
- 1AUTODOCK分子对接_autodock蛋白质和脂质分子对接
- 2自回归语言模型(AR)和自编码语言模型(AE)_ar ae模型
- 3el-table 表格封装并改造实现单元格可编辑_el-table 编辑单元格
- 4STM笔记_AD9833的详解及其f407驱动_ad9833驱动程序详解
- 523-480、基于Arduino Uno驱动的面部识别跟踪相机设计-CSDN_arduino uno 图像识别
- 6推荐3款自动爬虫神器,再也不用手撸代码了_爬虫软件 最新
- 7An unhandled exception occurred: spawn UNKNOWN windows10本地powershell启动不了解决方案_windows打不开powershell
- 8下一代 AI 搜索引擎 MindSearch:多智能体 + 系统2,模拟人类认知过程的 AI 搜索引擎
- 9脚本不得关闭非脚本打开的窗口。_【自动化测试】Selenium IDE脚本编辑与操作(了解)...
- 10【Redis】使用 Java 客户端连接 Redis_java连接redis
大模型微调之 在亚马逊AWS上实战LlaMA案例(四)_llama3的提示模板
赞
踩
大模型微调之 在亚马逊AWS上实战LlaMA案例(四)

在 Amazon SageMaker JumpStart 上微调 Llama 2 以生成文本
Meta 能够使用Amazon SageMaker JumpStart微调 Llama 2 模型。
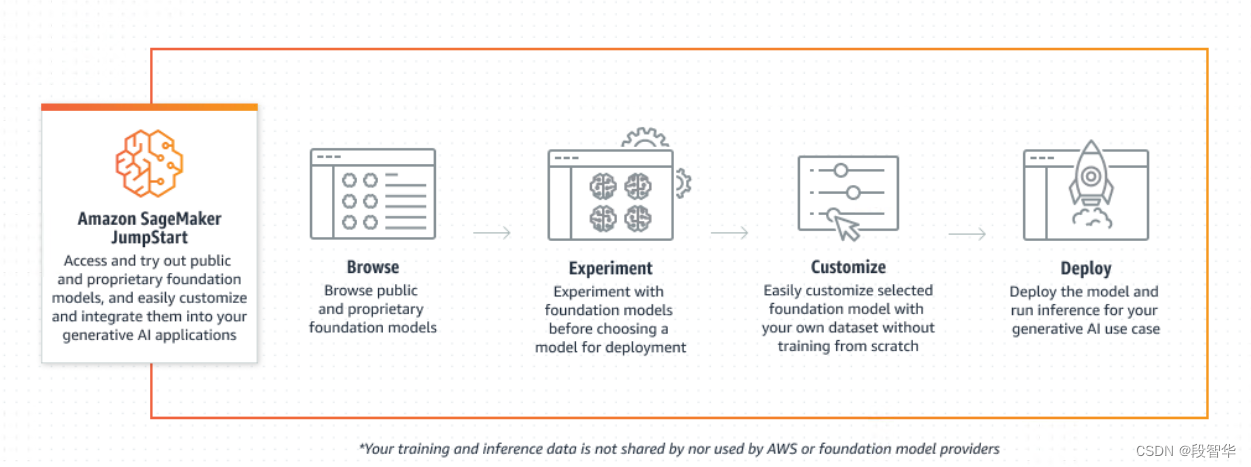
Llama 2 系列大型语言模型 (LLM) 是预先训练和微调的生成文本模型的集合,其规模从 70 亿到 700 亿个参数不等。经过微调的 LLM,称为 Llama-2-chat,针对对话用例进行了优化。您可以轻松尝试这些模型并将其与 SageMaker JumpStart 结合使用,SageMaker JumpStart 是一个机器学习 (ML) 中心,可提供对算法、模型和 ML 解决方案的访问,以便您可以快速开始使用 ML。现在,您还可以使用Amazon SageMaker Studio UI(只需单击几下)或使用 SageMaker Python SDK在 SageMaker JumpStart 上微调 70 亿、130 亿和 700 亿参数 Llama 2 文本生成模型。
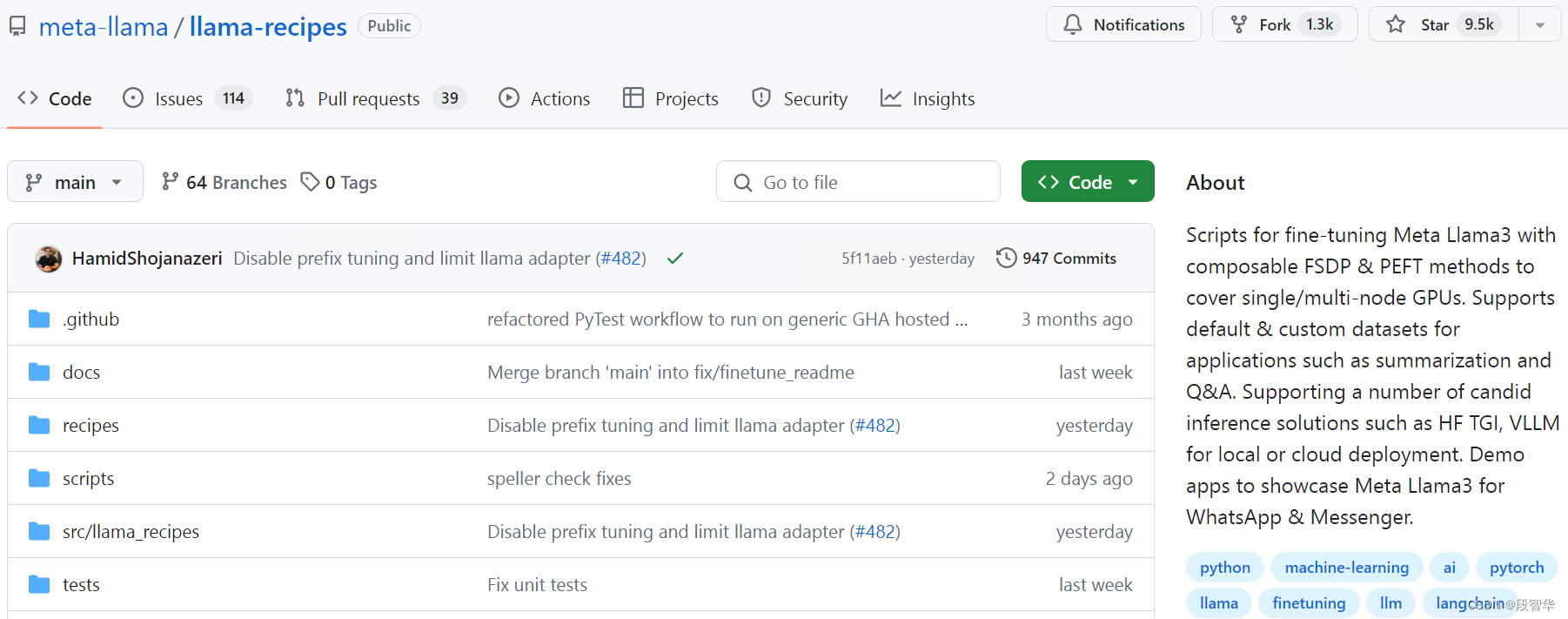
Llama 模型的微调基于 Meta 的llama-recipes存储库中提供的脚本,使用 PyTorch FSDP、PEFT/LoRA 和 int8 量化技术。
https://github.com/meta-llama/llama-recipes
Meta Llama 3 有一个新的提示模板和特殊标记(基于 tiktoken 标记生成器)。
标记 描述
- <|begin_of_text|> 这相当于BOS标记。
- <|end_of_text|> 这相当于EOS标记。对于多轮对话,它通常不被使用。相反,每条消息都以 相反 终止- <|eot_id|>。
- <|eot_id|> 该标记表示消息依次结束,即系统、用户或助理角色的单个消息的结束 。
- <|start_header_id|>{role}- <|end_header_id|> 这些标记包含特定消息的角色。可能的角色可以是:系统、用户、助理。
与 Meta Llama 3 的多回合对话遵循以下提示模板:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message_1 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1 }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message_2 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
每条消息<|eot_id|>在新标头开始之前都会有一个标记,表示角色发生变化。
一年多来,生成式人工智能基础模型一直是大多数机器学习和人工智能研究和用例的焦点。这些基础模型在文本生成、摘要、问答、图像和视频生成等生成任务中表现良好,因为它们的规模很大,而且还因为它们在多个大型数据集和数百个任务上进行了训练。尽管这些模型具有很强的泛化能力,但通常有些用例具有非常具体的领域数据(例如医疗保健或金融服务),因此这些模型可能无法为这些用例提供良好的结果。这导致需要根据特定用例和特定领域的数据进一步微调这些生成式人工智能模型。
在这系列文章中, 将介绍如何通过 SageMaker JumpStart 微调 Llama 2 预训练文本生成模型。
什么是Llama 2
Llama 2 是一种使用优化的 Transformer 架构的自回归语言模型。 Llama 2 旨在用于英语商业和研究用途。它具有一系列参数大小(70 亿、130 亿和 700 亿)以及预训练和微调的变量。根据 Meta 的说法,调整后的版本使用监督微调(SFT)和带有人类反馈的强化学习(RLHF)来符合人类对帮助和安全的偏好。 Llama 2 使用来自公开来源的 2 万亿个标记数据进行了预训练。调整后的模型旨在用于类似助理的聊天,而预训练的模型可适用于各种自然语言生成任务。无论开发人员使用哪个版本的模型,Meta 的负责任的使用指南都可以帮助指导额外的微调,这些微调可能是通过适当的安全缓解措施来定制和优化模型所必需的。
目前,Llama 2 在以下地区可用:
部署可用的预训练模型:“us-west-2”, “us-east-1”, “us-east-2”, “eu-west-1”, “ap-southeast-1”,“ap-southeast-2”
微调并部署微调后的模型:“us-east-1”, “us-west-2”,“eu-west-1”
Meta负责任的使用指南:负责任地构建的资源
负责任的使用指南是为开发人员提供的资源,它提供了以负责任的方式构建由大语言模型 (LLM) 支持的产品的最佳实践和注意事项,涵盖从开始到部署的各个开发阶段。
负责任的使用指南:您负责任地构建的资源
负责任的使用指南是为开发人员提供的资源,它提供了以负责任的方式构建由大语言模型 (LLM) 支持的产品的最佳实践和注意事项,涵盖从开始到部署的各个开发阶段。

https://ai.meta.com/static-resource/responsible-use-guide/
什么是 SageMaker JumpStart
借助 SageMaker JumpStart,机器学习从业者可以从众多公开可用的基础模型中进行选择。 ML 从业者可以从网络隔离环境将基础模型部署到专用Amazon SageMaker实例,并使用 SageMaker 自定义模型以进行模型训练和部署。现在,您只需在 SageMaker Studio 中单击几下,或通过 SageMaker Python SDK 以编程方式发现和部署 Llama 2,即可使用Amazon SageMaker Pipelines、Amazon SageMaker Debugger或容器日志等SageMaker 功能获得模型性能和 MLOps 控制。该模型部署在 AWS 安全环境中并受您的 VPC 控制,有助于确保数据安全。此外,您还可以通过 SageMaker JumpStart 微调 Llama2 7B、13B 和 70B 预训练文本生成模型。
为什么选择 Amazon SageMaker?
Amazon SageMaker 是一项完全托管的服务,汇集了一系列广泛的工具,可为任何用例提供高性能、低成本的机器学习 (ML)。借助 SageMaker,您可以使用笔记本、调试器、分析器、管道、MLOps 等工具大规模构建、训练和部署 ML 模型,所有这些都在一个集成开发环境 (IDE) 中进行。 SageMaker 通过简化的访问控制和 ML 项目的透明度来支持治理要求。此外,您还可以构建自己的 FM、在海量数据集上训练的大型模型,并使用专用工具来微调、实验、重新训练和部署 FM。 SageMaker 提供对数百个预训练模型的访问,包括公开可用的 FM,您只需单击几下即可部署。
Amazon SageMaker Pipelines 是一项专门构建的工作流编排服务,可自动执行从数据预处理到模型监控的机器学习 (ML) 的所有阶段。借助直观的 UI 和 Python SDK,您可以大规模管理可重复的端到端 ML 管道。与多个 AWS 服务的本机集成允许您根据 MLOps 要求自定义 ML 生命周期。
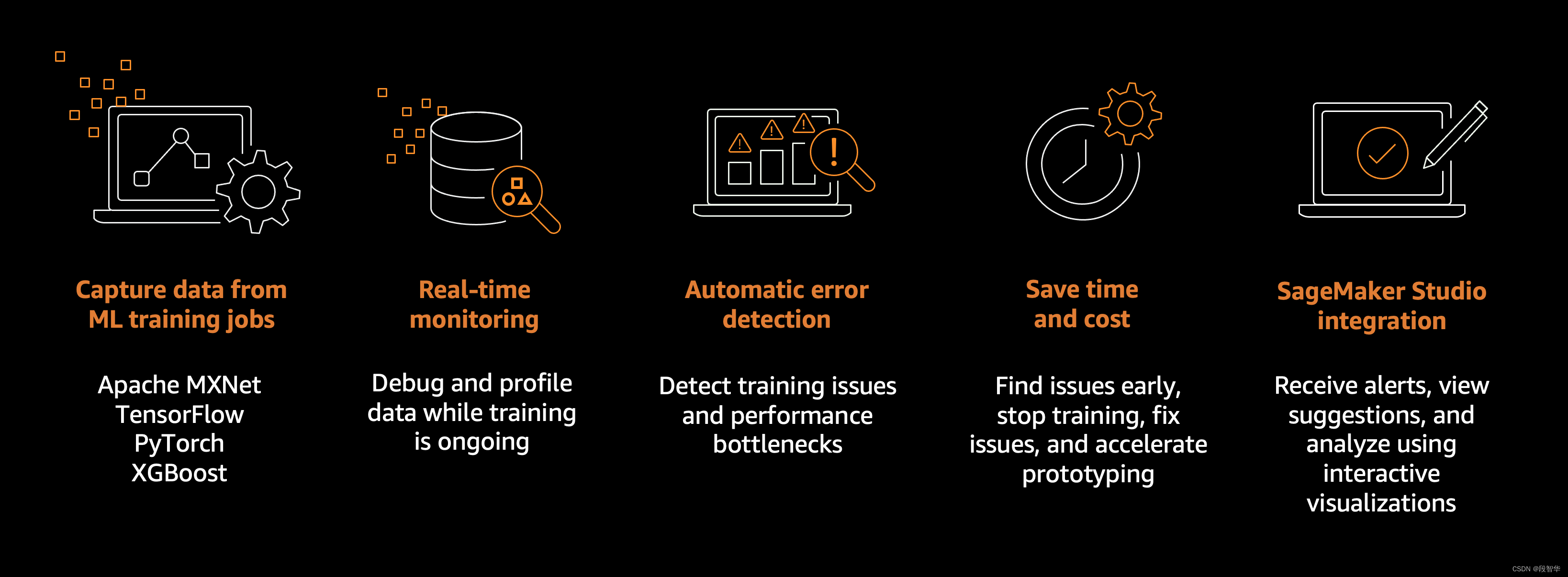
Amazon SageMaker 调试器功能
机器学习 (ML) 训练作业可能会出现过度拟合、激活函数饱和和梯度消失等问题,从而影响模型性能。
SageMaker Debugger 提供了调试训练作业并解决此类问题的工具,以提高模型的性能。调试器还提供了一些工具,用于在发现训练异常时发送警报、针对问题采取措施,并通过可视化收集的指标和张量来识别问题的根本原因。
SageMaker Debugger 支持 Apache MXNet、PyTorch、TensorFlow 和 XGBoost 框架。有关 SageMaker Debugger 支持的可用框架和版本的更多信息,请参阅支持的框架和算法。
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。







