
- 1TypeError: argument of type ‘type‘ is not iterable 解决办法python_argument of type 'type' is not iterable
- 2基于51单片机的万年历设计_51单片机万年历设计
- 3赛博活佛再出手,PaintsUndo一键生成绘画全过程视频!
- 4国产化区块链平台-FISCO BCOS 区块链
- 5微信小程序源码-160套微信小程序毕业设计的项目实战(源码+论文+演示视频)
- 6《Docker极简教程》--Docker容器--Docker容器的创建和使用_docker创建容器
- 7鸿蒙4.2小版本推出,鸿蒙5.0已经不远了_鸿蒙4.2不如4.0
- 8Springboot —— 根据docx填充生成word文件,并导出pdf_xwpftemplate
- 9MySQL运维实战(2.4) SSL认证在MySQL中的应用_ssl mysql通信
- 10sqlalchemy定期保持mysql连接活跃
详细介绍Seq2Seq、Attention、Transformer !!_seq2seq transformer
赞
踩
文章目录
前言
本文将从Seq2Seq工作原理、Attention工作原理、Transformer工作原理三个方面,详细介绍Encoder-Decoder工作原理。

Encoder-Decoder工作原理
1、Seq2Seq工作原理
Seq2Seq(Sequence-to-Sequence):输入一个序列,输出另一个序列。
在2014年,Cho等人首次在循环神经网络(RNN)中提出了Seq2Seq(序列到序列)模型。与传统的统计翻译模型相比,Seq2Seq模型极大地简化了序列转换任务的处理流程。
核心思想
- 编码器(Encoder):使用一个循环神经网络(RNN)作为编码器(Encoder),读取输入句子,并将其压缩成一个固定维度的编码。
- 解码器(Decoder):使用另一个循环神经网络(RNN)作为编码器(Decoder)读取这个编码,并逐步生成目标语言的一个句子。

Seq2Seq
Seq2Seq模型通过端到端的训练方式,将输入序列和目标序列直接关联起来,避免了传统方法中繁琐的特征工程和手工设计的对齐步骤。这使得模型能够自动学习从输入到输出的映射关系,提高了序列转换任务的性能和效率。
Seq2Seq
工作原理
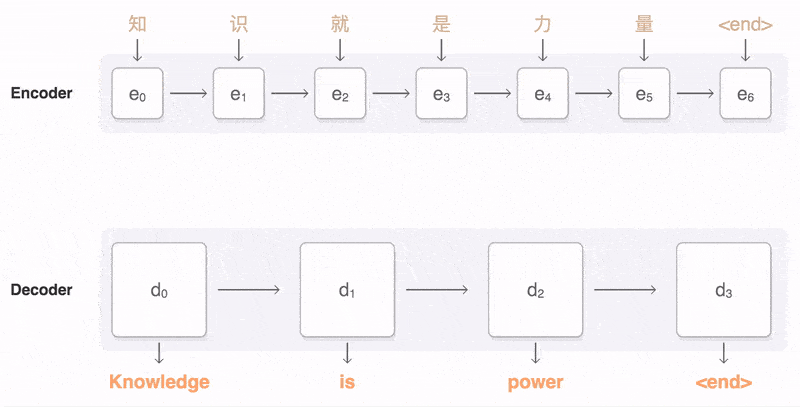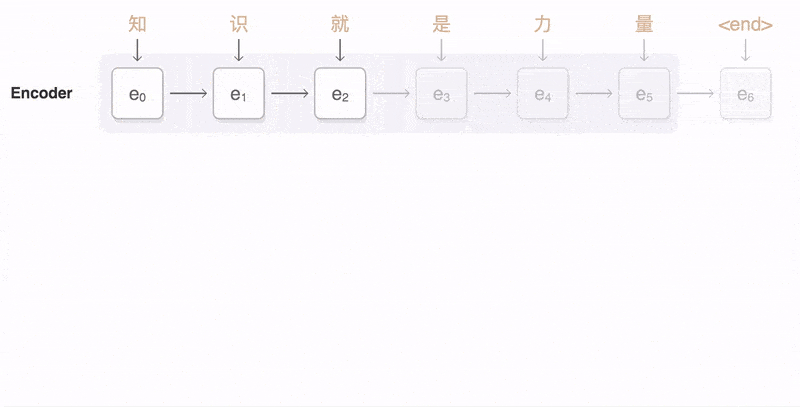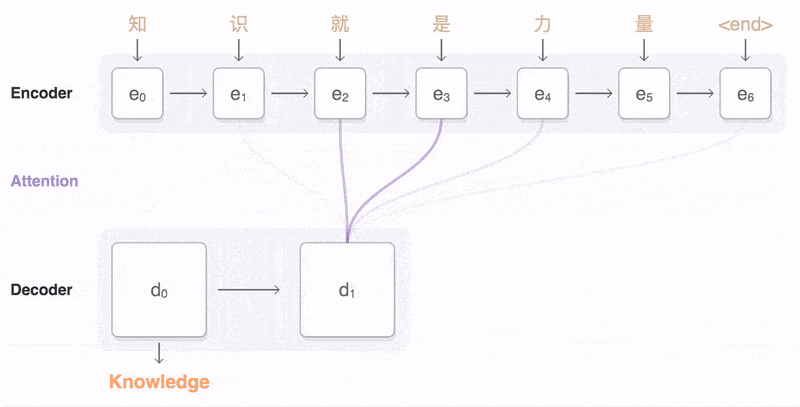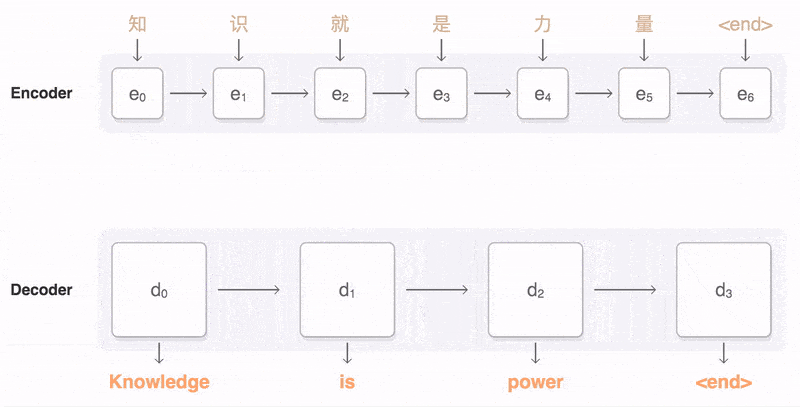
Seq2Seq模型中的编码器使用循环神经网络将输入序列转换为固定长度的上下文向量,而解码器则利用这个向量和另一个循环神经网络逐步生成输出序列。

Seq2Seq的工作原理
Encoder(编码器)
- 编码器是Seq2Seq模型中的一部分,负责将输入序列转换为固定长度的上下文向量。
- 它使用循环神经网络(RNN)或其变体(如LSTM、GRU)来实现这一转换过程。
- 在编码过程中,编码器逐个读取输入序列中的元素,并更新其内部隐藏状态。
- 编码完成后,编码器将最终的隐藏状态或经过某种变换的隐藏状态作为上下文向量传递给解码器。
Dncoder(解码器)
- 解码器是Seq2Seq模型中的另一部分,负责从上下文向量生成输出序列。
- 它同样使用循环神经网络(RNN)或其变体(如LSTM、GRU)来实现生成过程。
- 在每个时间步,解码器根据上一个时间步的输出、当前的隐藏状态和上下文向量来生成当前时间步的输出。
- 解码器通过逐步生成输出序列中的每个元素,最终完成整个序列的生成任务。
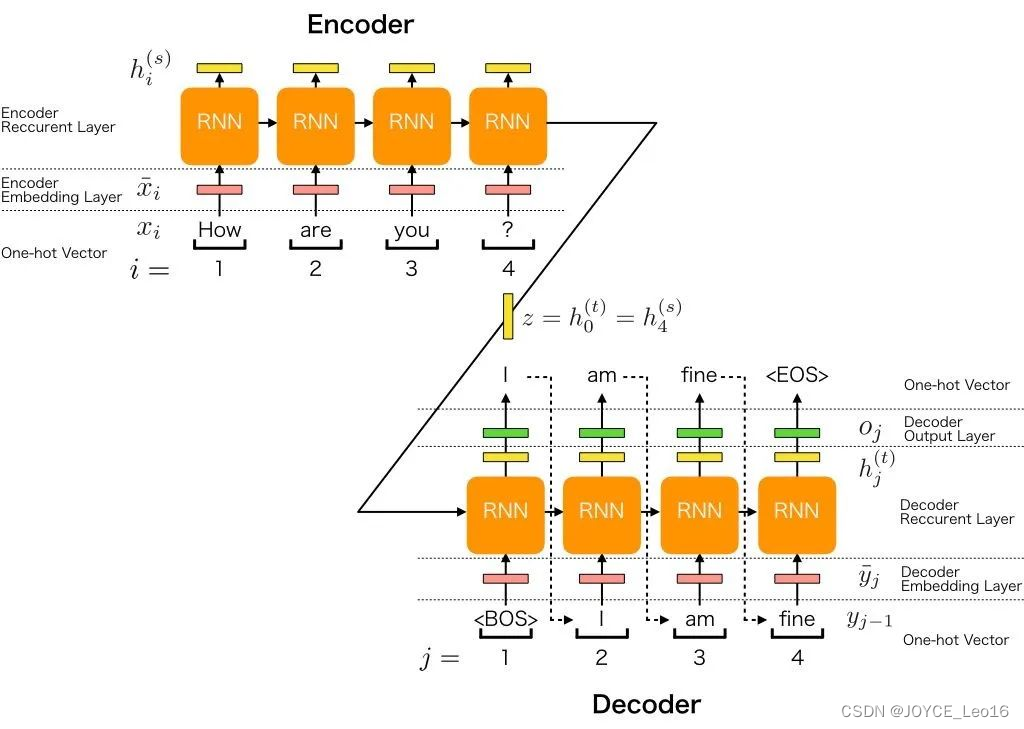
Seq2Seq的工作原理
2、Attention工作原理
Attention Mechanism(注意力机制):Attention Mechanism是一种在深度学习模型中用于处理序列数据的技术,尤其在处理长序列时表现出色。最初引入注意力机制是为了解决机器翻译中遇到的长句子(超过50字)性能下降问题。
传统的机器翻译在长句子上的效果并不理想,因为固定长度的向量难以包含句子的所有语义细节。注意力机制的核心思想是在生成每个输出词时,模型都能够关注到输入序列中的相关部分。
核心逻辑:从关注全部到关注重点
- Attention机制处理长文本时,能从中抓住重点,不丢失重要信息。
- Attention机制像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。
- 我们的视觉系统就是一种Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。

Attention Mechanism
工作原理
通过计算Decoder的隐藏状态与Encoder输出的每个词的隐藏状态的相似度(Score),进而得到每个词的Attention Weight,再将这些Weight与Encoder的隐藏状态加权求和,生成一个Context Vector。

Attention的工作原理
Encoder(编码器)
- 输入处理:原始输入是语料分词后的 token_id 被分批次传入 Embedding 层,将离散的 token_id 转换为连续的词向量。
- 特征提取:将得到的词向量作为输入,传入Encoder中的特征提取器(Feature Extractor)。特征提取器使用RNN系列的模型(RNN、LSTM、GRU),这里代称为RNNs。为了更好地捕捉一个句子前后的语义特征,使用双向的RNNs。双向RNNs由前向RNN和后向RNN组成,分别处理输入序列的前半部分和后半部分。
- 状态输出:两个方向的RNNs(前向和后向)各自产生一部分隐藏状态。将这两个方向的隐藏层状态拼接(concatenate)成一个完整的隐藏状态 hs。这个状态 hs 包含了输入序列中各个词的语义信息,是后续Attention机制所需的重要状态值。
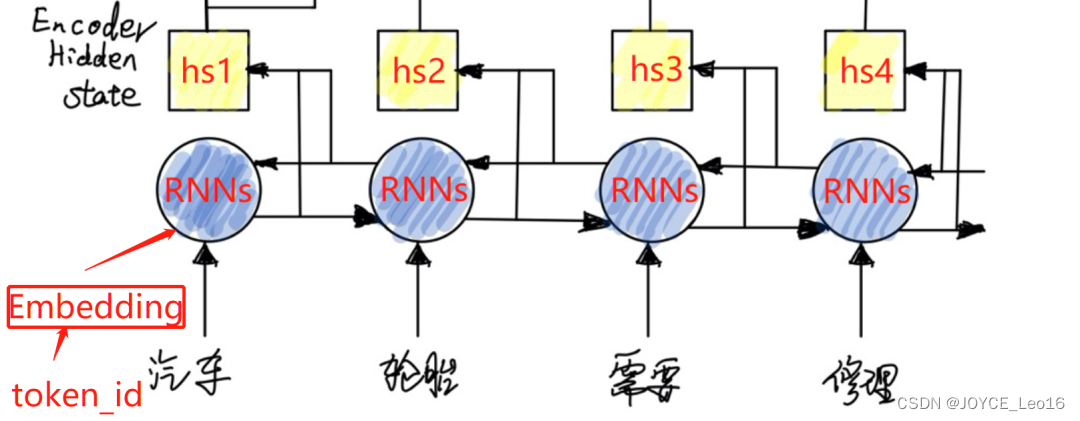
Encoder(编码器)
Decoder(解码器)
- 输入与隐藏状态传递:在Decoder的 t-1 时刻,RNNs(如LSTM或GRU)输出一个隐藏状态 h(t-1)。
- 计算Score:在 t 时刻,Decoder的隐藏状态 h(t-1) 与编码部分产生的每个时间步的隐藏状态 h(s) (来自双向RNNs的拼接状态)进行计算,以得到一个Score。
- 计算Attention Weight:将所有计算得到的Score进行softmax归一化,得到每个输入词对应的Attention Weight。

计算 Score、Attention Weight
- 计算Context Vector:使用得到的Attention Weight与对应的 h(s) 进行加权求和(reduce_sum),得到Context Vector。这个Context Vector是输入序列中各个词根据当前Decoder隐藏状态重新加权得到的表示。这个Vector包含了输入序列中重要信息的加权表示,用于指导Decoder生成当前时刻的输出。
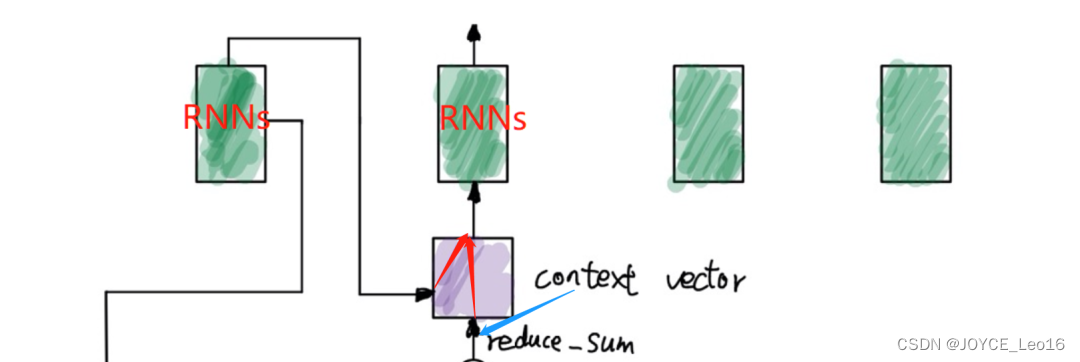
计算Context Vector
3、Transformer工作原理
Transformer:通常Attention会与传统的模型配合起来使用,但Google的一篇论文《Attention Is All You Need》中提出只需要注意力就可以完成传统模型所能完成的任务,从而摆脱传统模型对于长程依赖无能为力的问题并使得模型可以并行化,并基于此提出Transformer模型。

注意力机制的演化过程
Transformer架构
主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。

Transformer架构
输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
编码器部分:
- 由N个编码器堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
解码器部分:
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
工作原理
左边是N个编码器,右边是N个解码器,图中Transformer的N为6。
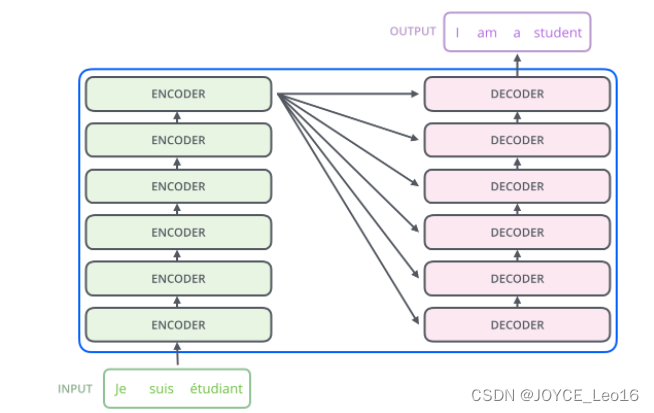
Transformer工作原理
Encoder(编码器)
- 图中的Transformer的编码器部分一共6个相同的编码器层组成。
- 每个编码器层都有两个子层,即多头自注意力机层(Multi-Head Attention)层和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。
- 在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
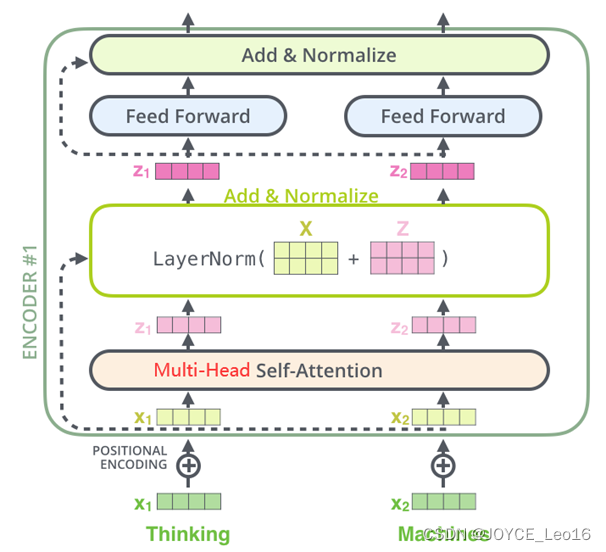
Encoder(编码器)架构
Decoder(解码器)
- 图中Transformer的解码器部分同样一共6个相同的解码器层组成。
- 每个解码器层都有三个子层,掩蔽自注意力层(Masked Self-Attention)、Encoder-Decoder注意力层、逐位置的前馈神经网络。
- 同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
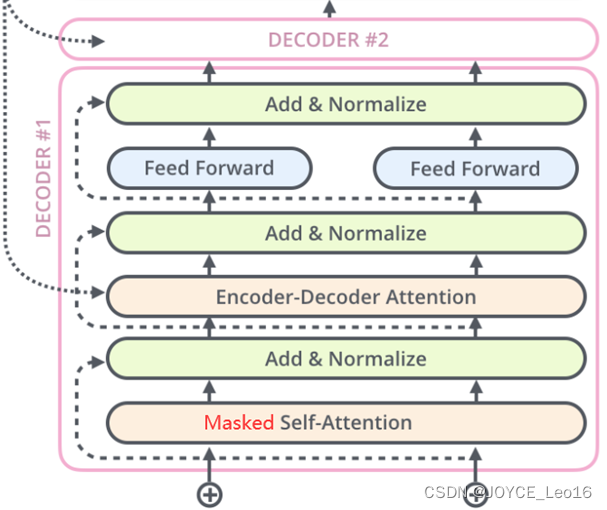
Decoder(解码器)架构
参考:架构师带你玩转AI

