
- 1常见的10种算法
- 2深度学习在医疗健康领域的应用:疾病预测_深度学习与疾病
- 3计算机开发岗和算法岗都有些什么区别?_开发还是算法怎么选择
- 4绘唐3模型怎么放本地sd安装及模型放置位置 及云端sd部署_三维图形的存储怎么挂到服务器上
- 5企业自身数据保护技巧你知道多少?用堡垒机可以实现吗?
- 6【信道估计】基于LS和MMSE算法导频信道估计(误差率对比)附Matlab代码_mmse信道估计matlab
- 7解决问题后的记录 \[Microsoft\]\[ODBC 驱动程序管理器\] 未发现数据源名称并且未指定默认驱动程序_odbcad64.exe
- 8python opencv毕设题目推荐
- 9MySql报 java.sql.SQLException: Incorrect string value 乱码解决方法_cause: java.sql.sqlexception: incorrect string val
- 10免费的题库查询接口_免费脚本题库配置链接
【论文略读】(MLLA)清华大学--Demystify Mamba in Vision: A Linear AttentionPerspective_demystify mamba in vision: a linear attention pers
赞
踩
基本信息
机构:清华大学,阿里巴巴
标题:在视觉上揭开曼巴的神秘面纱:线性注意力视角
时间:2024年5月26日
摘要
引入Baseline Mamba,指明Mamba在处理各种高分辨率图像的视觉任务有着很好的效率。
文章发现了强大的Mamba和线性注意力Transformer( linear attention Transformer)非常相似,然后就分析了两者之间的异同。
作者将Mamba模型重述为linear attention Transformer的变体,并且主要有六大差异,分别是:input gate, forget gate,shortcut, no attention normalization, single-head, and modified block design。作者对每个设计都细致的分析了优缺点,评估了性能,最终发现forget gate和block design是Mamba这么给力的主要贡献点。
基于以上发现,作者提出了一个类似mamba的线性注意力模型,Mamba-Like Linear Attention (MLLA) ,相当于取其精华,去其糟粕,把mamba两个最为关键的优点设计结合到线性注意力模型当中,具有可并行计算和快速推理的特点。
引言
如同Transformer的影响力,现在Mamba状态空间模型引发了广泛的学者研究兴趣。
Transformer的二次复杂度问题,被Mamba的SSM(State Space Model)解决了,可以允许处理计算成本很高的序列,成为自然语言处理和视觉识别的领军模型。
作者提出了线性注意力工作,用线性归一化代替了注意力操作机制当中的非线性Softmax函数,将计算顺序从降到了
,计算复杂度大幅度降低,从
降到了
,但其实线性注意力transformer并不是那么强,所以提出了问题:什么因素导致了mamba的成功,以及它相对线性注意力transformer的优势在哪里?
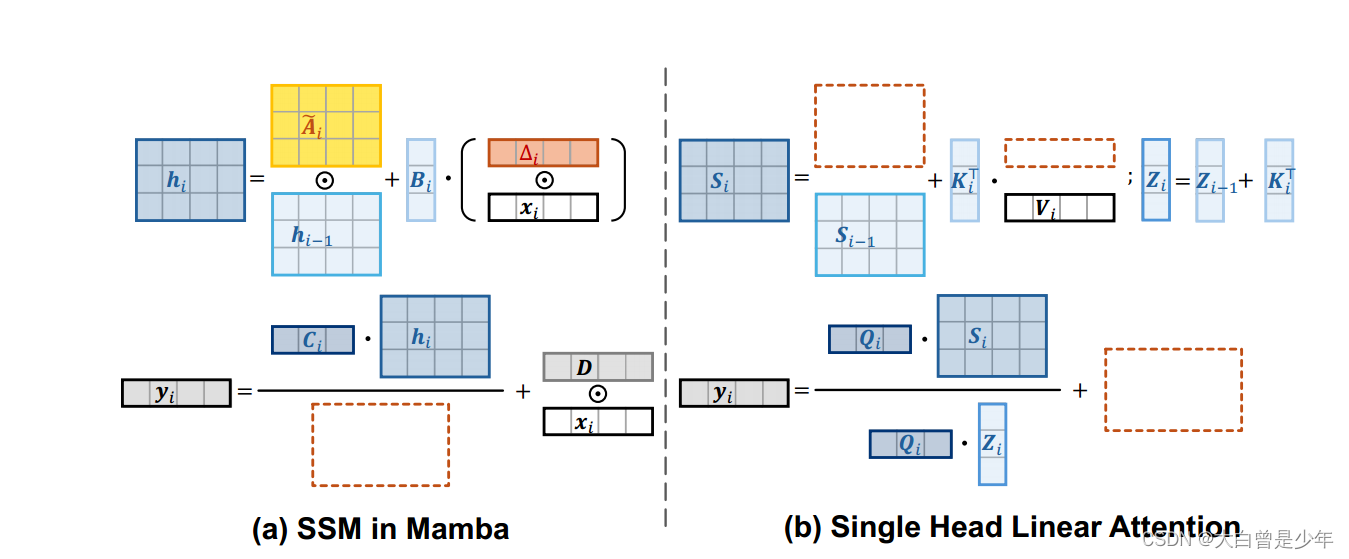
上图是论文中SSM与单头线性注意力的对比,棕色框是没有对方的东西,可以看到两者非常相似。
近期工作
transfomer很好,但广泛使用的softmax注意力会出现二次复杂度问题
mamba系列网络很好解决了这个问题
前书
3.1讲了注意力机制和线性注意力机制
3.2讲了选择状态空间模型SSM
列举了SSM和它的等价形式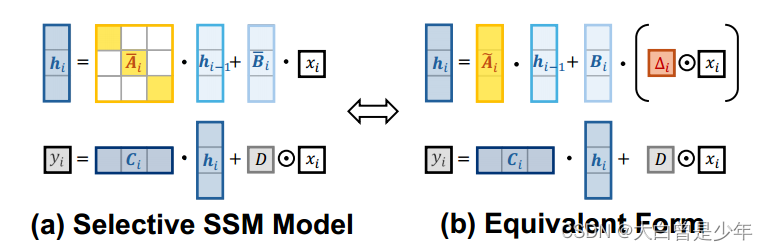
mamba和LAT(线性注意力Transformer简称,同下文)的联系
选择性SSM类似于LAT:
SSM增加了input gate, forgetgate and shortcut
SSM减少了normalization and multi-head design
随后作者对上述五个因素进行了简单分析,总结为:
曼巴可以看作是线性注意力转换器的变体,具有专门的线性注意力和改进的block设计
这一章也是宏观对比了三个block结构
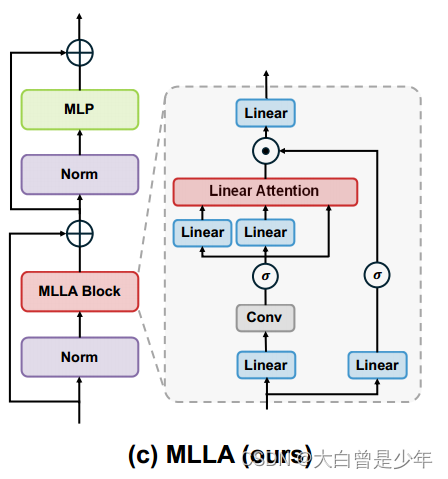
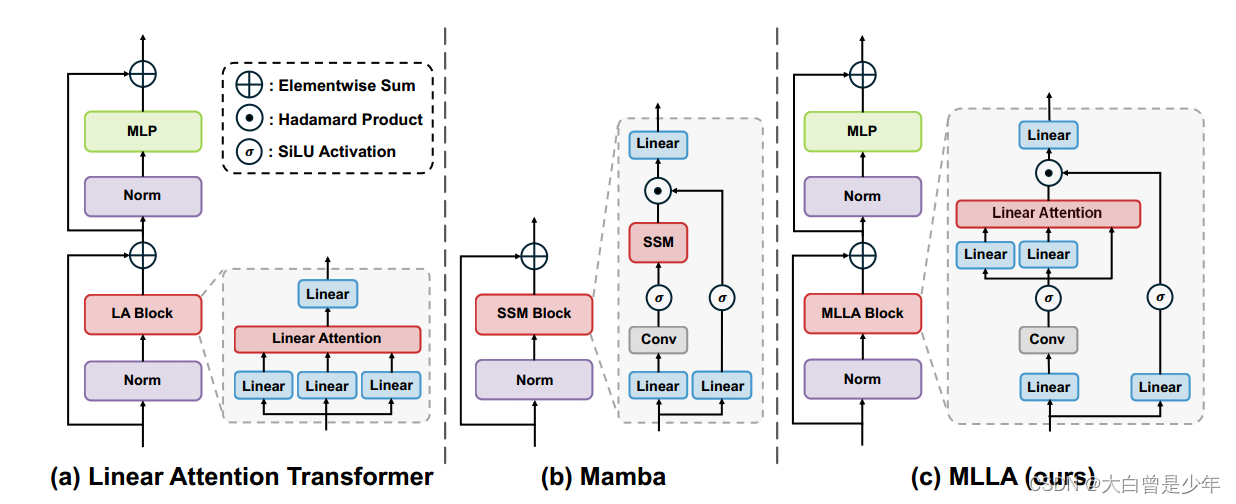 大致可以理解为,MLLA就是仿照Mamba,把Mamba中最好的结构设计(Forget gate、Block Design)加进LA Block中变成自己的MLLA Block。
大致可以理解为,MLLA就是仿照Mamba,把Mamba中最好的结构设计(Forget gate、Block Design)加进LA Block中变成自己的MLLA Block。
实证研究
Baseline:Swin-transformer中的Softmax注意力替代为线性注意力
消融实验
验证上文提到的几个架构差异影响,在ImageNet-1k上评估性能,做消融实验
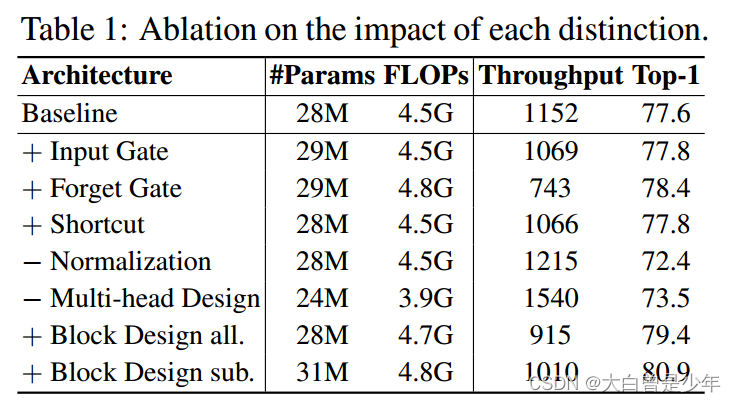
作者用两种方式来评估Block Design,分别是上表中的all和sub,all指的是用整个Mamba block架构替换transformer block,sub指的是mamba替代LA(线性注意力)block,保留MLP子块,可以看到sub的效果是最好的,下图MLLA中也是用的Block Design sub.的设计模式。
可以看到架构差异中的Forget gate和Block Design是对性能提高最猛的两个,LAT加了Forget gate,Top1加了0.6%,Block Design更多,all提高了Top1 1.8%,sub提高了Top1 3.3%.
这也是作者制作MLLA的原因。
整体模块复杂度
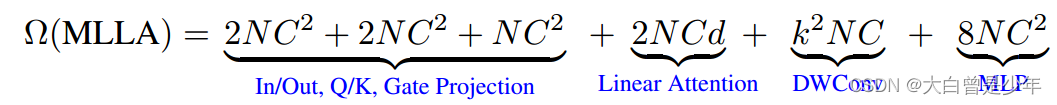
略微比Transformer的复杂度大一点,整体复杂度还是比较优秀的。
图像分类效果
MLLA在所有模型上T,S,B都超越了Mamba,证明了SSM中forget和block的优点。
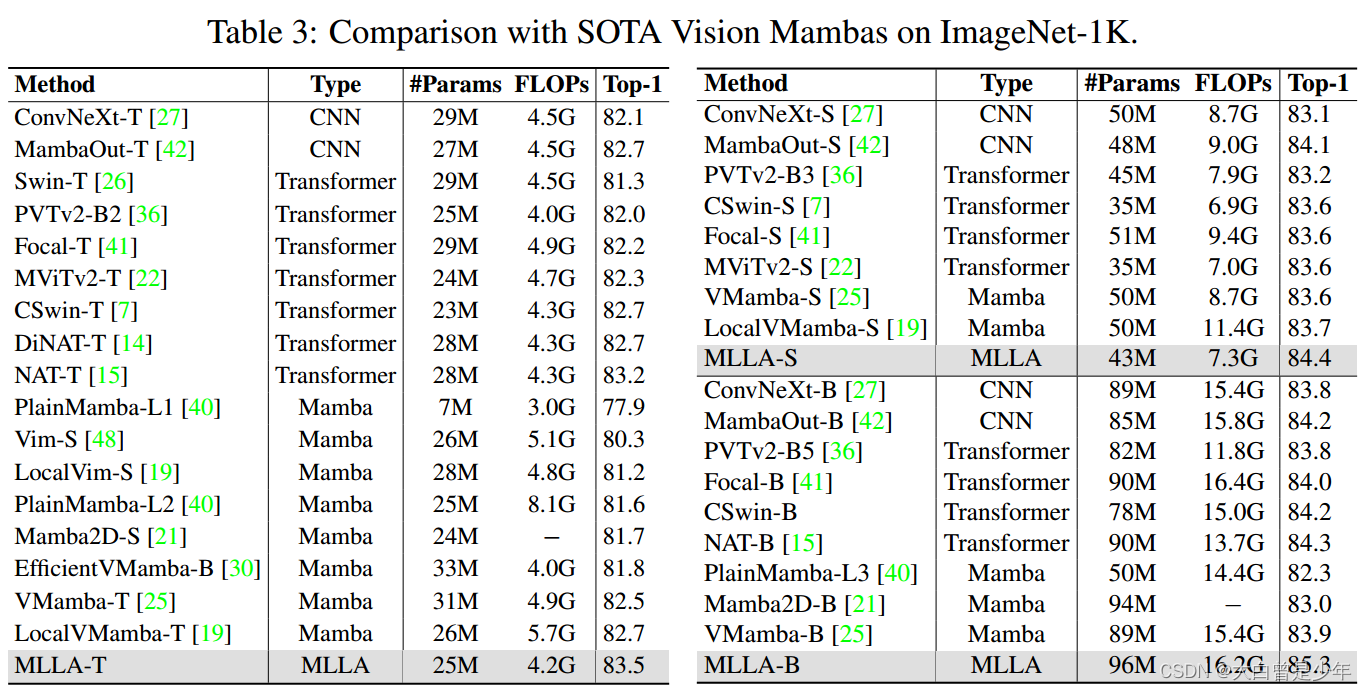
测量速度
MLLA受益于可并行计算,比Mamba系列模型推理速度都更快。
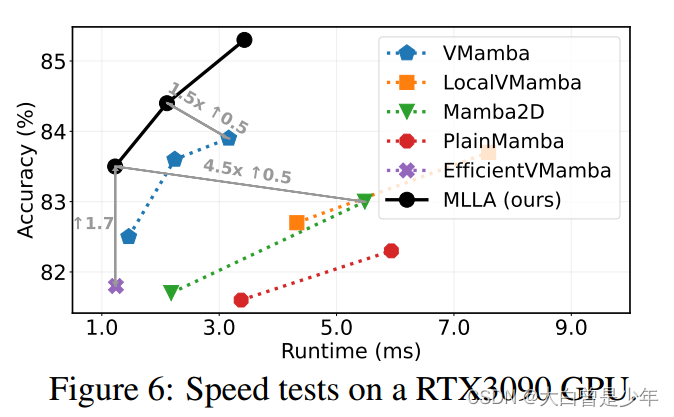
比Mamba2D快4.5倍,比VMamba快1.5倍并增加了0.5%的精度,这些都证明了并行MLLA比Mamba更适合非因果数据,如图像。
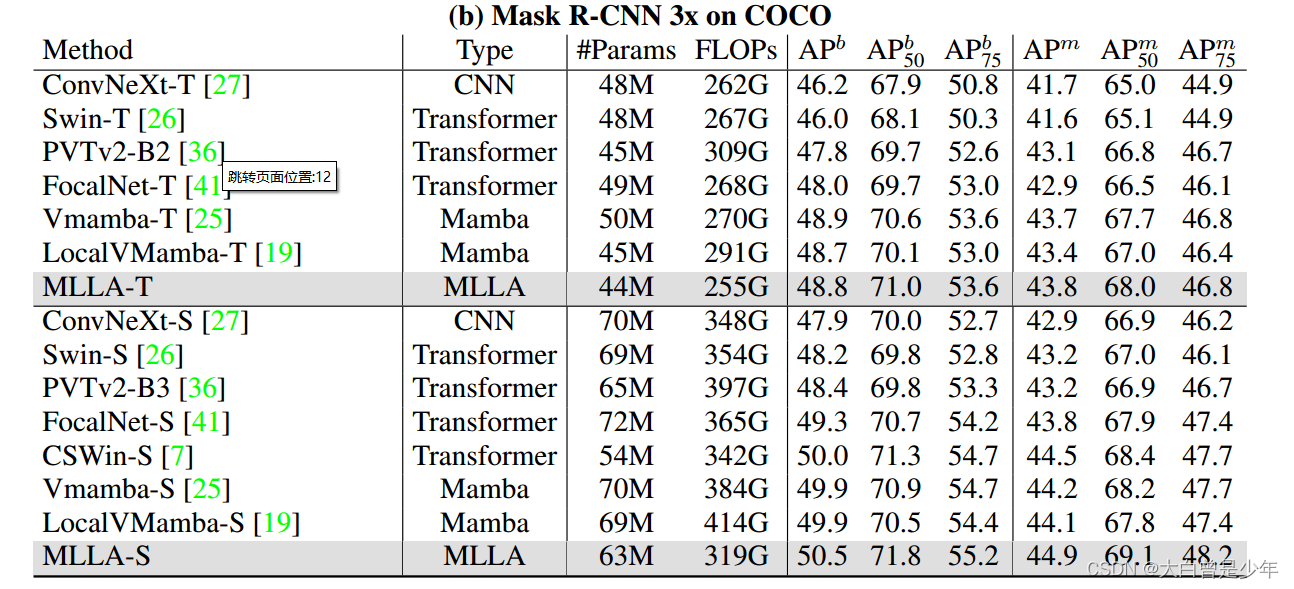
COCO目标检测
MLLA取得了优于Mamba模型的结果,表明在高分辨率密集预测任务中是有效的,MLLA提供了有效的全局建模。

MLLA表现优于MambaOut,MambaOut是我上个跑的模型,hh更替速度太快了。
ADE-20K语义分割
下图中SS和MS分别代表单尺度和多尺度测试
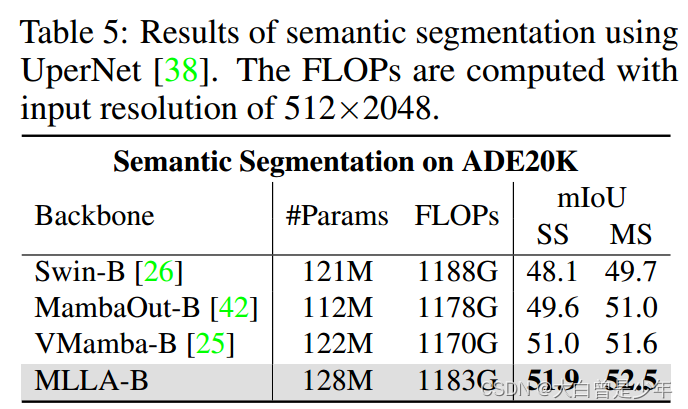
使用UperNet进行语义分割的结果,FLOPs的输入分辨率为512×2048。
结论
本文揭示了强大的曼巴和LAT之间惊人的密切关系,为曼巴的优势和成功提供了一些启示。我们将Mamba重新定义为线性注意力转换器的变体,并确定了它的六种主要特殊设计:输入门、遗忘门、快捷方式、无注意归一化、单头和修改块设计。经验验证表明,遗忘门和块设计在很大程度上提高了性能,而其他差异的贡献很小或损害了模型的性能。基于我们的研究结果,我们提出了我们的类曼巴线性注意(MLLA)模型,将这两个关键设计的优点纳入线性注意。MLLA在保持并行计算和高推理速度的同时,在多个任务上超越了各种视觉曼巴模型。
手敲不易,求关注求点赞,么么哒

