对不断增长的数据处理需求,HDFS可以轻松地扩展到成百上千个节点。HDFS的设计基于水平扩展,即通过添加更多的节点来扩展存储和计算能力。同时,HDFS还支持动态添加和删除节点,以便于根据实际需求调整集群的规模。
总的来说,HDFS的可靠性、高吞吐量、分布式存储、数据本地性和扩展性等特性,使得它成为处理大规模数据的首选方案,并在企业级数据处理和分析中得到广泛应用。
结论
Hadoop集群中各节点之间的连接和HDFS在数据处理中起着关键的作用。通过良好的网络连接和合理的架构设计,我们能够充分利用Hadoop集群的分布式计算能力和存储能力,实现高效的大数据处理和分析。
希望本文对您理解Hadoop集群的节点连接方式和HDFS的作用有所帮助。

